Gestützt auf die Diskussion im
AWS Minsk Community Chat
In letzter Zeit tobten echte Kämpfe um die Definition von DevOps und SRE.
Trotz der Tatsache, dass in vielerlei Hinsicht Diskussionen zu diesem Thema bereits aufgenommen wurden, einschließlich meiner, beschloss ich, die habr-Community und meine Meinung zu diesem Thema vor Gericht zu bringen. Für diejenigen, die interessiert sind, willkommen bei cat. Und alles von vorne anfangen lassen!
Hintergrund
In der Antike lebte ein separates Team von Softwareentwicklern und Serveradministratoren getrennt. Ersteres hat den Code erfolgreich geschrieben, letzteres mit verschiedenen warmen, an ersteres adressierten, liebevollen Worten. Es hat die Server eingerichtet, ist regelmäßig zu den Entwicklern gekommen und hat im Gegenzug ein umfassendes „Alles funktioniert auf meinem Computer“ erhalten. Das Geschäft wartete auf die Software, alles war im Leerlauf, in regelmäßigen Abständen pleite, alle waren nervös. Vor allem derjenige, der für dieses ganze Durcheinander bezahlt hat. Glorreiche Lampenära. Nun ja, Sie wissen bereits, woher die DevOps-Beine stammen.
Geburtspraktiken von DevOps
Dann kamen ernsthafte Onkel und sagten, dass dies keine Industrie ist, es ist unmöglich, so zu arbeiten. Und schleppte Lebenszyklusmodelle. Zum Beispiel ein V-Modell.
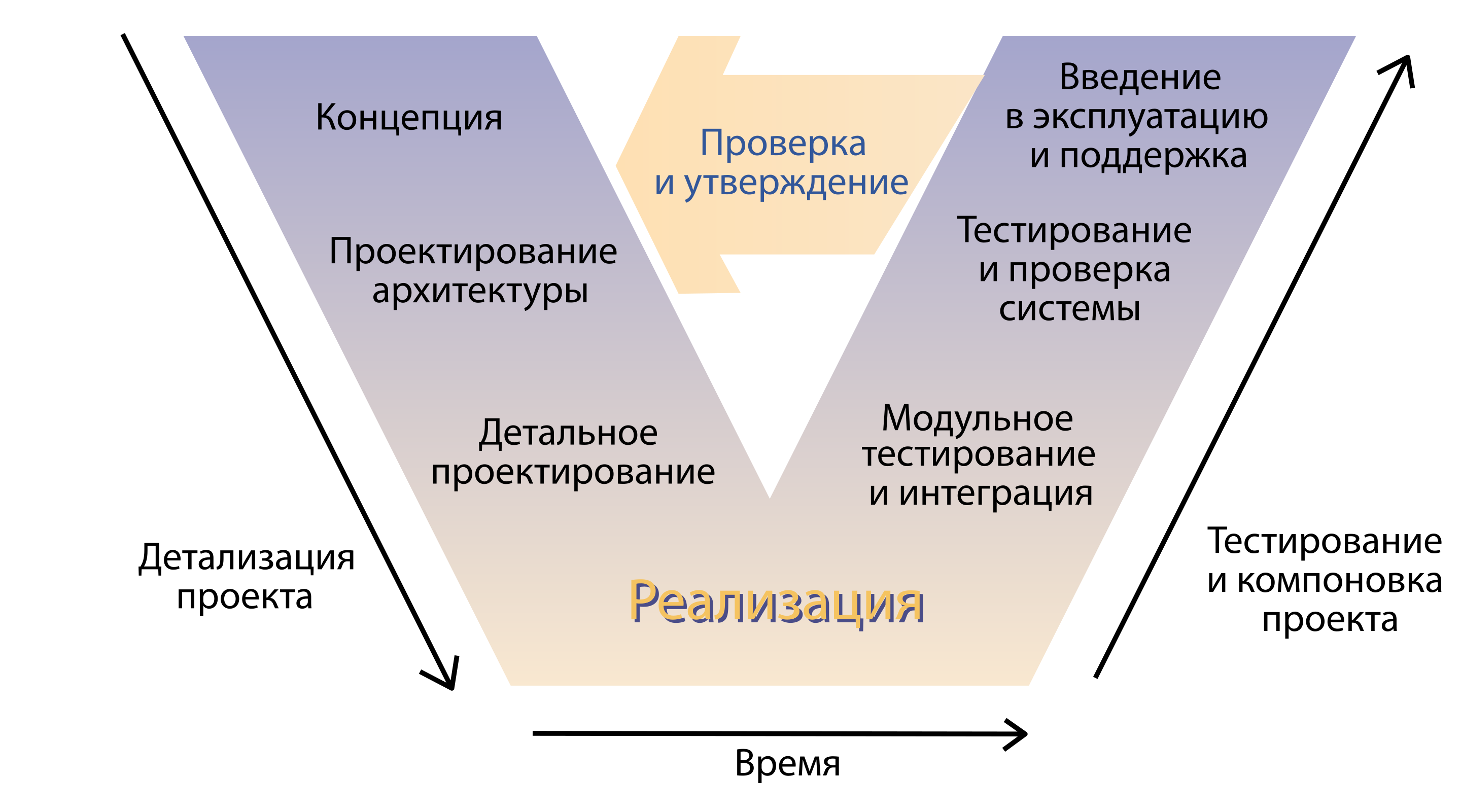
Was sehen wir also? Das Geschäft kommt mit einem Konzept, Architekten entwerfen Lösungen, Entwickler schreiben Code, dann scheitern sie. Jemand testet das Produkt, jemand liefert es irgendwie an den Endverbraucher, und irgendwo am Ausgang dieses Wundermodells wartet ein einsamer Geschäftskunde auf das vom Meer versprochene Wetter. Wir sind zu dem Schluss gekommen, dass wir Methoden brauchen, mit denen sich dieser Prozess etablieren lässt. Und sie beschlossen, Praktiken zu schaffen, die sie umsetzen würden.
Lyrischer Exkurs darüber, was Praxis ist
Mit Praxis meine ich ein Bündel von Technologie und Disziplin. Ein Beispiel ist die Beschreibung der Infrastruktur mit Terraform-Code. Disziplin ist das Beschreiben der Infrastruktur mit Code, sie liegt im Kopf des Entwicklers, und Technologie ist Terraform an sich.
