R ist ein sehr leistungsfähiges Werkzeug für die Arbeit mit Statistiken: von der Vorverarbeitung bis zur Erstellung von Modellen beliebiger Komplexität und entsprechender Grafiken.
Eine einfache Google-Anfrage liefert eine große Menge an Literatur zum Thema „Einfache und schnelle Verwendung von R“. Es werden riesige Bücher und zahlreiche Notizen zum Stapelüberlauf angezeigt , die auf den ersten Blick wie ein endloses Lagerhaus von Beispielen wirken, von denen jedes in zwei Zählungen vorliegt sammelt den notwendigen Code, um ein bestimmtes Problem zu lösen. In Wirklichkeit ist dies jedoch überhaupt nicht wahr. Es gibt nur sehr wenige Materialien, aus denen hervorgeht, wie ein einfacher Zeitplan „von Grund auf“ mit vorgefertigten Rezepten erstellt werden kann, um die bei der Lösung dieses Problems auftretenden Probleme zu lösen.
Um praktische Probleme zu lösen, sind spezifische schrittweise Anleitungen erforderlich und keine detaillierte Beschreibung der vollen Leistungsfähigkeit eines Pakets. Darüber hinaus sind vorgefertigte Fallstudien (die gleichen Schwertlilien ) oft wenig nützlich, da sie eine der wichtigsten Phasen der Arbeit mit Statistiken überspringen - die vorläufige Erfassung und Verarbeitung der Daten selbst. Aber genau für diese Arbeit braucht fast ein Großteil aller Zeit oft! Ein separates Problem ist die Erstellung von Zeitplänen, die formellen und häufig informellen Standards eines bestimmten beruflichen Umfelds entsprechen.
Meine Kollegen und ich müssen regelmäßig mehr und mehr Statistiken und darauf basierende Modelle visualisieren, um wissenschaftliche Ergebnisse zu veröffentlichen. Da sich das Studium mit Wirtschaft befasst, ähneln viele dieser Arbeiten dem professionellen Journalismus.
Irgendwann wurde klar, dass für eine effektive Teamarbeit eine Art vollwertige Pipeline für die Verarbeitung von Statistiken erforderlich ist. Dieser Artikel wurde als Einführung für Kollegen und als Spickzettel für mich zum Betrieb dieses Förderers erstellt. Es scheint, dass dieses Material für ein breiteres Publikum nützlich sein kann.
R Schmerzfreie Grafik: Komplettlösung
Grundeinstellung R
Zum Arbeiten benötigen Sie ein Standardpaket: R + RStudio . Sie sind für alle gängigen Plattformen kostenlos erhältlich. R wird zuerst installiert, dann RStudio. Es gibt normalerweise keine Probleme.
Bevor Sie arbeiten, ist es besser, das neue Skript sofort irgendwo in Ihrem Dateisystem zu speichern und das Arbeitsverzeichnis R sofort in dem Ordner zu installieren, in dem das Skript gespeichert ist (Menü Sitzung - Arbeitsverzeichnis festlegen - Speicherort der Quelldatei). Der letzte Hinweis ist wichtig, da ansonsten nach dem Neustart von RStudio kein externes oder natives Skript gestartet werden kann. Aus irgendeinem Grund macht RStudio dies nicht standardmäßig, was logisch wäre.
Selbst im Basispaket R gibt es Standard-Visualisierungswerkzeuge ( Plot- Funktion), mit denen Sie viele Arten von Diagrammen erstellen können. Dennoch reichen diese Funktionen für vollwertige, hochgradig anpassbare Illustrationen eindeutig nicht aus.
Die am häufigsten verwendete Bibliothek für Grafiken in R ist das Paket ggplot2 , das wir ebenfalls verwenden werden.
Es lohnt sich auch, die readxl- Pakete (zum Lesen von .xls-, .xlsx-Dateien) und dplyr (zum Arbeiten mit Arrays), scales (zum Arbeiten mit verschiedenen Datenmaßstäben) und Cairo (zum Zeichnen von Grafiken von ggplot in Dateien) sofort zu installieren. All dies kann mit einem einzigen Befehl ausgeführt werden:
install.packages("ggplot2", "readxl", "scales", "dplyr", "Cairo")
Datenerhebung und -aufbereitung
Das Erstaunlichste ist, dass diese Phase in jeder Literatur, sei es ein ernstes theoretisches Buch über angewandte theoretische Statistik oder ein Leitfaden für bestimmte statistische Pakete, sich katastrophal wenig Raum und Zeit widmet. Nach den Erfahrungen der unabhängigen Forschung und Leitung von Studenten und Nachwuchskollegen ist jedoch bekannt, dass in diesem Stadium der Löwenanteil der Zeit und des Aufwands sinken kann, weshalb es sehr wichtig ist, diese auch bei der Lösung rein technischer Probleme zu sparen.
