Zabbix ist ein beliebtes offenes Überwachungssystem, das von einer Vielzahl von Unternehmen eingesetzt wird. Ich werde über die Erfahrungen beim Erstellen eines Überwachungsclusters sprechen.
In dem Bericht werde ich kurz auf die zuvor vorgenommenen Änderungen (Patches) eingehen, die die Fähigkeiten des Systems erheblich erweitern und die Basis für den Cluster vorbereiten (Upload des Verlaufs in „Clickhouse“, asynchrones Polling). Und ich werde im Detail auf die Probleme eingehen, die während des System-Clusters aufgetreten sind - das Lösen von Identitätskonflikten in der Datenbank, ein wenig über das CAP-Theorem und das Überwachen mit verteilten Datenbanken, über die Nuancen der Arbeit von Zabbix im Cluster-Modus: Sicherung und Koordination von Servern und Proxys, über das Überwachen von Domänen und ein neues Aussehen auf Systemarchitektur.
Ich werde kurz darüber sprechen, wie ein Cluster zu Hause gestartet wird, woher die Quellen stammen und welche zusätzlichen. Für den Cluster sind Einstellungen erforderlich.

HighLoad ++ Sibirien 2019. Tomsk Hall. 24. Juni, 17 Uhr Abstracts und
Präsentation . Die nächste HighLoad ++ Konferenz findet am 6. und 7. April 2020 in St. Petersburg statt. Details und Tickets
hier .
Mikhaili Makurov (im Folgenden - MM): - Ich arbeite für eine Providerfirma. Der Anbieter heißt Intersvyaz, er arbeitet in der Stadt Tscheljabinsk. Wir haben ungefähr 1,5 Millionen Menschen. Und damit der Anbieter funktioniert, gibt es eine riesige Infrastruktur. Wir haben ungefähr 70.000 Geräte: Switches, IoT-Geräte ... - eine Menge von allem, was überwacht werden muss. Dieser Bericht befasst sich insbesondere mit der Verwendung von Zabbix und dem Aufbau eines auf Zabbix basierenden Clusters für die Überwachung der Infrastruktur.
Ich bin 12 Jahre im Anbieter. Jetzt mache ich überhaupt keine technischen Dinge, es geht mehr darum, Leute zu managen. Und das (technische Sachen) ist eigentlich mein Hobby. Ich werde dieses Thema etwas weiterentwickeln.
Probleme beim Überwachen
Ich glaube, ich habe Glück. Vor ungefähr anderthalb Jahren endete ich in einem Projekt, das so klang: "Wir müssen einige Probleme mit unserer Überwachung lösen." Ich habe eine Verantwortungszone (Überwachung) geerbt, die aus einer Reihe von Servern bestand, insbesondere aus 21 Servern:

Es gab 4 leistungsstarke Server und 15 Proxys - es war alles Hardware. Es gab einige Beschwerden über diese Überwachung. Das erste ist, dass es viel war. Wir haben nicht einen einzigen Server mit dem Provider so viel Platz belegt. Das ist Geld, Elektrizität ... Tatsächlich ist das kein großes Problem.

Das große Problem war, dass die Überwachung nicht mit dem Schritt hielt, was wir von ihm wollten. Für diejenigen, die Zabbix noch nicht aktiv genutzt haben, ist dies ein Dashboard, das die Verspätung bei Überprüfungen anzeigt:

Die meisten unserer Schecks befanden sich in der roten Zone. Sie liefen mehr als 10 Minuten langsamer als wir wollten, das heißt, sie waren 10 Minuten zu spät. Es war nicht sehr angenehm, aber es war immer noch möglich, mehr oder weniger zu leben. Das größte Problem war das folgende:

Es war ein Überwachungssystem eines funktionierenden Netzwerks. Bei der Ausführung der geplanten Arbeiten fiel ein Tausendersegment an fünf Schaltern ab. Zusammen mit diesen Schaltern gerieten Schalter und Überwachung in Vergessenheit. Als alles wiederhergestellt war, wurde zwei Stunden später die Überwachung wiederhergestellt. Es war schmerzlich unangenehm, und dieser Satz sollte in jedem Bericht stehen:

"Wir müssen etwas mit diesem Projekt machen!"
Und hier werde ich zwei Geschichten erzählen. Dann haben wir versucht, gleichzeitig auf zwei Arten zu gehen. Wir haben eine Integrationsgruppe - sie hat den Weg zum Bau eines modularen Systems gewählt (es gab einen sehr coolen Bericht von Avito zu Highload im November letzten Jahres in Moskau - sie haben darüber gesprochen):

Zabbix = Menschen + API + Effizienz
Die Jungs aus kleinen Stücken begannen ein System aufzubauen. Und mit einigen Enthusiasten arbeitete ich weiter an Zabbix. Dafür gab es Gründe. Was sind die Gründe?
- Erstens gibt es eine coole API. Und wenn Sie 60-70.000 Überwachungselemente haben, funktioniert dies natürlich nur automatisch. Sie können nicht so viele Hände ohne Fehler hinzufügen.
- Personal. Es gibt Dienstüberwachungsschichten, die rund um die Uhr arbeiten. Das sind keine IT-Spezialisten, das sind Leute im Dienst. Wir haben dem "Grafan" einige andere Systeme gezeigt - es ist schwer für sie. Es gibt Administratoren, die an Vielfalt und den Komfort der Überwachung im Zabbix selbst gewöhnt sind: Vorlagen, automatische Erkennung - und das ist alles cool!
- Zabbix kann effektiv sein.
Wird die SQL-Datenbank langsamer? Eine Antwort - Clickhouse
Der erste Grund war offensichtlich. Wir haben dann an MySQL gearbeitet, und es kam zu 6-7.000 Metriken pro Sekunde, und wir sahen konstante Verzögerungen auf den Festplatten.

Heute hat es schon 100 Mal geklungen: Die einzige Antwort ist Clickhouse:
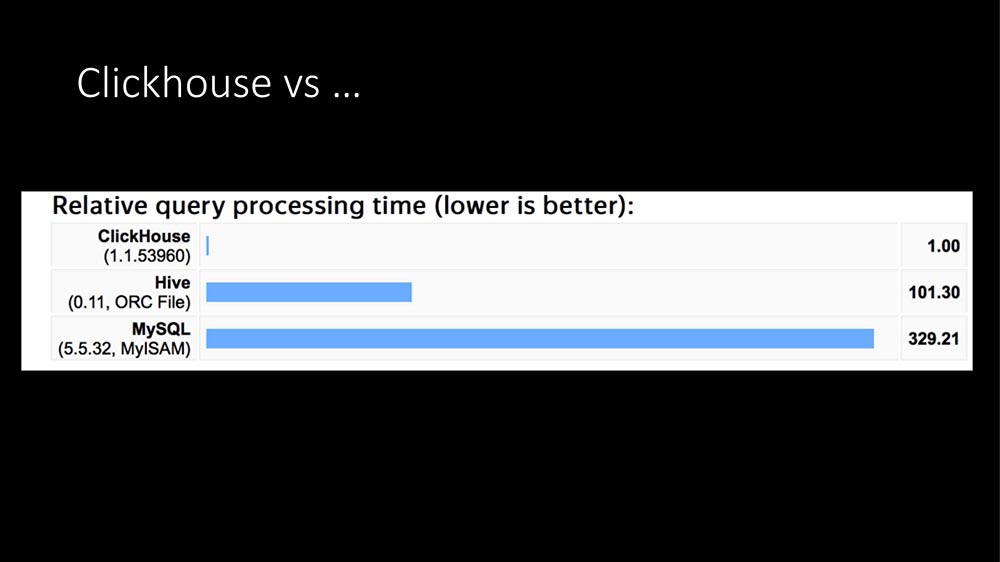
In der Struktur von Abfragen handelt es sich bei dem Großteil der Abfragen (unser Profiling in wenigen Stunden) um Metrikdatensätze. Das Schreiben von Metriken in eine SQL-Datenbank ist extrem teuer. Hier erschien TimeScaleDB ... Dann hatten wir ein „Clickhouse“ für ungefähr ein Jahr für andere Aufgaben in Betrieb (wir machen Big Data, wir haben eine große Anwendung - im Allgemeinen ist ein Anbieter jetzt ein ganzes IT-Geschäft).
Nachdem wir uns schöne Grafiken aus dem Internet angesehen hatten (das „Clickhouse“ ist hunderte Male schneller, es benötigt sehr wenig Speicherplatz) und über aktuelle Erfahrungen verfügten, haben wir unser HistoryStorage-Modul für „Zabbix“ geschrieben, damit die „Clickhouse“ -Daten direkt gespeichert werden können (d. H. nicht vom Dateiexport, sondern direkt im laufenden Betrieb).

