
Auf der RIT 2019 berichtete unser Kollege Alexander Korotkov über die Entwicklungsautomatisierung im CIAN: Um Leben und Arbeiten zu vereinfachen, nutzen wir unsere eigene Integro-Plattform. Es verfolgt den Lebenszyklus von Aufgaben, entfernt Routineoperationen von Entwicklern und reduziert die Anzahl der Fehler in der Produktion erheblich. In diesem Beitrag werden wir Alexanders Bericht ergänzen und Ihnen erläutern, wie wir von einfachen Skripten zum Kombinieren von Open Source-Produkten über unsere eigene Plattform übergegangen sind und was ein separates Automatisierungsteam tut.
Level Null
"Es gibt kein Nullniveau, das weiß ich nicht."
Shifu-Meister aus dem Film „Kung Fu Panda“Die Automatisierung bei CIAN begann 14 Jahre nach der Gründung des Unternehmens. Dann waren 35 Leute im Entwicklerteam. Schwer zu glauben, oder? Zwar gab es eine gewisse Form der Automatisierung, aber seit 2015 gibt es einen eigenen Bereich für die kontinuierliche Integration und Codebereitstellung.
Zu dieser Zeit hatten wir einen riesigen Monolithen aus Python, C # und PHP, der auf Linux / Windows-Servern bereitgestellt wurde. Für den Einsatz dieses Monsters hatten wir eine Reihe von Skripten, die wir manuell ausführten. Es gab auch eine Monolith-Baugruppe, die aufgrund von Konflikten beim Zusammenführen von Zweigen, Bearbeiten von Fehlern und Neuerstellen "mit einer anderen Aufgabengruppe im Build" Schmerzen und Leiden verursachte. Der vereinfachte Prozess sah folgendermaßen aus:

Dies passte nicht zu uns und wir wollten einen wiederholbaren, automatisierten und kontrollierten Erstellungs- und Bereitstellungsprozess erstellen. Dazu brauchten wir ein CI / CD-System und wählten zwischen der kostenlosen Version von Teamcity und den kostenlosen Jenkins, da wir mit ihnen gearbeitet haben und beide für eine Reihe von Funktionen geeignet waren. Wir haben Teamcity als neueres Produkt ausgewählt. Dann haben wir keine Microservice-Architektur verwendet und nicht mit einer großen Anzahl von Aufgaben und Projekten gerechnet.
Wir kommen zur Idee unseres eigenen Systems
Mit der Implementierung von Teamcity wurde nur ein Teil der manuellen Arbeit entfernt: Es wurden noch Pull-Requests erstellt, Aufgaben nach Status in Jira befördert und Aufgaben zur Freigabe ausgewählt. Teamcity kam damit nicht mehr klar. Es war notwendig, den Weg der weiteren Automatisierung zu wählen. Wir haben Optionen für die Arbeit mit Skripten in Teamcity oder den Wechsel zu Automatisierungssystemen von Drittanbietern erwogen. Letztendlich haben wir uns jedoch für die maximale Flexibilität entschieden, die nur unsere eigene Lösung bietet. So erschien die erste Version des internen Automatisierungssystems mit dem Namen Integro.
Teamcity befasst sich mit der Automatisierung von Montage- und Bereitstellungsprozessen auf der Anfangsebene. Integro hat sich auf die Automatisierung von Entwicklungsprozessen auf höchster Ebene konzentriert. Es war notwendig, die Arbeit mit Aufgaben in Jira mit der Verarbeitung des zugehörigen Quellcodes in Bitbucket zu verbinden. Zu diesem Zeitpunkt verfügte Integro über eigene Workflows für die Bearbeitung von Aufgaben verschiedener Art.