Hier gibt es zwei Fragen:
- Wie wähle ich das richtige Dateiformat?
- Wie lassen sich Daten am besten strukturieren?
Mit dem Format ist das Dilemma einfach: CSV im Vergleich zu Microsoft Excel (nicht so wichtig, "neue" .xlsx alte .xls). Viele Leute glauben, dass CSV von Einfachheit (in der Tat handelt es sich um eine normale Textdatei, bei der die Spaltenwerte durch Komma oder Semikolon getrennt sind) und Geschwindigkeit profitiert. Ich habe mich aus zwei Gründen für Excel entschieden: Erstens können Sie in dieser Datei mehrere Tabellen gleichzeitig auf verschiedenen Registerkarten speichern, und zweitens müssen Sie, was noch wichtiger ist, nicht überlegen, ob Sie das richtige Spaltentrennzeichen und die richtige Dezimalstelle auswählen. Bei CSV muss dies häufig manuell in den R-Code geschrieben werden, und es muss sichergestellt werden, dass die Datendatei mit denselben Einstellungen gespeichert wird.
Die Strukturierung von Daten ist komplexer und erfordert ein grundlegendes Verständnis für die Anordnung von Datenbanken. Wenn Sie sich nicht mit der Theorie relationaler Datenbanken über verschiedene Normalformen befassen, dann Die Datentabelle muss redundant sein, d. H. Zusätzliche Spalten enthalten. Dies ist notwendig, damit Sie später im Skript in R bestimmte Informationen für die weitere Verarbeitung flexibel auswählen können. Wenn wir beispielsweise eine primitive Zeitreihe darstellen möchten, müssen wir Spalten erstellen, die allen möglichen Gruppierungsmerkmalen entsprechen. Wenn es sich zum Beispiel um eine Reihe jährlicher Beobachtungen der Bevölkerung der bedingten Stadt Sewerowostotschinsk handelt, werden die folgenden Spalten benötigt: Jahr (Jahr), Var (Indikatorname), Wert (Indikatorwert).
Wir werden alle Eingabedaten für diese Art der Darstellung von Informationen bereitstellen.
Beispiel
Ziel: 2009-2018 einen Vergleich der Dynamik der Erntemengen in Russland, Sibirien und der Region Krasnojarsk erstellen.
Das Abrufen von Daten für diese Aufgabe ist ganz einfach: Finden Sie einfach den entsprechenden Indikator im einheitlichen abteilungsübergreifenden Informations- und Statistiksystem . Subtilität kommt als nächstes. Sie können die Daten sofort im XLSX-Format herunterladen und dann wie oben gezeigt manuell strukturieren. Glücklicherweise können Sie dies bei einigen Informationsquellen (z. B. EMISS) mit den Funktionen des Dienstes selbst tun. Dies vereinfacht die Arbeit erheblich und verkürzt den Zeitaufwand für die Erledigung.
Für EMISS ist es also ausreichend, in den Modus „Einstellungen“ (die entsprechende Schaltfläche in der oberen rechten Ecke der Datenseite) zu wechseln und alle Zeichen außer dem „Punkt“ aus der Spalte „Spalten“ in die Spalte „Zeilen“ zu verschieben. Es stellt sich heraus, dass ein Tisch fast bereit für unsere zukünftige Arbeit ist. Darüber hinaus ist es bereits in Excel (oder einem anderen geeigneten Editor) sinnvoll, die Tabellenstruktur auf eine ähnliche Form wie die oben dargestellte zu bringen und sicherzustellen, dass die erste Zeile nur die Namen von Variablen mit lateinischen Daten enthält (im Prinzip kann R mit russischsprachigen Überschriften arbeiten) Dies ist jedoch unpraktisch beim Schreiben von Code. Das Ergebnis war eine solche Tabelle (ein Fragment ist in mehreren Zeilen angegeben).
Jetzt können Sie diese graphs.xlsx aufrufen, das gesamte Buch in der Datei graphs.xlsx speichern und zu RStudio graphs.xlsx .