Außerdem haben wir ein Modul für die „Front“ geschrieben. Alle diese schönen Grafiken im Zabbix-Admin-Panel können von Clickhouse aus erstellt werden. Es ist klar, dass die API auch funktioniert.
Der Effekt ist ungefähr derselbe - der SQL Server als dedizierte Entität ist nicht vollständig geworden, dh die Last ist auf Null gefallen. Was am bemerkenswertesten ist, wir hatten bereits ein dediziertes „Clickhouse“ -Cluster: Als wir dort unsere gesamte Ladung abgaben, stieg es von 6 auf 10.000 Metriken. Die Administratoren sagten: "Aber wir sehen nichts, was gekommen ist. Nein! "
Wie wir Clickhouse erweitert haben
Ich sage noch weiter: Für Tests haben wir versucht, bis zu 140-150.000 Metriken pro Sekunde zu laden (wir konnten Zabbix nicht mehr auspressen, später werde ich sagen, warum), und das Clickhouse sieht diese Last auch nicht. Das heißt, es ist sehr bequem, kühle Ladung. In der Regel gibt es ein solches Modul.
Außerdem haben wir es etwas erweitert:

In unserer Version können Sie die Nanosekunden ausschalten. Sie wissen wahrscheinlich: Zabbix schreibt Sekunden und Nanosekunden in zwei Felder. Nehmen Sie in den „Clickhouse“ -Feldern, in denen die Variabilität sehr groß ist, viel Platz ein.
Übrigens über den Ort. Eine Metrik in Clickhouse (wir haben jetzt ungefähr 700 Milliarden Metriken aufgezeichnet) benötigt 2,9 Bytes. Gemäß der Zabbix-Dokumentation benötigt eine Metrik in SQL-Datenbanken 40 bis 100 Byte. Das Ausschalten der Nanosekunden spart weitere 40%, d. H. Etwa 1,5 Bytes pro Metrik. Das heißt, "Clickhouse" ist sehr effektiv in Bezug auf den Standort.
Auf Wunsch unserer Mitarbeiter, die sich mit maschinellem Lernen beschäftigen, haben wir eine Option getroffen, damit wir den Host und den Namen der Metrik schreiben können. Da die Variabilität der Daten groß ist, nimmt dies nicht viel zusätzlichen Platz ein, obwohl die Textdaten signifikant sein können (dies wurde mit langen Tests noch nicht verifiziert).
Außerdem haben wir zwei Ergänzungen vorgenommen, da wir Zabbix entwickelt haben und es oft ziehen mussten. Eine sehr coole Ergänzung: Zu Beginn können wir den Verlaufscache füllen, da Sie mit „Clickhouse“ Millionen von Datensätzen lesen können. Zu Beginn haben wir eine Verzögerung von 30 bis 40 Sekunden, erhalten jedoch einen sofort gestarteten Dienst mit einem erwärmten Cache.
In Fällen, in denen das Sammeln über die Infrastruktur einfacher ist, gibt es immer noch eine solche Option: das Lesen aus dem Cache für einige Zeit zu unterbinden. Es ist besser, 5 Minuten schnell zu arbeiten, ohne die Auslöser zu zählen, und dann füllt sich der Cache - wenn Sie dies nicht tun, beginnt die Stagnation der Historiensenker.
Im Allgemeinen gibt es ein „Clickhouse“ -Modul. Es kann verwendet werden.
Polling-Effizienz
Trotz der Tatsache, dass wir dann die Probleme mit der Basis gelöst haben, blieben die Bremsen und das Problem mit fünfzehn Proxies bestehen. Sie waren damit verbunden:

Dies ist die Hauptdatenverarbeitungs-Pipeline bei Zabbix. Es gibt eine Phase der Datenerfassung, eine Vorverarbeitung und Verlaufssynchronisierungen, die die gesamte Arbeit erledigen (Berechnung von Triggern, Warnungen, Speichern des Verlaufs). Der Cache-Engpass stellte sich heraus als:

Warum ist die Abfrage langsam? Denn die Threads, die die Anforderungen stellen, werden in der Cache-Konfiguration für Einheitenmetriken in die Warteschlange gestellt und blockiert. Es gibt andere Orte, aber sie sind nicht so eng. Beispielsweise gibt es eine Vorverarbeitung selbst und einen Verlaufscache. In unserem SQL haben wir folgende Einschränkungen:

Möglicherweise liegt dies an der Tatsache, dass in unserem Fall die Basis ungefähr 5 Millionen Metriken ist, die wir entfernen. Mit all den Optimierungen, die wir durchgeführt haben, konnten wir 70.000 Metriken im Engpass (im Konfigurations-Cache) erhalten, aber nur in dem Fall, in dem wir sie in großen Mengen verarbeiteten.
Was ist Massenverarbeitung? Poller wechselt zum Konfigurations-Cache und übernimmt die Aufgabe nicht für eine Metrik, sondern für 4 oder 8 Tausend. Gleichzeitig bietet sich ihm eine weitere wunderbare Gelegenheit: Er kann jetzt asynchron abrufen, weil er 4.000 Messdaten hat ... Warum tun sie eine nach der anderen? Sie können sofort alles fragen!
Asynchrones Polling ist effizienter als Proxy!
Für die Haupttypen, die vom Anbieter verwendet werden - SNMP und AGENT - haben wir die Abfrage in den asynchronen Modus umgeschrieben, und dies führte insgesamt zu einer Geschwindigkeitssteigerung von 100 auf 200. Wir hatten 15 Proxies, wir haben sie in 150 geteilt - sie waren komplett weg. Das Ergebnis waren zwei Banken, die nur für die Reserve benötigt werden:

Uniprozessor-Bank (eine Xeon 1280 kostet). Dies ist meine letzte Zeit:

Ungefähr 60% sind kostenlos, aber bei diesem Klingeln von 60% bis 40% werden regelmäßige Skripten auf dem Computer selbst ausgeführt (externe Skripten). Sie können optimiert werden, bis Probleme entstehen.
Die Skalierung sieht ungefähr so aus:

Dies sind 62.000 Hosts, ungefähr 5 Millionen Metriken. Unser aktueller Bedarf beträgt ungefähr 20.000 Metriken pro Sekunde.
Na wie alles? Wir haben die Performance-Probleme gelöst, die Historie erweitert und das Polling ist fantastisch. Das Problem ist gelöst? Nicht wirklich ... Alles wäre zu einfach.
Ich habe auf der vorherigen Karte einen Streich gespielt (nicht alle gezeigt):

Es gibt zwei Probleme. Ich möchte sagen: "Narren, Straßen." Es gibt einen menschlichen Faktor, es gibt Ausrüstung.
Ein Server reicht immer noch nicht aus. In etwa einem Jahr gab es zwei Fälle mit Hardwareproblemen - ein SSD-Laufwerk und etwas anderes. Die meisten Probleme sind der menschliche Faktor, wenn Menschen Tests durchführen. In unserem Unternehmen wird Zabbix als Dienstleistung genutzt: Alle Abteilungen können dort etwas Eigenes schreiben.
Ich würde gerne erweitern. Ich möchte mich nicht auf eine Dose verlassen können. Ich wollte, dass wir noch stärker bleiben können. Und ich möchte nach dem Scale-out-Prinzip skalieren. Hier gibt es gar nichts zu diskutieren: Wachsen, die Kapazität einer Dose erhöhen, ist schon seit 20 Jahren irrelevant.

Der Cluster angefordert ...
Irgendwann im Dezember erschien die erste Version. Eine atomare Cluster-Einheit wird auf einem separaten Host verarbeitet. Der Host wurde ausgewählt.