Und sie beschlossen, sie DevOps-Praktiken zu nennen - ich denke, sie bedeuteten von der Entwicklung bis zum Betrieb. Wir haben uns verschiedene knifflige Dinge ausgedacht - CI / CD-Praktiken, Praktiken, die auf dem IaC-Prinzip basieren, Tausende davon. Und es begann, die Entwickler schreiben den Code, DevOps-Ingenieure wandeln die Beschreibung des Systems in Form von Code in funktionierende Systeme um (ja, der Code ist leider nur eine Beschreibung, aber nicht die Verkörperung des Systems), die Auslieferung dreht sich und so weiter und so fort. Nachdem die Administratoren von gestern neue Praktiken beherrscht hatten, wurden sie stolz zu DevOps-Ingenieuren umgeschult, und alles begann. Und es war Abend und es war Morgen ... Entschuldigung, nicht von dort.
Alles ist wieder nicht Gott sei Dank
Sobald sich alles beruhigte und verschiedene schlaue "Methodologen" begannen, dicke Bücher über DevOps-Praktiken zu schreiben, brachen leise Streitigkeiten aus, der so ein berüchtigter DevOps-Ingenieur ist und der DevOps eine Produktionskultur ist, dass die Unzufriedenheit wieder gereift ist. Plötzlich war die Softwarebereitstellung eine absolut nicht triviale Aufgabe. Jede Entwicklungsinfrastruktur hat einen eigenen Stack, Sie müssen ihn irgendwo sammeln, Sie müssen die Umgebung irgendwo bereitstellen, hier brauchen Sie Tomcat, Sie brauchen immer noch eine schwierige Methode, um ihn zu starten - im Allgemeinen ist der Kopf geknackt. Und ein weiteres Problem stellte sich seltsamerweise als primär die Organisation von Prozessen heraus - diese Übermittlungsfunktion begann, wie ein Engpass, Prozesse zu blockieren. Außerdem wurde der Vorgang (Vorgänge) nicht abgebrochen. Es ist im V-Modell nicht sichtbar, und rechts befindet sich der gesamte Lebenszyklus. Daher ist es notwendig, die Infrastruktur irgendwie zu unterstützen, die Überwachung zu überprüfen, Vorfälle zu beheben und sogar die Zustellung zu erledigen. Das heißt mit einem Fuß sowohl in der Entwicklung als auch im Betrieb zu sitzen - und plötzlich stellte sich heraus, dass solche Entwicklung und Betrieb. Und dann gab es einen massiven Hype um Microservices. Und mit ihnen verlagerte sich die Entwicklung von lokalen Rechnern auf die Cloud - versuchen Sie, etwas vor Ort zu debuggen, wenn es Dutzende und Hunderte von Microservices gibt, wird die ständige Lieferung hier zum Überlebensmittel. Für die "kleine bescheidene Firma" war es immer noch egal wo, aber immer noch? Was ist mit Google?