Aufgrund der zunehmenden Automatisierung der Geschäftsprozesse hat die Anzahl der Projekte und Abläufe in Teamcity zugenommen. Es gab also ein neues Problem: Es fehlte eine freie Teamcity-Instanz (3 Agenten und 100 Projekte), wir fügten eine weitere Instanz (3 weitere Agenten und 100 Projekte) und dann eine weitere hinzu. Als Ergebnis haben wir ein System mit mehreren Clustern erhalten, das schwierig zu verwalten war:
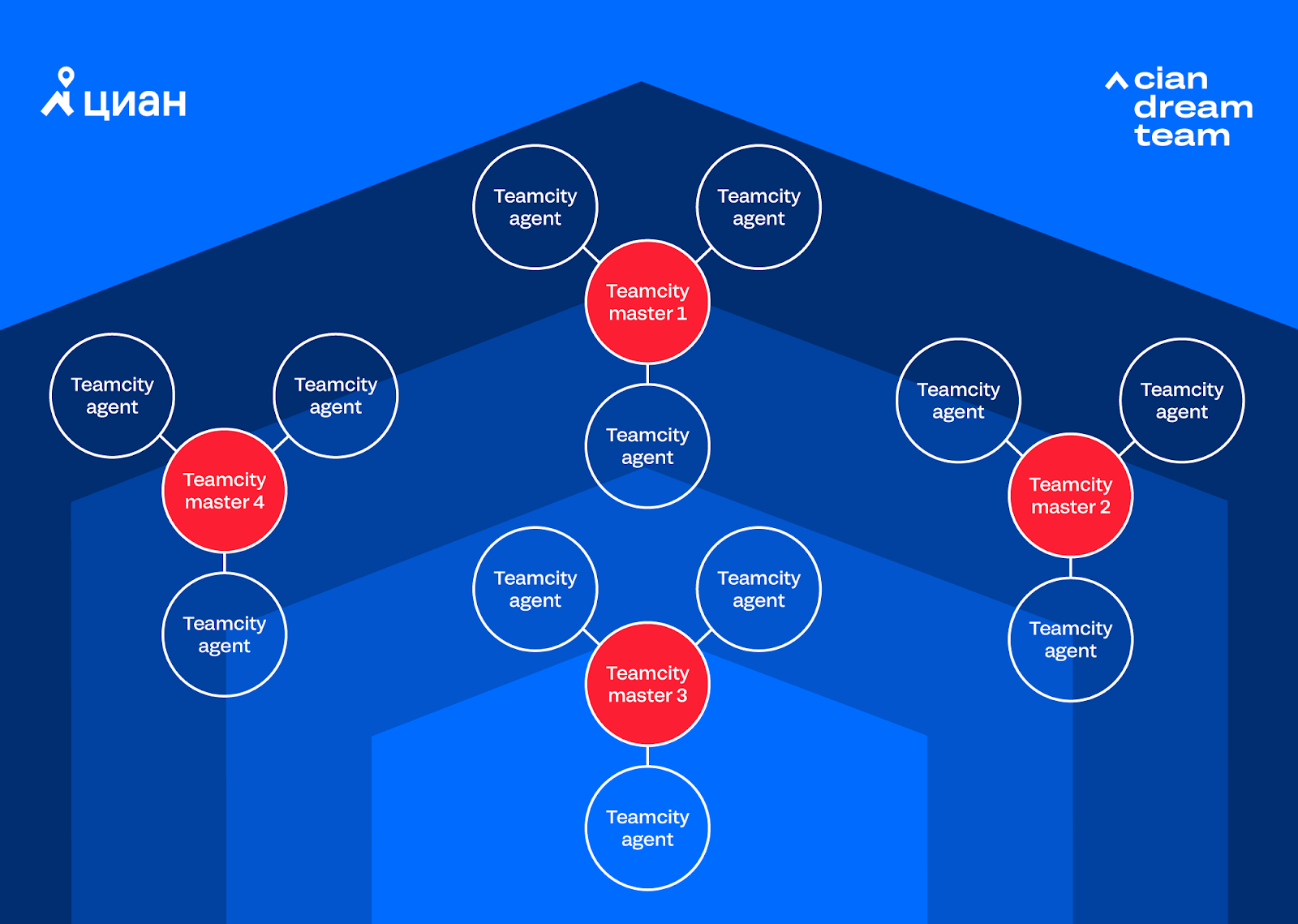
Als die Frage nach der 4-Instanz auftauchte, wurde uns klar, dass wir nicht mehr so leben können, da die Gesamtkosten für die Unterstützung von 4 Instanzen nicht mehr in ein Framework passen. Es stellte sich die Frage, ob Sie eine bezahlte Teamcity kaufen oder sich für einen kostenlosen Jenkins entscheiden sollten. Wir haben Berechnungen an Instanzen und Plänen für die Automatisierung durchgeführt und beschlossen, dass wir von Jenkins leben würden. Nach ein paar Wochen sind wir zu Jenkins gewechselt und haben die Kopfschmerzen beseitigt, die mit der Unterstützung mehrerer Teamcity-Instanzen verbunden sind. Daher konnten wir uns darauf konzentrieren, Integro zu entwickeln und Jenkins für uns selbst fertigzustellen.
