Für Hadoop und Greenplum besteht die Möglichkeit, sich auf SaaS vorzubereiten. Und wenn Khadup eine bekannte Sache ist, dann ist Greenplum (es ist die Basis des ArenadataDB-Produkts, das später besprochen wird) interessant, aber schon weniger "nach Gehör".
Arenadata DB ist ein verteiltes DBMS, das auf Open Source Greenplum basiert. Wie bei anderen MPP-Lösungen (Parallel Data Processing) ist die Cloud-Architektur für massiv parallele Systeme alles andere als optimal. Dies kann die Leistung um bis zu 30% (normalerweise weniger) reduzieren. Trotzdem kann dieses Problem behoben werden (worauf weiter unten eingegangen wird). Darüber hinaus lohnt es sich, einen solchen Service aus der Cloud zu kaufen. Oft ist er im Vergleich zur Bereitstellung Ihres eigenen Clusters bequem und rentabel.
In den Handbüchern wird die Verfügbarkeit vor Ort klar angegeben, aber jetzt erkennen viele Menschen, inwieweit die Cloud praktisch ist. Jeder weiß, dass es zu Leistungseinbußen kommen wird, aber es ist immer noch so praktisch und schnell, dass es bereits Projekte gibt, bei denen dies in einigen Phasen geopfert wird, beispielsweise beim Testen von Hypothesen.
Wenn Sie ein Data Warehouse mit mehr als 1 TB und Transaktionssysteme haben - nicht Ihr Lastprofil -, finden Sie im Folgenden eine Beschreibung der optionalen Maßnahmen. Warum 1 TB? Ab diesem Volumen ist der Einsatz von MPP im Vergleich zu klassischen DBMS im Hinblick auf das Verhältnis von Leistung zu Kosten effizienter.
Wann verwenden?
Wenn das klassische Einknoten-DBMS nach Architektur nicht für Ihre Volumes geeignet ist. Ein häufiger Fall ist ein neues Data Warehouse mit einer Kapazität von mehr als 1 TB. MPP DBMS liegt jetzt im Trend und Greenplum ist eines der besten auf dem Markt für moderne Aufgaben. Vor allem angesichts seiner Offenheit. Es gibt auch eine Reihe von proprietären Systemen mit einer Vielzahl von Funktionen: Terradata, Sap Khan, Exadata, Vertika. Deshalb, wenn Sie sich Ananas und Auerhahn nicht leisten können, dann nehmen Sie die Pflaume.
Der zweite Fall liegt vor, wenn Sie ein vorhandenes Data Warehouse für etwas Universelles wie Oracle oder Post-Congress haben, sich Benutzer jedoch regelmäßig über langsame Berichte beschweren. Und wenn es neue Aufgaben wie Big Data gibt - wenn Benutzer alle Daten sofort benötigen, können sie nicht vorhersagen, was sie mit ihnen tun werden. Es gibt viele Situationen, in denen ein operatives Unternehmen Berichte benötigt, die nur einen Tag relevant sind, und die keine Zeit haben, sich an einem Tag auszuzahlen. Das heißt, es werden grundsätzlich keine Daten benötigt. In diesem Fall ist es auch praktisch, MPP-Datenbanken zu verwenden und SaaS in der Cloud zu testen.
Der dritte Fall ist, wenn jemand der Khadup-Mode folgt und die Standardaufgaben der Stapelverarbeitung strukturierter Daten löst, der Cluster jedoch nicht gut zusammengestellt ist. Wir sehen oft, dass die Technologie ein wenig und gar nicht so angewendet wird, wie sie sollte. Beispielsweise müssen Sie auf Khadup keine relationale Datenbank erstellen. Wenn Ihre Hadoup plötzlich keine Echtzeitverarbeitung mehr hat oder sollte, aber der Administrator und der Entwickler entsetzt flüchteten, können Sie auch in der Cloud nach Greenplum schauen: Die Unterstützung ist sehr einfach, während die Fähigkeit, große Datenmengen zu verarbeiten, erhalten bleibt.
Warum versuchen es nur wenige?
