Wenn Sie sich für maschinelles Lernen interessieren, haben Sie wahrscheinlich von BERT und Transformatoren gehört.
BERT ist ein Sprachmodell von Google, das bei einer Reihe von Aufgaben mit großem Abstand die neuesten Ergebnisse zeigt. BERT und allgemein Transformatoren sind zu einem völlig neuen Schritt in der Entwicklung von Algorithmen zur Verarbeitung natürlicher Sprache (NLP) geworden. Der Artikel darüber und die „Rangliste“ für verschiedene Benchmarks finden Sie auf der Website von Papers With Code .
Bei BERT gibt es ein Problem: Der Einsatz in industriellen Systemen ist problematisch. BERT-Base enthält 110M Parameter, BERT-Large - 340M. Aufgrund einer so großen Anzahl von Parametern ist es schwierig, dieses Modell auf Geräte mit begrenzten Ressourcen, wie z. B. Mobiltelefone, herunterzuladen. Darüber hinaus macht die lange Inferenzzeit dieses Modell ungeeignet, wenn die Reaktionsgeschwindigkeit kritisch ist. Daher ist die Suche nach Wegen zur Beschleunigung des BERT ein sehr aktuelles Thema.
In Avito müssen wir häufig Probleme mit der Textklassifizierung lösen. Dies ist eine typische angewandte maschinelle Lernaufgabe, die gut untersucht wurde. Aber es gibt immer die Versuchung, etwas Neues auszuprobieren. Dieser Artikel entstand aus dem Versuch heraus, BERT in alltäglichen maschinellen Lernaufgaben anzuwenden. Darin werde ich zeigen, wie Sie die Qualität eines vorhandenen Modells mithilfe von BERT erheblich verbessern können, ohne neue Daten hinzuzufügen oder das Modell zu komplizieren.

Wissensdestillation als Methode zur Beschleunigung neuronaler Netze
Es gibt verschiedene Möglichkeiten, neuronale Netze zu beschleunigen / zu vereinfachen. Die detaillierteste Rezension, die ich getroffen habe, ist im Intento-Blog auf dem Medium veröffentlicht .
Die Methoden lassen sich grob in drei Gruppen einteilen:
- Änderung der Netzwerkarchitektur.
- Modellkomprimierung (Quantisierung, Bereinigung).
- Wissensdestillation.
Wenn die ersten beiden Methoden relativ gut bekannt und verständlich sind, ist die dritte weniger verbreitet. Zum ersten Mal schlug Rich Caruana die Idee der Destillation in dem Artikel „Model Compression“ vor . Das Wesentliche ist einfach: Sie können ein leichtgewichtiges Modell trainieren, das das Verhalten eines Lehrermodells oder sogar eines Ensembles von Modellen nachahmt. In unserem Fall wird der Lehrer BERT sein und der Schüler wird ein beliebiges leichtes Modell sein.
Herausforderung
Analysieren wir die Destillation am Beispiel der binären Klassifikation. Nehmen Sie den offenen SST-2-Datensatz aus dem Standardsatz von Tasks, mit denen Modelle für NLP getestet werden.
Dieser Datensatz ist eine Sammlung von Rezensionen zu Filmen mit IMDb, aufgeschlüsselt nach emotionalen Farben - positiv oder negativ. Die Metrik in diesem Datensatz ist die Genauigkeit.
Ausbildung von BERT-basierten Modellen oder „Lehrern“
Zunächst müssen Sie das „große“ BERT-basierte Modell trainieren, das Lehrer wird. Der einfachste Weg, dies zu tun, besteht darin, die Einbettungen von BERT zu nehmen und den Klassifikator darüber zu trainieren und dem Netzwerk eine Ebene hinzuzufügen.
Dank der Transformers-Bibliothek ist dies ziemlich einfach, da es eine fertige Klasse für das BertForSequenceClassification-Modell gibt. Meiner Meinung nach wurde das ausführlichste und verständlichste Tutorial zum Unterrichten dieses Modells von Towards Data Science veröffentlicht .
Stellen wir uns vor, wir hätten ein geschultes BertForSequenceClassification-Modell. In unserem Fall ist num_labels = 2, da wir eine binäre Klassifikation haben. Wir werden dieses Modell als "Lehrer" verwenden.
"Schüler" lernen
Als Student können Sie jede Architektur nehmen: ein neuronales Netzwerk, ein lineares Modell, einen Entscheidungsbaum. Versuchen wir, BiLSTM für eine bessere Visualisierung beizubringen. Zunächst unterrichten wir BiLSTM ohne BERT.