Mit dem Wachstum der Basisautomatisierung (in Form der automatischen Erstellung von Pull-Requests, der Erfassung und Veröffentlichung von Code-Coverage und anderen Überprüfungen) bestand ein starker Wunsch, manuelle Freigaben so weit wie möglich abzulehnen und diese Arbeit Robotern zu überlassen. Darüber hinaus begann das Unternehmen, auf Microservices umzusteigen, die häufige und voneinander getrennte Veröffentlichungen erforderten. So kamen wir nach und nach zur automatischen Freigabe unserer Mikrodienste (vorerst geben wir den Monolithen aufgrund der Komplexität des Prozesses manuell frei). Aber wie gewöhnlich ist eine neue Komplexität entstanden.
Testen automatisieren
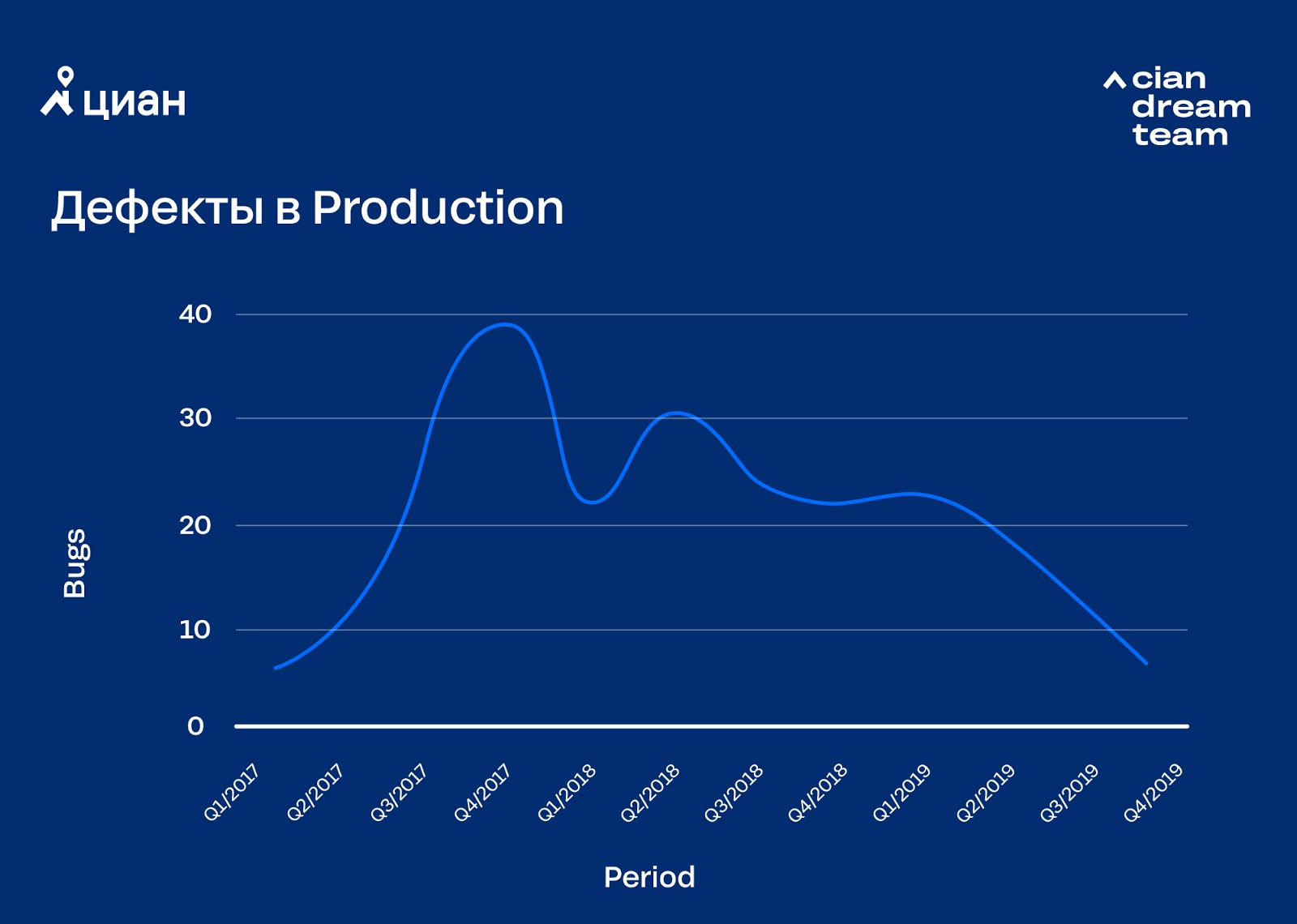
Aufgrund der Automatisierung von Releases haben sich die Entwicklungsprozesse beschleunigt, auch weil einige Testphasen übersprungen wurden. Dies führte zu einem vorübergehenden Qualitätsverlust. Es klingt kitschig, aber zusammen mit der Beschleunigung von Releases war es notwendig, die Methodik der Produktentwicklung zu ändern. Es war notwendig, über das Testen der Automatisierung nachzudenken und persönliche Verantwortung (hier geht es darum, „eine Idee im Kopf zu akzeptieren“ anstatt Geldstrafen) des Entwicklers für den veröffentlichten Code und die darin enthaltenen Fehler sowie über die Entscheidung, die Aufgabe durch eine automatische Bereitstellung zu erteilen / nicht zu erteilen.
