Wir werden uns ansehen, wie Zabbix mit der TimescaleDB-Datenbank als Backend arbeitet. Wir zeigen, wie Sie bei Null anfangen und wie Sie mit PostgreSQL migrieren. Wir geben auch vergleichende Leistungstests der beiden Konfigurationen.

HighLoad ++ Sibirien 2019. Tomsk Hall. 24. Juni, 16:00 Uhr. Abstracts und
Präsentation . Die nächste HighLoad ++ Konferenz findet am 6. und 7. April 2020 in St. Petersburg statt. Details und Tickets
hier .
Andrey Gushchin (im Folgenden als
AG bezeichnet): - Ich bin ein ZABBIX Technical Support Engineer (im Folgenden als Zabbix bezeichnet), ein Trainer. Ich arbeite seit mehr als 6 Jahren im technischen Support und wurde direkt mit der Leistung konfrontiert. Heute werde ich über die Leistung sprechen, die TimescaleDB im Vergleich zu regulärem PostgreSQL 10 bieten kann. Außerdem ein einleitender Teil - darüber, wie es funktioniert.
Wichtige Leistungsherausforderungen: Von der Erfassung bis zur Datenbereinigung
Zunächst gibt es bestimmte Leistungsprobleme, mit denen jedes Überwachungssystem konfrontiert ist. Die erste Leistungsherausforderung ist die schnelle Erfassung und Verarbeitung von Daten.

Ein gutes Überwachungssystem sollte alle Daten umgehend und rechtzeitig empfangen, gemäß den Auslösungsausdrücken verarbeiten, dh nach bestimmten Kriterien verarbeiten (in verschiedenen Systemen ist dies anders) und in der Datenbank speichern, um diese Daten in Zukunft verwenden zu können.

Die zweite Herausforderung besteht darin, Geschichte zu schreiben. Speichern Sie häufig in der Datenbank und greifen Sie schnell und bequem auf diese Kennzahlen zu, die über einen bestimmten Zeitraum hinweg erfasst wurden. Das Wichtigste ist, dass es bequem ist, diese Daten abzurufen, sie in Berichten, Diagrammen, Triggern, in einigen Schwellenwerten, für Warnungen usw. zu verwenden.

Die dritte Leistungsherausforderung besteht darin, die Story zu klären. Das heißt, wenn Ihr Tag so ist, dass Sie keine detaillierten Messdaten speichern müssen, die über einen Zeitraum von 5 Jahren (sogar Monaten oder zwei Monaten) erfasst wurden. Einige Netzwerkknoten wurden gelöscht, andere Hosts werden nicht mehr benötigt, da sie bereits veraltet sind und nicht mehr erfasst werden. All dies muss bereinigt werden, damit Ihre Datenbank nicht zu groß wird. Im Allgemeinen ist das Löschen des Verlaufs häufig ein schwerwiegender Test für den Speicher - sehr oft wirkt sich dies auf die Leistung aus.
Wie löse ich Caching-Probleme?
Ich werde jetzt speziell über den Zabbix sprechen. In Zabbix werden der erste und der zweite Anruf mithilfe der Zwischenspeicherung aufgelöst.

Datenerhebung und -verarbeitung - Wir verwenden RAM, um all diese Daten zu speichern. Nun werden diese Daten detaillierter besprochen.
Auch auf der Datenbankseite gibt es eine bestimmte Zwischenspeicherung für die Hauptbeispiele - für Diagramme und andere Dinge.
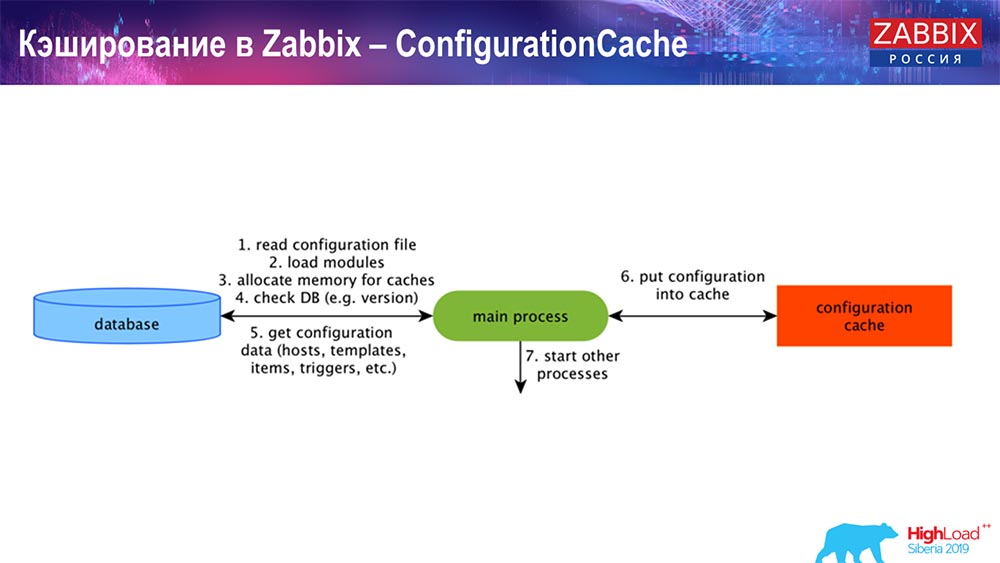
Caching auf der Seite des Zabbix-Servers selbst: Wir haben ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Was ist das?

ConfigurationCache ist der Hauptcache, in dem Metriken, Hosts, Datenelemente und Trigger gespeichert werden. Alles, was Sie zur Verarbeitung der Vorverarbeitung benötigen, Daten sammeln, von welchen Hosts mit welcher Häufigkeit Daten gesammelt werden sollen. All dies wird in ConfigurationCache gespeichert, um nicht in die Datenbank zu gelangen und keine unnötigen Anforderungen zu erstellen. Nachdem der Server gestartet wurde, aktualisieren wir diesen Cache (erstellen) und aktualisieren ihn regelmäßig (abhängig von den Konfigurationseinstellungen).
Caching in Zabbix. Datenerfassung
Hier ist das Schema ziemlich groß:

Die wichtigsten im Schema sind diese Sammler:
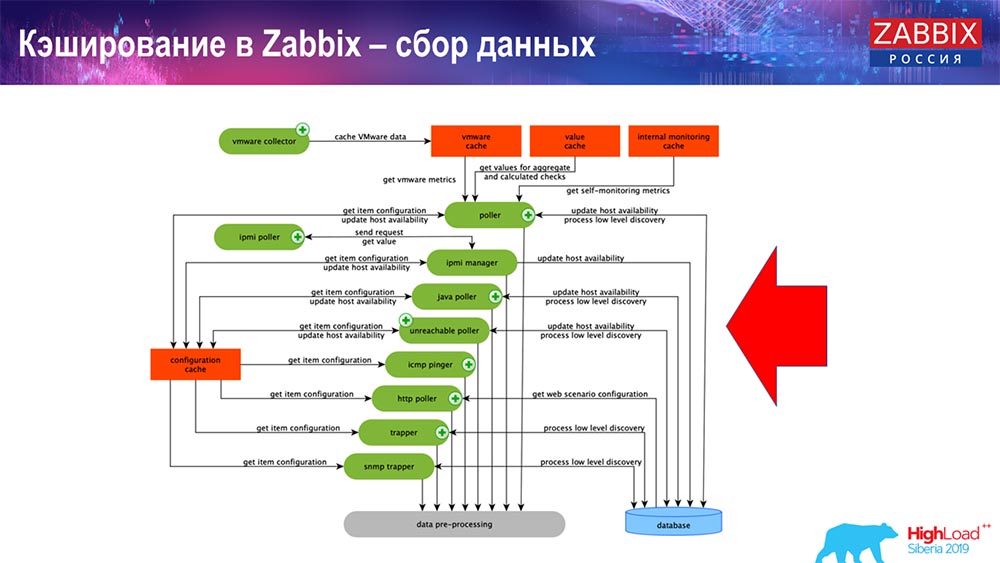
Dies sind die Montagevorgänge selbst, verschiedene "Pollers", die für verschiedene Arten von Baugruppen verantwortlich sind. Sie sammeln Daten über icmp, ipmi, nach unterschiedlichen Protokollen und übermitteln sie an die Vorverarbeitung.
PreProcessing HistoryCache
Wenn wir Datenelemente berechnet haben (wer Zabbix kennt - weiß), dh berechnete, aggregierte Datenelemente, beziehen wir sie direkt aus ValueCache. Wie es gefüllt ist, werde ich später erzählen. Alle diese Kollektoren verwenden ConfigurationCache, um ihre Jobs abzurufen und sie dann an die Vorverarbeitung weiterzuleiten.
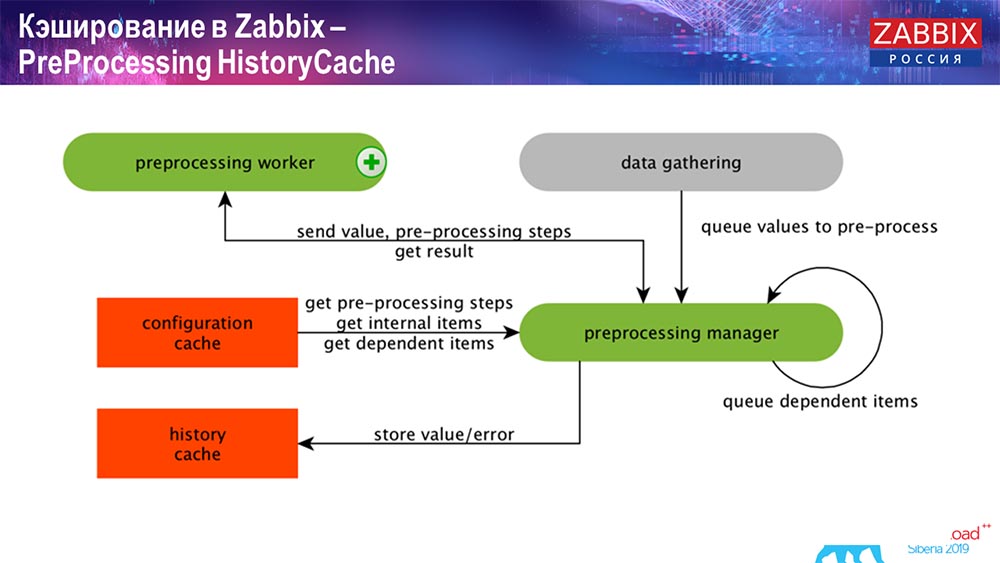
Die Vorverarbeitung verwendet auch ConfigurationCache, um Vorverarbeitungsschritte abzurufen, und verarbeitet diese Daten auf verschiedene Arten. Ab Version 4.2 haben wir es dem Proxy übermittelt. Dies ist sehr praktisch, da die Vorverarbeitung selbst ein ziemlich schwieriger Vorgang ist. Und wenn Sie einen sehr großen "Zabbix" mit einer großen Anzahl von Datenelementen und einer hohen Häufigkeit der Erfassung haben, erleichtert dies die Arbeit erheblich.
Dementsprechend speichern wir diese Daten in HistoryCache, nachdem wir sie in einer Vorverarbeitung auf irgendeine Weise verarbeitet haben, um sie weiterzuverarbeiten. Damit ist die Datenerfassung beendet. Wir gehen weiter zum Hauptprozess.
Verlaufssynchronisation
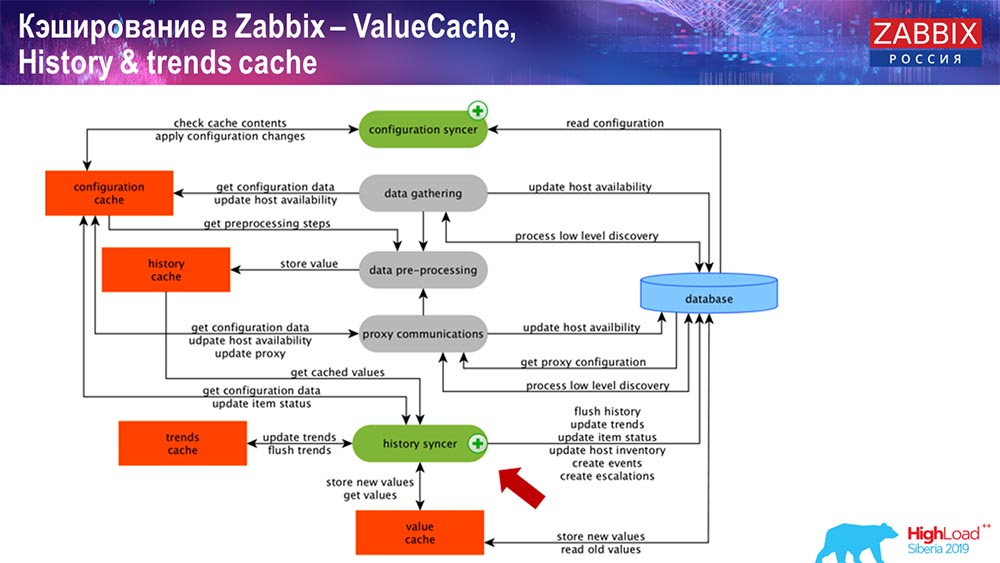
Der Hauptprozess in Zabbix (da es sich um eine monolithische Architektur handelt) ist History Syncer. Dies ist der Hauptprozess, der sich speziell mit der atomaren Verarbeitung jedes Datenelements, dh jedes Werts, befasst:
- value kommt (es nimmt es von HistoryCache);
- Überprüft in Configuration Syncer: Gibt es Trigger für die Berechnung? Berechnet sie;
Wenn dies der Fall ist, werden Ereignisse erstellt, und es wird eine Eskalation erstellt, um eine Warnung zu erstellen, falls dies durch die Konfiguration erforderlich ist. - zeichnet Trigger für die nachfolgende Verarbeitung, Aggregation auf; Wenn Sie in der letzten Stunde usw. aggregieren, merkt sich dieser Wert ValueCache, um nicht zur Verlaufstabelle zu wechseln. Somit wird ValueCache mit den erforderlichen Daten gefüllt, die für die Berechnung von Triggern, berechneten Elementen usw. erforderlich sind.
- Dann schreibt History Syncer alle Daten in die Datenbank.
- Die Datenbank schreibt sie auf die Festplatte - hier endet der Verarbeitungsprozess.
Datenbanken Caching
Auf der DB-Seite gibt es verschiedene Caches, wenn Sie sich Diagramme oder Ereignisberichte ansehen möchten. Im Rahmen dieses Berichts werde ich jedoch nicht darauf eingehen.
Für MySQL gibt es Innodb_buffer_pool, eine Reihe verschiedener Caches, die ebenfalls konfiguriert werden können.
Aber das sind die wichtigsten:
- shared_buffer;
- effective_cache_size;
- shared_pool.

Ich habe für alle Datenbanken angegeben, dass es bestimmte Caches gibt, mit denen Sie die Daten, die häufig für Abfragen benötigt werden, im Speicher behalten können. Dort haben sie ihre eigenen Technologien dafür.
Informationen zur Datenbankleistung
Dementsprechend gibt es ein Wettbewerbsumfeld, dh der Zabbix-Server sammelt Daten und zeichnet sie auf. Beim Neustart wird auch aus dem Verlauf gelesen, um ValueCache usw. zu füllen. Hier können Sie Skripte und Berichte erstellen, die die Zabbix-API verwenden, die auf der Grundlage der Weboberfläche erstellt wurde. "Zabbiks" -API ist in der Datenbank enthalten und erhält die notwendigen Daten, um Grafiken, Berichte oder eine Liste von Ereignissen und kürzlich aufgetretenen Problemen zu erhalten.

Eine ebenfalls sehr beliebte Visualisierungslösung ist Grafana, die von unseren Benutzern verwendet wird. Kann sowohl über die "Zabbiks" -API als auch über die Datenbank direkt eingegeben werden. Dies schafft auch einen gewissen Wettbewerb um den Erhalt von Daten: Eine feinere und bessere Abstimmung der Datenbank ist erforderlich, um der schnellen Übermittlung von Ergebnissen und Tests zu entsprechen.

Verlauf löschen. Zabbix hat eine Haushälterin
Die dritte Herausforderung von Zabbix besteht darin, die Geschichte mit der Haushälterin zu klären. Hauskiper erfüllt alle Einstellungen, dh in unseren Datenelementen wird angegeben, wie viel (in Tagen) gespeichert werden soll, wie viel Trends gespeichert werden sollen, wie dynamisch Änderungen sind.
Ich habe nicht über TrendCache gesprochen, den wir im laufenden Betrieb berechnen: Die Daten kommen an, wir aggregieren sie in einer Stunde (im Grunde sind dies die Zahlen für die letzte Stunde), die durchschnittliche / minimale Menge und schreiben sie einmal pro Stunde in die Tabelle der Dynamik von Änderungen (Trends). . Hauskiper startet und löscht Daten aus der Datenbank mit regulären Auswahlen, was nicht immer effektiv ist.
Wie kann man verstehen, dass es ineffizient ist? In den Leistungsdiagrammen der internen Prozesse sehen Sie folgendes Bild:
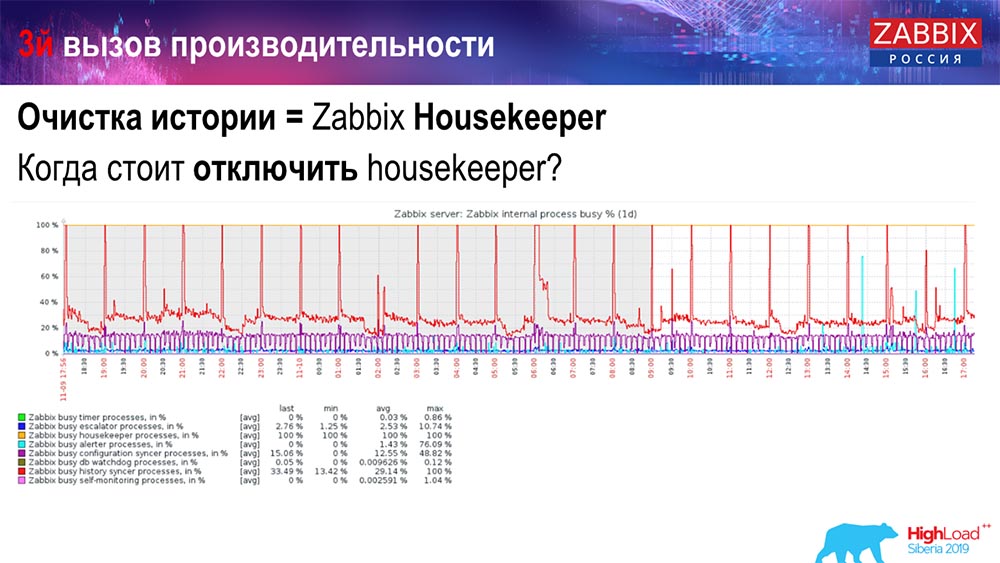
Ihr Verlaufssynchronisator ist ständig beschäftigt (rotes Diagramm). Und das "rote" Diagramm, das oben draufsteht. Dies ist der Hauskiper, der startet und auf die Datenbank wartet, wenn er alle angegebenen Zeilen löscht.
Nehmen Sie eine Item ID: Sie müssen die letzten 5 Tausend löschen; Natürlich nach Indizes. In der Regel ist der Datensatz jedoch groß genug - die Datenbank liest ihn immer noch von der Festplatte und legt ihn im Cache ab. Dies ist eine sehr teure Operation für die Datenbank. Dies kann je nach Größe zu Performance-Problemen führen.
Sie können Hauskiper auf einfache Weise deaktivieren - wir haben für jeden eine vertraute Weboberfläche. Unter Administration general (Einstellungen für „Housekeeper“) deaktivieren wir die interne Verwaltung für interne Verlaufsdaten und Trends. Dementsprechend kontrolliert Hauskiper dies nicht mehr:

Was kann ich als nächstes tun? Sie haben die Verbindung getrennt, Ihre Zeitpläne wurden verbessert ... Welche Probleme können in diesem Fall noch auftreten? Was kann helfen?
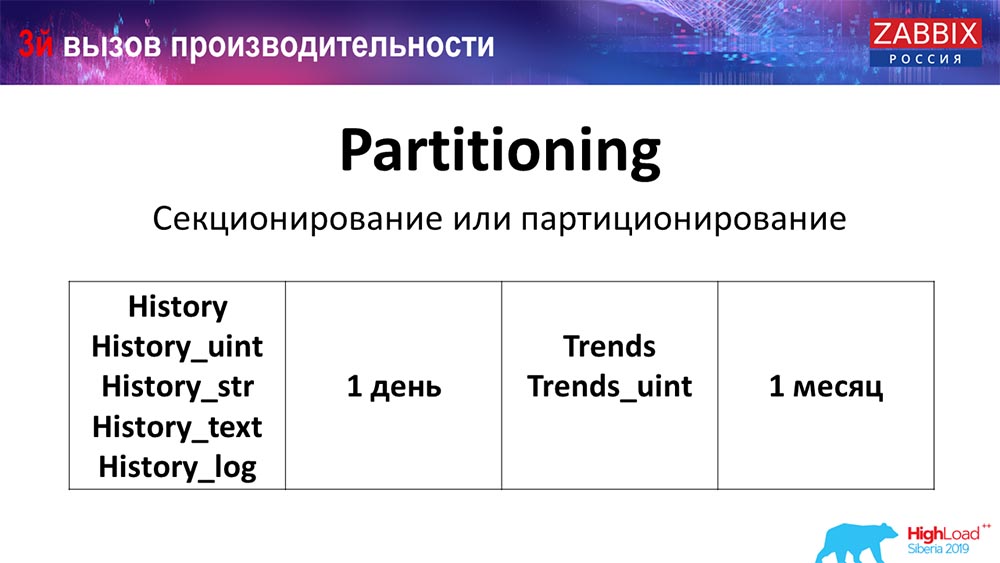
Partitionierung (Partitionierung)
Dies wird normalerweise in jeder relationalen Datenbank konfiguriert, die ich auf andere Weise aufgelistet habe. MySQL hat eine eigene Technologie. Insgesamt sind sie sich jedoch in Bezug auf PostgreSQL 10 und MySQL sehr ähnlich. Natürlich gibt es viele interne Unterschiede in der Implementierung und den Auswirkungen auf die Leistung. Generell führt die Erstellung einer neuen Partition jedoch häufig auch zu bestimmten Problemen.

Abhängig von Ihrem Setup (wie viele Daten Sie an einem Tag erstellen) legen Sie normalerweise mindestens einen Tag / Partition und für Trends die Dynamik der Änderungen 1 Monat / neue Partition fest. Dies kann sich ändern, wenn Sie ein sehr umfangreiches Setup haben.
Lassen Sie uns gleich über die Größe des Setups sprechen: Bis zu 5.000 neue Werte pro Sekunde (sogenanntes nvps) - dies wird als kleines "Setup" betrachtet. Durchschnitt - 5 bis 25 Tausend Werte pro Sekunde. Alles, was oben steht, sind bereits große und sehr große Installationen, die eine sehr sorgfältige Konfiguration der Datenbank selbst erfordern.
Bei sehr großen Installationen 1 Tag - dies ist möglicherweise nicht optimal. Ich persönlich sah auf MySQL-Partitionen von 40 Gigabyte pro Tag (und es kann mehr geben). Dies ist eine sehr große Datenmenge, die zu Problemen führen kann. Es muss reduziert werden.
Warum partitionieren?
Was Partitionierung gibt, denke ich, jeder weiß, ist die Tabellenpartitionierung. Häufig handelt es sich dabei um separate Dateien auf Datenträger- und Bereichsanforderungen. Er wählt eine Partition optimaler aus, wenn diese Teil der üblichen Partition ist.
Insbesondere für Zabbix wird es von Bereich zu Bereich verwendet, das heißt, wir verwenden einen Zeitstempel (die Zahl ist normal, die Zeit vom Beginn der Ära an). Sie geben den Beginn des Tages / das Ende des Tages an, und dies ist eine Partition. Wenn Sie vor zwei Tagen Daten beantragen, wird dies alles schneller aus der Datenbank ausgewählt, da Sie nur eine Datei in den Cache hochladen und ausgeben müssen (anstatt eine große Tabelle).

Viele Datenbanken beschleunigen auch das Einfügen (Einfügen in eine einzelne untergeordnete Tabelle). Ich spreche zwar abstrakt, es ist aber auch möglich. Oft hilft das Aufteilen.
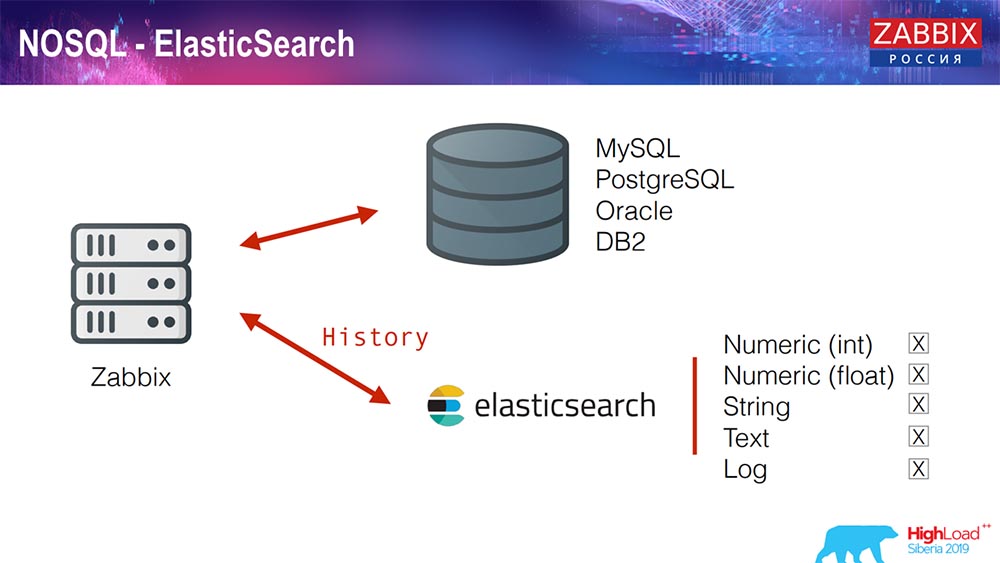
Elasticsearch für NoSQL
Kürzlich haben wir in 3.4 eine Lösung für NoSQL implementiert. Es wurde die Möglichkeit hinzugefügt, in Elasticsearch zu schreiben. Sie können verschiedene Typen schreiben: Wählen Sie - schreiben Sie Zahlen oder Zeichen; Wir haben String-Text, Sie können Protokolle in Elasticsearch schreiben ... Dementsprechend wird das Webinterface auch auf Elasticsearch zugreifen. Dies funktioniert in einigen Fällen gut, kann aber im Moment verwendet werden.
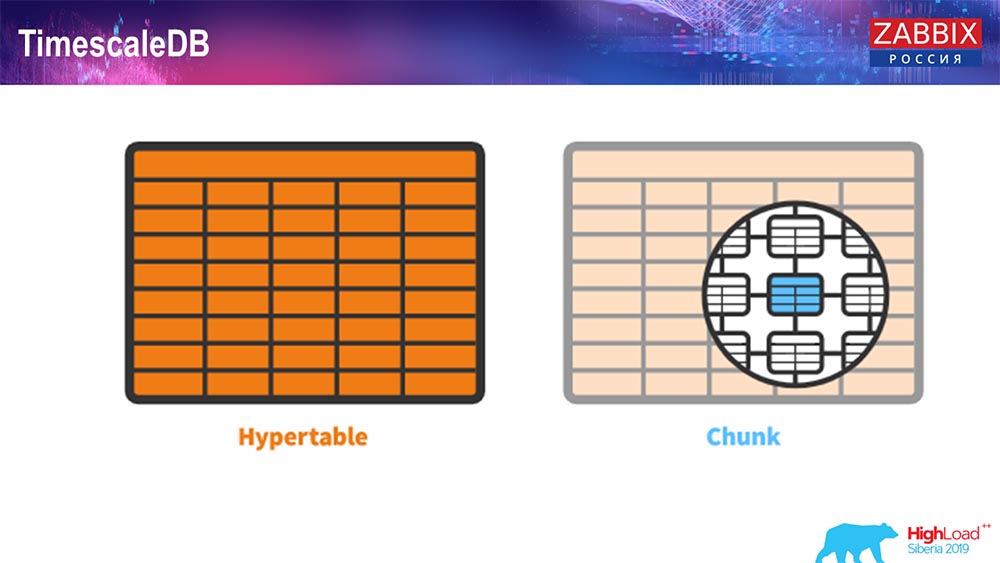
TimescaleDB. Hypertabellen
In 4.4.2 haben wir eine Sache wie TimescaleDB bemerkt. Was ist das? Dies ist eine Erweiterung für Postgres, dh sie verfügt über eine native PostgreSQL-Schnittstelle. Außerdem können Sie mit dieser Erweiterung viel effizienter mit Zeitreihendaten arbeiten und haben eine automatische Partitionierung. Wie sieht es aus:

Dies ist hypertable - es gibt ein solches Konzept in Timescale. Dies ist die Hypertabelle, die Sie erstellen und die Blöcke enthält. Chunks sind Partitionen, das sind Kindertabellen, wenn ich mich nicht irre. Es ist wirklich effektiv.
TimescaleDB und PostgreSQL
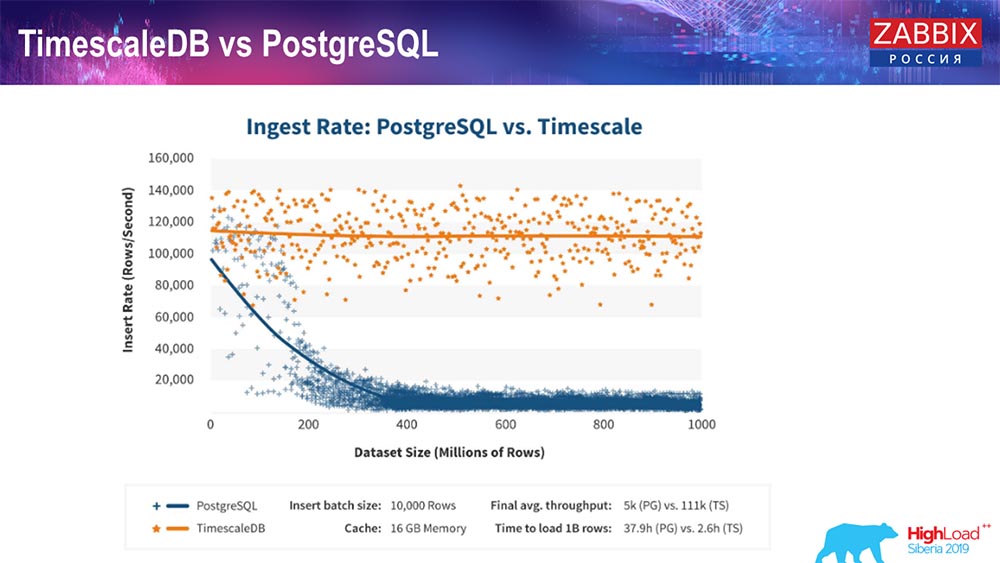
Wie die Hersteller von TimescaleDB versichern, verwenden sie einen korrekteren Anforderungsverarbeitungsalgorithmus, insbesondere insert'ov, der es Ihnen ermöglicht, mit zunehmender Größe der Datenmengeneinfügung eine annähernd konstante Leistung zu erzielen. Das heißt, nach 200 Millionen Zeilen "Postgres" beginnt die übliche sehr durchzubiegen und verliert buchstäblich an Leistung auf Null, während "Timescale" es Ihnen ermöglicht, Einfügungen mit einer beliebigen Datenmenge so effizient wie möglich einzufügen.
Wie installiere ich TimescaleDB? Alles ist einfach!
Er hat es in der Dokumentation, es ist beschrieben - es kann aus Paketen für jeden geliefert werden ... Es kommt auf die offiziellen Pakete von Postgres an. Es kann manuell kompiliert werden. So kam es, dass ich für die Datenbank kompilieren musste.
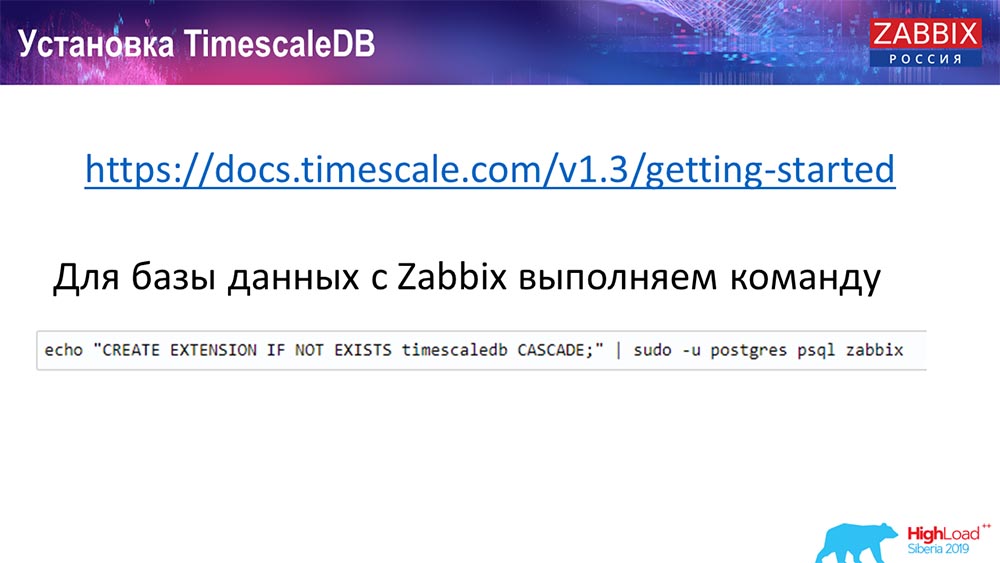
Bei Zabbix aktivieren wir einfach Extention. Ich denke, dass diejenigen, die Extention in Postgres verwendet haben ... Sie müssen nur Extention aktivieren und es für die von Ihnen verwendete Zabbix-Datenbank erstellen.
Und der letzte Schritt ...
TimescaleDB. Migrationsverlaufstabellen
Sie müssen eine Hypertabelle erstellen. Hierfür gibt es eine spezielle Funktion - Hypertabelle erstellen. Darin gibt der erste Parameter die Tabelle an, die in dieser Datenbank benötigt wird (für die Sie eine Hypertabelle erstellen müssen).

Das zu erstellende Feld und chunk_time_interval (dies ist das Intervall der Chunks (zu verwendende Partitionen). 86.400 sind ein Tag.
Parameter migrate_data: Wenn Sie true eingeben, werden alle aktuellen Daten in zuvor erstellte Chunks übertragen.
Ich selbst habe migrate_data verwendet - es dauert ziemlich lange, je nachdem, wie groß Ihre Datenbank ist. Ich hatte mehr als ein Terabyte - die Erstellung dauerte mehr als eine Stunde. In einigen Fällen habe ich beim Testen die Verlaufsdaten für den Text (history_text) und den String (history_str) gelöscht, um sie nicht zu übertragen - sie waren für mich nicht wirklich interessant.
Und wir machen das letzte Update in unserer db_extention: Wir setzen timescaledb so, dass die Datenbank und insbesondere unsere Zabbix verstehen, was db_extention ist. Es aktiviert es und verwendet die korrekte Syntax und Datenbankabfragen unter Verwendung der für TimescaleDB erforderlichen "Funktionen".
Serverkonfiguration
Ich habe zwei Server benutzt. Der erste Server ist eine virtuelle Maschine, die klein genug ist, 20 Prozessoren und 16 Gigabyte RAM. Richten Sie Postgres 10.8 ein:

Das Betriebssystem war Debian, das Dateisystem war xfs. Ich habe nur minimale Einstellungen vorgenommen, um diese bestimmte Datenbank zu verwenden, abzüglich dessen, was Zabbix verwenden wird. Auf demselben Computer befanden sich ein Zabbix-Server, PostgreSQL und Load Agents.

