Eigentlich hatte ich nicht vor zu sehen, welche Farbe die Eingeweide von Rust hatten. Ich habe ein Hobbyprojekt auf Go aufgegriffen und bin zu GitHub gegangen, um den Stand von fasthttp zu sehen: Entwickelt es sich? Na, zumindest unterstützt? Aufgewachsen. Ging, schaute, wo fasthttp in TechEmpower- Benchmarks sitzt. Ich schaue: und dort zeigt fasthttp kaum die Hälfte dessen, was der Anführer schafft - zu etwas Actix auf etwas Rust. Was für ein Schmerz.
Hier verschränkte ich die Arme, schlug dreimal mit dem Kopf auf den Boden und rief: "Halleluja, wahrlich, Rust ist ein wahrer Gott, wie blind ich vorher war!" Aber entweder haben die Griffe nicht funktioniert, oder die Stirn hat es bereut ... Stattdessen habe ich mich mit dem Code der Tests befasst, der in Go und den Actix-Web-Tests in Rust geschrieben wurde. Um es zu klären.
Nach ein paar Stunden fand ich heraus:
- warum actix-web Rust framework bei allen TechEmpower-Tests an erster Stelle steht,
- wie Java startet Script.
Jetzt erzähle ich dir alles in der richtigen Reihenfolge.
Was ist der TechEmpower Framework Benchmark?
Wenn ein Web-Framework demonstriert, ob es "Ich bin schnell" an Freunde flüstert oder beispielsweise darüber nachdenkt, dies zu tun, fällt es mit Sicherheit in den TechEmpower Framework-Benchmark. Ein beliebter Ort, um die Leistung zu messen.
Die Website hat ein eigenartiges Design: Die Registerkarten mit Filtern, Runden, Bedingungen und Ergebnissen für verschiedene Testarten sind mit großzügiger Hand auf der Seite verteilt. So großzügig und mitreißend, dass Sie sie einfach nicht bemerken. Es lohnt sich jedoch, auf die Registerkarten zu klicken. Die Informationen dahinter sind hilfreich.
Am einfachsten ist es, die Klartext-Testergebnisse "Hello World!" für Webserver. Die Autoren des Frameworks geben in der Regel einen Link dazu an: Wir bleiben angeblich in den ersten hundert. Der Fall ist richtig und nützlich. Im Allgemeinen ist es für viele gut, Klartext zu verschenken, und die Führungskräfte bilden eine enge Gruppe.
In diesen Registerkarten werden die Ergebnisse von Tests anderer Typen (Szenarien) angezeigt. Es gibt sieben davon, weitere Details finden Sie hier . Diese Skripte testen nicht nur, wie das Framework / die Plattform die Verarbeitung einer einfachen http-Anforderung handhabt, sondern auch eine Kombination mit einem Datenbank-Client, einer Vorlagen-Engine oder einem JSON-Serializer.
In einer virtuellen Umgebung befinden sich Testdaten auf einer physischen Hardware. Neben Grafiken gibt es tabellarische Daten. In der Regel eine Menge interessanter Dinge, lohnt es sich zu graben, nicht nur auf die Position von "Ihrer" Plattform zu schauen.
Das erste, woran ich dachte, nachdem ich die Testergebnisse durchgesehen hatte: "Warum unterscheidet sich alles so sehr von Klartext?!". Im Klartext befinden sich die Führungskräfte in einer engen Gruppe, aber wenn es um die Arbeit mit der Datenbank geht, liegt actix-web deutlich vorne. Gleichzeitig zeigt es eine stabile Anforderungsbearbeitungszeit. Shaitan.
Eine weitere Anomalie: eine unglaublich leistungsstarke JavaScript-Lösung. Es heißt ex4x. Es stellte sich heraus, dass sein Code etwas weniger als vollständig in Java geschrieben war. Wird von Java Runtime, JDBC, verwendet. JavaScript-Code wird in Bytecode übersetzt und klebt Java-Bibliotheken. Sie haben es buchstäblich genommen - und Script an Java angehängt. Den Tricks der blassen Gesichter sind keine Grenzen gesetzt.
