NeurIPS (
Neuronale Informationsverarbeitungssysteme ) ist die weltweit größte Konferenz zu maschinellem Lernen und künstlicher Intelligenz und das wichtigste Ereignis in der Welt des Tiefenlernens.
Werden wir DS-Ingenieure im neuen Jahrzehnt auch Biologie, Linguistik und Psychologie beherrschen? Wir werden in unserer Kritik erzählen.

Dieses Jahr brachte die Konferenz in Vancouver (Kanada) mehr als 13.500 Menschen aus 80 Ländern zusammen. Dies ist nicht das erste Jahr, in dem die Sberbank Russland auf der Konferenz vertreten hat. Das DS-Team sprach über die Einführung von ML in Bankprozessen, den ML-Wettbewerb und die Funktionen der Sberbank DS-Plattform. Was waren die Haupttrends des Jahres 2019 in der ML-Community? Die Konferenzteilnehmer erzählen:
Andrey Chertok und
Tatyana Shavrina .
In diesem Jahr wurden über 1400 Artikel bei NeurIPS akzeptiert - Algorithmen, neue Modelle und neue Anwendungen für neue Daten.
Link zu allen MaterialienInhalt:
- Trends
- Interpretierbarkeit des Modells
- Multidisziplinarität
- Argumentation
- RL
- Gan
- Wichtige eingeladene Vorträge
- "Soziale Intelligenz", Blaise Aguera y Arcas (Google)
- "Veridical Data Science", Bin Yu (Berkeley)
- „Modellierung menschlichen Verhaltens mit maschinellem Lernen: Chancen und Herausforderungen“, Nuria M Oliver, Albert Ali Salah
- "Vom System 1 zum System 2 Deep Learning", Yoshua Bengio
Trends für 2019
1. Interpretierbarkeit des Modells und die neue ML-MethodikDas Hauptthema der Konferenz ist die Interpretation und der Nachweis, warum wir diese oder jene Ergebnisse erhalten. Man kann lange über die philosophische Bedeutung der Interpretation der „Black Box“ sprechen, aber es gab realere Methoden und technische Entwicklungen in diesem Bereich.
Die Methode der Reproduzierbarkeit von Modellen und die Extraktion von Wissen daraus ist ein neues wissenschaftliches Instrumentarium. Modelle können als Werkzeug zum Erwerb und Testen neuen Wissens dienen, und jede Phase der Vorverarbeitung, Schulung und Anwendung des Modells sollte reproduzierbar sein.
Ein erheblicher Teil der Veröffentlichungen befasst sich nicht mit der Erstellung von Modellen und Werkzeugen, sondern mit Problemen der Gewährleistung von Sicherheit, Transparenz und Überprüfbarkeit der Ergebnisse. Insbesondere wurde ein separater Datenstrom über Angriffe auf das Modell (gegnerische Angriffe) angezeigt, und Optionen sowohl für Angriffe auf das Training als auch für Angriffe auf Anwendungen werden berücksichtigt.
Artikel:
- Veridical Data Science ist ein Artikel zur Modellüberprüfung. Es enthält einen Überblick über moderne Werkzeuge zur Interpretation von Modellen, insbesondere die Verwendung von Aufmerksamkeit und die Gewinnung von Merkmalsbedeutung aufgrund der "Destillation" des neuronalen Netzes durch lineare Modelle.