Ich habe 50 aktive Agenten verwendet, die das LoadableModule verwenden, um schnell verschiedene Ergebnisse zu generieren. Sie erzeugten Linien, Zahlen und so weiter. Ich habe die DB mit vielen Daten verstopft. Anfänglich enthielt die Konfiguration 5.000 Datenelemente pro Host, und ungefähr jedes Datenelement enthielt einen Auslöser - so dass es sich um eine echte Konfiguration handelte. Manchmal braucht es sogar mehr als einen Auslöser, um verwendet zu werden.

Ich habe das Update-Intervall, die Auslastung selbst so geregelt, dass ich nicht nur 50 Agenten (mehr hinzugefügt), sondern auch dynamische Datenelemente verwendet und das Update-Intervall auf 4 Sekunden reduziert habe.
Leistungstest. PostgreSQL: 36 Tausend NVPs
Der erste Start, das erste Setup, das ich auf reinem PostreSQL 10 auf dieser Hardware hatte (35.000 Werte pro Sekunde). Wie Sie auf dem Bildschirm sehen können, dauert das Einfügen von Daten im Bruchteil einer Sekunde - alles ist in Ordnung und schnell, SSDs (200 Gigabyte). Das einzige ist, dass 20 GB schnell voll sind.
Es wird noch viel mehr solcher Charts geben. Dies ist das Standardleistungs-Dashboard des Zabbix-Servers.
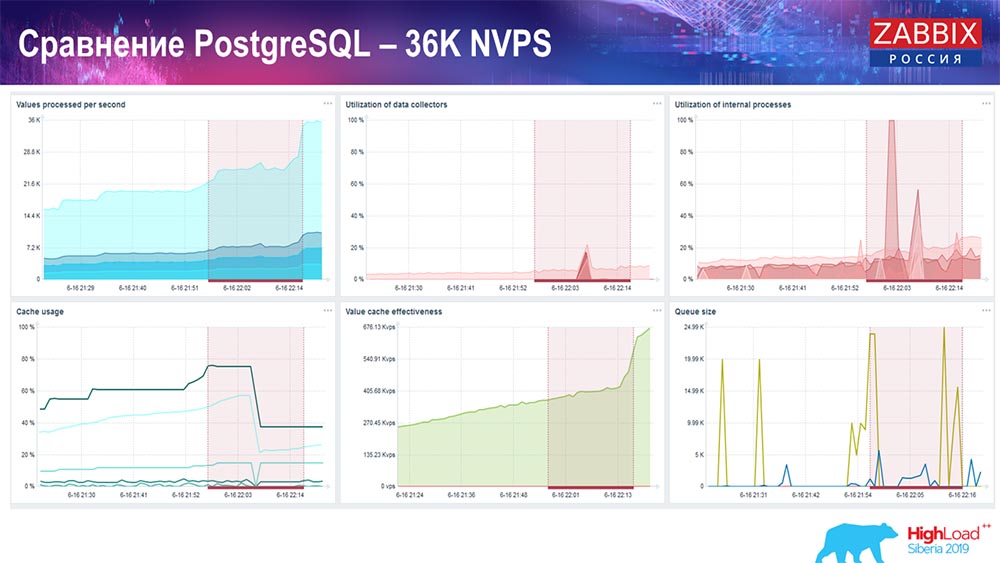
Das erste Diagramm zeigt die Anzahl der Werte pro Sekunde (blau, oben links), in diesem Fall 35.000 Werte. Dies (Ladezentrum) ist das Laden von Montageprozessen, und dies (oben rechts) ist das Laden von internen Prozessen: Verlaufssynchronisatoren und Haushälterin, die hier seit einer ausreichenden Zeit ausgeführt werden.
Diese Grafik (unten in der Mitte) zeigt die Verwendung von ValueCache - wie viele ValueCache-Treffer für Trigger (mehrere Tausend Werte pro Sekunde). Ein weiteres wichtiges Diagramm ist das vierte (unten links), das die Verwendung von HistoryCache zeigt, über die ich gesprochen habe. Dabei handelt es sich um einen Puffer vor dem Einfügen in die Datenbank.
Leistungstest. PostgreSQL: 50 Tausend NVPs
Als Nächstes habe ich die Last auf 50.000 Werte pro Sekunde auf derselben Hardware erhöht. Beim Laden mit Hauskiper wurden bei der Berechnung bereits in 2-3 Sekunden zehntausend Werte erfasst. Was in der Tat in dem folgenden Screenshot gezeigt wird:
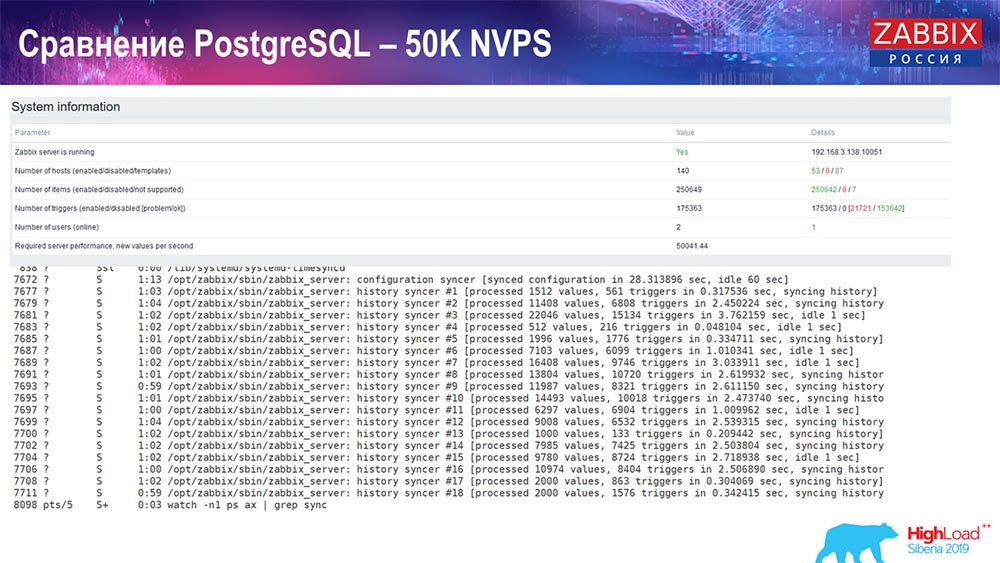
Hauskiper beginnt bereits, sich in die Arbeit einzumischen, aber im Allgemeinen liegt die Beladung mit Senkfängern immer noch bei 60% (dritte Grafik oben rechts). Der HistoryCache wird bereits während der Arbeit von "Hauskiper" aktiv gefüllt (unten links). Es war ungefähr ein halbes Gigabyte, gefüllt mit 20%.
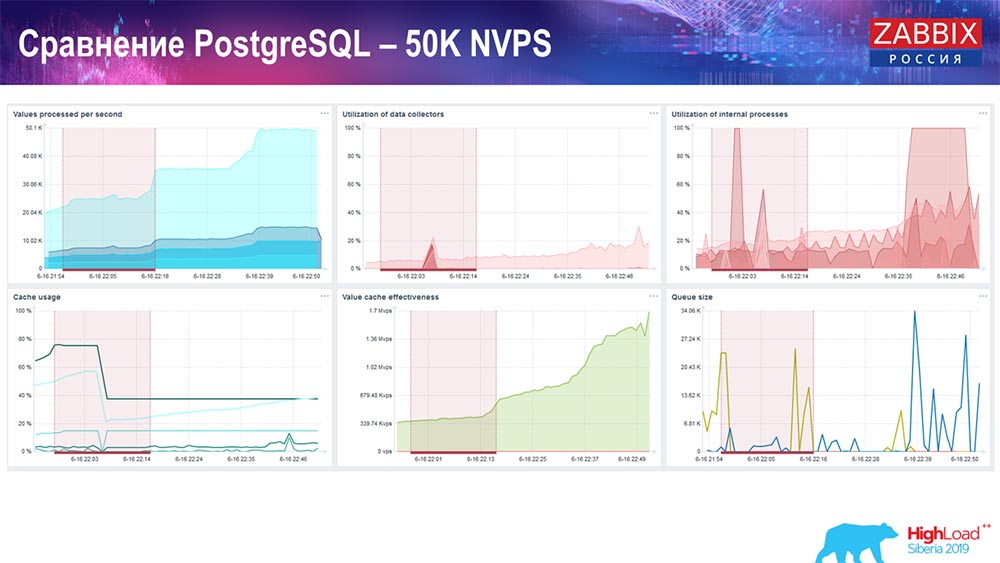
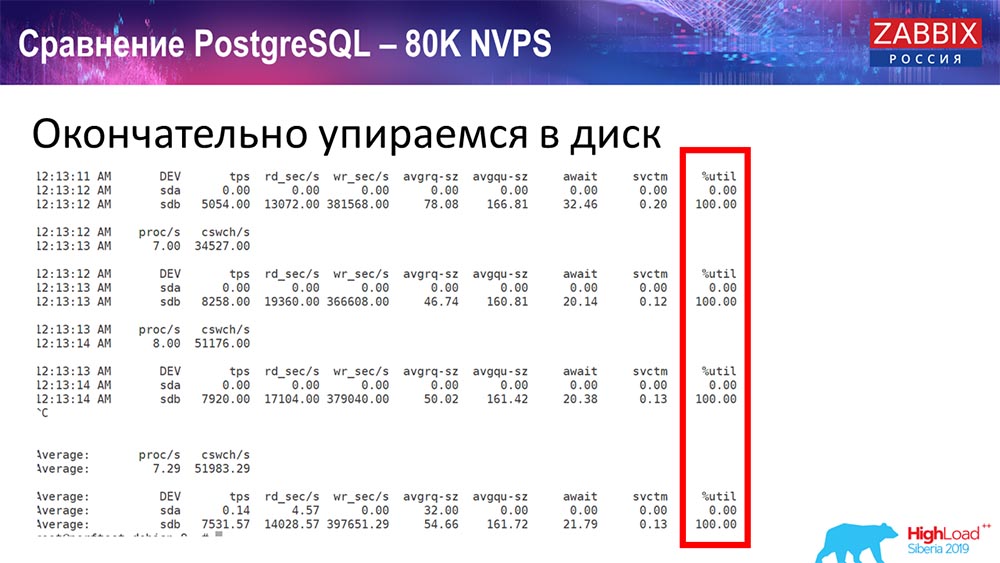
Leistungstest. PostgreSQL: 80 Tausend NVPs
Weiter erhöht auf 80 Tausend Werte pro Sekunde:
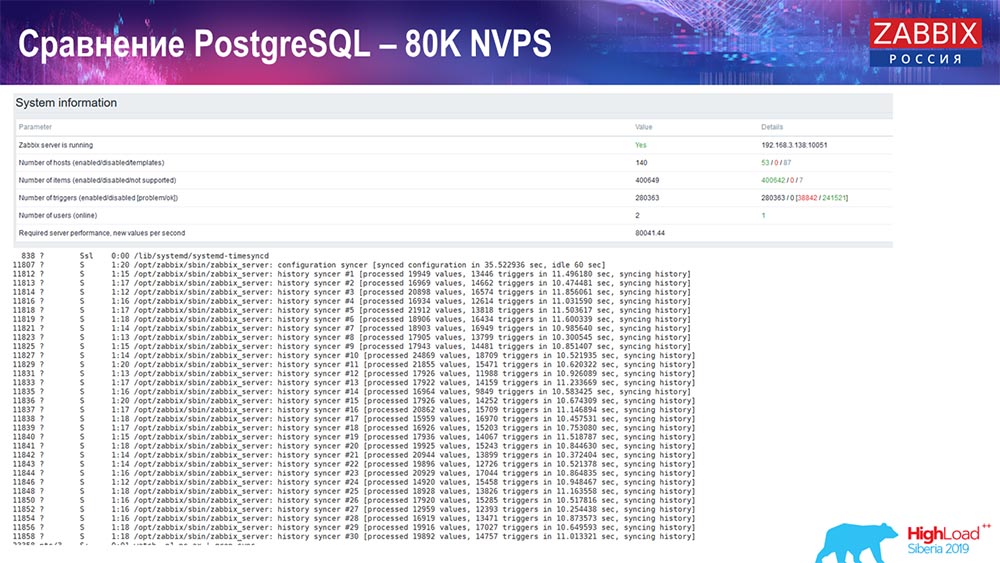
Es waren ungefähr 400 Tausend Datenelemente, 280 Tausend Trigger. Wie Sie sehen, war der Einsatz für die Beladung historischer Platinen (30 Stück) bereits recht hoch. Außerdem habe ich verschiedene Parameter erhöht: History-Sinker, Cache ... Auf dieser Hardware stieg das Laden von History-Sinkern auf ein Maximum, fast "bis ins Regal" - dementsprechend war HistoryCache sehr stark ausgelastet:
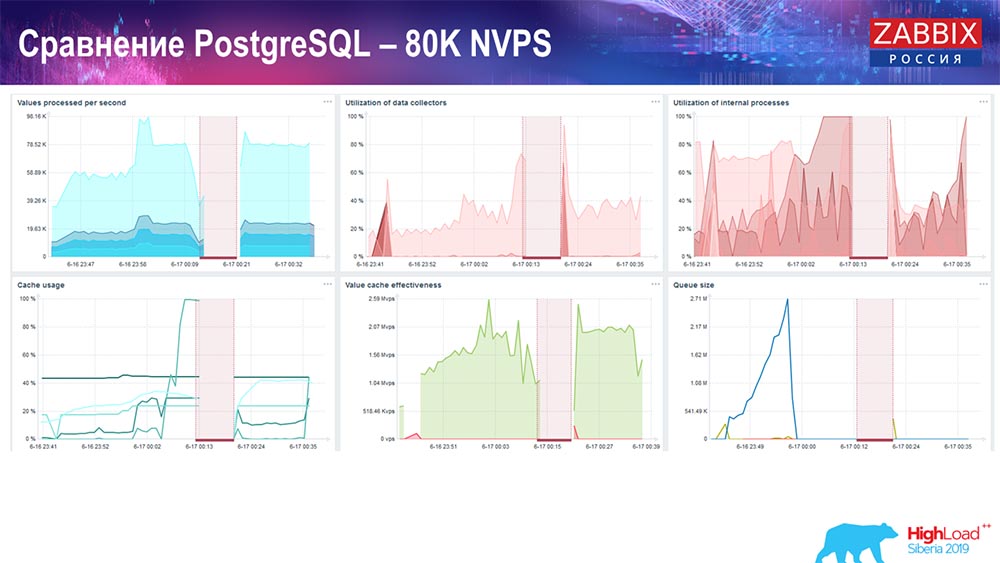
Während dieser ganzen Zeit habe ich alle Parameter des Systems (wie der Prozessor verwendet wird, RAM) überwacht und festgestellt, dass die Festplattenauslastung maximal war - ich habe die maximale Kapazität dieser Festplatte auf dieser Hardware, auf dieser virtuellen Maschine, erreicht. "Postgres" begann mit einer solchen Intensität, Daten ziemlich aktiv zu speichern, und die Platte hatte keine Zeit mehr zum Schreiben, Lesen ...
Ich nahm einen anderen Server, der bereits 48 Prozessoren mit 128 Gigabyte RAM hatte:
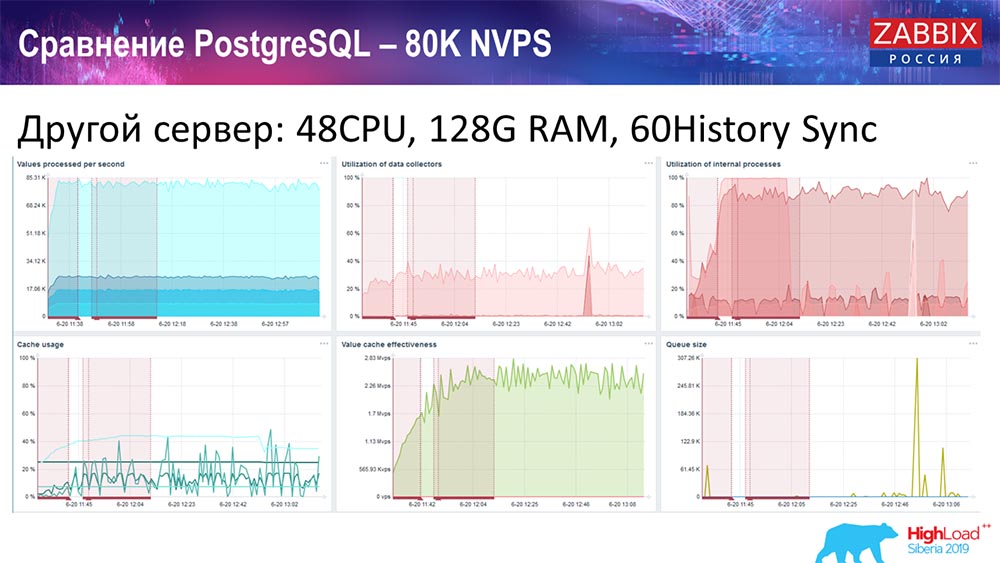
Außerdem habe ich es "getrübt" - ich habe History Syncer (60 Teile) installiert und eine akzeptable Leistung erzielt. In der Tat sind wir nicht "im Regal", aber dies ist wahrscheinlich die Grenze der Produktivität, wo es bereits notwendig ist, etwas dagegen zu unternehmen.