Wie man den Code ansieht und was drin ist
Der Code für alle Tests ist auf GitHub. Alles befindet sich in einem einzigen Repository, was sehr praktisch ist. Du kannst klonen und schauen, du kannst direkt auf GitHub schauen. Das Testen umfasst mehr als 300 verschiedene Kombinationen des Frameworks mit Serialisierern, Template-Engines und dem Datenbank-Client. In verschiedenen Programmiersprachen, mit einer anderen Herangehensweise an die Entwicklung. Implementierungen in einer Sprache sind in der Nähe, sie können mit Implementierungen in anderen Sprachen verglichen werden. Der Code wird von der Community gepflegt und ist nicht die Arbeit einer Person oder eines Teams.
Der Benchmark-Code ist ein großartiger Ort, um Ihren Horizont zu erweitern. Es ist interessant zu analysieren, wie verschiedene Personen die gleichen Probleme lösen. Es gibt nicht viel Code, die verwendeten Bibliotheken und Lösungen sind leicht zu unterscheiden. Ich bereue überhaupt nicht, dass ich dort angekommen bin. Ich habe viel gelernt. Zuallererst über Rust.
Vor Rust hatte ich eine sehr vage Idee. In jedem Artikel über C, C ++, D und insbesondere Go gibt es mit Sicherheit ein paar Kommentatoren, die ausführlich und mit Sorge erklären, dass Eitelkeit, Unsinn und Dummheit in etwas anderem geschrieben sind, solange es etwas gibt Gascogne Rust. Manchmal werden sie so sehr mitgerissen, dass sie Codebeispiele geben als eine unvorbereitete Person oder wenige akzeptieren verblüfft: "Warum, warum, warum all diese Symbole?!"
Daher war das Öffnen des Codes beängstigend.
Ich habe geschaut. Es stellte sich heraus, dass Programme in Rust gelesen werden können. Außerdem ist der Code so gut gelesen, dass ich sogar Rust installiert, versucht habe, den Test zu kompilieren und ein bisschen daran zu basteln.
Hier habe ich dieses Geschäft fast aufgegeben, weil die Zusammenstellung eine lange Zeit dauert. Sehr lang. Wenn ich D'Artagnan wäre oder nur ein Choleriker, wäre ich in die Gascogne gelaufen, und tausend Teufel wären niedergeschlagen. Aber ich habe es geschafft. Ich habe wieder Tee getrunken. Es scheint, dass nicht einmal eine Tasse: Auf meinem Laptop hat die erste Zusammenstellung etwa 20 Minuten gedauert, dann macht aber alles mehr Spaß. Vielleicht bis zu den nächsten großen Update-Kisten.
Aber ist es nicht Rust selbst?
Nein. Keine Programmiersprache.
Natürlich ist Rust eine wunderbare Sprache. Kraftvoll, flexibel, wenn auch aus Gewohnheit und wortreich. Aber die Sprache selbst wird keinen schnellen Code schreiben. Die Sprache ist eines der Werkzeuge, eine der Entscheidungen, die der Programmierer trifft.
Wie gesagt - Klartext zu verschenken ist für viele schnell erledigt. Die Leistung von actix-web, fasthttp und einem Dutzend anderer Frameworks bei der Verarbeitung einer einfachen Anfrage ist durchaus vergleichbar, dh andere Sprachen haben die technische Fähigkeit, mit Rust zu konkurrieren.
Actix-web selbst ist natürlich „schuld“: ein schnelles, pragmatisches, exzellentes Produkt. Die Serialisierung ist praktisch, die Template-Engine ist gut - sie hilft auch sehr.
Insbesondere unterscheiden sich die Ergebnisse von Tests, die mit der Datenbank arbeiten.
Nachdem ich mich ein wenig in den Code eingearbeitet hatte, stellte ich drei Hauptunterschiede heraus, die (meiner Meinung nach) dazu beigetragen haben, dass sich Actix-Tests bei synthetischen Tests von der Konkurrenz abheben:
- Pipelined Pipelined Tokio-Postgres-Betriebsmodus;
- Verwenden einer einzelnen Verbindung mit einem Rust-Test anstelle eines Verbindungspools mit einem in Go geschriebenen Test.
