Am Vorabend des Kursbeginns „Mathematik für Data Science. Advanced Course “führten wir ein offenes Webinar zum Thema„ Methoden der Regressionsanalyse in der Datenwissenschaft “durch. Daraufhin haben wir uns mit dem Konzept der linearen Regressionen vertraut gemacht, untersucht, wo und wie sie in der Praxis angewendet werden können, und erfahren, welche Themen und Abschnitte der mathematischen Analyse, der linearen Algebra und der Wahrscheinlichkeitstheorie in diesem Bereich verwendet werden. Dozent - Peter Lukyanchenko , Dozent an der Hochschule für Wirtschaft, Leiter Technologieprojekte.
Wenn wir im Kontext von Data Science über Mathematik sprechen, können wir die drei am häufigsten gelösten Probleme herausgreifen (obwohl es natürlich mehr Probleme gibt):

Sprechen wir über diese Aufgaben im Detail:
- Die Aufgabe der Regressionsanalyse oder der Identifizierung von Abhängigkeiten (wenn wir eine Reihe von Beobachtungen haben). In der obigen Grafik können Sie sehen, dass es eine bestimmte Variable x und eine bestimmte Variable y gibt, und wir beobachten die Werte von y für ein bestimmtes x. Wir kennen diese Punkte und kennen ihre Koordinaten, und wir wissen auch, dass x y irgendwie beeinflusst, das heißt, diese beiden Variablen sind voneinander abhängig. Natürlich wollen wir die Abhängigkeitsgleichung berechnen - hierfür verwenden wir das Modell der klassischen paarweisen linearen Regression , wenn angenommen wird, dass ihre Abhängigkeit durch eine bestimmte Gerade beschrieben werden kann. Dementsprechend werden dann die Geraden-Koeffizienten ausgewählt, um den Fehler in der Beschreibung der Daten zu minimieren. Und genau davon, welche Art von Fehler (Qualitätsmetrik) ausgewählt wird, hängt das tatsächliche Ergebnis der Konstruktion einer linearen Regression ab.
- Eine weitere Aufgabe der Datenanalyse sind Empfehlungssysteme . Dies ist, wenn wir sagen, dass es zum Beispiel Online-Shops gibt, die eine bestimmte Menge von Waren haben und eine Person Einkäufe tätigt. Basierend auf diesen Informationen ist es möglich, eine Beschreibung dieser Person im Vektorraum bereitzustellen und, nachdem dieser Vektorraum erstellt wurde, eine mathematische Abhängigkeit von der Wahrscheinlichkeit zu erstellen, mit der diese Person dieses oder jenes Produkt in Kenntnis ihrer vorherigen Einkäufe kaufen wird. Dementsprechend sprechen wir von Klassifizierung, wenn wir potenzielle Käufer nach den Grundsätzen „Kaufen-Nicht-Kaufen“, „Interessant-Uninteressant“ usw. klassifizieren. Es gibt verschiedene Ansätze: benutzerbasiert und artikelbasiert.
- Der dritte Bereich ist Computer Vision . Im Rahmen dieser Aufgabe versuchen wir festzustellen, wo sich das für uns interessante Objekt befindet. Dies ist eigentlich eine Lösung für das Problem der Fehlerminimierung, indem bestimmte Pixel ausgewählt werden, die das Bild des Objekts bilden.
Bei allen drei Problemen gibt es Optimierung, Fehlerminimierung und das Vorhandensein des einen oder anderen Modells, das die Abhängigkeit von Variablen beschreibt. Gleichzeitig befindet sich in jedem eine Darstellung von Daten, die in eine Vektorbeschreibung zerlegt werden. In unserem Artikel widmen wir dem Abschnitt, der sich auf
Regressionsmodelle auswirkt, besondere Aufmerksamkeit.
Wir haben bereits erwähnt, dass es eine Reihe von Datenpaaren gibt: X und Y. Wir wissen, welche Werte Y in Bezug auf X annimmt. Wenn X die Zeit ist, erhalten wir ein Zeitreihenmodell, in dem Y beispielsweise der Ölpreis ist und zur gleichen Zeit, der Rubel-Dollar-Wechselkurs, und X ist ein bestimmter Zeitraum von 2014 bis 2018:
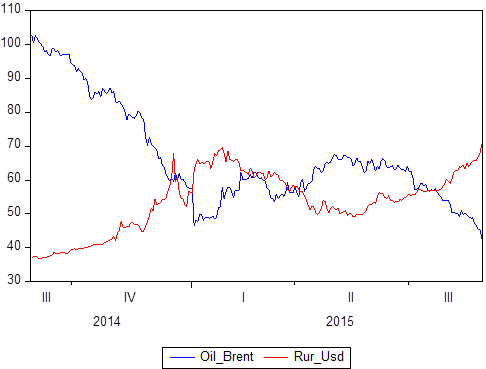
Wenn Sie grafisch erstellen, ist klar, dass diese beiden Zeitreihen voneinander abhängig sind. Nachdem Sie das Konzept der Korrelation definiert haben, können Sie den Grad ihrer Abhängigkeit berechnen. Wenn Sie dann wissen, dass einige Werte perfekt korreliert sind (die Korrelation ist 1 oder -1), können Sie dies entweder für Prognoseaufgaben oder für Beschreibungsaufgaben verwenden.