- Das sieht so aus: Tiefes Lernen für interpretierbare Bilderkennung Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, Jonathan K. Su
- Ein Maßstab für Interpretierbarkeitsmethoden in tiefen neuronalen Netzen Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans und Been Kim
- Auf dem Weg zu interpretierbarem Bestärkungslernen unter Verwendung der aufmerksamen Augmented Agents Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra und Danilo Jimenez Rezende
- Ein voreingenommenes Maß für die Bedeutung von MDI-Merkmalen für zufällige Wälder Xiao Li, Yu Wang, Sumanta Basu, Karl Kumbier und Bin Yu
- Wissensextraktion ohne beobachtbare Daten Jaemin Yoo, Minyong Cho, Taebum Kim, U Kang
- Ein Schritt zur Quantifizierung unabhängig reproduzierbarer maschineller Lernforschung Edward Raff
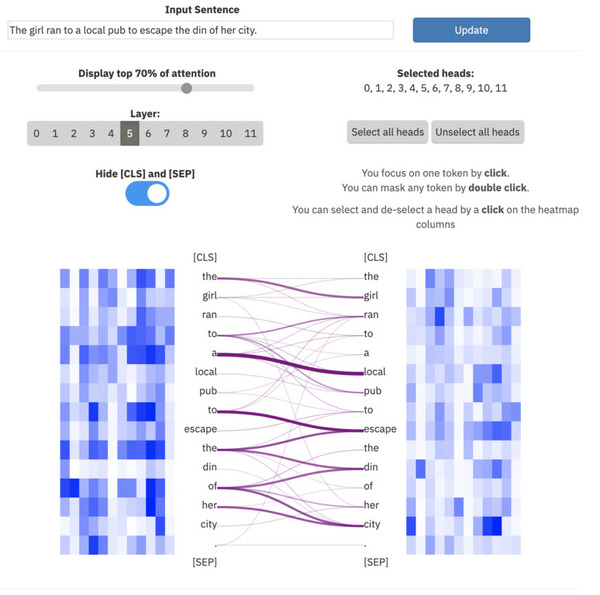 ExBert.net zeigt die Modellinterpretation für Textverarbeitungsaufgaben
ExBert.net zeigt die Modellinterpretation für Textverarbeitungsaufgaben
2. MultidisziplinaritätUm eine zuverlässige Überprüfung zu gewährleisten und Mechanismen zum Testen und Auffüllen von Wissen zu entwickeln, benötigen wir Spezialisten aus verwandten Bereichen, die gleichzeitig über Kompetenzen in ML und im Fachbereich (Medizin, Linguistik, Neurobiologie, Pädagogik usw.) verfügen. Besonders hervorzuheben ist die bedeutendere Präsenz von Werken und Präsentationen zu den Themen Neurowissenschaften und Kognitionswissenschaften - es kommt zu einer Annäherung von Fachleuten und zu einer Anleihe von Ideen.
Neben dieser Annäherung ist Multidisziplinarität in der gemeinsamen Verarbeitung von Informationen aus verschiedenen Quellen geplant: Text und Fotos, Text und Spiele, Graphendatenbanken + Text und Fotos.
Artikel:
 Zwei Modelle - ein Stratege und ein Darsteller - basierend auf RL und NLP spielen eine Online-Strategie3. Begründung
Zwei Modelle - ein Stratege und ein Darsteller - basierend auf RL und NLP spielen eine Online-Strategie3. BegründungStärkung der künstlichen Intelligenz - eine Bewegung in Richtung selbstlernender Systeme, "bewusst", argumentieren und argumentieren (argumentieren). Insbesondere kommt es zu kausaler Folgerung und vernünftigem Denken. Ein Teil der Berichte befasst sich mit Meta-Learning (Lernen lernen) und der Kombination von DL-Technologien mit Logik 1. und 2. Ordnung - der Begriff Artificial General Intelligence (AGI) wird in Reden von Sprechern häufig verwendet.
Artikel:
- Heterogenes Graph-Lernen für visuelles Denken Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang, Nong Xiao
- Überbrückung von maschinellem Lernen und logischem Denken durch entführendes Lernen Wang-Zhou Dai, Qiuling Xu, Yang Yu, Zhi-Hua Zhou
- Implizit lernen, in Logik erster Ordnung zu argumentieren Vaishak Belle, Brendan Juba
- PHYRE: Ein neuer Maßstab für das physikalische Denken Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson und Ross Girshick
- Quanteneinbettung von Wissen für das Denken von Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam und L Venkata Subramaniam
4. Verstärkung lernenBei den meisten Arbeiten werden die traditionellen Bereiche von RL - DOTA2, Starcraft, weiterentwickelt, wobei Architekturen mit Computer Vision, NLP und Graphendatenbanken kombiniert werden.
