Die Datenzuordnung ist eine Möglichkeit, Anwendungscode in Ebenen zu unterteilen. Mapping ist in Android-Anwendungen weit verbreitet. Ein beliebtes Beispiel für die Architektur der mobilen Anwendung Android-CleanArchitecture verwendet das Mapping sowohl in der Originalversion ( ein Beispiel für einen Mapper von CleanArchitecture ) als auch in der neuen Kotlin-Version ( ein Beispiel für einen Mapper ).
Mit der Zuordnung können Sie die Ebenen der Anwendung lösen (z. B. die API entfernen), den Code vereinfachen und visueller gestalten.
Ein Beispiel für eine nützliche Zuordnung ist im Diagramm dargestellt:
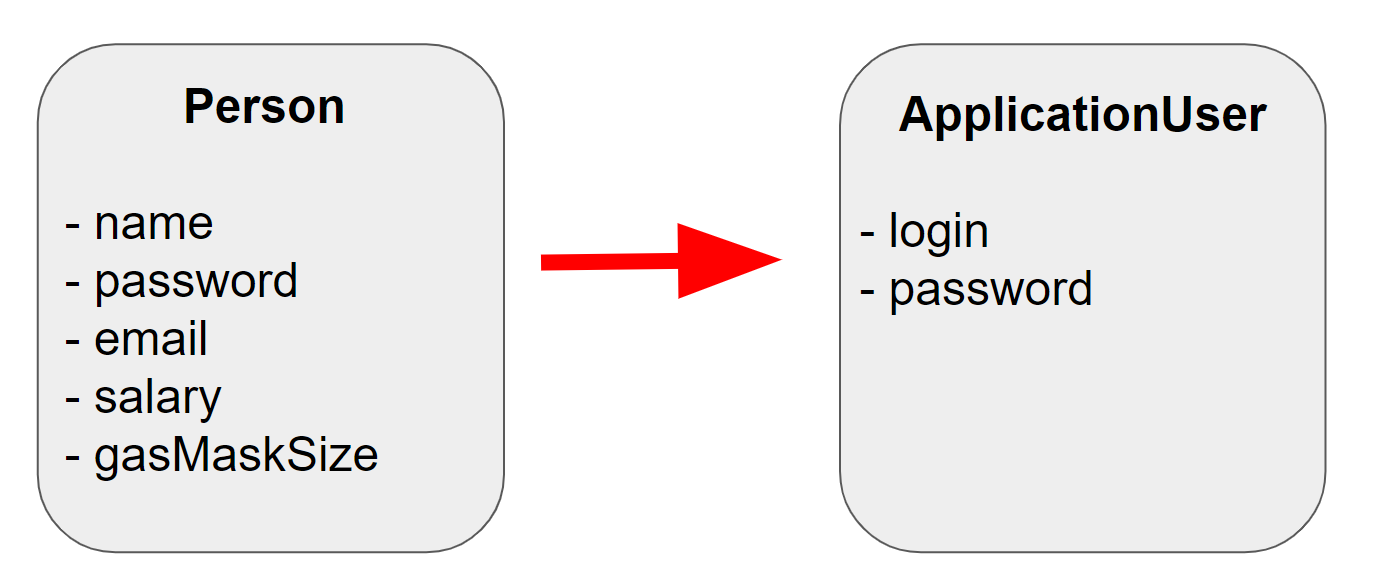
Es müssen nicht alle Felder des Person werden, wenn wir in dem Teil der Anwendung, der uns interessiert, nur zwei Felder benötigen: login und password . Wenn es für uns bequemer ist, Person als Anwendungsbenutzer zu betrachten, können wir nach der Zuordnung problemlos ein Modell mit einem Namen verwenden, den wir verstehen.
Lassen Sie uns anhand des Beispiels der Konvertierung von zwei Person und Salary von der Source in die Destination bequeme und praktische Methoden für die Destination .

Zum Beispiel werden die Modelle vereinfacht. Person enthält Salary in beiden Schichten der Anwendung.
Wenn Sie in diesem Code dasselbe Modell verwenden, empfiehlt es sich möglicherweise, die Ebenen der Anwendung zu überarbeiten und keine Zuordnung zu verwenden.