- Aktualisieren von Actix-Benchmarks mit einem einzigen Befehl, der über eine einfache Abfrage gesendet wird, anstatt mehrere UPDATE-Befehle zu senden.
Was für ein Fördermodus?
Hier ist ein Ausschnitt aus der tokio-postgres-Dokumentation (die im Benchmark der PostgreSQL-Clientbibliothek verwendet wird), der erklärt, was die Entwickler damit meinen:
Sequential Pipelined | Client | PostgreSQL | | Client | PostgreSQL | |----------------|-----------------| |----------------|-----------------| | send query 1 | | | send query 1 | | | | process query 1 | | send query 2 | process query 1 | | receive rows 1 | | | send query 3 | process query 2 | | send query 2 | | | receive rows 1 | process query 3 | | | process query 2 | | receive rows 2 | | | receive rows 2 | | | receive rows 3 | | | send query 3 | | | | process query 3 | | receive rows 3 | |
Der Client im Pipelined-Modus (Pipelined-Modus) wartet nicht auf eine PostgreSQL-Antwort, sondern sendet die nächste Abfrage, während PostgreSQL die vorherige verarbeitet. Es ist ersichtlich, dass Sie auf diese Weise dieselbe Sequenz von Datenbankabfragen erheblich schneller verarbeiten können.
Wenn die Verbindung im Pipeline-Modus Duplex ist (was die Möglichkeit bietet, Ergebnisse parallel zum Senden zu erhalten), kann sich diese Zeit geringfügig verkürzen. Es scheint, dass es bereits eine experimentelle Version von tokio-postgres gibt, bei der eine Duplexverbindung geöffnet ist.
Da der PostgreSQL-Client mehrere Nachrichten (Parse, Bind, Execute und Sync) an jede zur Ausführung gesendete SQL-Abfrage sendet und eine Antwort darauf erhält, ist der Pipeline-Modus auch bei der Verarbeitung einzelner Abfragen effektiver.
Und warum ist es nicht in Go?
Da Go normalerweise Datenbankverbindungspools verwendet. Verbindungen sind nicht zur parallelen Verwendung vorgesehen.
Wenn Sie dieselben SQL-Abfragen über einen Pool und nicht über eine Verbindung ausführen, können Sie theoretisch mit einem normalen seriellen Client eine noch kürzere Ausführungszeit erzielen, als wenn Sie über eine einzelne Verbindung arbeiten, sei es dreimal per Pipeline:
| Connection | Connection 2 | Connection 3 | PostgreSQL | |----------------|----------------|----------------|-----------------| | send query 1 | | | | | | send query 2 | | process query 1 | | receive rows 1 | | send query 3 | process query 2 | | | receive rows 2 | | process query 3 | | | receive rows 3 | |
Es sieht so aus, als ob das Schaffell (Förderer-Modus) die Kerze nicht wert ist.
Nur unter hoher Last kann die Anzahl der Verbindungen zum PostgreSQL-Server ein Problem sein.
Und was hat die Anzahl der Verbindungen damit zu tun?
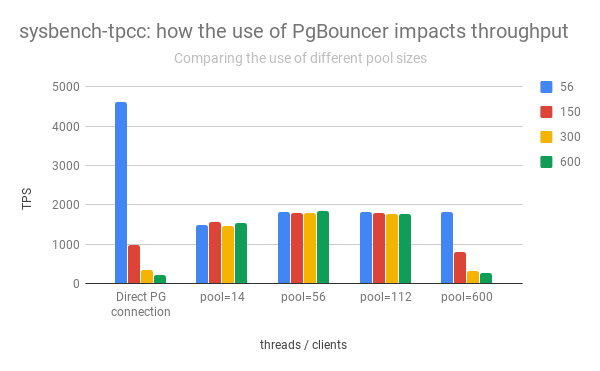
Hier geht es darum, wie der PostgreSQL-Server auf eine Zunahme der Anzahl von Verbindungen reagiert.