Wir verbinden die notwendigen Bibliotheken.
library(ggplot2) library(readxl) library(Cairo) library(scales) library(dplyr)
Wenn ein Zeitplan für eine russischsprachige Veröffentlichung vorbereitet wird, müssen Sie das entsprechende Gebietsschema unbedingt konfigurieren. Die modernste Option, die in den meisten Fällen funktioniert, ist natürlich die UTF-8-Codierung:
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")
Wenn das System alt ist (einige alte Windows- oder Linux-Versionen), müssen Sie zunächst verstehen, welche Codierung standardmäßig verwendet wird - dies ist keine so einfache Aufgabe, die weit vom Zweck dieses Artikels entfernt ist.
Jetzt müssen Sie die Daten in R laden.
df_logging <- read_excel("graphs.xlsx", sheet ="logging")
Die Blattoption hier legt den Namen des Blatts in der Excel-Arbeitsmappe fest, aus der die Daten geladen werden.
Wir erstellen die einfachste Version des erforderlichen Zeitplans.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location))

Im Prinzip erwies sich fast „out of the box“ als sehr lohnenswerter Zeitplan, der für eine erste Analyse des untersuchten Prozesses durchaus geeignet ist, im Hinblick auf eine mögliche Veröffentlichung jedoch noch erhebliche Verbesserungen erfordert.
Lassen Sie uns zunächst den Grafikstil auf einen akademischeren übertragen. Das ggplot2 Paket enthält mehrere vorgefertigte Grundthemen . Das Theme von theme_classic ist für unseren Fall am besten geeignet. Im Rahmen der Konfiguration können Sie die Basisgröße der Schriftart und des Headsets sofort festlegen. Meine persönlichen Vorlieben gehören zum modernen Schriftsystem PT Sans, PT Serif, PT Mono . Aber Sie können natürlich auch nach einer klassischeren Times oder nach Helvetica fragen. Auch die Veröffentlichung, in der die Veröffentlichung geplant ist, kann diesbezüglich spezielle Anweisungen enthalten. Der Basispunkt wird empirisch zu 12 pt bestimmt.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12)
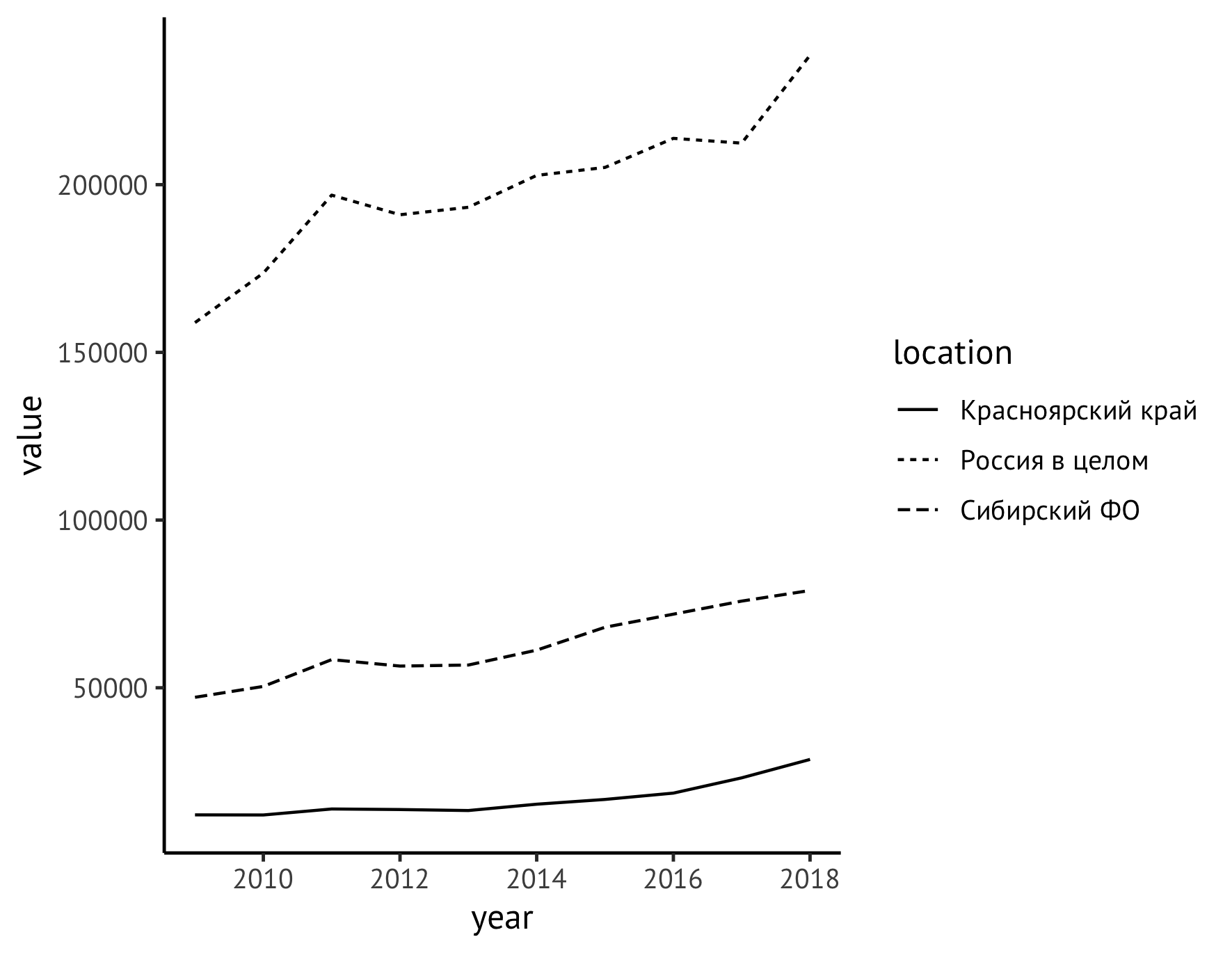
Bewegen Sie anschließend die Legende aus dem rechten Feld des Diagramms nach unten (mithilfe der theme ) und geben Sie den Achsen gleichzeitig aussagekräftige Namen ( labs ). Entlang der Y-Achse schreiben wir den Namen des Indikators mit Maßeinheiten ("Protokollvolumen, Millionen Kubikmeter") und löschen die Beschriftungen entlang der X-Achse insgesamt, da klar ist, dass dort Jahre markiert sind.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + labs(x = "", y = " , . . ", color="")