Methode 1: Mapper-Methoden
Ein Beispiel:
class PersonSrc( private val name: String, private val salary: SalarySrc ) { fun mapToDestination() = PersonDst( name, salary.mapToDestination()
Die schnellste und einfachste Methode. Er wird in CleanArchitecture Kotlin verwendet ( ein Beispiel für die Zuordnung ).
Ein Plus ist die Möglichkeit, Felder auszublenden. Felder in PersonSrc können private . Der Code, der die PersonSrc Klasse verwendet, ist von diesen unabhängig. PersonSrc bedeutet, dass die PersonSrc verringert ist.
Solcher Code ist schneller zu schreiben und einfacher zu ändern - Felddeklarationen und ihre Verwendung sind an einem Ort. Es ist nicht erforderlich, das Projekt zu durchlaufen und verschiedene Dateien zu ändern, wenn Klassenfelder geändert werden.
Diese Option ist jedoch schwieriger zu testen. Die Mapper-Methode der PersonSrc-Klasse PersonSrc Aufruf der Mapper-Methode SalarySrc . Daher ist es schwieriger, nur die Zuordnung von Person ohne Salary testen. Sie müssen dafür Moki verwenden.
Ein weiteres Problem kann auftreten, wenn gemäß den Anforderungen der Architektur die Anwendungsschichten nicht voneinander wissen können: d.h. In der Src Klasse einer Ebene können Sie nicht mit einer Dst Ebene arbeiten und umgekehrt. In diesem Fall kann diese Mapping-Version nicht verwendet werden.
In dem betrachteten Beispiel ist die Src Schicht von der Dst Schicht abhängig und kann Klassen dieser Schicht erstellen. Für die umgekehrte Situation (wenn Dst von Src abhängig ist) ist die Option mit statischen Factory-Methoden geeignet:
class PersonDst( private val name: String, private val salary: SalaryDst ) { companion object { fun fromSource( src: PersonSrc ) = PersonDst(src.name, SalaryDst.fromSource(src.salary)) } } class SalaryDst( private val amount: Int ) { companion object { fun fromSource(src: SalarySrc) = SalaryDst(src.amount) } }
Die Zuordnung erfolgt innerhalb der Klassen des Dst Layers. Dies bedeutet, dass diese Klassen dem Code, der sie verwendet, nicht alle ihre Eigenschaften und Strukturen offenbaren.
Wenn in der Anwendung eine Ebene von der anderen abhängig ist und Daten in beide Richtungen zwischen den Anwendungsebenen übertragen werden, ist es logisch, statische Factory-Methoden zusammen mit Mapper-Methoden zu verwenden.
Zusammenfassung der Zuordnungsmethode:
+ Schreiben Sie schnell Code, Mapping ist immer zur Hand
+ Einfache Änderung
+ Niedrige Code-Konnektivität
- Schwierige Unit-Tests (Moki benötigt)
- Nicht immer von der Architektur erlaubt
Methode 2: Mapper-Funktionen
Modelle:
class PersonSrc( val name: String, val salary: SalarySrc ) class SalarySrc(val amount: Int) class PersonDst( val name: String, val salary: SalaryDst ) class SalaryDst(val amount: Int)
Mapper:
fun mapPerson( src: PersonSrc, salaryMapper: (SalarySrc) -> SalaryDst = ::mapSalary
In diesem Beispiel ist mapPerson eine Funktion höherer Ordnung als Sie bekommt den Mapper für das Salary . Ein interessantes Merkmal des spezifischen Beispiels ist das Standardargument für diese Funktion. Dieser Ansatz ermöglicht es uns, den aufrufenden Code zu vereinfachen und gleichzeitig den Mapper in Komponententests einfach neu zu definieren. Sie können diese Zuordnungsmethode ohne die Standardmethode verwenden und sie immer im aufrufenden Code übergeben.
Es ist nicht immer praktisch, den Mapper und die Klassen, mit denen er arbeitet, an verschiedenen Stellen des Projekts zu platzieren. Bei häufigen Änderungen der Klasse müssen Sie verschiedene Dateien an verschiedenen Orten suchen und ändern.
Diese Zuordnungsmethode erfordert, dass alle Eigenschaften mit Klassendaten für den Mapper sichtbar sind, d. H. private Visibility kann für sie nicht verwendet werden.