Jedes MPP-DBMS benötigt viel Kapazität. Das ist viel Eisen. Tatsächlich haben die Leute Angst, nur wegen des Einstiegspreises den Proof-of-Concept-Level zu erreichen. Sie können dies nicht physisch tun. Eine der Hauptideen unseres SaaS ist es, Ihnen die Möglichkeit zu geben, mit all dem zu spielen, ohne einen Eisenhaufen zu kaufen.
Und wir treffen uns regelmäßig mit Kunden, die sagen, dass wir nicht allein begleiten, operieren usw. wollen. Und ich würde gerne auslagern. Dies ist ein Analysesystem, das in den meisten Fällen geschäftskritisch, aber nicht geschäftskritisch ist. Viele im Westen lagern aus, wir haben auch vor kurzem angefangen.
Was ist das Beste an MPP?
Klassisches Corporate Data Warehouse: Für alle Datenquellen werden inkrementelle Daten abgerufen, und anschließend werden die Fenster für Benutzer erstellt. Benutzer über diesen Storefronts erstellen ihre Berichte. „Ich möchte jeden Tag sehen, wie es im Geschäft läuft“ - das ist es.
Noch ein paar Worte zur Cloud-Lösung
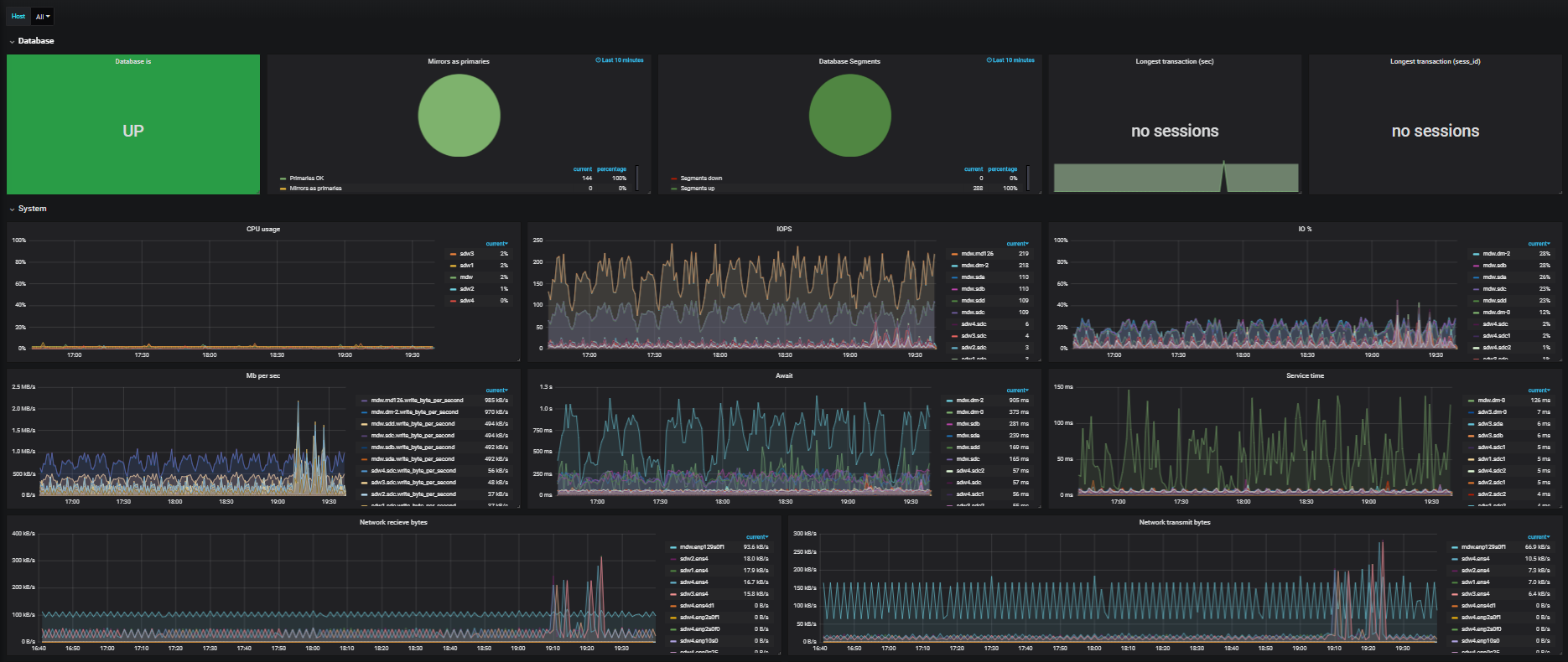
Früher waren solche Infrastrukturen schlecht für Clouds ausgelegt. In der Realität betreten jedoch immer mehr Kunden die Cloud. Für die Arbeit ist eine hohe Leistung erforderlich, da es sich um viele große analytische Abfragen handelt, die viele CPUs verbrauchen, viel Arbeitsspeicher erfordern und hohe Anforderungen an Festplatten und Netzwerkinfrastruktur stellen. Wenn Kunden verteilte DBMS in der Cloud bereitstellen, können daher verschiedene Probleme auftreten.