Die linke Spaltengruppe zeigt den Anstieg und Abfall der PostgreSQL-Leistung in Abhängigkeit von der Anzahl der offenen Verbindungen:
( Nach Percona-Post )
Es ist zu erkennen, dass mit zunehmender Anzahl offener Verbindungen die Leistung des PostgreSQL-Servers rapide abnimmt.
Darüber hinaus ist das Öffnen einer direkten Verbindung nicht "kostenlos". Unmittelbar nach dem Öffnen sendet der Client Dienstinformationen, "stimmt" mit dem PostgreSQL-Server überein, wie die Anforderungen verarbeitet werden.
In der Praxis müssen Sie daher die Anzahl der aktiven Verbindungen zu PostgreSQL begrenzen und diese häufig zusätzlich über pgbouncer oder eine andere Odyssee weiterleiten.
Warum war actix-web schneller?
Zunächst einmal ist actix-web selbst verdammt schnell. Er setzt die „Obergrenze“ fest und ist etwas höher als die der anderen. Andere verwendete Bibliotheken (serde, yarde) sind ebenfalls sehr, sehr produktiv. In Tests mit PostgreSQL schien es mir jedoch möglich zu sein, das Problem zu lösen, da der Actix-Web-Server einen Thread auf dem Prozessorkern startet. Jeder Thread öffnet nur eine Verbindung zu PostgreSQL.
Je weniger Verbindungen aktiv sind, desto schneller funktioniert PostgreSQL (siehe Grafik oben).
Der Client, der im Pipeline-Modus (tokio-postgres) arbeitet, ermöglicht es Ihnen, eine Verbindung mit PostgreSQL effektiv für die parallele Verarbeitung von Benutzeranfragen zu verwenden. HTTP-Request-Handler speichern ihre SQL-Befehle in einer Warteschlange und richten sie in einer anderen aus, um Ergebnisse zu erhalten. Die Ergebnisse machen Spaß, die Verzögerungen sind minimal, alle sind glücklich. Die Gesamtleistung ist höher als bei einem System mit einem Verbindungspool.
Sie müssen also den Pool verlassen, einen PostgreSQL-Pipeline-Client schreiben, und das Glück und die unglaubliche Geschwindigkeit werden sofort kommen?
Möglicherweise. Aber nicht auf einmal.
Wenn es unwahrscheinlich ist, dass der Fördermodus speichert, und sicherlich nicht speichert
Das im Benchmark-Code verwendete Schema funktioniert nicht mit PostgreSQL-Transaktionen.
In der Benchmark werden keine Transaktionen benötigt und der Code wird unter Berücksichtigung der Tatsache geschrieben, dass keine Transaktionen stattfinden. In der Praxis passieren sie.
Wenn der Backend-Code eine PostgreSQL-Transaktion öffnet (um beispielsweise zwei verschiedene Tabellen atomar zu ändern), werden alle über diese Verbindung gesendeten Befehle innerhalb dieser Transaktion ausgeführt.
Da die Verbindung mit PostgreSQL parallel genutzt wird, gerät alles durcheinander. Die Befehle, die in einer vom Entwickler entworfenen Transaktion ausgeführt werden sollen, werden mit SQL-Befehlen gemischt, die von parallelen HTTP-Request-Handlern initiiert werden. Wir erhalten zufällige Datenverluste und Probleme mit deren Integrität.
Also hallo Transaktion - auf Wiedersehen parallele Nutzung einer Verbindung. Sie müssen sicherstellen, dass die Verbindung nicht von anderen HTTP-Request-Handlern verwendet wird. Sie müssen entweder die Verarbeitung eingehender http-Anforderungen beenden, bevor Sie die Transaktion schließen, oder einen Pool für Transaktionen verwenden, um mehrere Verbindungen zum Datenbankserver herzustellen. Es gibt mehrere Pool-Implementierungen für Rust und keine. Darüber hinaus existieren sie in Rust getrennt von der Datenbank-Client-Implementierung. Sie können nach Geschmack, Farbe, Geruch oder nach Belieben wählen. Go funktioniert so nicht. Die Kraft der Generika, ja.