Zusammenfassung der Zuordnungsmethode:
+ Einfaches Testen von Einheiten
- Schwierige Änderung
- Erfordert offene Felder für Datenklassen
Methode 3: Erweiterungsfunktionen
Mapper:
fun PersonSrc.toDestination( salaryMapper: (SalarySrc) -> SalaryDst = SalarySrc::toDestination ): PersonDst { return PersonDst(this.name, salaryMapper.invoke(this.salary)) } fun SalarySrc.toDestination(): SalaryDst { return SalaryDst(this.amount) }
Im Allgemeinen identisch mit den Mapper-Funktionen, aber die Syntax des Mapper-Aufrufs ist einfacher: .toDestination() .
Es ist zu beachten, dass Erweiterungsfunktionen aufgrund ihrer statischen Natur zu unerwartetem Verhalten führen können: https://kotlinlang.org/docs/reference/extensions.html#extensions-are-resolved-stratic
Zusammenfassung der Zuordnungsmethode:
+ Einfaches Testen von Einheiten
- Schwierige Änderung
- Erfordert offene Felder für Datenklassen
Methode 4: Mapper-Klassen mit einer Schnittstelle
Funktionsbeispiele haben einen Nachteil. Mit ihnen können Sie jede Funktion mit einer Signatur (SalarySrc) -> SalaryDst . Durch das Vorhandensein der Mapper<SRC, DST> Schnittstelle Mapper<SRC, DST> wird der Code deutlicher.
Ein Beispiel:
interface Mapper<SRC, DST> { fun transform(data: SRC): DST } class PersonMapper( private val salaryMapper: Mapper<SalarySrc, SalaryDst> ) : Mapper<PersonSrc, PersonDst> { override fun transform(src: PersonSrc) = PersonDst( src.name, salaryMapper.transform(src.salary) ) } class SalaryMapper : Mapper<SalarySrc, SalaryDst> { override fun transform(src: SalarrSrc) = SalaryDst( src.amount ) }
In diesem Beispiel ist SalaryMapper eine PersonMapper Abhängigkeit. Auf diese Weise können Sie den Salary Mapper bei Unit-Tests bequem austauschen.
In Bezug auf die Zuordnung in der Funktion weist dieses Beispiel nur einen Nachteil auf - die Notwendigkeit, etwas mehr Code zu schreiben.
Zusammenfassung der Zuordnungsmethode:
+ Besser tippen
- Mehr Code
Wie die Mapper-Funktionen:
+ Einfaches Testen von Einheiten
- Schwierige Änderung
- erfordert offene Felder für Datenklassen
Methode 5: Reflexion
Die Methode der schwarzen Magie. Betrachten Sie diese Methode bei anderen Modellen.
Modelle:
data class EmployeeSrc( val firstName: String, val lastName: String, val age: Int
Mapper:
fun EmployeeSrc.mapWithRef() = with(::EmployeeDst) { val propertiesByName = EmployeeSrc::class.memberProperties.associateBy { it.name } callBy(parameters.associateWith { parameter -> when (parameter.name) { EmployeeDst::name.name -> "$firstName $lastName"
Ein Beispiel wird hier ausspioniert.
In diesem Beispiel speichern EmployeeSrc und EmployeeDst den Namen in verschiedenen Formaten. Mapper muss lediglich einen Namen für das neue Modell vergeben. Die restlichen Felder werden automatisch verarbeitet, ohne Code zu schreiben (die Option else ist when ).
Die Methode kann beispielsweise nützlich sein, wenn Sie große Modelle mit einer Reihe von Feldern haben und die Felder im Grunde genommen für dieselben Modelle aus verschiedenen Ebenen übereinstimmen.
Ein großes Problem entsteht zum Beispiel, wenn Sie die erforderlichen Felder zu Dst hinzufügen und es nicht zufällig in Src oder im Mapper gibt: eine IllegalArgumentException in der Laufzeit. Reflexion hat auch Leistungsprobleme.
Zusammenfassung der Zuordnungsmethode:
+ weniger Code
+ einfacher Unit-Test
- gefährlich
- kann die Leistung beeinträchtigen
Schlussfolgerungen
Solche Schlussfolgerungen können aus unserer Überlegung gezogen werden:
Mapper-Methoden - klarer Code, schneller zu schreiben und zu warten
Mapper- Funktionen und Erweiterungsfunktionen - testen Sie einfach das Mapping.
Mapper-Klassen mit Schnittstelle - testen Sie einfach das Mapping und den klareren Code.
Reflexion - geeignet für Nicht-Standard-Situationen.