Das erste Problem ist die schlechte Netzwerkleistung. Da dies alles in der Cloud in einer virtuellen Umgebung geschieht, können sich viele Computer auf einem Hypervisor befinden. Virtuelle Maschinen können auf verschiedene Hypervisoren verteilt sein. Darüber hinaus können sie zu bestimmten Zeitpunkten über verschiedene Rechenzentren verteilt sein und von Supervisoren virtuell bearbeitet werden. Und deshalb leidet das Netzwerk sehr. Bei der Verarbeitung einer Milliarde Datensätze in einer Tabelle werden beispielsweise 10 Server verwendet, und diese Daten werden zwischen allen Servern ausgetauscht. Eine Unterart funktioniert innerhalb eines Servers, und selbst innerhalb eines Servers funktionieren viele solcher Unterarten. Es können 10 bis 20 sein, und jetzt beginnen alle, während der Ausführung der Anforderung Daten über das Netzwerk zu übertragen. Das Netzwerk fällt wie Winterkulturen. Welche Schlussfolgerung kann daraus gezogen werden? Verwenden Sie Clouds mit hoher Bandbreite, z. B. die CROC Cloud, die 56 GB für Infiniband bietet.
Das zweite Problem besteht darin, dass Firewalls und DDoS-Schutz sehr verzerrt aussehen. Abgebrochen, entschied. Vor der Verwendung wird empfohlen, eine zusätzliche Stunde einzuplanen, um alle Einstellungen zu überprüfen.
Immer noch nicht wahrnehmbar Live-Migration und Aktualisierung. Um einen Computer auf einen anderen Hypervisor und zurück zu ziehen, müssen Sie keine Pakete verlieren. Es ist notwendig, mit den Einstellungen am Ende zu schamanisieren. Zum Beispiel sind wir fast sofort aufgestiegen, um die Zwischenablage zu vergrößern. MTU auf 9.000 Jumboframe angehoben.
Natürlich Laufwerke mit Festplatte. Sie mögen einen solchen Datensatz wirklich nicht, besonders wenn es sich um sehr, sehr zufällige Sektoren in der Warteschlange mit den restlichen Anforderungen handelt. Wir haben beschlossen, den Speicher in Segmente zu unterteilen: eines ist nur für Greenplum, das andere wird gemeinsam genutzt. Dies ist in Situationen erforderlich, in denen ein Dutzend Kunden Greenplum-Installationen parallel bereitstellen. MPP nutzt das Festplattensubsystem so weit wie möglich aus, Cloud-Dienste sind mit dem Speicher verbunden, und die Leistung dort ist nahezu identisch mit der des Kanals. Wenn nicht alle Clients der Cloud MPP berechnen, können Sie einen sehr signifikanten Gewinn erzielen. Eine effiziente Energieverteilung in solchen Lasten funktioniert sehr gut.
Und aufgrund seiner eigenen Architektur ist Greenplum in der Cloud effizienter als Redshift, BigQuery und Snowflake.