Um die Maßeinheiten für die Wahrnehmung komfortabler zu machen, werden wir von tausend Kubikmetern abweichen. m bis Millionen. Teilen Sie dazu einfach die Werte durch 1000, dh passen Sie die erste Zeile unseres Codes wie folgt an:
ggplot(data=df_logging, aes(x=year, y=value/1000))
Gleichzeitig müssen Sie die Einheiten in der Beschriftung ändern:
labs(x = "", y = " , . ", color="")
Und sofort werden wir den Bildstil leicht verbessern, indem wir Punkte hinzufügen, um jeden beobachteten Wert anzuzeigen, für den wir eine Anweisung hinzufügen:
geom_point(size=2)
Sie können auch den Stil der Linien selbst explizit festlegen. Es ist logisch, den Indikator für Russland als durchgezogene Linie und für den Sibirischen Föderationsbezirk und das Krasnojarsker Territorium zu definieren - verschiedene Versionen von intermittierenden:
scale_linetype_manual(values=c("twodash", "solid", "dotted"))
Nun sehen der allgemeine Code und das Diagramm folgendermaßen aus:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + labs(x = "", y = " , . ", color="")

Es bleibt eine inhaltlichere Aufgabe zu lösen - den Informationsgehalt unseres Zeitplans zu erhöhen. Daraus ist nun zu ersehen, dass der Indikator für alle Beobachtungsobjekte im Allgemeinen gewachsen ist, außerdem ist er seit etwa 2014 stärker als zuvor. Aber es wäre viel klarer, wenn wir auch die Werte im ersten und letzten Jahr und zum Beispiel in der Spitze des Jahres 2011 direkt in der Grafik darstellen würden. Die neue geom_text Anweisung hilft:
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8)
Auf den ersten Blick sieht es ziemlich kompliziert aus, und ich muss sagen, dass es wirklich nicht so einfach war, es zusammenzubauen. Ich werde versuchen zu erklären, was hier passiert. geom_text fügt dem Diagramm geom_text hinzu. Für diesen Befehl wird ein Datensatz benötigt. Wenn wir df_logging direkt darin spezifizieren df_logging , würden wir Beschriftungen über jedem Punkt erhalten. Dies wird ziemlich oft gemacht, aber für relativ einfache Zeitreihen wie unsere wird dieser Ansatz nur unnötiges visuelles Rauschen erzeugen, ohne uns neue Informationen über das Verhalten des beobachteten Indikators zu liefern. Daher werden wir nur die Jahre berücksichtigen, die für das Verständnis der Dynamik des Indikators wesentlich sind: 2009 (Beginn der Beobachtungen), 2011 (lokaler Höchstwert), 2018 (Ende der Beobachtungen). Dies wird der Standard- subset helfen.