Ein separater Konferenztag war dem RL-Workshop gewidmet, in dem die Architektur des Optimistic Actor Critic-Modells vorgestellt wurde, das alle vorherigen, insbesondere die der Soft Actor Critic, übertrifft.
Artikel:
 StarCraft-Spieler kämpfen gegen Alphastar (DeepMind)5. GAN
StarCraft-Spieler kämpfen gegen Alphastar (DeepMind)5. GANGenerative Netzwerke stehen nach wie vor im Fokus: Viele Arbeiten verwenden Vanille-GANs für mathematische Beweise und wenden sie auch in neuen, ungewöhnlichen Versionen an (graphgenerative Modelle, Arbeiten mit Reihen, Anwendung, um Beziehungen in Daten zu verursachen und zu bewirken usw.).
Artikel:
Da die Arbeit mehr als
1.400 genommen hat , werden wir über die wichtigsten Leistungen sprechen.
Eingeladene Vorträge
"Soziale Intelligenz", Blaise Aguera y Arcas (Google)
LinkFolien und VideosDer Bericht widmet sich der allgemeinen Methodik des maschinellen Lernens und den Perspektiven, die die Branche derzeit verändern - vor welchen Kreuzungen stehen wir? Wie funktioniert das Gehirn und die Evolution und warum verwenden wir so wenig, dass wir die Entwicklung natürlicher Systeme bereits gut kennen?
Die industrielle Entwicklung von ML stimmt weitgehend mit den Meilensteinen der Entwicklung von Google überein, das seine Forschungsergebnisse zu NeurIPS von Jahr zu Jahr veröffentlicht:
- 1997 - Start von Suchkapazitäten, ersten Servern, kleiner Rechenleistung
- 2010 - Jeff Dean startet das Google Brain-Projekt, ein Boom des neuronalen Netzwerks zu Beginn
- 2015 - Industrielle Implementierung neuronaler Netze, schnelle Gesichtserkennung direkt auf dem lokalen Gerät, durch Tensor Computing geschärfte Low-Level-Prozessoren - TPU. Google bringt Coral ai auf den Markt - ein Analogon von Raspberry pi, einem Mini-Computer zum Einführen neuronaler Netze in experimentelle Installationen
- 2017 - Google beginnt mit der Entwicklung eines dezentralen Trainings und kombiniert die Ergebnisse des Trainings neuronaler Netze von verschiedenen Geräten zu einem Modell - auf Android
Heutzutage beschäftigt sich eine ganze Branche mit Datensicherheit, indem Lernergebnisse auf lokalen Geräten kombiniert und reproduziert werden.
Föderiertes Lernen - ML-Richtung, in der einzelne Modelle unabhängig voneinander studieren und dann zu einem einzigen Modell (ohne Zentralisierung der Quelldaten) kombiniert werden, angepasst an seltene Ereignisse, Anomalien, Personalisierung usw. Alle Android-Geräte sind für Google im Wesentlichen ein einziger Computer-Supercomputer.
Generative Modelle, die auf föderiertem Lernen basieren, sind laut Google ein zukunftsträchtiger Bereich, der sich "in den frühen Stadien des exponentiellen Wachstums" befindet. Laut dem Dozenten können GANs lernen, das Massenverhalten von Populationen lebender Organismen und Denkalgorithmen zu reproduzieren.
Anhand von zwei einfachen GAN-Architekturen wird gezeigt, dass bei ihnen die Suche nach dem Optimierungspfad in einem Kreis wandert, was bedeutet, dass die Optimierung als solche nicht stattfindet. Darüber hinaus modellieren diese Modelle sehr erfolgreich die Experimente, die Biologen an Bakterienpopulationen durchgeführt haben, und zwingen sie, neue Strategien für das Verhalten bei der Nahrungssuche zu erlernen. Wir können daraus schließen, dass das Leben anders funktioniert als die Optimierungsfunktion.