Um Text an die Eingabe eines neuronalen Netzwerks zu senden, müssen Sie ihn als Vektor darstellen. Eine der einfachsten Möglichkeiten besteht darin, jedes Wort seinem Index im Wörterbuch zuzuordnen. Das Wörterbuch besteht aus den n beliebtesten Wörtern in unserem Datensatz sowie zwei Servicewörtern: "pad" - "dummy word", damit alle Sequenzen gleich lang sind, und "unk" - für Wörter außerhalb des Wörterbuchs. Wir werden das Wörterbuch mit den Standardwerkzeugen von torchtext erstellen. Der Einfachheit halber habe ich keine vorgefertigten Worteinbettungen verwendet.
import torch from torchtext import data def get_vocab(X): X_split = [t.split() for t in X] text_field = data.Field() text_field.build_vocab(X_split, max_size=10000) return text_field def pad(seq, max_len): if len(seq) < max_len: seq = seq + ['<pad>'] * (max_len - len(seq)) return seq[0:max_len] def to_indexes(vocab, words): return [vocab.stoi[w] for w in words] def to_dataset(x, y, y_real): torch_x = torch.tensor(x, dtype=torch.long) torch_y = torch.tensor(y, dtype=torch.float) torch_real_y = torch.tensor(y_real, dtype=torch.long) return TensorDataset(torch_x, torch_y, torch_real_y)
Modell BiLSTM
Der Code für das Modell sieht folgendermaßen aus:
import torch from torch import nn from torch.autograd import Variable class SimpleLSTM(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, batch_size, device=None): super(SimpleLSTM, self).__init__() self.batch_size = batch_size self.hidden_dim = hidden_dim self.n_layers = n_layers self.embedding = nn.Embedding(input_dim, embedding_dim) self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout) self.fc = nn.Linear(hidden_dim * 2, output_dim) self.dropout = nn.Dropout(dropout) self.device = self.init_device(device) self.hidden = self.init_hidden() @staticmethod def init_device(device): if device is None: return torch.device('cuda') return device def init_hidden(self): return (Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device)), Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device))) def forward(self, text, text_lengths=None): self.hidden = self.init_hidden() x = self.embedding(text) x, self.hidden = self.rnn(x, self.hidden) hidden, cell = self.hidden hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)) x = self.fc(hidden) return x
Schulung
Für dieses Modell ist die Dimension des Ausgabevektors (batch_size, output_dim). Im Training verwenden wir den üblichen logloss. PyTorch verfügt über eine BCEWithLogitsLoss-Klasse, die Sigmoid- und Kreuzentropie kombiniert. Was du brauchst.
def loss(self, output, bert_prob, real_label): criterion = torch.nn.BCEWithLogitsLoss() return criterion(output, real_label.float())
Code für eine Ära des Lernens:
def get_optimizer(model): optimizer = torch.optim.Adam(model.parameters()) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma=0.9) return optimizer, scheduler def epoch_train_func(model, dataset, loss_func, batch_size): train_loss = 0 train_sampler = RandomSampler(dataset) data_loader = DataLoader(dataset, sampler=train_sampler, batch_size=batch_size, drop_last=True) model.train() optimizer, scheduler = get_optimizer(model) for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Train')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) model.zero_grad() output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) loss.backward() optimizer.step() train_loss += loss.item() scheduler.step() return train_loss / len(data_loader)
Code zur Überprüfung nach der Ära:
def epoch_evaluate_func(model, eval_dataset, loss_func, batch_size): eval_sampler = SequentialSampler(eval_dataset) data_loader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=batch_size, drop_last=True) eval_loss = 0.0 model.eval() for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Val')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) eval_loss += loss.item() return eval_loss / len(data_loader)
Wenn all dies zusammengestellt ist, erhalten wir den folgenden Code zum Trainieren des Modells:
import os import torch from torch.utils.data import (TensorDataset, random_split, RandomSampler, DataLoader, SequentialSampler) from torchtext import data from tqdm import tqdm def device(): return torch.device("cuda" if torch.cuda.is_available() else "cpu") def to_device(text, bert_prob, real_label): text = text.to(device()) bert_prob = bert_prob.to(device()) real_label = real_label.to(device()) return text, bert_prob, real_label class LSTMBaseline(object): vocab_name = 'text_vocab.pt' weights_name = 'simple_lstm.pt' def __init__(self, settings): self.settings = settings self.criterion = torch.nn.BCEWithLogitsLoss().to(device()) def loss(self, output, bert_prob, real_label): return self.criterion(output, real_label.float()) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=1, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model def train(self, X, y, y_real, output_dir): max_len = self.settings['max_seq_length'] text_field = get_vocab(X) X_split = [t.split() for t in X] X_pad = [pad(s, max_len) for s in tqdm(X_split, desc='pad')] X_index = [to_indexes(text_field.vocab, s) for s in tqdm(X_pad, desc='to index')] dataset = to_dataset(X_index, y, y_real) val_len = int(len(dataset) * 0.1) train_dataset, val_dataset = random_split(dataset, (len(dataset) - val_len, val_len)) model = self.model(text_field) model.to(device()) self.full_train(model, train_dataset, val_dataset, output_dir) torch.save(text_field, os.path.join(output_dir, self.vocab_name)) def full_train(self, model, train_dataset, val_dataset, output_dir): train_settings = self.settings num_train_epochs = train_settings['num_train_epochs'] best_eval_loss = 100000 for epoch in range(num_train_epochs): train_loss = epoch_train_func(model, train_dataset, self.loss, self.settings['train_batch_size']) eval_loss = epoch_evaluate_func(model, val_dataset, self.loss, self.settings['eval_batch_size']) if eval_loss < best_eval_loss: best_eval_loss = eval_loss torch.save(model.state_dict(), os.path.join(output_dir, self.weights_name))
Destillation
Die Idee dieser Destillationsmethode stammt aus einem Artikel von Forschern der University of Waterloo . Wie ich bereits sagte, muss der „Schüler“ lernen, das Verhalten des „Lehrers“ nachzuahmen. Was genau ist das Verhalten? In unserem Fall sind dies die Vorhersagen des Lehrermodells auf dem Trainingssatz. Die wichtigste Idee ist, die Netzwerkausgabe zu verwenden, bevor die Aktivierungsfunktion angewendet wird. Es wird angenommen, dass das Modell auf diese Weise die interne Repräsentation besser lernen kann als im Fall der endgültigen Wahrscheinlichkeiten.