Für die korrekte Darstellung von Zahlen gemäß der russischsprachigen Tradition benötigen wir ein Komma als Trennzeichen zwischen Ganzzahl und Dezimalstelle ( decimal.mark ) und für das Abschneiden der Anzahl der Nachkommastellen die decimal.mark . Verschiedene Experimente damit, einschließlich der Verwendung der Rundungsfunktion, führten dazu, dass wir, wenn wir eine Dezimalstelle benötigen, den Wert 3 an die digits .
Die Option check_overlap wird hier nicht direkt benötigt, kann aber in anderen Fällen nützlich sein: Sie dient zur automatischen Kontrolle überlappender Beschriftungen. Die Option vjust steuert die vertikale Platzierung von Beschriftungen. Der Wert wird nach Geschmacksgesichtspunkten ausgewählt.
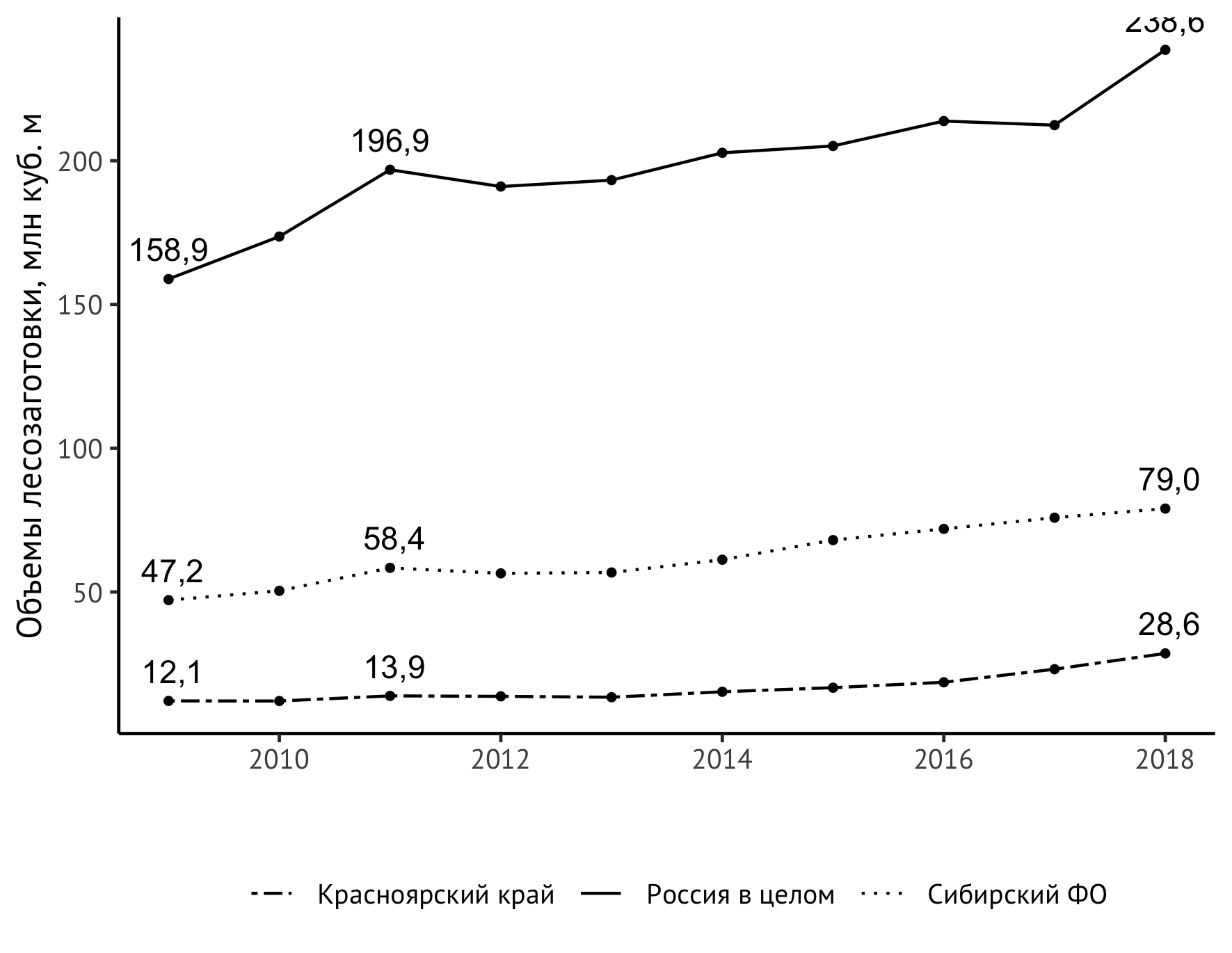
Nun ist der Zeitplan wirklich interessant zu betrachten!
