
Kürzlich las ich ein Buch über Mathematik und die Schönheit von Menschen und dachte darüber nach, wie man vor einem Jahrzehnt verstehen kann, welche menschliche Schönheit ziemlich primitiv war. Die Überlegung, welches Gesicht aus mathematischer Sicht als schön angesehen wird, beruhte auf der Tatsache, dass es symmetrisch sein sollte. Seit der Renaissance gab es auch Versuche, schöne Gesichter anhand der Entfernungsverhältnisse an einigen Gesichtspunkten zu beschreiben und zum Beispiel zu zeigen, dass schöne Gesichter eine Beziehung haben, die nahe am goldenen Schnitt liegt. Ähnliche Vorstellungen über die Position von Punkten werden jetzt als eine der Methoden zum Identifizieren von Gesichtern (Suche nach Gesichtspunkten) verwendet. Wie die Erfahrung zeigt, können Sie jedoch bei einer Reihe von Aufgaben bessere Ergebnisse erzielen, z.
B. bei der Bestimmung des Alters, des Geschlechts oder sogar der
sexuellen Orientierung , wenn Sie die Anzahl der Zeichen nicht auf die Position bestimmter Punkte im Gesicht beschränken. Es ist hier bereits offensichtlich, dass die Frage der Ethik der Veröffentlichung der Ergebnisse solcher Studien eine akute sein kann.
Das Thema der Schönheit der Menschen und ihre Bewertung kann auch ethisch umstritten sein. Bei der Entwicklung der Anwendung haben sich viele meiner Freunde geweigert, ihre Fotos für Tests zu verwenden, oder wollten das Ergebnis einfach nicht wissen (es ist lustig, dass sich die meisten Mädchen