Um Qualitätsprobleme zu beseitigen, haben wir zwei wichtige Entscheidungen getroffen: Wir haben mit der Durchführung von Kanarientests begonnen und eine automatische Überwachung des Fehlerhintergrunds mit automatischer Reaktion auf dessen Überschuss implementiert. Die erste Lösung ermöglichte es, offensichtliche Fehler zu finden, bevor der Code vollständig in Produktion ging, die zweite reduzierte die Reaktionszeit auf Probleme in der Produktion. Natürlich treten Fehler auf, aber wir verwenden den größten Teil unserer Zeit und Energie nicht auf die Korrektur, sondern auf die Minimierung.
Automatisierungsteam
Mittlerweile beschäftigen wir 130 Entwickler und
wachsen weiter . Das Team für kontinuierliche Integration und Codebereitstellung (im Folgenden als Deploy and Integration- oder DI-Team bezeichnet) besteht aus 7 Mitarbeitern und arbeitet in zwei Richtungen: Entwicklung der Integro-Automatisierungsplattform und von DevOps.
DevOps ist verantwortlich für die Dev / Beta-Umgebung der CIAN-Website, die Integro-Umgebung, hilft Entwicklern bei der Lösung von Problemen und entwickelt neue Ansätze für die Skalierung von Umgebungen. Das Geschäftsfeld von Integro befasst sich sowohl mit Integro selbst als auch mit verwandten Diensten, z. B. Plug-Ins für Jenkins, Jira und Confluence, und entwickelt auch Hilfsprogramme und Anwendungen für Entwicklungsteams.
Das DI-Team arbeitet mit dem Platform-Team zusammen, das Architekturen, Bibliotheken und Entwicklungsansätze innerhalb des Unternehmens entwickelt. Gleichzeitig kann jeder Entwickler im CIAN einen Beitrag zur Automatisierung leisten, z. B. eine Mikroautomatisierung gemäß den Anforderungen des Teams vornehmen oder eine coole Idee zur Verbesserung der Automatisierung teilen.
Puff Pie Automation in Cyan
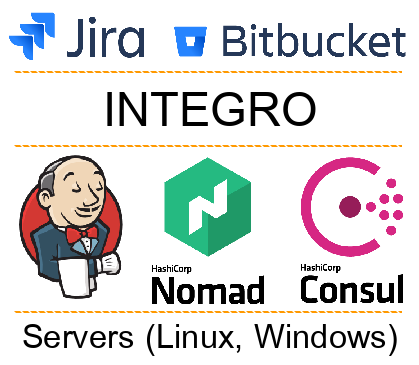
Alle an der Automatisierung beteiligten Systeme können in mehrere Ebenen unterteilt werden:
- Externe Systeme (Jira, Bitbucket usw.). Entwicklungsteams arbeiten mit ihnen.
- Plattform Integro. Meistens arbeiten Entwickler nicht direkt damit, aber sie unterstützt die Arbeit der gesamten Automatisierung.
- Zustellungs-, Orchestrierungs- und Entdeckungsdienste (z. B. Jeknins, Consul, Nomad). Mit ihrer Hilfe stellen wir den Code auf den Servern bereit und stellen die Dienste miteinander bereit.
- Physische Schicht (Server, Betriebssystem, zugehörige Software). Auf dieser Ebene funktioniert unser Code. Dies kann entweder ein physischer oder ein virtueller Server sein (LXC, KVM, Docker).
Basierend auf diesem Konzept teilen wir die Verantwortungsbereiche innerhalb des DI-Teams auf. Die ersten beiden Ebenen liegen in der Verantwortung des Entwicklungsbereichs von Integro, und die letzten beiden Ebenen liegen bereits im Verantwortungsbereich von DevOps. Diese Trennung ermöglicht es Ihnen, sich auf Aufgaben zu konzentrieren und beeinträchtigt nicht die Interaktion, da wir nebeneinander stehen und ständig Wissen und Erfahrung austauschen.