Leistungstest. TimescaleDB: 80 Tausend NVPs
Meine Hauptaufgabe war die Verwendung von TimescaleDB. Fehler ist auf jedem Diagramm sichtbar:
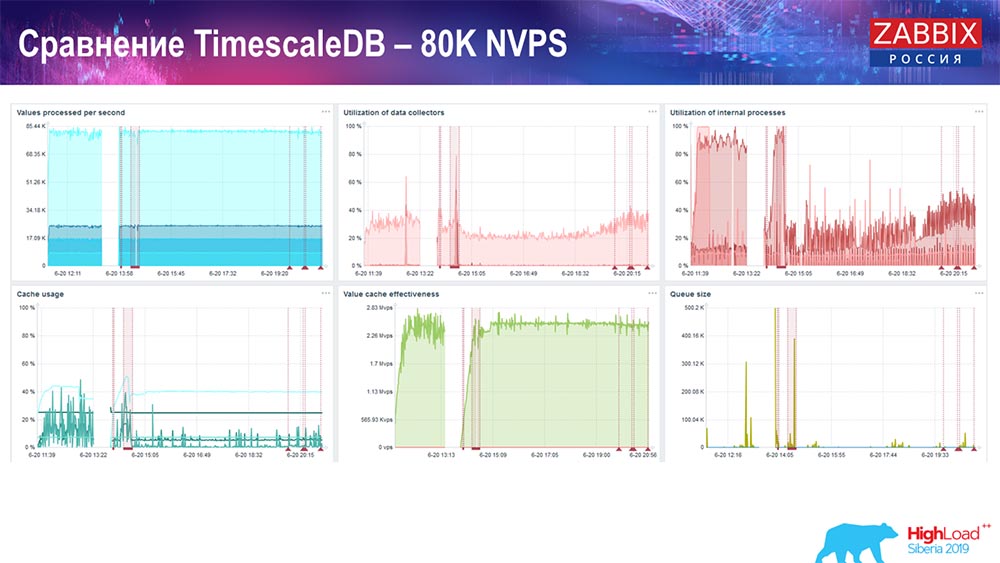
Diese Einbrüche sind nur Datenmigration. Danach hat sich im "Zabbix" -Server das Ladeprofil von History-Sinkern, wie Sie sehen, stark verändert.
Es ist fast dreimal so schnell, dass Sie Daten einfügen und weniger HistoryCache verwenden können - dementsprechend erhalten Sie Daten zeitnah. Wiederum sind 80.000 Werte pro Sekunde eine ziemlich hohe Rate (natürlich nicht für Yandex). Im Allgemeinen ist dies ein ziemlich umfangreiches Setup mit einem Server.PostgreSQL-Leistungstest: 120.000 NVPs
Als nächstes habe ich den Wert der Anzahl der Datenelemente auf eine halbe Million erhöht und den geschätzten Wert von 125 Tausend pro Sekunde erhalten: Und ich habe folgende Grafiken:
Und ich habe folgende Grafiken: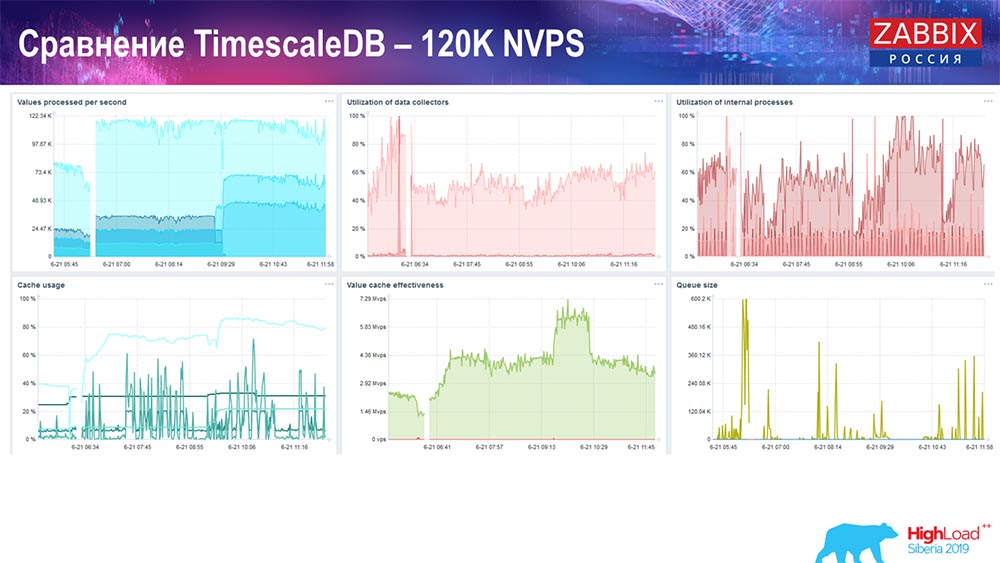 Im Prinzip ist dies eine funktionierende Konfiguration, die ziemlich lange funktionieren kann. Da ich aber nur 1,5 Terabyte Festplatte hatte, habe ich es in ein paar Tagen ausgegeben. Gleichzeitig wurden neue TimescaleDB-Partitionen erstellt, die für die Leistung völlig unbemerkt blieben, was für MySQL nicht zu sagen ist.Partitionen werden normalerweise nachts erstellt, da sie das allgemeine Einfügen und Ausführen von Tabellen blockieren und zu einer Beeinträchtigung des Dienstes führen können. In diesem Fall ist das nicht! Die Hauptaufgabe bestand darin, die Funktionen von TimescaleDB zu testen. Das Ergebnis war eine solche Zahl: 120 Tausend Werte pro Sekunde.Es gibt auch Beispiele in der Community:
Im Prinzip ist dies eine funktionierende Konfiguration, die ziemlich lange funktionieren kann. Da ich aber nur 1,5 Terabyte Festplatte hatte, habe ich es in ein paar Tagen ausgegeben. Gleichzeitig wurden neue TimescaleDB-Partitionen erstellt, die für die Leistung völlig unbemerkt blieben, was für MySQL nicht zu sagen ist.Partitionen werden normalerweise nachts erstellt, da sie das allgemeine Einfügen und Ausführen von Tabellen blockieren und zu einer Beeinträchtigung des Dienstes führen können. In diesem Fall ist das nicht! Die Hauptaufgabe bestand darin, die Funktionen von TimescaleDB zu testen. Das Ergebnis war eine solche Zahl: 120 Tausend Werte pro Sekunde.Es gibt auch Beispiele in der Community: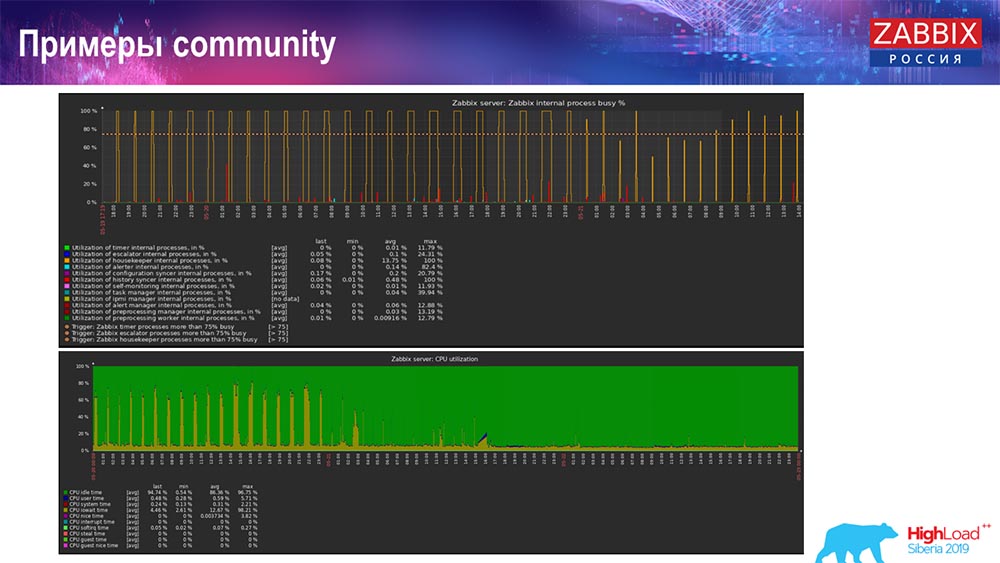 Der Mann schaltete auch TimescaleDB ein und die Last bei der Verwendung von io.weight fiel auf den Prozessor. Durch die Einbeziehung von TimescaleDB wurde auch die Verwendung von Elementen interner Prozesse verringert. Und das sind gewöhnliche Pancake-Festplatten, dh eine gewöhnliche virtuelle Maschine auf gewöhnlichen Festplatten (keine SSDs)!Für einige kleine Setups, die von der Festplattenleistung abhängen, ist TimescaleDB meiner Meinung nach eine sehr gute Lösung. Auf diese Weise können Sie problemlos weiterarbeiten, bevor Sie auf eine schnellere Hardware für die Datenbank migrieren.Ich lade Sie alle zu unseren Veranstaltungen ein: Konferenz - in Moskau, Gipfel - in Riga. Nutzen Sie unsere Kanäle - Telegramm, Forum, IRC. Wenn Sie Fragen haben - kommen Sie zu unserem Schalter, wir können über alles reden.
Der Mann schaltete auch TimescaleDB ein und die Last bei der Verwendung von io.weight fiel auf den Prozessor. Durch die Einbeziehung von TimescaleDB wurde auch die Verwendung von Elementen interner Prozesse verringert. Und das sind gewöhnliche Pancake-Festplatten, dh eine gewöhnliche virtuelle Maschine auf gewöhnlichen Festplatten (keine SSDs)!Für einige kleine Setups, die von der Festplattenleistung abhängen, ist TimescaleDB meiner Meinung nach eine sehr gute Lösung. Auf diese Weise können Sie problemlos weiterarbeiten, bevor Sie auf eine schnellere Hardware für die Datenbank migrieren.Ich lade Sie alle zu unseren Veranstaltungen ein: Konferenz - in Moskau, Gipfel - in Riga. Nutzen Sie unsere Kanäle - Telegramm, Forum, IRC. Wenn Sie Fragen haben - kommen Sie zu unserem Schalter, wir können über alles reden.Publikumsfragen