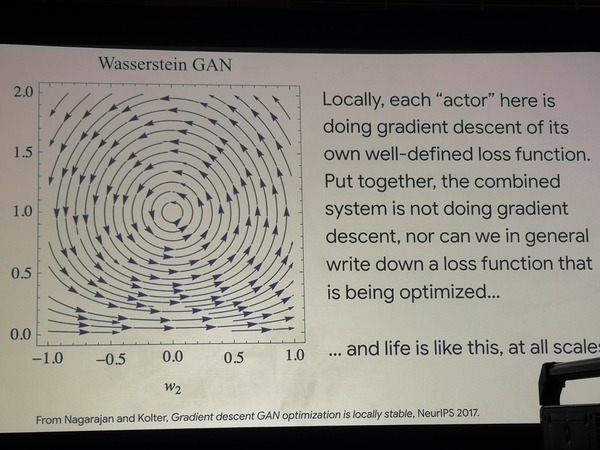 Wandering GAN-Optimierung
Wandering GAN-OptimierungAlles, was wir jetzt im Rahmen des maschinellen Lernens tun, sind enge und äußerst formalisierte Aufgaben, während diese Formalismen schlecht verallgemeinert sind und nicht unserem Fachwissen auf Gebieten wie Neurophysiologie und Biologie entsprechen.
Was es in naher Zukunft wirklich wert ist, aus dem Bereich der Neurophysiologie ausgeliehen zu werden, ist die neue Architektur der Neuronen und eine kleine Überarbeitung der Mechanismen der Rückübertragung von Fehlern.
Das menschliche Gehirn selbst lernt nicht, wie man ein neuronales Netzwerk benutzt:
- Er hat keine zufälligen primären Einführungen, einschließlich jener, die durch die Sinne und in der Kindheit festgelegt wurden
- Er hat die etablierten Richtungen der instinktiven Entwicklung (der Wunsch, eine Sprache von einem Säugling in aufrechter Haltung zu lernen)
Das Erlernen des individuellen Gehirns ist eine untergeordnete Aufgabe. Vielleicht sollten wir die „Kolonien“ sich schnell verändernder Individuen betrachten, die sich gegenseitig Wissen übermitteln, um die Mechanismen der Gruppenentwicklung zu reproduzieren.
Was können wir jetzt in ML-Algorithmen einbauen:
- Anwenden von Zelllinienmodellen, die der Bevölkerung Training bieten, aber das kurze Leben des Individuums („individuelles Gehirn“)
- Lernen in wenigen Augenblicken an einigen Beispielen
- Komplexere Neuronenstrukturen, leicht unterschiedliche Aktivierungsfunktionen
- Weitergabe des „Genoms“ an zukünftige Generationen - Backpropagation-Algorithmus
- Sobald wir Neurophysiologie und Neuronale Netze verbinden, werden wir lernen, aus vielen Komponenten ein multifunktionales Gehirn aufzubauen.
Unter diesem Gesichtspunkt ist die Praxis von SOTA-Lösungen nachteilig und sollte überprüft werden, um gemeinsame Aufgaben (Benchmarks) zu entwickeln.
"Veridical Data Science", Bin Yu (Berkeley)
Videos und FolienDer Bericht befasst sich mit dem Problem der Interpretation maschineller Lernmodelle und der Methodik ihrer direkten Verifikation und Verifikation. Jedes trainierte ML-Modell kann als Wissensquelle wahrgenommen werden, die daraus extrahiert werden muss.
In vielen Bereichen, insbesondere in der Medizin, ist die Anwendung des Modells unmöglich, ohne dieses verborgene Wissen zu extrahieren und die Ergebnisse des Modells zu interpretieren. Andernfalls können wir nicht sicher sein, dass die Ergebnisse stabil, nicht zufällig und zuverlässig sind und den Patienten nicht töten. Die gesamte Richtung der Arbeitsmethodik entwickelt sich innerhalb des Paradigmas des tiefen Lernens und geht über seine Grenzen hinaus - die veridical data science. Was ist das?