Ein wichtiger Punkt: Im Test, dessen Code ich sah, werden keine Transaktionen geöffnet. Diese Frage ist es einfach nicht wert. Der Benchmark-Code ist für eine bestimmte Aufgabe und sehr spezielle Betriebsbedingungen der Anwendung optimiert. Die Entscheidung, eine Verbindung pro Server-Stream zu verwenden, wurde wahrscheinlich bewusst getroffen und erwies sich als sehr effektiv.
Gibt es noch etwas Interessantes im Benchmark-Code?
Ja
Das Szenario zur Leistungsmessung ist sehr detailliert beschrieben. Sowie die Kriterien, die der an den Tests teilnehmende Code erfüllen muss. Eine davon ist, dass alle Abfragen an den Datenbankserver nacheinander ausgeführt werden müssen.
Das folgende (leicht abgekürzte) Codefragment scheint die Kriterien nicht zu erfüllen:
let mut worlds = Vec::with_capacity(num);
Alles sieht aus wie ein typischer Start von parallelen Prozessen. Da jedoch eine Verbindung zu PostgreSQL verwendet wird, werden Abfragen an den Datenbankserver nacheinander gesendet. Eins nach dem anderen. Wie erforderlich. Kein Verbrechen.
Warum so? Nun, erstens wird in dem Code (der in der Redaktion, die in der 18. Runde arbeitete, angegeben wurde) async / await noch nicht verwendet, er erschien später in Rust. Und durch Futures num es einfacher, SQL-Abfragen "parallel" zu senden - wie im obigen Code. Auf diese Weise können Sie eine zusätzliche Leistungssteigerung erzielen: Während PostgreSQL die erste SQL-Abfrage akzeptiert und verarbeitet, wird der Rest an PostgreSQL weitergeleitet. Der Webserver wartet nicht auf das Ergebnis der einzelnen Tasks, sondern wechselt zu anderen Tasks und kehrt erst dann zur Verarbeitung der http-Anforderung zurück, wenn alle SQL-Abfragen abgeschlossen sind.
Für PostgreSQL besteht der Bonus darin, dass dieselbe Art von Abfrage im selben Kontext (Verbindung) hintereinander ausgeführt wird. Die Wahrscheinlichkeit, dass der Abfrageplan nicht wiederhergestellt wird, steigt.
Es stellt sich heraus, dass die Vorteile des Pipeline-Modus (siehe das Diagramm aus der tokio-postgres-Dokumentation) auch bei der Verarbeitung einer einzelnen http-Anforderung voll ausgenutzt werden.
Was sonst?
Verwenden des einfachen Abfrageprotokolls für Stapelaktualisierungen
Das Kommunikationsprotokoll zwischen dem Client und dem PostgreSQL-Server ermöglicht alternative Methoden zum Ausführen von SQL-Befehlen. Das übliche Protokoll (Extended Query) umfasst das Senden mehrerer Nachrichten an einen Client: Parse, Bind, Execute und Sync. Eine Alternative ist das Simple Query-Protokoll, nach dem eine einzige Nachricht ausreicht, um einen Befehl auszuführen und Ergebnisse zu erhalten - Query.
Der Hauptunterschied zwischen den üblichen Protokollen besteht in der Übertragung der Anforderungsparameter: Sie werden getrennt vom Befehl selbst übertragen. Es ist sicherer. Das vereinfachte Protokoll geht davon aus, dass alle Parameter der SQL-Abfrage in eine Zeichenfolge konvertiert und im Hauptteil der Abfrage enthalten sind.
Eine interessante Lösung für die actix-web-Benchmarks bestand darin, mehrere Tabelleneinträge mit einem einzigen Befehl zu aktualisieren, der über das Simple Query-Protokoll gesendet wurde.
Gemäß dem Benchmark muss der Webserver bei der Verarbeitung einer Benutzeranforderung mehrere Datensätze in der Tabelle aktualisieren und Zufallszahlen schreiben. Offensichtlich dauert das Aktualisieren von Datensätzen nacheinander mit sequentiellen Abfragen länger als das Aktualisieren aller Datensätze auf einmal.