weigerten, die Ergebnisse zu kennen). Auch das Ziel der Automatisierung der Schönheitsprüfung kann interessante philosophische Fragen aufwerfen. Inwieweit wird der Schönheitsbegriff von der Kultur bestimmt? Wie wahr ist „Schönheit im Auge des Betrachters“? Ist es möglich, objektive Anzeichen von Schönheit hervorzuheben?
Um diese Fragen zu beantworten, müssen Sie die Statistiken über die Bewertungen einiger Personen durch andere Personen studieren. Ich habe versucht, ein neuronales Netzwerkmodell zu entwerfen und zu trainieren, das die Schönheit bewertet und auf einem Android-Telefon ausführt.
Teil 0. Pipeline
Um zu verstehen, wie die nächsten Schritte miteinander zusammenhängen, habe ich ein Diagramm des Projekts gezeichnet:
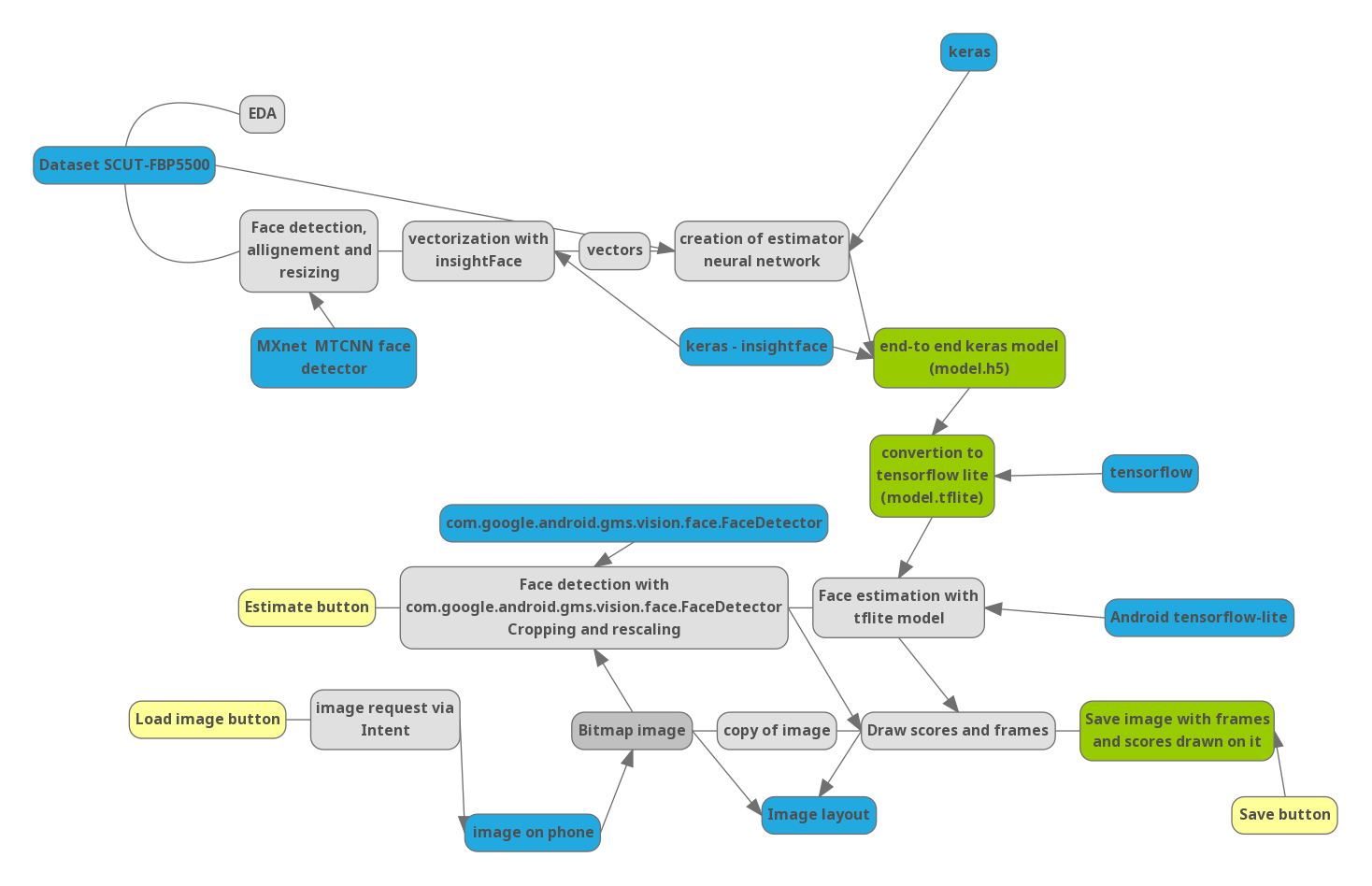
Blau - wichtige Bibliotheken und externe Daten. Gelb - Steuerelemente in der Anwendung.
Teil 1. Python
Da die Bewertung von Schönheit ein ziemlich heikles Thema ist, gibt es nicht sehr viele Datensätze im öffentlichen Bereich, die Fotos mit einer Bewertung enthalten (ich bin sicher, dass Online-Dating-Dienste wie der Zunder viel umfangreichere Statistiken haben). Ich fand
eine Datenbank, die an einer der Universitäten in China zusammengestellt wurde und 5500 Fotos enthielt, die jeweils von 7 Bewertern unter chinesischen Studenten ausgewertet wurden. Von den 5.500 Fotografien sind 2.000 asiatische Männer (AM), 2.000 asiatische Frauen (AF) und jeweils 750 europäische Männer (CM) und Frauen (CF).