Tatsache ist, dass in Zabbix ziemlich starke Verbindungen zwischen Elementen bestehen, die sich auf demselben Host befinden können, dh Trigger können verbunden werden, sie können in der Vorverarbeitung zusammen verarbeitet werden. Zwischen den Hosts ist die Konnektivität jedoch nicht so hoch. Daher ist es normal, diesen Cluster zwischen den Knoten des Clusters zu verwenden - dort wird nicht viel Datenverkehr stattfinden. Die Hauptaufgabe von Clustern besteht darin, untereinander zu vereinbaren, wer an welchen Hosts beteiligt ist.
Ich würde gerne unser maximales Limit von 60-70.000 Metriken überschreiten, weil der Appetit mit dem Essen einhergeht. Wir haben Leute, die sich mit QoE beschäftigen ... Quality of Experience - eine Analyse der Funktionsweise des Internets für Abonnenten auf der Grundlage von Transitmetriken, dh Sie liefern alle TCP-Metriken an 1,5 Millionen Menschen und geben sie in die Überwachung ein - es gibt eine Menge Daten.
Und ich wollte Zuverlässigkeit. Ich wollte es, wenn etwas passiert ... Der Schichtdienstbeamte rief an und sagte: "Wir haben Probleme mit dem Server", schaltete ihn aus, wir werden es morgen herausfinden.
Erster Cluster
Die erste Version wurde basierend auf etcd implementiert:

Etcd ist ein verteilter Schlüsselwertspeicher, der in vielen fortschrittlichen Projekten verwendet wird (soweit ich das verstehe, in Kubernetes). Alles war großartig. Etcd bietet sehr interessante Tools - zum Beispiel löst es das Problem der Auswahl des Hauptservers. Aber so ein Problem ...
Wir hatten ein klassisches "Zabbix" mit drei Links: "web" - die Basis - der Server selbst. Und wir haben dort "Clickhouse" hinzugefügt, und jetzt haben wir auch etcd hinzugefügt. Die Admins begannen sich hinter den Köpfen zu kratzen: Hier gibt es zu viele Abhängigkeiten - es wird wahrscheinlich nicht zuverlässig sein. Im Verlauf der Entwicklung wurde eines noch klarer: In Zabbix selbst ist bereits eine Art der serverübergreifenden Kommunikation integriert, die nur zwischen dem Server und dem Proxy verwendet wird, der sogenannte Proxy-Poller-Prozess:

Es ist ziemlich cool für die Kommunikation zwischen Servern mit minimalen Änderungen. Dies erlaubte etcd (zumindest vorübergehend) nicht zu verwenden, den Code stark zu vereinfachen und vor allem an verifiziertem Code zu arbeiten (es scheint, dass dieser Code 5 oder 7 Jahre alt ist).
Wie werden Server in einem Cluster koordiniert?
Die Koordination erfolgt wie beim IGP-Protokoll nach Typ. Damit die Server Priorität haben (ich sage jetzt, warum dies erforderlich ist) und um Konflikte in der SQL-Datenbank beim Schreiben von Protokollen zu vermeiden, wird jedem Server eine ID zugewiesen (bisher manuell) - dies ist eine Zahl von 0 bis 63 (63 - es ist nur eine Konstante, vielleicht mehr):

Der Server mit der maximalen Kennung wird zum "Master". Als wir unsere ersten Testcluster starteten, sagten unsere Administratoren als Erstes: „Wow! Und lasst sie uns auf verschiedene Seiten stellen. Gut, großartig! “(Wir werden darauf zurückkommen). Und wenn jemand Cluster verteilt hat, ist es möglich zu steuern, wie die Topologie neu verteilt wird: Wohin geht die Rolle des "Masters" im Falle eines Ausfalls des "Zabbix" Hauptservers:

In diesem Fall wie folgt:

Schritt
Im ursprünglichen Zabbix geschieht dies folgendermaßen: Der Server selbst ist für die Generierung von Auto-Increment-Indizes verantwortlich. Um zu verhindern, dass viele Instanzen einander auf den Fersen sind (um keine Protokolle mit denselben Indizes zu erstellen), wird Stepping verwendet: „Zabbix“ mit dem Bezeichner „1“ generiert ein Vielfaches von eins - 1, 11, 21; mit der Kennung "7" - 7, 17, 27 (mit Nuancen).
Wir sind mit Modifikatoren gefahren.