Wie die Bereitstellung aussieht:
So:
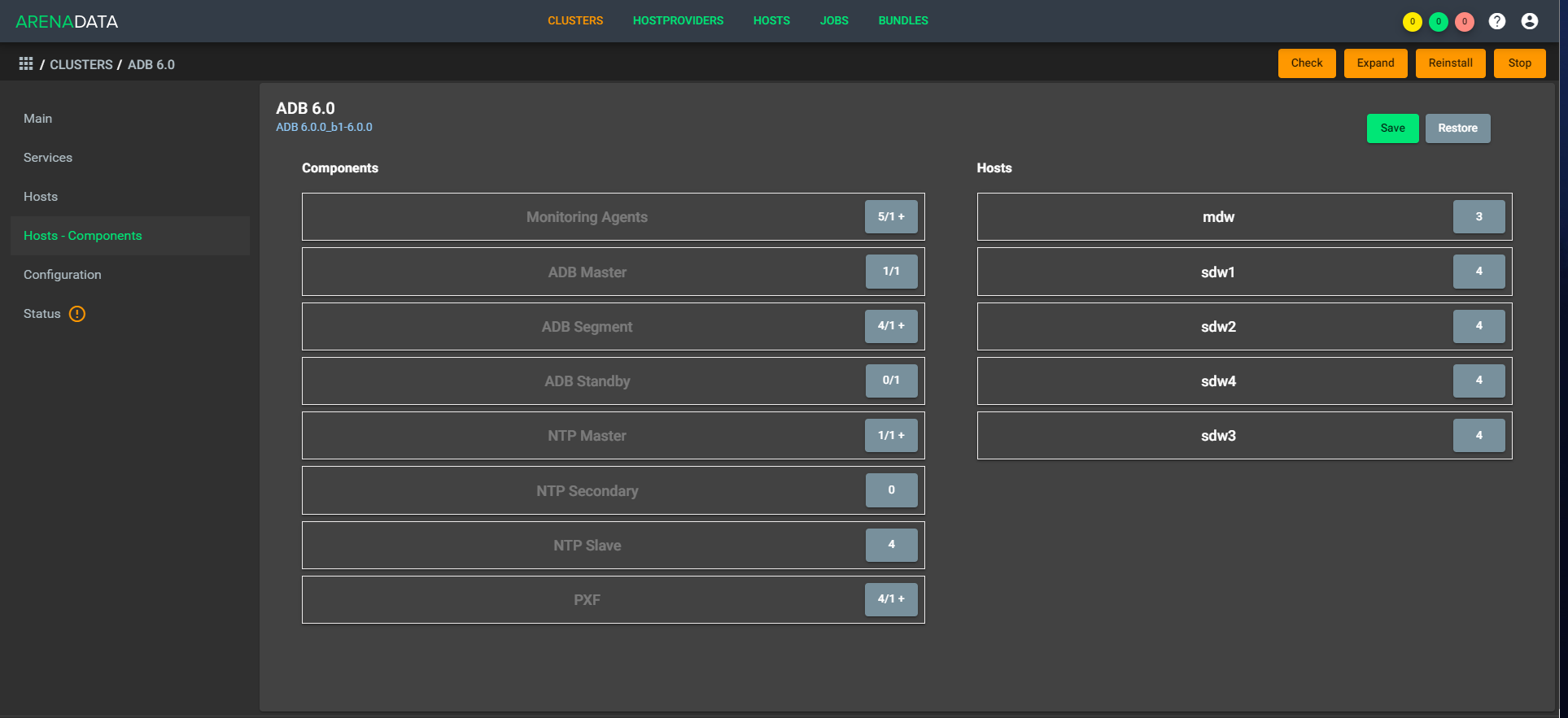
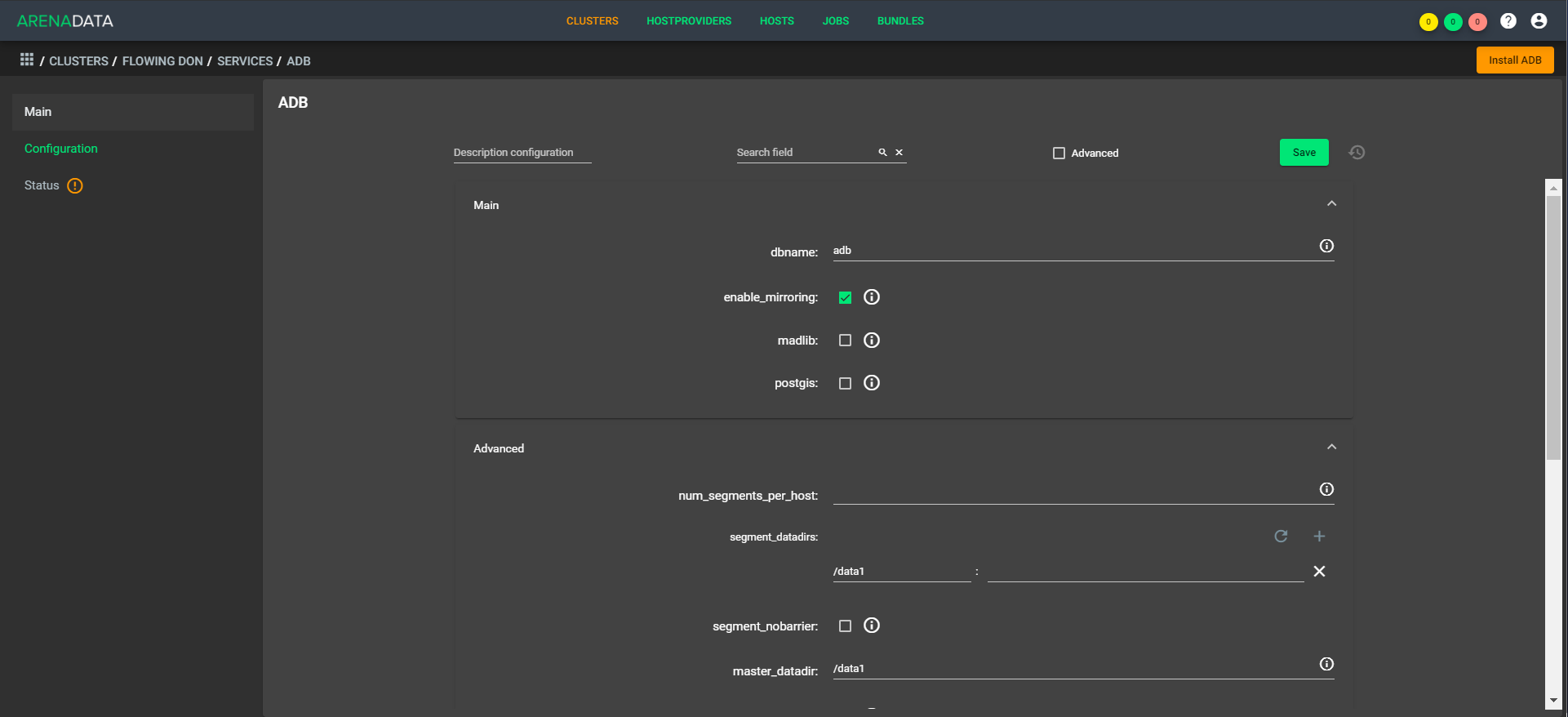
Die Architektur ist "atmungsaktiv", dh Sie können schnell einen einfachen Faktor in der Konfiguration bereitstellen. Am Nachmittag haben wir beispielsweise fünf CPUs, und am Abend steigen 1.000 Handler, und zehn CPUs arbeiten. In diesem Fall müssen Sie die Daten nicht ausgleichen, da sie sich im selben Speicher befinden. Eine Erweiterung ist sofort verfügbar. Die schnelle Komprimierung muss noch ein wenig abgeschlossen werden.