Google SRE
Google ist gekommen, hat die größten Kakteen gefressen und sich entschieden - wir brauchen das nicht, wir brauchen Zuverlässigkeit. Und Zuverlässigkeit muss managen. Und ich habe mich entschieden - wir brauchen Spezialisten, die die Zuverlässigkeit managen. Er nannte sie SR-Ingenieure und sagte, hier sind Sie, machen Sie es wie gewohnt, gut. Hier haben Sie SLI, hier haben Sie SLO, hier haben Sie Überwachung. Und steckte die Nase in Operationen. Und nannte sein "zuverlässiges DevOps" SRE. Alles scheint in Ordnung zu sein, aber es gibt einen dreckigen Hack, den sich Google leisten könnte - Leute einzustellen, die über Entwicklerfähigkeiten und ein
bisschen mehr Nähen zu Hause verfügen und
die die Funktionsweise funktionierender Systeme als SR-Ingenieure kennen. Außerdem hat die Einstellung solcher Personen und von Google selbst Probleme - hauptsächlich, weil es hier mit sich selbst konkurriert - es ist notwendig, die Geschäftslogik jemandem zu beschreiben. Die Lieferung wurde von Release-Ingenieuren aufgehängt, SR-Ingenieure verwalten die Zuverlässigkeit (natürlich nicht direkt, sondern beeinflussen die Infrastruktur, ändern die Architektur, verfolgen Änderungen und Indikatoren, behandeln Vorfälle). Schön, dass du
Bücher schreiben kannst. Aber was ist, wenn Sie nicht Google sind, aber die Zuverlässigkeit dennoch Bedenken hat?
DevOps-Ideen entwickeln
Es war pünktlich zu Docker, der von lxc und verschiedenen Orchestrierungssystemen wie Docker Swarm und Kubernetes aufwuchs, und die DevOps-Ingenieure atmeten aus - die Vereinheitlichung der Praktiken vereinfachte die Bereitstellung. In einem solchen Ausmaß vereinfacht, dass es möglich wurde, sogar Entwickler zu beliefern - dass deployment.yaml vorhanden ist. Containerisierung löst das Problem. Und die Reife von CI / CD-Systemen ist bereits auf Dateiebene geschrieben und alles hat begonnen - die Entwickler werden es selbst tun. Und dann fangen wir an zu reden, wie wir unsere SRE machen können, mit ... ja, zumindest mit jemandem.
SRE nicht bei Google
Nun, ok, wir haben die Lieferung geliefert, wir scheinen zu atmen, gehen zurück in die guten alten Zeiten, als Administratoren die Prozessorlast beobachteten, die Systeme abstimmten und in aller Ruhe etwas Unverständliches aus den Bechern schlürften ... Halt. Dafür haben wir nichts unternommen (sorry!). Es stellt sich plötzlich heraus, dass wir bei Google hervorragende Methoden anwenden können - es kommt nicht auf die Prozessorauslastung an, und nicht darauf, wie oft wir die Laufwerke dort oder in der Cloud wechseln. Wir optimieren die Kosten, und die Geschäftsmetriken sind dieselben berüchtigten SLx. Und niemand hat ihnen das Infrastrukturmanagement abgenommen, und es ist notwendig, Vorfälle zu lösen, regelmäßig im Dienst zu sein und im Allgemeinen in den Geschäftsprozessen zu sein. Und Leute, fangen Sie schon ein bisschen auf einem guten Niveau an zu programmieren, Google hat auf Sie gewartet.
Zusammenfassend. Plötzlich, aber Sie sind es schon leid zu lesen und Sie sind gespannt darauf, dem Autor im Kommentar zum Artikel zu schreiben. DevOps als Lieferpraxis war und ist. Und es geht nirgendwo hin. SRE als eine Reihe von Betriebspraktiken macht diese Lieferung erfolgreich.