Vor langer Zeit, in der weit entfernten Solargalaxie, noch bevor sie Teil des Rostelecom-Universums wurde, bestand die Notwendigkeit, mit einem kleinen webProxy-Produkt nicht nur den Netzwerkverkehr zu filtern, sondern auch Statistiken über diesen zu erstellen und ihn anschließend zu speichern. Zu dieser Zeit waren Spaltendatenbanken nicht so beliebt wie heute. Das einzig geeignete Analogon war die kostenpflichtige HP Vertica-Datenbank. Wie sie in der Solar Galaxy dieses Problem gelöst haben und wozu sie schließlich gekommen sind, werden wir unter dem Strich erzählen.

Zunächst haben wir uns entschlossen, eine eigene Datenbank zu erstellen. Als Ergebnis wurde es in OCaml mit binärer Speicherung von Spalten (Textdarstellungen wurden mit lz4 komprimiert) und einer eigenen, recht flexiblen Abfragesprache für S-Ausdrücke geschrieben. Die Partitionierung wurde pro Tag durchgeführt.
Beispiel anfordern:

Es war nicht die bequemste und schnellste, aber erweiterbare und anpassbare Option.
Die Zeit verging ebenso wie die Notwendigkeit, die Erstellung von Statistiken und Verkehrsberichten zu beschleunigen. Aus diesem Grund haben wir begonnen, andere Optionen in Betracht zu ziehen:
- reines Postgres;
- Postgres + cstore_fdw;
- Clickhouse;
- Elastisch
Vergleich von Elastic vs Postgres
In der ersten Phase haben wir Elastic und Postgres + cstore verglichen. Postgres wurde am genauesten betrachtet, da es bereits im System verwendet wurde und Fachwissen zur Verfügung stand, um damit zu arbeiten.
Elastic wurde auch im Unternehmen aktiv eingesetzt. Trotz der „Attraktivität“ der Volltextsuche und ihrer Geschwindigkeit musste Elastic aufgrund des zu großen Datenvolumens auf der Festplatte eingestellt werden. In Bezug auf die Geschwindigkeit gewann Elastic bei einfachen Abfragen etwa dreimal, beispielsweise bei der Abfrage „TOP 20 Sites in einer Woche“. Und bei komplexeren - bis zu 9 Mal: "TOP 20 Websites für Traffic pro Monat."
Es war jedoch besser als seine eigene Basis, was Minuten in Anspruch nahm, verglichen mit 5-6 Sekunden in Elastic und 15-55 Sekunden in Postgres.
Postgres vs Clickhouse Vergleich
Ausgangsdaten
Mit https://github.com/wizardjedi/clickhouse-test haben wir Container mit Postgres und Clickhouse genommen. Diese Container wurden zum Erstellen von Tabellen entwickelt.
Tabellenansicht für Postgres:

Der Primärschlüssel musste entfernt werden, da die Fremdtabelle in Postgres dies nicht zulässt.
Für Clickhouse sieht das Erstellen einer solchen Tabelle folgendermaßen aus:
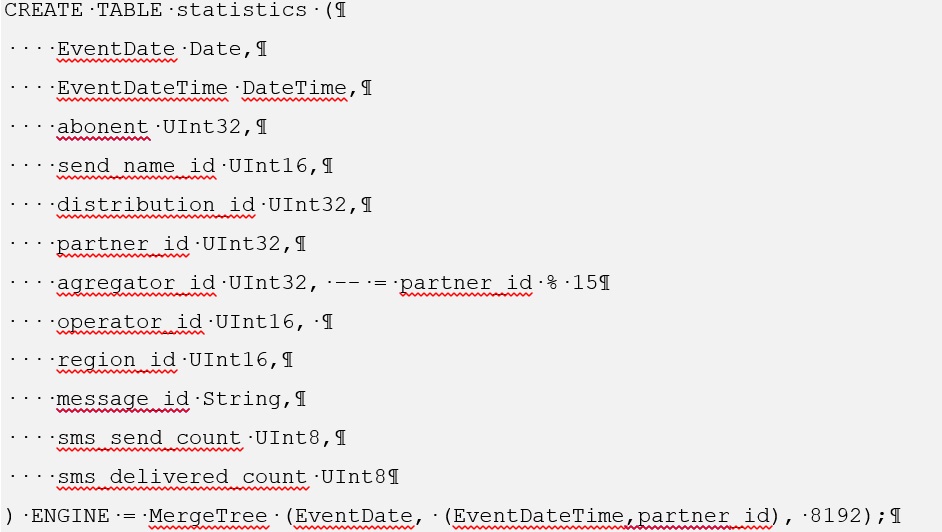
Informationen zum Installieren von cstore for Postgres finden Sie unter https://github.com/citusdata/cstore_fdw .
Außerdem müssen Sie bei der Installation von cstore das Paket postgresql-server-dev-XY installieren
Beim Leistungsvergleich wurden die folgenden Datengrößen (in Megabyte) verwendet:

Die Quelldaten sind nur eine SQL-Abfrage, in der alle Tupel aufgelistet sind, d. H. Rohdaten.
Während der Ausführung von Abfragen, insbesondere von schweren, wurden zusätzlich zu den Daten die Dimensionen der Datenbank gemessen.
Es stellte sich heraus, dass Clickhouse definitiv keine Steigerung verzeichnete.

Berechnen von Systemparametern
Hersteller: Intel
Leitung: Core i5
Modell: 8250U
Taktfrequenz: 1,60 GHz pro Kern
Kerne: 4
RAM: 16 GB
SSD: 256 GB
Laden von Daten in eine Datenbank
Für ein solches Datenvolumen in Clickhouse wurden sie ziemlich schnell geladen: 1 Stunde 40 Minuten (dies gilt für 600 Millionen Tupel).
Zuerst wollten wir alles in einer Datei herunterladen, aber der Fehler "bad_alloc" wurde angezeigt. Offenbar aufgrund der Unfähigkeit von Clickhouse, Speicher zuzuweisen. Es wurde keine Lösung gefunden. Aus diesem Grund wurden 600 Millionen Tupel in 30 Dateien zu je 20 Millionen aufgeteilt, wobei jede Datei etwas länger als 3 Minuten heruntergeladen wurde.
Bei Postgres waren die Dinge komplizierter, aber nur am Anfang. Das Herunterladen von SQL-Rohdateien, die den Befehl INSERT INTO <Tabellenname> (Attribute) VALUES tuples enthalten, ist zeitaufwändig. Daher wurde alles in das CSV-Format konvertiert und der Befehl COPY <Tabellenname> FROM WITH CSV ausgeführt.
Es ist erwähnenswert, dass wir zuerst die Daten in eine reguläre Postgres-Tabelle geladen haben, von wo aus wir sie in eine fremde Tabelle kopiert haben, die von cstore gesteuert wird. Aus diesem Grund dauerte das Laden von Postgres aus einer CSV-Datei auch etwas weniger als zwei Stunden.
Leistungsvergleich
Der Leistungsvergleich von Postgres und Clickhouse ist in der folgenden Tabelle dargestellt. Aber ohne Indizes zu erstellen und Datenbankparameter zu ändern. Irgendwann war der Speicher auf der Festplatte fast voll. Daher musste eine nicht komprimierte reguläre Tabelle aus Postgres gelöscht werden. Derzeit sind nur Tabellen im Clickhouse- und Postgres-Store verfügbar.
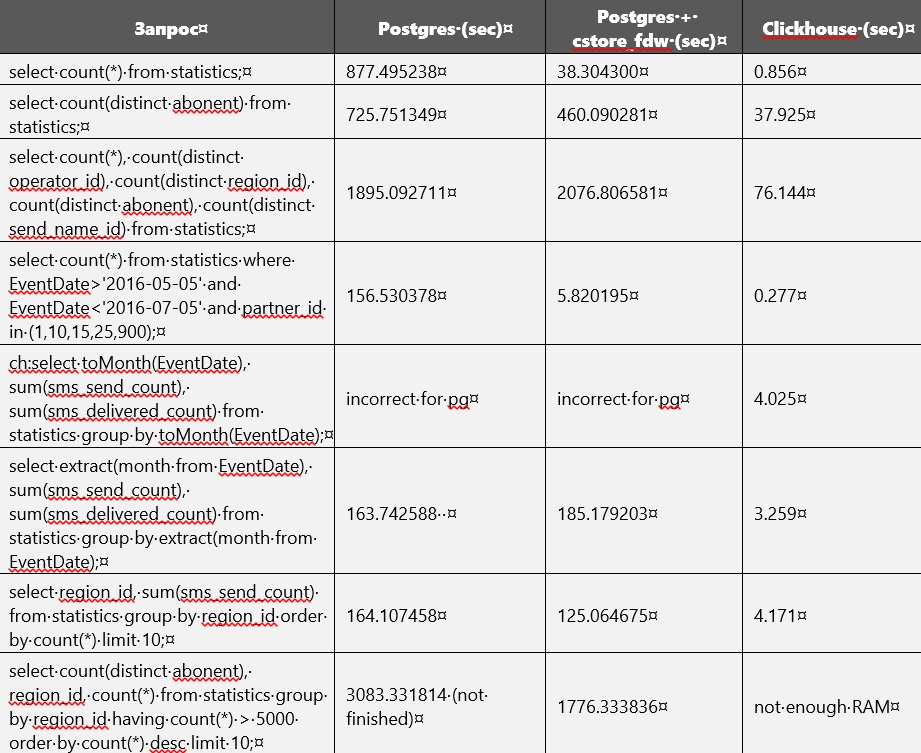
Anscheinend konzentriert sich cstore auf das erste Attribut, das beim Erstellen angegeben wurde. Mit anderen Worten, er sortiert alle Daten danach. Dies kann leicht bemerkt werden, da die Abfragen im Zusammenhang mit EventDate in cstore schneller ausgeführt wurden als in Postgres.
Bei der Ausführung von Abfragen benötigte Postgres manchmal bis zu 27 GB für temporäre Dateien auf einem externen Laufwerk.
Clickhouse beansprucht viel RAM.