Integro
Konzentrieren wir uns auf Integro und beginnen mit dem Technologie-Stack:
- CentOs 7
- Docker + Nomad + Consul + Vault
- Java 11 (der alte Integro-Monolith bleibt in Java 8 erhalten)
- Spring Boot 2.X + Spring Cloud Config
- PostgreSql 11
- Rabbitmq
- Apache entzünden
- Camunda (eingebettet)
- Grafana + Graphit + Prometheus + Jaeger + ELK
- Web-Benutzeroberfläche: Reagieren (CSR) + MobX
- SSO: Schlüsselmantel
Wir halten uns an das Prinzip der Microservice-Entwicklung, obwohl wir das Erbe eines Monolithen der früheren Version von Integro haben. Jeder Mikrodienst dreht sich in seinem Docker-Container, die Dienste kommunizieren über HTTP-Anforderungen und RabbitMQ-Nachrichten miteinander. Microservices finden sich gegenseitig über Consul und führen eine Anfrage durch, wobei die Autorisierung über SSO (Keycloak, OAuth 2 / OpenID Connect) erfolgt.

Betrachten Sie als reales Beispiel die Interaktion mit Jenkins, die aus den folgenden Schritten besteht:
- Der Workflow-Management-Microservice (im Folgenden als Flow-Microservice bezeichnet) möchte die Assembly in Jenkins ausführen. Zu diesem Zweck findet er über Consul IP: PORT eine Mikroservice-Integration mit Jenkins (im Folgenden: Jenkins-Mikroservice) und sendet ihm eine asynchrone Anforderung zum Starten der Assembly in Jenkins.
- Der Jenkins-Microservice generiert nach Eingang der Anfrage die Job-ID und gibt sie zurück, anhand derer das Ergebnis der Arbeit identifiziert werden kann. Gleichzeitig startet er den Build in Jenkins durch einen Aufruf der REST-API.
- Jenkins erstellt und sendet nach Abschluss einen Webhook mit den Ergebnissen an den Jenkins-Microservice.
- Ein Jenkins-Microservice, der einen Webhook erhalten hat, generiert eine Nachricht über den Abschluss der Anforderungsverarbeitung und hängt die Ausführungsergebnisse an diese an. Die generierte Nachricht wird an die RabbitMQ-Warteschlange gesendet.
- Über RabbitMQ gelangt die veröffentlichte Nachricht an den Flow-Mikrodienst, der das Ergebnis der Verarbeitung seiner Aufgabe erfährt, indem die Job-ID aus der Anforderung und der empfangenen Nachricht abgeglichen wird.
Jetzt haben wir ungefähr 30 Microservices, die in mehrere Gruppen unterteilt werden können:
- Konfigurationsmanagement.
- Informieren und Interagieren mit Benutzern (Instant Messenger, E-Mail).
- Arbeite mit Quellcode.
- Integration mit Bereitstellungstools (Jenkins, Nomaden, Konsul usw.).
- Überwachung (Releases, Bugs usw.).
- Webdienstprogramme (Benutzeroberfläche zum Verwalten von Testumgebungen, Sammeln von Statistiken usw.).
- Integration mit Task Trackern und ähnlichen Systemen.
- Workflow für verschiedene Aufgaben verwalten.
Workflow-Aufgaben
Integro automatisiert Aktivitäten im Zusammenhang mit dem Task-Lebenszyklus. Vereinfacht durch den Task-Lebenszyklus meinen wir den Workflow einer Task in Jira. In unseren Entwicklungsprozessen gibt es abhängig vom Projekt, der Art der Aufgabe und den für eine bestimmte Aufgabe ausgewählten Optionen verschiedene Variationen des Workflows.