Betrachten Sie die folgende Abbildung:
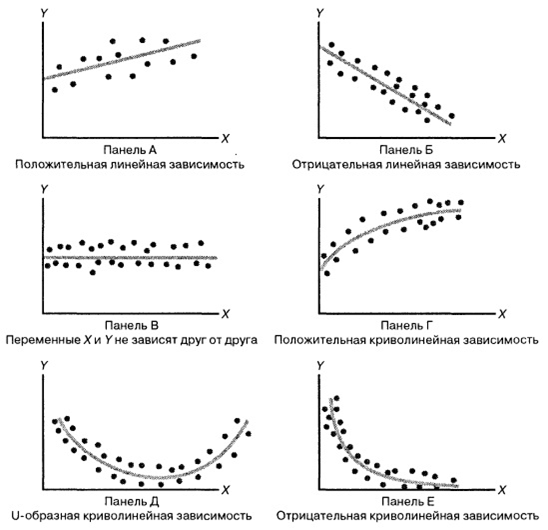
Der schwierigste Teil bei der Bildung eines Regressionsmodells besteht darin,
zunächst eine bestimmte Funktion in sein Gedächtnis zu übernehmen . Zum Beispiel ist in Abbildung A Y = kX + b, in Abbildung C ist Y = -kX + b, in Abbildung C ist das „Spiel“ gleich einer Zahl, der Graph in Abbildung D basiert höchstwahrscheinlich auf der Wurzel von X ”, an der Basis von D, möglicherweise eine Parabel, und an der Basis von E - eine Übertreibung.
Es stellt sich heraus, dass
wir ein Modell der Datenabhängigkeit wählen und die Arten der Abhängigkeit zwischen Zufallsvariablen unterschiedlich sind. Alles ist nicht so offensichtlich, denn auch in diesen einfachen Zeichnungen sehen wir verschiedene Abhängigkeiten. Durch Auswahl einer bestimmten Beziehung können wir Regressionsmethoden verwenden, um das Modell zu kalibrieren.
Die Qualität Ihrer Prognosen hängt davon ab, welches Modell Sie auswählen . Wenn wir uns auf lineare Regressionsmodelle konzentrieren, nehmen wir an, dass es eine Reihe von reellen Werten gibt:

Die Abbildung zeigt die 4 beobachteten Werte von X1, X2, X2, X4. Für jedes der X ist der Y-Wert bekannt (in unserem Fall sind dies die Punkte: P1, P2, P3, P4). Dies sind die Punkte, die wir tatsächlich auf den Daten beobachten. So haben wir einen bestimmten Datensatz erhalten. Aus irgendeinem Grund haben wir entschieden, dass die lineare Regression die Beziehung zwischen dem X und dem Spieler am besten beschreibt. Weiterhin ist die ganze Frage, wie die Gleichung einer geraden Linie Y = b
1 + b
2 X zu konstruieren ist, wobei b
2 der Steigungskoeffizient ist, b
1 der Schnittkoeffizient ist. Die ganze Frage ist, welche b
2 und b
1 am besten eingestellt sind, damit diese Gerade die Beziehung zwischen diesen Variablen so genau wie möglich beschreibt.
Die Punkte R
1 , R
2 , R
3 , R
4 sind die Werte, die unser Modell bei den Werten von X ausgibt. Was passiert? Punkte P sind Punkte, die wir tatsächlich beobachten (tatsächlich gesammelt), und Punkte R sind Punkte, die wir in unserem Modell beobachten (die, die es produziert). Was folgt, ist eine wahnsinnig einfache menschliche Logik: Ein
Modell wird nur dann als qualitativ angesehen, wenn die Punkte R so nahe wie möglich an den Punkten P liegen .