Die im Testcode generierte Anfrage sieht ungefähr so aus:
UPDATE world SET randomnumber = temp.randomnumber FROM (VALUES (1, 2), (2, 3) ORDER BY 1) AS temp(id, randomnumber) WHERE temp.id = world.id
Wobei (1, 2), (2, 3) die Zeilenbezeichnerpaare / neuer Wert des Zufallszahlenfeldes sind.
Die Anzahl der aktualisierten Datensätze ist variabel. Das Vorbereiten einer (PREPARE) -Anforderung im Voraus ist nicht sinnvoll. Da es sich bei den zu aktualisierenden Daten um numerische Daten handelt und der Quelle vertraut werden kann (dem Testcode selbst), besteht keine Gefahr der SQL-Injection. Die Daten werden einfach in den SQL-Body aufgenommen und alles wird mithilfe des Simple Query-Protokolls gesendet.
Einfache Abfrage wird gemunkelt. Ich traf eine Empfehlung: "Arbeiten Sie nur am Simple Query-Protokoll, und alles wird schnell und gut." Ich nehme sie mit großer Skepsis wahr. Mit der einfachen Abfrage können Sie die Anzahl der an den PostgreSQL-Server gesendeten Nachrichten verringern, indem Sie die Verarbeitung der Abfrageparameter auf die Clientseite verlagern. Sie können den Gewinn für dynamisch generierte Abfragen mit einer variablen Anzahl von Parametern sehen. Bei der gleichen Art von SQL-Abfragen (die häufiger vorkommen) ist der Gewinn nicht offensichtlich. Gut und wie sicher die Verarbeitung von Abfrageparametern sein wird, bestimmt im Fall von Simple Query die Implementierung der Clientbibliothek.
Wie ich oben geschrieben habe, wird in diesem Fall der Hauptteil der SQL-Abfrage dynamisch generiert, die Daten sind numerisch und werden vom Server selbst generiert. Die perfekte Kombination für Simple Query. Aber auch in diesem Fall lohnt es sich, andere Optionen zu testen. Alternativen hängen von der PostgreSQL-Plattform und dem Client ab: pgx (der Client für Go) ermöglicht das Senden eines Befehlspakets, JDBC - um einen Befehl mehrmals hintereinander mit verschiedenen Parametern auszuführen. Beide Lösungen können mit der gleichen Geschwindigkeit ausgeführt werden oder sogar schneller sein.
Warum führt Rust?
Der Anführer ist natürlich nicht Rust. Tests, die auf actix-web basieren, sind führend - er setzt die "Obergrenze" der Leistung. Es gibt zum Beispiel Raketen und Eisen, die bescheidene Stellungen einnehmen. Aber im Moment ist es actix-web, das das Potenzial für den Einsatz von Rust in der Webentwicklung bestimmt. Für mich ist das Potenzial sehr hoch.
Ein weiterer nicht offensichtlicher, aber wichtiger "geheimer" Server auf Basis von actix-web, der in allen TechEmpower-Benchmarks den ersten Platz belegte - wie es mit PostgreSQL funktioniert:
- Pro Webserver-Stream wird nur eine Verbindung mit PostgreSQL geöffnet. Diese Verbindung verwendet den Pipeline-Modus, mit dem Benutzeranforderungen effektiv parallel verarbeitet werden können.
- Je weniger aktive Verbindungen vorhanden sind, desto schneller reagiert PostgreSQL. Die Geschwindigkeit der Verarbeitung von Benutzeranforderungen nimmt zu. Gleichzeitig arbeitet das gesamte System unter Last stabiler (Verzögerungen bei der Verarbeitung eingehender Anforderungen sind geringer, sie wachsen langsamer).
Wenn Geschwindigkeit wichtig ist, ist diese Option wahrscheinlich schneller als die Verwendung von Multiplexern (wie pgbouncer und odyssey). Und sicherlich war er in den Benchmarks schneller.
Es ist sehr interessant, wie sich Async / Warten, das in Rust aufgetaucht ist, und das jüngste Drama mit Actix-Web auf die Popularität von Rust in der Webentwicklung auswirken. Es ist auch interessant, wie sich die Testergebnisse ändern, wenn sie asynchron verarbeitet werden.