Der ursprüngliche Artikel schlägt vor, der Verlustfunktion einen Begriff hinzuzufügen, der für den "Imitations" -Fehler (MSE) zwischen Modellprotokollen verantwortlich ist.

Zu diesem Zweck nehmen wir zwei kleine Änderungen vor: Ändern Sie die Anzahl der Netzwerkausgänge von 1 auf 2 und korrigieren Sie die Verlustfunktion.
def loss(self, output, bert_prob, real_label): a = 0.5 criterion_mse = torch.nn.MSELoss() criterion_ce = torch.nn.CrossEntropyLoss() return a*criterion_ce(output, real_label) + (1-a)*criterion_mse(output, bert_prob)
Sie können den gesamten Code, den wir geschrieben haben, wiederverwenden, indem Sie nur das Modell und den Verlust neu definieren:
class LSTMDistilled(LSTMBaseline): vocab_name = 'distil_text_vocab.pt' weights_name = 'distil_lstm.pt' def __init__(self, settings): super(LSTMDistilled, self).__init__(settings) self.criterion_mse = torch.nn.MSELoss() self.criterion_ce = torch.nn.CrossEntropyLoss() self.a = 0.5 def loss(self, output, bert_prob, real_label): return self.a * self.criterion_ce(output, real_label) + (1 - self.a) * self.criterion_mse(output, bert_prob) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=2, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model
Das ist alles, jetzt lernt unser Modell "nachzuahmen".
Modellvergleich
Im Originalartikel werden die besten Klassifizierungsergebnisse für SST-2 bei a = 0 erhalten, wenn das Modell nur lernt, zu imitieren, ohne reale Bezeichnungen zu berücksichtigen. Die Genauigkeit ist immer noch geringer als bei BERT, aber deutlich besser als bei regulärem BiLSTM.

Ich habe versucht, die Ergebnisse des Artikels zu wiederholen, aber in meinen Experimenten wurde das beste Ergebnis bei a = 0,5 erzielt.
So sehen Verlust- und Genauigkeitsdiagramme aus, wenn Sie LSTM wie gewohnt lernen. Gemessen am Verlustverhalten lernte das Modell schnell und irgendwann nach der sechsten Ära begann die Umschulung.
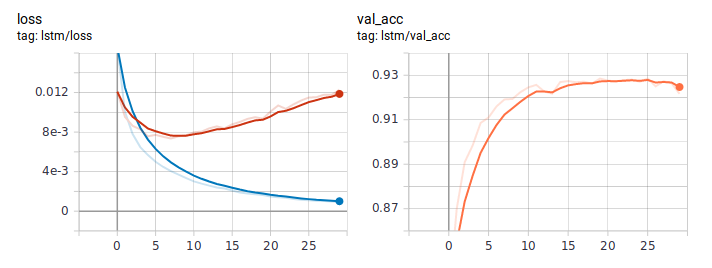
Destillationsdiagramme:
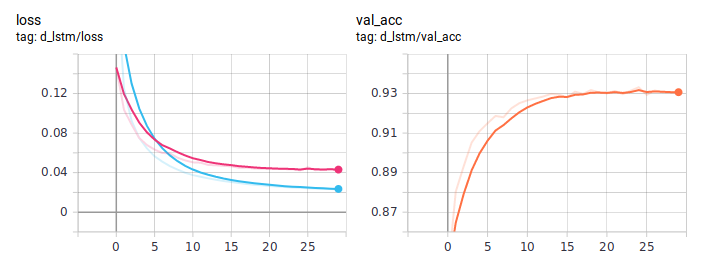
Destilliertes BiLSTM ist durchweg besser als normal. Es ist wichtig, dass sie in der Architektur absolut identisch sind, der einzige Unterschied liegt in der Art des Unterrichts. Ich habe den vollständigen Trainingscode auf GitHub gepostet .
Fazit
In diesem Leitfaden habe ich versucht, die Grundidee eines Destillationsansatzes zu erläutern. Die spezifische Architektur des Schülers hängt von der jeweiligen Aufgabe ab. Im Allgemeinen ist dieser Ansatz jedoch bei jeder praktischen Aufgabe anwendbar. Aufgrund der Komplexität in der Phase des Modelltrainings können Sie die Qualität erheblich steigern und gleichzeitig die ursprüngliche Einfachheit der Architektur beibehalten.