Lassen Sie uns die Daten mit dem Python-Pandas-Modul lesen und einen kurzen Blick auf die Daten werfen. Geschätzte Verteilung für verschiedene Geschlechter und Rassen:
import pandas as pd import matplotlib.pyplot as plt ratingDS=pd.read_excel('../input/faces-scut/scut-fbp5500_v2/SCUT-FBP5500_v2/All_Ratings.xlsx') Answer=ratingDS.groupby('Filename').mean()['Rating'] ratingDS['race']=ratingDS['Filename'].apply(lambda x:x[:2]) fig, ax = plt.subplots(2, 2, sharex='col') for i, race in enumerate(['CF','CM','AF','AM']): sbp=ax[i%2,i//2] ratingDS[ratingDS['race']==race].groupby('Filename')['Rating'].mean().hist(alpha=0.5, bins=20,label=race,grid=False,rwidth=0.9,ax=sbp) sbp.set_title(race)
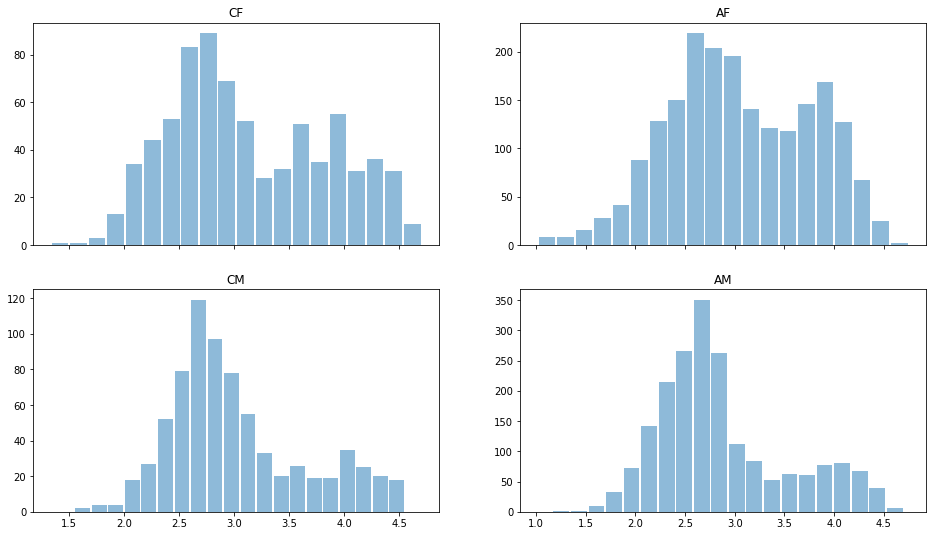
Es ist zu sehen, dass Männer im Allgemeinen als weniger schön gelten als Frauen, die Verteilung ist bimodal - es gibt solche. die als schön und "durchschnittlich" gelten. Es gibt fast keine niedrigen Bewertungen, sodass die Daten renormiert werden könnten. Aber lassen wir sie jetzt.
Sehen wir uns die Standardabweichung in den Schätzungen an:
ratingDS.groupby('Filename')['Rating'].std().mean()
Es ist 0,64, was bedeutet, dass der Unterschied bei den Bewertungen der verschiedenen Bewerter weniger als 1 von 5 Punkten beträgt, was auf Einstimmigkeit bei den Bewertungen der Schönheit hinweist. Man kann mit Recht sagen, dass "Schönheit NICHT im Auge des Betrachters liegt". Bei der Mittelwertbildung können Sie die Daten zuverlässig zum Trainieren des Modells verwenden und müssen sich nicht um die grundsätzliche Unmöglichkeit einer programmgesteuerten Auswertung kümmern.
Trotz des geringen Wertes der Standardabweichung der Schätzung kann sich die Meinung einiger Bewerter stark von der "normalen" unterscheiden. Bauen wir die Verteilung der Differenz zwischen Schätzung und Median auf:
R2=ratingDS.join(ratingDS.groupby('Filename')['Rating'].median(), on='Filename', how='inner',rsuffix =' median') R2['ratingdiff']=(R2['Rating median']-R2['Rating']).astype(int) print(set(R2['ratingdiff'])) R2['ratingdiff'].hist(label='difference of raings',bins=[-3.5,-2.5,-1.5,-0.5,0.5,1.5,2.5,3.5,4.5],grid=False,rwidth=0.5)
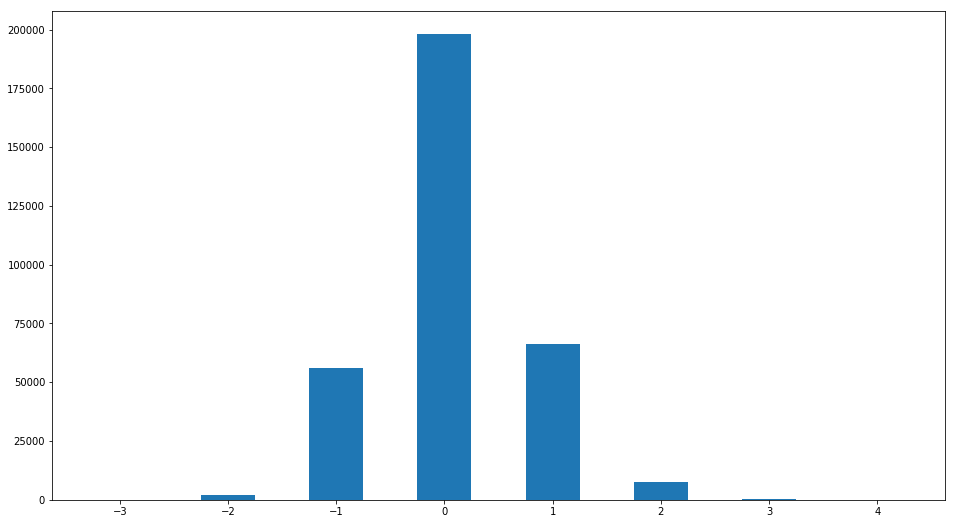
Es wurde ein interessantes Muster gefunden. Personen, deren Punktzahl um mehr als 1 Punkt vom Median abweicht
len(R2[R2['ratingdiff'].abs()>1])/len(R2)
0.02943333333333333332
Weniger als 3%. Das heißt, eine auffallende Einstimmigkeit wird erneut in Bezug auf die Beurteilung der Schönheit bestätigt.
Erstellen Sie eine Tabelle mit den erforderlichen Durchschnittsbewertungen