Es wurde jedoch ein unerwartetes Problem festgestellt: Der obere rechte Wert wird durch die vertikale Größe des Bildes abgeschnitten. Es gibt verschiedene Möglichkeiten, um dieses Problem zu lösen. Ich stieg mit einer leichten Ausdehnung der vertikalen Achsenskala mit einer expliziten Obergrenze von 250 Millionen Kubikmetern aus. m:
scale_y_continuous(limits = c(0,250))
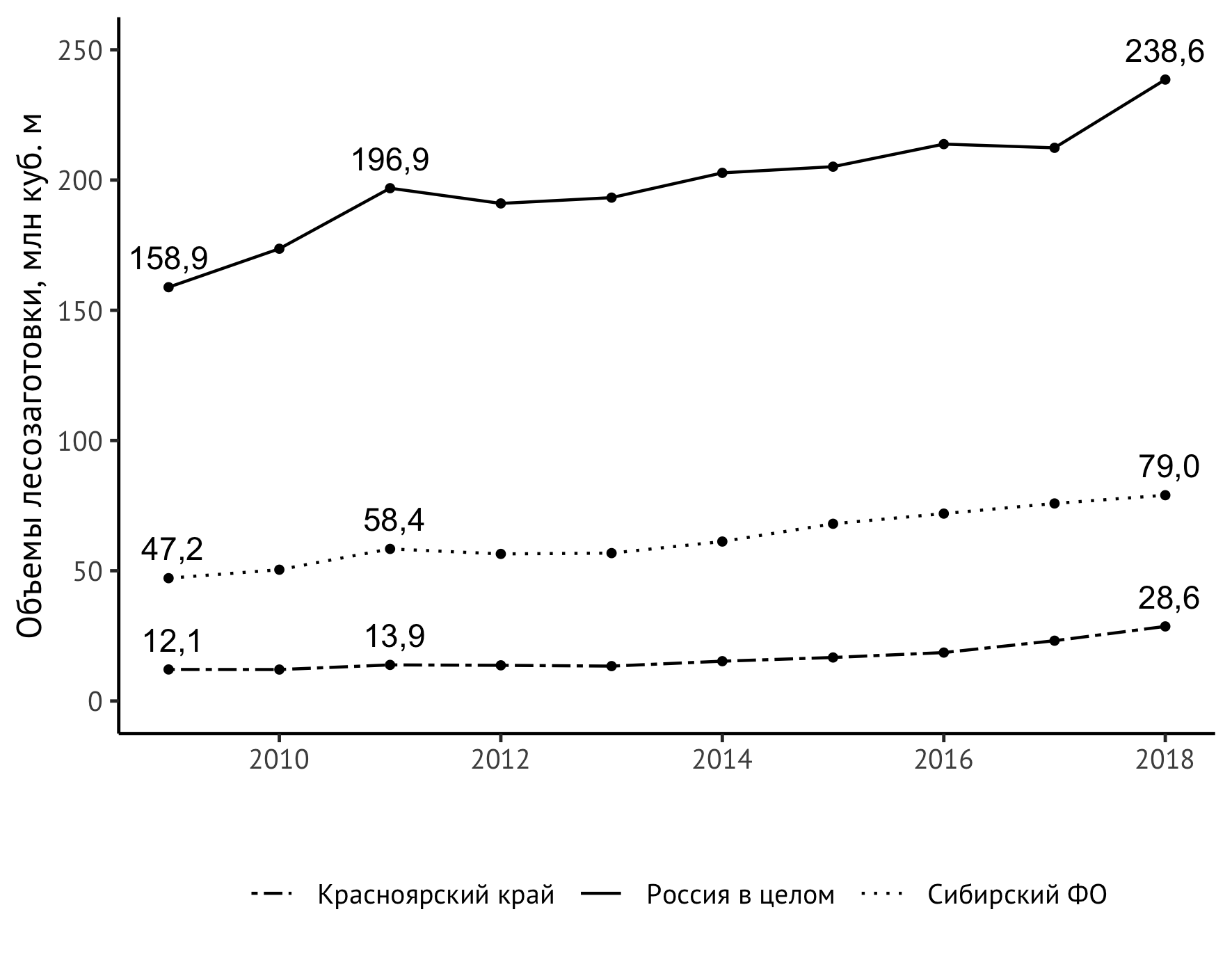
Fertig Der endgültige Code sieht also so aus:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + scale_y_continuous(limits = c(0,250)) + labs(x = "", y = " , . ", color="")
Das resultierende Bild ist in der Monografie enthalten: Strukturmodernisierung als Faktor zur Steigerung der Wettbewerbsfähigkeit der Region (am Beispiel des Krasnojarsker Territoriums) / ed. Shishatsky N.G. - Novosibirsk: IEOPP SB RAS, 2020 (im Druck).