Frage des Publikums (im Folgenden - A): - Wenn TimescaleDB so einfach zu konfigurieren ist und eine solche Leistungssteigerung bietet, sollte es möglicherweise als bewährte Methode zum Einrichten von Zabbix mit Postgres verwendet werden? Und gibt es irgendwelche Fallstricke und Nachteile dieser Entscheidung, oder kann ich, wenn ich mich dazu entschloss, Zabbix selbst herzustellen, Postgres sicher nehmen, Timescale sofort dort platzieren, es verwenden und nicht über irgendwelche Probleme nachdenken? ? AH:- Ja, ich würde sagen, dass dies eine gute Empfehlung ist: Verwenden Sie Postgres sofort mit der Erweiterung TimescaleDB. Wie gesagt, viele gute Reviews, obwohl dieses "Feature" experimentell ist. Tatsächlich zeigen Tests, dass dies eine großartige Lösung ist (mit TimescaleDB), und ich denke, es wird sich weiterentwickeln! Wir beobachten, wie sich diese Erweiterung entwickelt, und werden korrigieren, was benötigt wird.Schon während der Entwicklung haben wir uns auf eines ihrer berühmten „Features“ verlassen: Dort könnte man mit Brocken etwas anders arbeiten. Aber dann haben sie es in der nächsten Version herausgesägt, und wir mussten uns nicht mehr auf diesen Code verlassen. Ich würde empfehlen, diese Lösung für viele Setups zu verwenden. Wenn Sie MySQL verwenden ... Für mittlere Setups funktioniert jede Lösung gut.A:- Auf den neuesten Grafiken, die aus der Community stammen, gab es eine Grafik mit „Housekeeper“:
AH:- Ja, ich würde sagen, dass dies eine gute Empfehlung ist: Verwenden Sie Postgres sofort mit der Erweiterung TimescaleDB. Wie gesagt, viele gute Reviews, obwohl dieses "Feature" experimentell ist. Tatsächlich zeigen Tests, dass dies eine großartige Lösung ist (mit TimescaleDB), und ich denke, es wird sich weiterentwickeln! Wir beobachten, wie sich diese Erweiterung entwickelt, und werden korrigieren, was benötigt wird.Schon während der Entwicklung haben wir uns auf eines ihrer berühmten „Features“ verlassen: Dort könnte man mit Brocken etwas anders arbeiten. Aber dann haben sie es in der nächsten Version herausgesägt, und wir mussten uns nicht mehr auf diesen Code verlassen. Ich würde empfehlen, diese Lösung für viele Setups zu verwenden. Wenn Sie MySQL verwenden ... Für mittlere Setups funktioniert jede Lösung gut.A:- Auf den neuesten Grafiken, die aus der Community stammen, gab es eine Grafik mit „Housekeeper“: Es funktionierte weiter. Was macht Hauskiper mit TimescaleDB?AG: - Jetzt kann ich nicht sicher sagen - Ich schaue auf den Code und sage ausführlicher. TimescaleDB-Abfragen werden nicht zum Löschen von Chunks verwendet, sie werden jedoch irgendwie aggregiert. Ich bin zwar nicht bereit, diese technische Frage zu beantworten. Wir klären heute oder morgen am Stand.A: - Ich habe eine ähnliche Frage - zur Leistung des Löschvorgangs in Timescale.A (Antwort des Publikums): - Wenn Sie Daten aus einer Tabelle löschen, wenn Sie dies durch Löschen tun, müssen Sie die Tabelle durchgehen - löschen, bereinigen, alles für ein zukünftiges Vakuum markieren. Da Sie in Timescale über Blöcke verfügen, können Sie diese löschen. Grob gesagt, sagen Sie einfach zu der Datei, die sich in den Big Data befindet: "Löschen!""Timescale" versteht einfach, dass es keinen solchen Block mehr gibt. Und da es in den Abfrageplaner integriert ist, erfasst es Ihre Bedingungen in ausgewählten oder anderen Vorgängen und versteht sofort, dass dieser Block nicht mehr vorhanden ist - "Ich werde nicht mehr dorthin gehen!" (Daten nicht verfügbar).