Answer=ratingDS.groupby('Filename').mean()['Rating']
Unsere Datenbank ist klein; Außerdem enthalten alle Fotos meist Vollbildaufnahmen, und ich hätte gerne ein zuverlässiges Ergebnis für jede Position des Gesichts. Um Probleme mit einer kleinen Datenmenge zu lösen, wird häufig die Transfer-Lerntechnik verwendet - die Verwendung von Modellen, die für ähnliche Aufgaben vortrainiert sind, und deren Modifikation. Nah an meiner Aufgabe ist die Gesichtserkennungsaufgabe. Es wird in der Regel dreistufig gelöst.
1. Auf dem Bild und seiner Skalierung befindet sich eine Gesichtserkennung.
2. Unter Verwendung eines neuronalen Faltungsnetzwerks wird das Bild des Gesichts in einen Merkmalsvektor umgewandelt, und die Eigenschaften einer solchen Transformation sind derart, dass die Transformation in Bezug auf die Drehung des Gesichts und die Änderung der Frisur invariant ist. Manifestationen von Emotionen und temporären Bildern. Ein solches Netzwerk zu trainieren ist eine interessante Aufgabe für sich, die für eine lange Zeit geschrieben werden kann. Darüber hinaus erscheinen ständig neue Entwicklungen, um diese Umwandlung zu verbessern und die Algorithmen zur Massenverfolgung und Identifizierung zu verbessern. Sie optimieren sowohl die Netzwerkarchitektur als auch die Trainingsmethode (Beispiel Triplett-Verlust - Oberflächen-Bogen-Verlust).
3. Vergleich des Merkmalsvektors mit den in der Datenbank gespeicherten.
Für unsere Aufgabe habe ich fertige Lösungen von 1-2 Punkten verwendet. Das Erkennen von Gesichtern wird in der Regel auf vielfältige Weise gelöst. Darüber hinaus verfügt fast jedes Mobilgerät über Gesichtserkenner (unter Android sind sie Teil des standardmäßigen GooglePlay-Servicepakets), mit denen Gesichter beim Fotografieren scharfgestellt werden. Bezüglich der Übersetzung von Personen in Vektorform gibt es einen nicht offensichtlichen subtilen Punkt. Tatsache ist, dass die Zeichen. extrahiert, um das Erkennungsproblem zu lösen - sind charakteristisch für eine Person, aber sie können überhaupt nicht mit Schönheit korrelieren. Außerdem. Aufgrund der Besonderheiten von neuronalen Faltungsnetzen sind diese Zeichen hauptsächlich lokal und können im Allgemeinen viele Probleme verursachen (Single-Pixel-Angriff). Trotzdem stellte ich fest, dass die Ergebnisse stark von der Dimension des Vektors abhängen. Wenn 128 Zeichen nicht ausreichen, um die Schönheit zu bestimmen, ist 512 ausreichend. Auf dieser Grundlage wurde ein
vorab geschultes, auf Reset basierendes insightFace-Netzwerk ausgewählt. Wir werden Keras auch als Rahmen für maschinelles Lernen verwenden.