Exportieren
Mit dem in RStudio integrierten Plug-In für die Grafikanzeige können Sie Bilder in verschiedenen Formaten ohne zusätzliche Befehle mit nur wenigen Klicks exportieren. Das Problem ist, dass dieser Dienst für praktische Aufgaben praktisch nutzlos ist. Beim Speichern in Rasterformaten (.jpg, .png) ist die Standardeinstellung sehr niedrig. Wenn Sie also beispielsweise ein Bild in Word importieren, wird es unscharf. Bei den Vektoren .eps oder .pdf ist die Situation offen gesagt noch schlimmer: Das Speichern erfolgt entweder bei Fehlern, bei denen das Öffnen der Datei nicht möglich ist, oder ohne die Möglichkeit, russischsprachige Inschriften zu verwenden.
Die Lösung besteht darin, die ggsave Funktion aus dem ggplot Paket zu verwenden.
Wenn für die Ausgabe eine normale Rasterdatei erforderlich ist, z. B. im PNG-Format, ist alles ganz einfach:
ggsave("logging.png", width=709, height=549, units="px")
Die Geometrie (Optionen width und height ) und Maßeinheiten ( units ) können weggelassen werden, aber dann wird das Bild standardmäßig quadratisch exportiert, was kaum praktisch ist. Aus diesem Grund ist es besser, Ihren eigenen Anteil und die erforderliche Größe zu ermitteln und diese Parameter manuell festzulegen, wie in der obigen Codezeile beschrieben.
Für die spätere Verwendung des Bildes in Papierpublikationen ist es sinnvoll, das Bild in Vektorformaten zu exportieren, damit später im Layout die Bildgeometrie frei verändert werden kann. Viele Magazine bevorzugen das .eps-Format - es ist auch praktisch, es für den Export nach Word zu verwenden. Wir benötigen den bereits installierten und verbundenen Cairo-Treiber:
ggsave(filename = "export.eps", width=15, height=11.6, units="cm", device = cairo_ps)
Dateien werden in dem aktuellen Verzeichnis gespeichert, in dem sich das R-Skript befindet.
Was gibt es noch zu lesen
Die Literatur zu Grafiken in R ist ziemlich umfangreich. Hier sind einige Beispiele, von denen das erste die Arbeit des Autors des ggplot-Pakets ist:
Das wahrscheinlich beste und ausführlichste Buch über Grafiken in R in russischer Sprache ist das Buch von Timofei Samsonov. Visualisierung und Analyse von Geodaten in der R-Sprache . Dies ist eine ausgezeichnete, detaillierte Anleitung zu vielen allgemeinen und spezifischen Problemen, die mit R gelöst werden können.
Sie können auch ein Buch in Russisch über R im Allgemeinen empfehlen:
Shitikov V.K., Mastitsky S.E. Klassifikation, Regression, Data Mining-Algorithmen unter Verwendung von R. 2017 .
Ein interessantes und motivierendes Beispiel ist eine aussagekräftige Präsentation zum Einsatz von ggplot2 bei der Erstellung von Zeichnungen für die einflussreiche Financial Times .