Wenn wir den Abstand zwischen diesen Punkten für dasselbe „X“ (P
1 - R
1 , P
2 - R
2 usw.) konstruieren, erhalten wir sogenannte lineare Regressionsfehler. Wir erhalten die Abweichungen in linearer Regression und diese Abweichungen heißen U
1 , U
2 , U
3 ... U
n . Und diese Fehler können entweder positiv oder negativ sein (wir könnten sie überschätzen oder unterschätzen). Um diese Abweichungen zu vergleichen, müssen sie analysiert werden. Hier wird eine sehr große und schöne Methode angewendet - Quadrieren (Quadrieren "tötet" das Zeichen). Und die Summe der Quadrate aller Abweichungen in der mathematischen Statistik heißt RSS (Residual Sum of Squares). Durch Minimieren von RSS um b
1 und durch Minimieren von RSS um b
2 erhalten wir optimale Koeffizienten, die tatsächlich
durch die Methode der kleinsten Quadrate abgeleitet werden .
Nachdem wir die Regression aufgebaut haben, die optimalen Koeffizienten b
1 und b
2 bestimmt haben und die Regressionsgleichung vorliegen, enden die Probleme nicht dort und das Problem entwickelt sich weiter. Tatsache ist, dass, wenn die Regression selbst in einem Diagramm markiert ist, alle Werte, die wir haben, sowie die Durchschnittswerte der „Spiele“, die Summe der quadratischen Fehler geklärt werden kann.
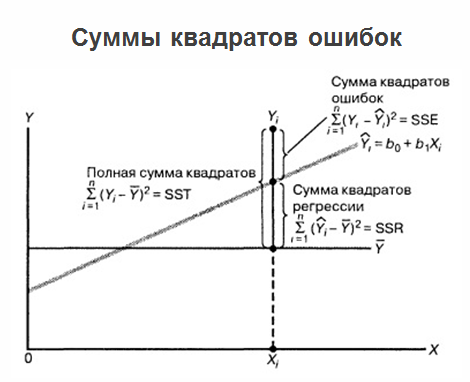
Gleichzeitig wird es als nützlich erachtet, Fehler bei der Regressionsvorhersage in Bezug auf die Variable X anzuzeigen. Siehe folgende Abbildung:

Wir haben eine Art Regression und haben die realen Daten gezogen. Wir haben den Abstand von jedem realen Wert zur Regression. Und wir haben es relativ zum Nullwert für die entsprechenden Werte von X gezeichnet. Und in der obigen Abbildung sehen wir ein wirklich schlechtes Bild: Die
Fehler hängen von X ab. Eine gewisse Korrelationsabhängigkeit wird klar ausgedrückt:
Je weiter wir uns entlang des "X" bewegen, desto größer ist die Signifikanz von Fehlern . Das ist sehr schlecht. Das Vorhandensein einer Korrelation in diesem Fall weist darauf hin, dass wir das Regressionsmodell fälschlicherweise übernommen haben und dass es einige Parameter gab, an die wir „nicht gedacht“ oder die wir einfach aus den Augen verloren haben. Wenn alle Variablen im Modell platziert sind, sollten die Fehler vollständig zufällig sein und nicht davon abhängen, welche Faktoren gleich sind.
Fehler müssen mit der gleichen Wahrscheinlichkeitsverteilung vorliegen , sonst sind Ihre Vorhersagen fehlerhaft. Wenn Sie die Fehler Ihres Modells in der Ebene gezeichnet haben und auf ein divergierendes Dreieck gestoßen sind, ist es besser, von vorne zu beginnen und das Modell vollständig neu zu erzählen.
Durch die Analyse von Fehlern können Sie sogar sofort nachvollziehen, wo sie sich verrechnet haben und welche Art von Fehler sie gemacht haben. Und hier darf der Gauß-Markov-Satz nicht fehlen:

Der Satz bestimmt die Bedingungen, unter denen die durch die Methode der kleinsten Quadrate erhaltenen Schätzungen die besten, konsistentesten und effektivsten in der Klasse der linearen unverzerrten Schätzungen sind.
Die Schlussfolgerung kann wie folgt gezogen werden: Jetzt verstehen wir, dass der
Bereich der Erstellung eines Regressionsmodells gewissermaßen der Höhepunkt aus der Sicht der Mathematik ist , da alle möglichen Abschnitte gleichzeitig zusammengeführt werden, was zum Beispiel bei der Datenanalyse nützlich sein kann:
- lineare Algebra mit Datendarstellungsmethoden;
- mathematische Analyse mit Optimierungstheorie und Mitteln zur Funktionsanalyse;
- Wahrscheinlichkeitstheorie mit Mitteln zur Beschreibung zufälliger Ereignisse und Größen und zur Modellierung der Beziehung zwischen Variablen.
Trotzdem schlage ich vor, Kollegen, nicht nur das gesamte Webinar zu lesen und anzusehen . Der Artikel enthielt keine Momente in Bezug auf lineare Programmierung, Optimierung in Regressionsmodellen und andere Details, die für Sie nützlich sein könnten.