Einen ausführlichen Code zum Herunterladen von vorgefertigten Modellen finden Sie
hier. model=LResNet100E_IR()
Der
mtcnn-Gesichtsdetektor wurde als Gesichtsdetektor für die Vorverarbeitung verwendet
. detector = MtcnnDetector(model_folder=mtcnn_path, ctx=ctx, num_worker=1, accurate_landmark = True, threshold=det_threshold)
Bilder aus dem Datensatz ausrichten, zuschneiden und vektorisieren:
imgpath='../input/faces-scut/scut-fbp5500_v2/SCUT-FBP5500_v2/Images/'
Wir werden die Daten aufbereiten, indem wir sie in Übungsvektoren aufteilen (90% von ihnen werden untersucht) und validieren (wir werden die Arbeit des Modells an ihnen überprüfen). Wir normalisieren die Daten auf einen Bereich von 0-1.
X=np.stack(facevecs)[:,0,:] Y=(Answer[:])/5 Indicies=np.arange(len(Answer)) X,Y,Indicies=sklearn.utils.shuffle(X,Y,Indicies) Xtrain=X[:int(len(facevecs)*0.9)] Ytrain=Y[:int(len(facevecs)*0.9)] Indtrain=Indicies[:int(len(facevecs)*0.9)] Xval=X[int(len(facevecs)*0.9):] Yval=Y[int(len(facevecs)*0.9):] Indval=Indicies[int(len(facevecs)*0.9):]
Kommen wir nun zum Modell. Schönheit beschreiben.
def Createheadmodel(): inp=keras.layers.Input((512,)) x=keras.layers.Dense(32,activation='elu')(inp) x=keras.layers.Dropout(0.1)(x) out=keras.layers.Dense(1,activation='hard_sigmoid',use_bias=False,kernel_initializer=keras.initializers.Ones())(x) model=keras.models.Model(input=inp,output=out) model.layers[-1].trainable=False model.compile(optimizer=keras.optimizers.Adam(lr=0.0001), loss='mse') return model modelhead=Createheadmodel()
Dieses Modell ist ein einschichtiges, vollständig verbundenes neuronales Netzwerk mit 32 Neuronen und 512 Eingangsknoten - eine der einfachsten Architekturen, die jedoch gut trainiert ist:
hist=modelhead.fit(Xtrain,Ytrain, epochs=4000, batch_size=5000, validation_data=(Xval,Yval) )
4950/4950 [==============================] - 0s 3us / Schritt - Verlust: 0,0069 - val_loss: 0,0071
Bauen wir Lernkurven auf
plt.plot(hist.history['loss'][100:], label='loss') plt.plot(hist.history['val_loss'][100:],label='validation_loss') plt.legend(bbox_to_anchor=(0.95, 0.95), loc='upper right', borderaxespad=0.)
Wir sehen, dass der Verlust (mittlere quadratische Abweichung) bei den Validierungsdaten 0,0071 beträgt, daher beträgt die Standardabweichung 0,084 oder 0,42 Punkte auf einer Fünf-Punkte-Skala, was weniger ist als die Streuung in Schätzungen, die von Personen angegeben wurden (0,6 Punkte). Unser Modell arbeitet.