Wir wollen die Qualität wissenschaftlicher Veröffentlichungen und die Reproduzierbarkeit von Modellen so erreichen, dass sie:
- vorhersehbar
- berechenbar
- stabil
Diese drei Prinzipien bilden die Grundlage der neuen Methodik. Wie können ML-Modelle anhand dieser Kriterien getestet werden? Am einfachsten ist es, sofort interpretierbare Modelle (Regressionen, Entscheidungsbäume) zu erstellen. Wir möchten jedoch die unmittelbaren Vorteile des Tiefenlernens nutzen.
Es gibt verschiedene Möglichkeiten, um mit dem Problem umzugehen:
- interpretiere das Modell;
- Verwenden Sie aufmerksamkeitsorientierte Methoden
- Verwenden Sie Algorithmus-Ensembles für das Training und stellen Sie sicher, dass linear interpretierbare Modelle die gleichen Antworten wie ein neuronales Netzwerk vorhersagen und Merkmale aus einem linearen Modell interpretieren.
- Trainingsdaten ändern und ergänzen. Dies umfasst das Hinzufügen von Rauschen, Interferenzen und Datenerweiterungen.
- alle Methoden, die sicherstellen, dass die Modellergebnisse nicht zufällig sind und nicht von kleinen unerwünschten Interferenzen abhängen (gegnerische Angriffe);
- Interpretieren Sie das Post-Factum-Modell nach dem Training.
- Zeichengewichte auf verschiedene Arten untersuchen;
- studieren Sie die Wahrscheinlichkeiten aller Hypothesen, die Verteilung der Klassen.
 Gegenangriff auf ein Schwein
Gegenangriff auf ein SchweinModellierungsfehler kosten alle viel: Ein anschauliches Beispiel - die Arbeit von Reinhart und Rogov "
Wachstum in Zeiten der Verschuldung " beeinflusste die Wirtschaftspolitik vieler europäischer Länder und zwang sie zu einer Sparpolitik, doch eine sorgfältige Gegenprüfung von Daten und deren Verarbeitung Jahre später zeigte das gegenteilige Ergebnis!
Jede ML-Technologie hat ihren eigenen Lebenszyklus von Implementierung zu Implementierung. Aufgabe der neuen Methodik ist es, in jeder Lebensphase des Modells drei Grundprinzipien zu überprüfen.
Zusammenfassung:
- Es werden mehrere Projekte entwickelt, um das ML-Modell zuverlässiger zu machen. Dies ist zum Beispiel deeptune (Link zu: github.com/ChrisCummins/paper-end2end-dl );
- Für die Weiterentwicklung der Methodik ist es notwendig, die Qualität der Veröffentlichungen im Bereich ML signifikant zu verbessern;
- Maschinelles Lernen braucht Führungskräfte mit multidisziplinärer Ausbildung und Fachkenntnissen in technischen und humanitären Bereichen.
„Modellierung menschlichen Verhaltens mit maschinellem Lernen: Chancen und Herausforderungen“ Nuria M Oliver, Albert Ali Salah
Vorlesung zur Modellierung des menschlichen Verhaltens, seiner technologischen Grundlagen und Anwendungsperspektiven.
Die Modellierung des menschlichen Verhaltens kann unterteilt werden in:
- individuelles Verhalten
- Kleingruppenverhalten
- Massenverhalten
Jeder dieser Typen kann mit ML modelliert werden, jedoch mit völlig unterschiedlichen Eingabeinformationen und Merkmalen. Jeder Typ hat auch seine eigenen ethischen Probleme, die jedes Projekt durchläuft:
- individuelles Verhalten - Identitätsdiebstahl, Deepfake;
- das Verhalten von Personengruppen - Deanonymisierung, Informationsbeschaffung über Bewegungen, Telefonanrufe usw .;
Individuelles VerhaltenDas Thema Computer Vision - Erkennen menschlicher Emotionen, seine Reaktionen. Es ist nur im Kontext, in der Zeit oder mit einer relativen Skala der eigenen Variabilität der Emotionen möglich. Auf der Folie ist die Erkennung der Emotionen von Mona Lisa anhand des Kontexts aus dem emotionalen Spektrum der mediterranen Frauen zu sehen. Ergebnis: ein Lächeln der Freude, aber mit Verachtung und Ekel. Der Grund liegt höchstwahrscheinlich in der technischen Art und Weise, die "neutrale" Emotion zu bestimmen.