Betrachten Sie den Workflow, den wir am häufigsten verwenden:
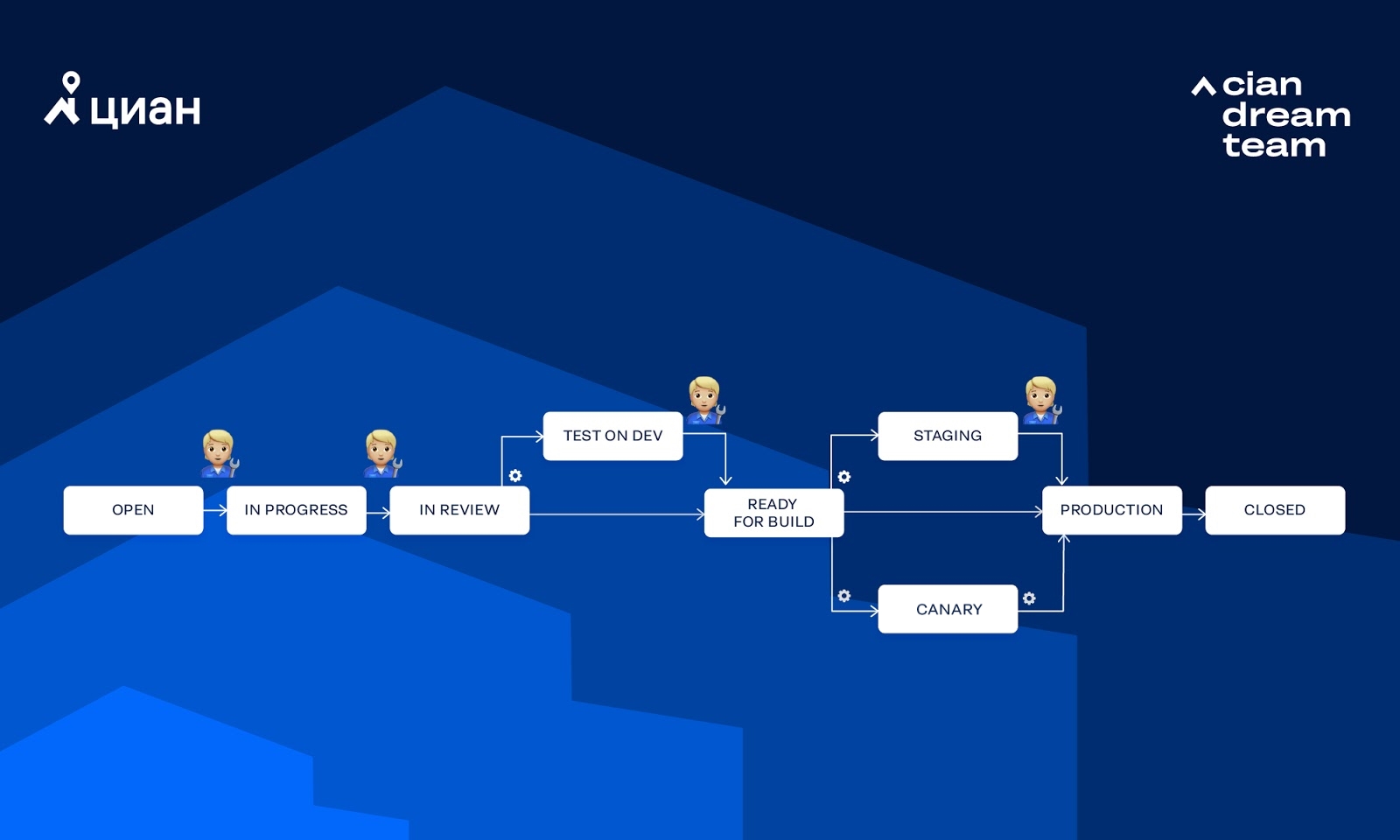
Im Diagramm zeigt das Zahnrad an, dass der Übergang von Integro automatisch aufgerufen wird, während die menschliche Figur bedeutet, dass der Übergang von der Person manuell aufgerufen wird. Schauen wir uns einige Möglichkeiten an, wie eine Aufgabe diesen Workflow durchlaufen kann.
Vollständig manuelles Testen für DEV + BETA ohne Kanarientests (normalerweise geben wir einen Monolithen frei):
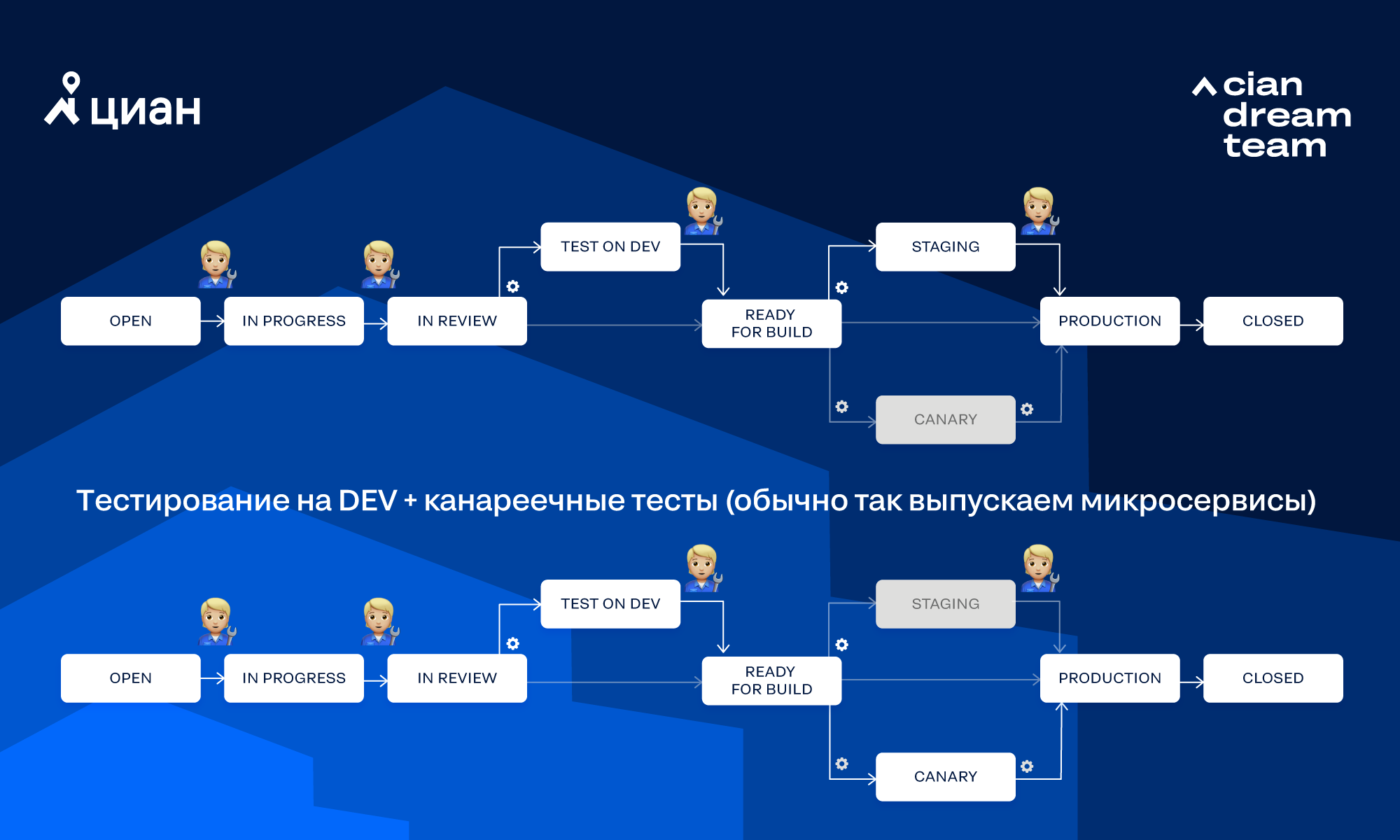
Es kann andere Kombinationen von Übergängen geben. Manchmal kann der Pfad, den die Aufgabe nehmen wird, über Optionen in Jira ausgewählt werden.
Aufgabenbewegung
Berücksichtigen Sie die grundlegenden Schritte, die beim Verschieben der Aufgabe im Workflow "Testen auf DEV + -Kanarientests" ausgeführt werden:
1. Der Entwickler oder die PM erstellt die Aufgabe.
2. Der Entwickler übernimmt die Aufgabe zur Arbeit. Überträgt es nach Abschluss in den Status IN REVIEW.
3. Jira sendet Webhook an den Jira-Microservice (ist für die Integration mit Jira verantwortlich).
4. Der Jira Microservice sendet eine Anfrage an den Flow Service (er ist verantwortlich für die internen Workflows, in denen die Arbeit ausgeführt wird), um den Workflow zu starten.
5. Innerhalb des Flow-Dienstes:
- Die Prüfer für die Aufgabe werden zugewiesen (Users-Microservice, der alles über Benutzer weiß + Jira-Microservice).
- Über den Mikroservice Source (er kennt sich mit Repositorys und Verzweigungen aus, arbeitet aber nicht mit dem Code selbst) sucht er nach Repositorys, in denen sich eine Verzweigung unserer Aufgabe befindet (um die Suche zu vereinfachen, stimmt der Name der Verzweigung mit der Aufgabennummer in Jira überein). In den meisten Fällen hat die Aufgabe nur einen Zweig in einem Repository. Dies vereinfacht die Verwaltung der Warteschlange bei der Bereitstellung und verringert die Konnektivität zwischen den Repositorys.