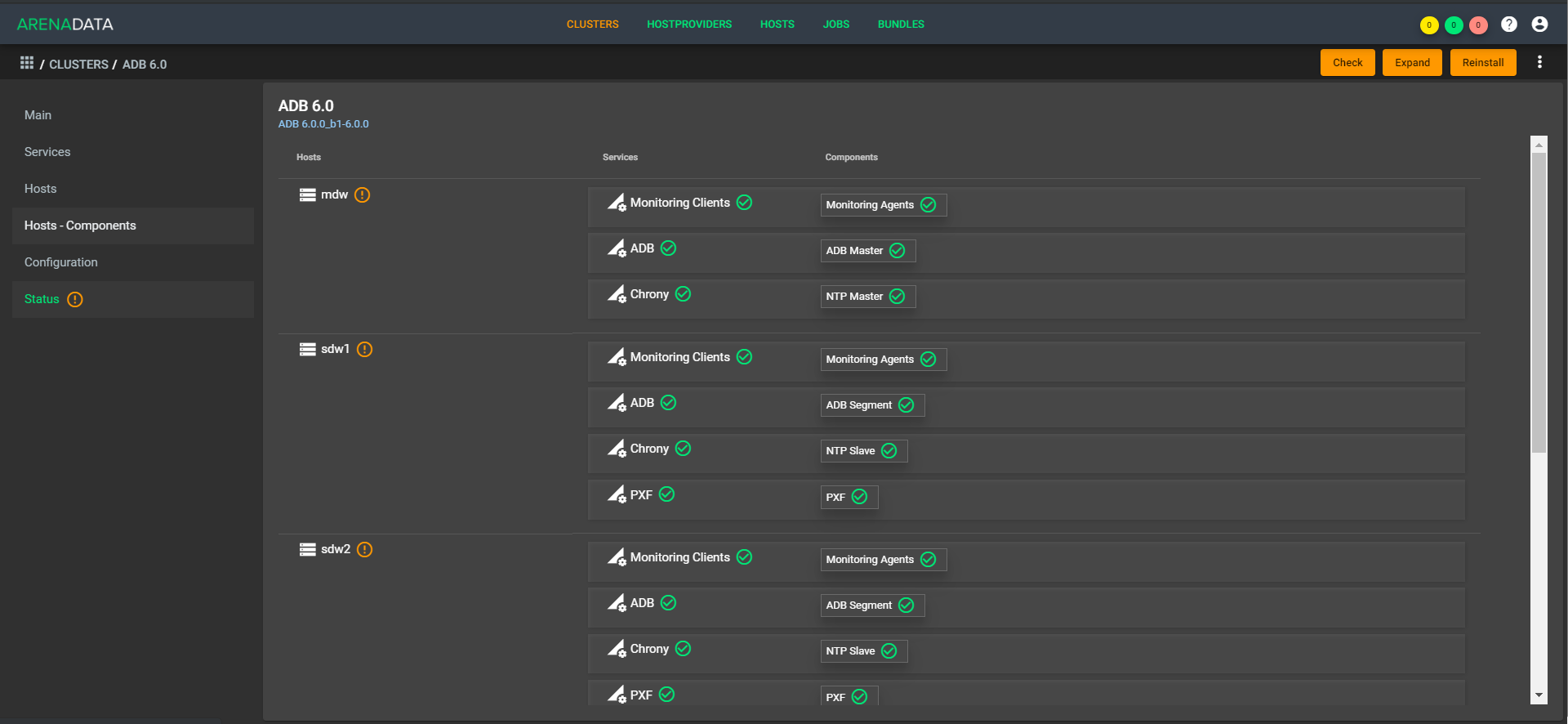
Jetzt gibt es für den Kunden eine zentrale Verwaltungsstelle. Er kommt an einen Ort, wirft dort eine Anfrage wie: "Bereitstellen eines Clusterplans für mich auf solchen Maschinen", und unser Support stellt die Maschinen in der Cloud bereit (bei uns oder beim Kunden), platziert Greenplum dort, startet, konfiguriert und nimmt alle Einstellungen vor. Gleiches gilt für die Überwachung, Verwaltung und Aktualisierung. Während der Automatisierung werden die Schaltflächen in Ihrem Konto weiterhin unterstützt.
Wir haben zuerst die Zweckmäßigkeit eines solchen Ansatzes für interne Projekte verstanden und dann begonnen, SaaS für Kunden bereitzustellen. Wir haben eine tiefe Integration mit S3 - dies ermöglicht es Ihnen, Greenplum als System mit getrennten Ebenen für Computing und Storage zu verwenden oder S3 für Backups und Greenplum als Kern in QCD in der Cloud zu verwenden. Mit der CROC-API und der ADCM-API können Umgebungen für Unternehmen flexibel bereitgestellt werden.