In der Konfigurationsdatei /etc/clickhouse/users.xml wurden <max_memory_usage> 12000000000 </ max_memory_usage> und <max_bytes_before_external_sort> 1000000000 </ max_btes_before_external_sort> angegeben.
Für einige Anfragen reichte der Arbeitsspeicher nicht aus, weshalb wir ihn erhöhen mussten. Danach wurde die Bearbeitung der Anfragen fortgesetzt, aber bei der letzten Anfrage wurde sie noch unterbrochen. Es standen mehrere weitere Parameter zur Verfügung, um den Speicherverbrauch zu begrenzen: https://clickhouse.yandex/docs/ru/query_language/queries/ .
So kam es, dass wir Clickhouse ein wenig mehr Daten hinzufügten: 695_640_000 Tupel anstelle von 600_000_000, aber das hinderte ihn nicht am Gewinnen.
In cstore_fdw können Sie verschiedene Parameter konfigurieren, die sich auf die Leistung auswirken: https://github.com/citusdata/cstore_fdw/issues/174 , https://github.com/citusdata/cstore_fdw .
Partitionierung
Die Partitionierung finden Sie auch in Clickhouse unter https://github.com/yandex/ClickHouse/blob/master/docs/ru/table_engines/custom_partitioning_key.md , https://clickhouse.yandex/docs/ru/table_engines/custom_partitioning_key / und in Postgres (10 und 11 Versionen). Ein Beispiel für die Partitionierung in clickhouse finden Sie unter https://github.com/yandex/ClickHouse/blob/master/dbms/tests/queries/0_stateless/00502_custom_partitioning_local.sql und https://github.com/yandex/ClickHouse/issues/1513 .
Die Verwendung der Partitionierung in Postgres ist möglich, vorausgesetzt, dass cstore nur mit fremden Tabellen funktioniert, da Sie einen Server dafür erstellen müssen und Sie keinen Server für reguläre Tabellen angeben können. Eine Fremdtabelle kann nicht in Partitionen unterteilt werden, sondern selbst als Partition fungieren. Daher gibt es nur eine Möglichkeit, die Partitionierung zu verwenden: Erstellen Sie eine reguläre übergeordnete Tabelle, und fügen Sie ihr fremde Tabellen in Form von Partitionen hinzu, die bereits auf cstore_fdw funktionieren.
Bei Clickhouse funktioniert die Partitionierung sofort.
Fazit
Aus diesem Grund haben wir uns für Clickhouse entschieden, weil es intelligent ist: Es ist immer mindestens zehnmal schneller als Analoge. Auf Speicherservern gibt es normalerweise mehr als 32 GB, 64 GB und 128 GB, sodass Abfragen in Tabellen mit etwa 50 GB problemlos ausgeführt werden können. Wenn die Tabelle sehr groß ist, hilft das Partitionieren oder Optimieren der Parameter des Clickhouse-Servers.