- Für jeden gefundenen Zweig wird die folgende Abfolge von Aktionen ausgeführt:
i) Betankung des Master-Zweigs (Git-Microservice für die Arbeit mit Code).
ii) Der Zweig wird vom Entwickler für Änderungen gesperrt (Bitbucket Microservice).
iii) In diesem Zweig wird eine Pull-Anforderung erstellt (Bitbucket-Microservice).
iv) Eine Nachricht über die neue Pull-Anfrage wird an die Chats des Entwicklers gesendet (Benachrichtigen Sie den Microservice, wenn Sie mit Benachrichtigungen arbeiten).
v) Erstellen, Testen und Bereitstellen von Tasks für DEV (Jenkins Microservice für die Arbeit mit Jenkins).
vi) Wenn alle vorhergehenden Absätze erfolgreich abgeschlossen wurden, setzt Integro seine Genehmigung in den Pull-Request (Bitbucket-Microservice). - Integro erwartet von den designierten Prüfern eine Pull-Request-Genehmigung.
- Sobald alle erforderlichen Genehmigungen eingegangen sind (einschließlich der erfolgreich bestandenen automatisierten Tests), überträgt Integro die Aufgabe in den Status Test on Dev (Jira Microservice).
6. Tester testen die Aufgabe. Wenn keine Probleme vorliegen, wird die Aufgabe in den Status Bereit zum Erstellen versetzt.
7. Integro "sieht", dass der Task zur Freigabe bereit ist, und startet seine Bereitstellung im kanarischen Modus (Jenkins Microservice). Die Freigabebereitschaft wird durch ein Regelwerk bestimmt. Zum Beispiel eine Aufgabe im richtigen Status, es gibt keine Sperren für andere Aufgaben, jetzt gibt es keine aktiven Berechnungen für diesen Mikrodienst usw.
8. Die Aufgabe wird in den Status von Canary (Jira-microservice) übertragen.
9. Jenkins startet über Nomad eine Bereitstellung von Tasks im kanarischen Modus (normalerweise 1-3 Instanzen) und benachrichtigt den Release-Überwachungsdienst (DeployWatch-Microservice) über die Berechnung.
10. DeployWatch-microservice sammelt Hintergrundfehler und reagiert gegebenenfalls darauf. Wird der Hintergrundfehler überschritten (die Hintergrundrate wird automatisch berechnet), werden die Entwickler über den Microservice Benachrichtigen benachrichtigt. Wenn der Entwickler nach 5 Minuten nicht geantwortet hat (auf "Zurücksetzen" oder "Bleiben" geklickt), wird das automatische Rollback der kanarischen Instanzen gestartet. Wenn der Hintergrund nicht überschritten wird, muss der Entwickler die Bereitstellung der Aufgabe in der Produktion manuell starten (durch Drücken der Schaltfläche auf der Benutzeroberfläche). Wenn der Entwickler innerhalb von 60 Minuten keine Bereitstellung in der Produktion gestartet hat, werden die kanarischen Instanzen aus Sicherheitsgründen ebenfalls abgepumpt.
11. Nach dem Start der Bereitstellung in der Produktion:
- Die Aufgabe wird in den Produktionsstatus (Jira Microservice) überführt.
- Jenkins Microservice startet den Bereitstellungsprozess und benachrichtigt die Bereitstellung des DeployWatch-Microservice.
- DeployWatch-microservice überprüft, ob alle Container in der Produktion aktualisiert wurden (es gab Fälle, in denen nicht alle aktualisiert wurden).
- Eine Benachrichtigung über die Ergebnisse der Bereitstellung an die Produktion wird über den Benachrichtigungsmikroservice gesendet.
12. Die Entwickler haben 30 Minuten Zeit, um das Rollback des Tasks mit Production zu starten, falls ein fehlerhaftes Verhalten des Microservices festgestellt wird. Nach dieser Zeit wird die Aufgabe automatisch in den Master (Git-microservice) übernommen.
13. Nach einer erfolgreichen Zusammenführung im Master wird der Task-Status auf Closed (Jira Microservice) geändert.
Das Schema gibt nicht vor, vollständig detailliert zu sein (in Wirklichkeit gibt es sogar noch mehr Schritte), aber es ermöglicht es, den Grad der Integration in Prozesse zu bewerten. Wir halten dieses Schema nicht für ideal und verbessern die Prozesse der automatischen Verfolgung von Releases und der Bereitstellung.
Was weiter
Wir haben große Pläne für die Entwicklung der Automatisierung, z. B. die Ablehnung manueller Vorgänge während der Freigabe von Monolithen, die Verbesserung der Überwachung während der automatischen Bereitstellung und die Verbesserung der Interaktion mit Entwicklern.
Aber lassen Sie uns jetzt an dieser Stelle anhalten. Wir haben oberflächlich viele Themen in der Überprüfung der Automatisierung behandelt, einige haben sie überhaupt nicht angesprochen, daher beantworten wir gerne Fragen. Wir warten auf Vorschläge, was im Detail zu behandeln ist, schreiben Sie in den Kommentaren.