Um die Funktionsweise des Modells zu veranschaulichen, können Sie das Streudiagramm verwenden. Für jedes Foto wird aus den Validierungsdaten ein Punkt erstellt, an dem eine der Koordinaten der durchschnittlichen Gesichtsbewertung und die zweite der durchschnittlichen vorhergesagten Bewertung entspricht:
Answer2=Answer.to_frame()[:5500] Answer2['ans']=0 Answer2['race']=Answer2.index Answer2['race']=Answer2['race'].apply(lambda x: x[:2]) Answer2['ans']=modelhead.predict(np.stack(facevecs)[:,0,:])*5 xy=np.array(Answer2.iloc[Indval][['ans','Rating']]) plt.scatter(xy[:,1],xy[:,0])

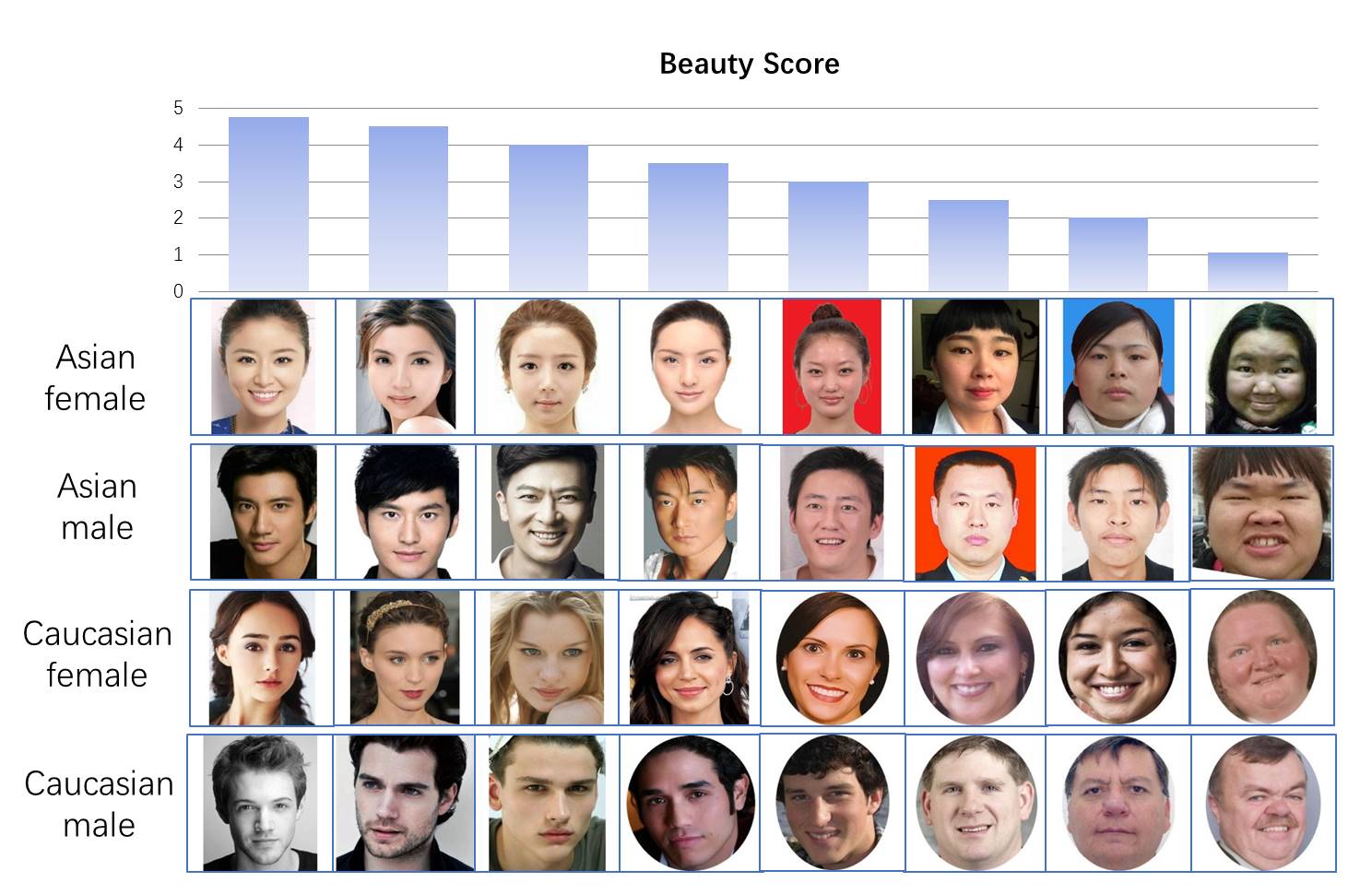
Y-Achse - vom Modell vorhergesagte Werte, X-Achse - Durchschnittswerte der Schätzungen von Personen. Wir sehen eine hohe Korrelation (das Diagramm ist entlang der Diagonale verlängert). Sie können unsere Ergebnisse auch visuell überprüfen - nehmen Sie die Gesichter der einzelnen Kategorien mit vorhergesagten Bewertungen von 1 bis 5
import matplotlib.image as mpimg f, axarr = plt.subplots(4,5,figsize=(10, 10)) for i, race in enumerate(['AF','CF', "AM", 'CM']): for rating in range(1,6):

Wir sehen, dass das Ergebnis beim Sortieren nach Schönheit vernünftig aussieht.