Verhalten in kleinen GruppenBisher wird das Schlimmste aufgrund fehlender Informationen modelliert. Die Arbeiten von 2018 - 2019 wurden als Beispiel gezeigt. auf Dutzende von Menschen X Dutzende von Videos (vgl. Bilddatensätze 100k ++). Für die beste Simulation bei dieser Aufgabe sind multimodale Informationen erforderlich, vorzugsweise von Sensoren zu einem Telehöhenmesser, Thermometer, Mikrofonaufzeichnung usw.
MassenverhaltenDas am weitesten entwickelte Gebiet sind als Kunden die Vereinten Nationen und viele Staaten. Außenüberwachungskameras, Daten von Telefontürmen - Abrechnung, SMS, Anrufe, Daten zur Bewegung zwischen den Staatsgrenzen - all dies vermittelt eine sehr zuverlässige Vorstellung von der Bewegung der Menschenströme, von sozialen Instabilitäten. Mögliche Anwendungen der Technologie: Optimierung von Rettungseinsätzen, Unterstützung und rechtzeitige Evakuierung der Bevölkerung im Notfall. Die verwendeten Modelle werden bislang meist schlecht interpretiert - das sind verschiedene LSTMs und Faltungsnetzwerke. Es gab eine kurze Bemerkung, dass die UNO sich für ein neues Gesetz einsetzt, das europäische Unternehmen dazu verpflichtet, anonymisierte Daten weiterzugeben, die für jede Forschung notwendig sind.
"Vom System 1 zum System 2 Deep Learning", Yoshua Bengio
FolienIn einem Vortrag von Joshua trifft Benjio Deep Learning auf der Ebene der Zielsetzung auf die Neurowissenschaften.
Benjio identifiziert zwei Haupttypen von Aufgaben gemäß der Methodik des Nobelpreisträgers Daniel Kahneman (das Buch „
Langsam denken, schnell lösen “)
Typ 1 - System 1, die unbewussten Aktionen, die wir „an der Maschine“ (dem alten Gehirn) ausführen: Autofahren an vertrauten Orten, Gehen, Erkennen von Gesichtern.
Typ 2 - System 2, bewusste Handlungen (Großhirnrinde), Zielsetzung, Analyse, Denken, zusammengesetzte Aufgaben.
KI erreicht bislang nur bei Aufgaben der ersten Art ausreichende Höhen - während es unsere Aufgabe ist, sie auf die zweite zu übertragen, nachdem wir gelernt haben, multidisziplinäre Operationen durchzuführen und mit logischen, kognitiven Fähigkeiten auf hohem Niveau zu arbeiten.
Um dieses Ziel zu erreichen, wird vorgeschlagen:
- Verwenden Sie Aufmerksamkeit als Schlüsselmechanismus für die Modellierung des Denkens in NLP-Aufgaben
- Verwenden Sie Meta-Learning und Repräsentationslernen, um bewusstseinsrelevante Zeichen besser zu modellieren und zu lokalisieren - und wechseln Sie darauf aufbauend in die Arbeit mit übergeordneten Konzepten.
Anstelle der Schlussfolgerung verlassen wir den eingeladenen Vortragseintrag: Benjio ist einer von vielen Wissenschaftlern, die versuchen, das ML-Feld über die Probleme der Optimierung, SOTA und neuer Architekturen hinaus zu erweitern.
Es bleibt die Frage offen, inwieweit die Kombination der Probleme des Bewusstseins, des Einflusses der Sprache auf das Denken, die Neurobiologie und die Algorithmen uns in Zukunft erwartet und es uns ermöglicht, zu Maschinen überzugehen, die wie Menschen „denken“.
Vielen Dank!