Es funktionierte weiter. Was macht Hauskiper mit TimescaleDB?AG: - Jetzt kann ich nicht sicher sagen - Ich schaue auf den Code und sage ausführlicher. TimescaleDB-Abfragen werden nicht zum Löschen von Chunks verwendet, sie werden jedoch irgendwie aggregiert. Ich bin zwar nicht bereit, diese technische Frage zu beantworten. Wir klären heute oder morgen am Stand.A: - Ich habe eine ähnliche Frage - zur Leistung des Löschvorgangs in Timescale.A (Antwort des Publikums): - Wenn Sie Daten aus einer Tabelle löschen, wenn Sie dies durch Löschen tun, müssen Sie die Tabelle durchgehen - löschen, bereinigen, alles für ein zukünftiges Vakuum markieren. Da Sie in Timescale über Blöcke verfügen, können Sie diese löschen. Grob gesagt, sagen Sie einfach zu der Datei, die sich in den Big Data befindet: "Löschen!""Timescale" versteht einfach, dass es keinen solchen Block mehr gibt. Und da es in den Abfrageplaner integriert ist, erfasst es Ihre Bedingungen in ausgewählten oder anderen Vorgängen und versteht sofort, dass dieser Block nicht mehr vorhanden ist - "Ich werde nicht mehr dorthin gehen!" (Daten nicht verfügbar). Das ist alles!
Das heißt, der Tabellenscan wird durch das Entfernen der Binärdatei ersetzt, sodass dies schnell geht.A: - Bereits angesprochen wurde das Thema nicht SQL. Soweit ich weiß, muss Zabbix die Daten nicht wirklich ändern, aber all dies ist so etwas wie ein Protokoll. Ist es möglich, spezialisierte Datenbanken zu verwenden, die ihre Daten nicht ändern können, aber gleichzeitig speichern, akkumulieren, verschenken - Clickhouse, sagen wir mal etwas Kafka-ähnliches? .. Kafka ist auch ein Protokoll! Kann man sie irgendwie integrieren?AH:- Das Entladen kann erfolgen. Wir haben eine bestimmte "Funktion" ab Version 3.4: Sie können alle historischen Dateien, Ereignisse und alles andere in Dateien schreiben. und dann von einem beliebigen Handler an eine beliebige andere Datenbank senden. In der Tat, viele, die direkt in die Datenbank wiederholen und schreiben. Im laufenden Betrieb schreiben historische Synchronisierer all dies in Dateien, drehen diese Dateien und so weiter, und Sie können dies in das Clickhouse werfen. Über die Pläne kann ich nichts sagen, aber möglicherweise wird die weitere Unterstützung für NoSQL-Lösungen (wie "Clickhouse") fortgesetzt.A: - Im Allgemeinen stellt sich heraus, dass Sie Postgres vollständig loswerden können?AH:- Das Schwierigste an Zabbix sind natürlich die historischen Tabellen, die die meisten Probleme und Ereignisse verursachen. In diesem Fall gibt es meiner Meinung nach im Allgemeinen keine Probleme, wenn Sie Ereignisse für eine lange Zeit nicht speichern und die Historie mit Trends in einem anderen schnellen Speicher aufbewahren.A: - Können Sie einschätzen, wie viel schneller alles funktioniert, wenn Sie zum Beispiel zum Clickhouse gehen?AG: - Ich habe nicht getestet. Ich denke, dass zumindest die gleichen Zahlen ganz einfach erreicht werden können, wenn man bedenkt, dass "Clickhouse" eine eigene Benutzeroberfläche hat, aber ich kann es nicht mit Sicherheit sagen. Besser testen. Es hängt alles von der Konfiguration ab: wie viele Hosts Sie haben und so weiter. Die Einfügung ist eine Sache, aber Sie müssen immer noch diese Daten nehmen - Grafana oder etwas anderes.A:- Das heißt, wir sprechen über einen gleichberechtigten Kampf und nicht über den großen Vorteil dieser schnellen Datenbanken?AG: - Ich denke, wenn wir integrieren, wird es genauere Tests geben.A: - Wo ist die gute alte RRD geblieben? Warum haben Sie zu SQL-Datenbanken gewechselt? Bei RRD wurden zunächst alle Messdaten erfasst.AG: - In der RRD „Zabbix“ war es vielleicht eine sehr alte Version. SQL-Datenbanken gab es schon immer - ein klassischer Ansatz. Der klassische Ansatz ist MySQL, PostgreSQL (es gibt sie schon lange). Wir haben eine gemeinsame Schnittstelle für SQL- und RRD-Datenbanken, die wir so gut wie nie benutzt haben.
Ein bisschen Werbung :)
Vielen Dank für Ihren Aufenthalt bei uns. Mögen Sie unsere Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder Ihren Freunden
Cloud-basiertes VPS für Entwickler ab 4,99 US-Dollar empfehlen, ein
einzigartiges Analogon zu Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 Dollar oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2-mal billiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur wir haben
2 x Intel TetraDeca-Core Xeon 2 x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV ab 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über
das Erstellen von Infrastruktur-Bldg. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?