Jetzt erstellen wir ein vollständiges Modell, in dem wir dem Eingang ein Gesicht übergeben, am Ausgang eine Bewertung von 0 bis 1 erhalten und es in das für das Telefon geeignete tflite-Format konvertieren
import tensorflow as tf finmodel=Model(input=model.input, output=modelhead(model.output)) finmodel.save('finmodel.h5') converter = tf.lite.TFLiteConverter.from_keras_model_file('finmodel.h5') converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE] tflite_quant_model = converter.convert() open ("modelquant.tflite" , "wb").write(tflite_quant_model) from IPython.display import FileLink FileLink(r'modelquant.tflite')
Dieses Modell erhält am Eingang ein Bild eines Gesichts mit einer Größe von 112 * 112 * 3 und am Ausgang eine einzelne Zahl von 0 bis 1, was die Schönheit des Gesichts bedeutet (obwohl wir bedenken müssen, dass die Bewertungen im Datensatz nicht von 0 bis 5, sondern von 1 bis 5 variierten).
Teil 2. JAVA
Lassen Sie uns versuchen, eine einfache Anwendung für ein Android-Handy zu schreiben. Die Java-Sprache ist für mich neu und ich war noch nie in der Entwicklung für Android involviert. Daher verwendet das Projekt keine Optimierung der Arbeit, keine Flusskontrolle und andere Dinge, die für Anfänger arbeitsintensiv sind. Da Java-Code ziemlich umständlich ist, gebe ich hier nur die wichtigsten Teile an, damit das Programm funktioniert. Den vollständigen Anwendungscode finden Sie
hier . Die Anwendung öffnet ein Foto, erkennt und bewertet ein Gesicht in einem zuvor gespeicherten Netzwerk und zeigt das Ergebnis an:

Aus entwicklungspolitischer Sicht sind dabei folgende Funktionen wichtig.
1. Die Funktion zum Laden des neuronalen Netzwerks aus der Datei model.tflite im Assets-Ordner in das Interpreter-Objekt
import org.tensorflow.lite.Interpreter; Interpreter interpreter; try { interpreter=new Interpreter(loadModelFile(MainActivity.this)); Log.e("TIME", "Interpreter_started "); } catch (IOException e) { e.printStackTrace(); Log.e("TIME", "Interpreter NOT started "); } private MappedByteBuffer loadModelFile(Activity activity) throws IOException { AssetFileDescriptor fileDescriptor = activity.getAssets().openFd("model.tflite"); FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor()); FileChannel fileChannel = inputStream.getChannel(); long startOffset = fileDescriptor.getStartOffset(); long declaredLength = fileDescriptor.getDeclaredLength(); return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength); }
2. Erkennen von Gesichtern mithilfe des FaceDetector-Moduls, das Teil des Standardbibliothekspakets von Google ist, mithilfe eines neuronalen Netzwerks und Anzeigen der Ergebnisse.
import com.google.android.gms.vision.face.Face; import com.google.android.gms.vision.face.FaceDetector; private void detectFace(){
Wenn Sie mit der Einstufung auf Ihrem Handy spielen möchten, können Sie die
Anwendung vom GooglePlay-Markt herunterladen.