Wie interagieren die Server miteinander?
Dies ist das Erbe von IGPs Hello Packets alle 5 Sekunden. Die Server wissen also, dass sie Nachbarn haben. Der „Master“ weiß also, dass Nachbarn in der Nähe sind, und auf dieser Grundlage entscheidet der „Master“, welche Hosts auf welche Server verteilt werden können.

Dementsprechend gibt es eine Konfiguration. Nach alter Erinnerung nenne ich es Topologie. Eine Topologie ist im Wesentlichen eine Liste von Servern und Hosts, die zu ihnen gehören.
Das Protokoll ist einfach - das ist JSON:

Dies ist auch das Erbe der Zabbix-Proxy- und Zabbix-Serverkommunikation. Im Allgemeinen macht es keinen Sinn, etwas anderes zu verwenden. Das Einzige ist, dass es bei Zabbix 4 Bytes (ZBXD) gibt, aber das ist nicht der Punkt.
Im Hallo-Paket wird die Server-ID übertragen: Wenn der Server das Paket sendet, wird seine ID und seine Version der Topologie angegeben. Auf diese Weise stellen die Server schnell fest, dass es eine neue Version der Topologie gibt, und werden sehr schnell aktualisiert.
Tatsächlich ist die Topologie selbst nur ein Baum, eine Liste von Servern. Für jeden Server eine Liste der unterstützten Hosts:

Und dann entsteht ein interessantes Problem.
Es gibt eine solche magische Phrase - Überwachungsdomänen
Worum geht es? Im klassischen Zabbix war alles einfach - eine eindeutige Einstellung: Dieser Host wird von diesem Proxy überwacht, dieser Proxy gibt Daten an den Server weiter. Wenn der Proxy nicht installiert wurde (oder nicht benötigt wird), überwacht dieser Server alle Hosts:

Was tun, wenn wir viele Server haben? Darüber hinaus könnte die Tatsache problematisch sein, dass wir über geografisch verteilte Server verfügen, und der Server in einem langsam arbeitenden Büro in Kemerowo wird versuchen, die gesamte Infrastruktur von Nowosibirsk zu überwachen.

Das wollen wir nicht. Wir möchten einen Mechanismus haben, mit dem nicht alle Server, sondern die von uns ausgewählten (möglicherweise auf der Grundlage der Geografie) einen bestimmten Host überwachen können. Gleichzeitig wollen wir das schaffen, und wir wollen, dass es einfach ist. Hierfür wurde die Idee der Domänenüberwachung erfunden. Tatsächlich handelt es sich hierbei um einfache Gruppen. Es sind einfach bereits Gruppen im Datensatz enthalten.
Und als ich das tat, sprachen die Leute von der Operation mit mir - sie sagten: „Die Gruppen verwirren uns sehr. Wir fangen immer an, über normale Gruppen nachzudenken. “ Daher dieser Name: Überwachungsdomänen.
Hosts beziehen sich eindeutig auf: einen Host - eine Domain:

Die Hostdomäne kann eine beliebige Anzahl von Servern enthalten. Server können sich in einer beliebigen Anzahl von Domänen befinden. Dies ist eine sehr flexible Sache. Um die Flexibilität zu erweitern und das Gehirn vollständig zu zerstören, gibt es auch eine Standarddomäne:

Server, die Mitglieder der Standarddomäne sind, werden von allen Hosts überwacht, die keine Live-Server oder keine Überwachungsdomäne haben.
Auf diese Weise können wir die Hosts nur topologisch an einige Server binden und die Verteilung der Hosts für den Fall steuern, dass ein Server ausfällt:

Das nächste Problem, auf das wir gestoßen sind ...
Cluster: Anders denken
Wenn wir über viele Server verfügen, gibt es neue Möglichkeiten zum Erstellen eines Clusters und einer Topologie. Dies ist ein Klassiker, wenn es eine Art zentralen Standort gibt und es abgelegene Standorte gibt. oder sagen wir, ein Proxy, an den die Last delegiert wird:

Im Falle des Clusters Zabbix kann es auf zwei Arten implementiert werden. Sie können den klassischen Weg gehen: Verdoppeln Sie einfach die Infrastruktur. In der Mitte haben wir zwei Server, die einen Cluster bilden, die Hosts neu anordnen oder die Last selbst tragen können, wenn der Nachbar abstürzt. Dementsprechend können Sie zusätzliche Proxys auf denselben Servern einrichten - wir erhalten eine doppelte Reserve:

Sie können die neuen "Funktionen" verwenden und dies tun:

Die Hauptsache ist, nicht in eine Situation zu gehen, in der ein geografisch entfernter Server eine große Infrastruktur an einem anderen Ort überwacht. Dies ist eher ein Verwaltungsproblem (ich nenne es Geschäft), da es sich um ein Konfigurationsproblem handelt.
Cluster: Split Gehirn und Sicht
, :
- split brain;
- point of view ( ).
. Split brain – , . , - – ? , , ( ).
point of view : , , , . . , RTT , .
:

, . , , . , – . , , , .
SQL-
, , , . . , , … . .
-, , , - – . , Galera MySQL.
PostgreSQL. «» : , , – . «», , .
?
, :


– . :
- - (Logs), . problems, events events recovery. , – , .
- 15 (State). – ( – – «» ). . , ; – …
- - (Configuration update).
«. «», SQL-:

-, :

Das ist richtig. -, , … – , 2 ! : « , ». - , , .
. , :

, . SQL- . , SQL-. ( - ), «» ( ). …
. Installation
, , «» . . , ?

«»- (. . «» daemon). ( ): ( 1 63, «») ( , ).
ServerIP IP-. , , IP- . - , proxy poller, trapper hello-, proxy poller .
. , , « »:

:

, default. . – , IP-, , ( ). «» – default.
-, .
- .
- , : « , ». .
- - , .
- , hello-time, : « »; .
- .
, , , . 30-40 . , , , .
, . - : « , !» -!

– : - , - , , GitLab, CI/CD, . , , – .
, , – 4.0.9 (4.2 ). Roadmap – -. -, «»; , RPM'.

( ) «» «»-. . , . – : , - … ? !.. «», .
SQL- , , . History Storage.
Referenzen
5 . .
-, , , , . . -.

, ? ! , , , . - - , . , , . , :

. «»- , .
- , , , .
- «» : , Configuration Cache, .
- , , . , , .
- - , . , , . 200 , – .
: !. , , .
. Server ( ). Servers:

? KPI- , ; , . . , , «»-, «»- – , ; .
Fragen
Frage des Publikums (im Folgenden - A): - Ich möchte klären, wie es zwischen den Servern läuft. Mit welchem Protokoll kommunizieren sie? Gibt es irgendeine Art von Sicherheit? Weil es nicht sehr "sicher" ist, die Kommunikation zwischen Servern ins Internet zu bringen ... Wie läuft das?
MM: - Ich denke, das ist ein Anwärter auf die beste Frage - auf den Punkt! Als wir zur Standardkommunikation übergingen, übernahmen die Server für ihre Kommunikation zwischen den Servern alle Kommunikationsprotokollfunktionen, die zwischen dem Server und dem Proxy bestehen. Ich werde klarstellen: Es gibt Verschlüsselung, Datenkomprimierung. Bitte - auf die gleiche Weise wird alles über das Web konfiguriert, wie es standardmäßig für den Server und den Proxy konfiguriert ist; alles wird funktionieren.
A: - Wie arbeitet Hauskiper für Sie bei Clickhouse?
MM: - Im Standard "Zabbix" gibt es keine Schnittstelle von der "Haushälterin" zur Verlaufsschnittstelle, dh die Verlaufsschnittstelle unterstützt keine Datenrotation (ElasticSearch unterstützt z. B. nicht). Vielleicht ist es in 4.2 (habe ich nicht geschaut), aber bisher auf 4.0.9.
Mach es dir einfach! Das neue "Clickhouse" hat eine Partition. Ich würde gerne veraltete Partitionen deaktivieren. Es ist klar, dass es keine Rotation auf der Ebene einzelner Elemente gibt, aber es gibt einen Trick in Zabbix: Sie können globale Werte angeben (z. B. den gesamten Verlauf nicht länger als 90 Tage speichern) - Sie können alle Elemente aus diesen globalen Werten löschen. . Und es wird geschafft! Es gibt mehr zu diesem Thema bei Gitlab.
Wir wollen das architektonische richtig machen: ob man das History Interface so erweitert, dass es im Grunde genommen wäre ... Im Allgemeinen möchte ich keine technischen Schulden hinterlassen, aber es wird gemacht. Weil es notwendig ist, begann das mehr "Clickhouse" zu unterstützen.
A: - Wie fühlst du dich dabei? Wie sich herausstellt, erledigen Sie ziemlich viele Arbeiten, die nicht von einem Anbieter ausgeführt werden.
MM: - Ich habe es wahrscheinlich nicht richtig ausgedrückt. Das ist mein Hobby! Ich bin nicht wirklich ein technischer Spezialist - ich bin ein Manager. In meiner Freizeit übe ich.
A: - Ich dachte, Sie machen das als Teil Ihres Kerngeschäfts ...
MM: - Geschäft gibt mir einen coolen Ort zum Testen. In der Tat empfehle ich sehr - es entlastet das Gehirn. Irgendwo auf der Management-"Sache" würde ich dies sagen - wenn Sie von menschlichen Problemen zu diesen wechseln können. Sie sind so cool gelöst! Dies sind technische Probleme. Sie haben programmiert und es funktioniert so, wie Sie es programmiert haben! Schade, dass die Leute das nicht tun sollten.
A: - Schreiben Sie über einen Proxy oder direkt an „Clickhouse“?
MM: - Direkt. Tatsächlich wird auch die geänderte Verlaufsschnittstelle, die für das "Elastix" verwendet wird, vererbt. Die URL wird verwendet, dh über die http-Schnittstelle sendet "Zabbiks" "Clickhouse". Was cool ist, Zabbix aggregiert, wenn es einen großen Datenstrom gibt, Tausende von Metriken in einer Packung, und dies fällt sehr cool auf das Clickhouse.
A: - Tatsächlich schreibt er bachi für ihn?
MM: - Ja. Eine SQL-Abfrage, die von der URL ausgeführt wird, enthält normalerweise tausend Metriken. Admins "Clickhouse" freuen sich einfach.
Moderator: - Dies ist das Ende des Programms in diesem Raum. Es gibt ein Abendprogramm, das organisiert wird, und es gibt etwas, das nur Sie tun können. Und ich schlage vor, während Sie miteinander kommunizieren, darüber nachzudenken, welche interessanten Dinge Sie tun können ... Wenn Sie sich gegenseitig von Ihren Fällen erzählen, können Sie höchstwahrscheinlich darüber Bericht erstatten. Wenn Sie miteinander diskutieren, finden Sie nur einen Überblick - das Programmkomitee nimmt Ihre Bewerbung an, überlegt und hilft, daraus eine gute, packende Geschichte zu machen. Vielleicht haben Sie eine Geschichte über die Arbeit mit dem Programmkomitee?
MM: - Eigentlich wird viel Feedback gegeben. Ich hatte so viel Glück: Eine Person aus dem Programmkomitee lebt in meinem Tscheljabinsk, und Highload ist die einzige Konferenz, die so eng mit Sprechern zusammenarbeitet. Ich habe so etwas nirgendwo anders gesehen. Es ist sehr vorteilhaft! Verschiedene Phasen: Die Jungs schauen sich das Video an, kommentieren die Folien - es passiert wirklich im Thema (Rechtschreibung, Tippfehler). Sehr cool Ich empfehle! Versuchen Sie es selbst!
Ein bisschen Werbung :)
Vielen Dank für Ihren Aufenthalt bei uns. Mögen Sie unsere Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder Ihren Freunden
Cloud-basiertes VPS für Entwickler ab 4,99 US-Dollar empfehlen, ein
einzigartiges Analogon zu Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 Dollar oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2-mal billiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur wir haben
2 x Intel TetraDeca-Core Xeon 2 x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV ab 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über
das Erstellen von Infrastruktur-Bldg. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?