Hallo habr Ich präsentiere Ihnen die Übersetzung des Artikels "Visualisierung eines neuronalen maschinellen Übersetzungsmodells (Mechanik von Seq2seq-Modellen mit Aufmerksamkeit)" von Jay Alammar.
Sequence-to-Sequence-Modelle (seq2seq) sind Deep-Learning-Modelle, die bei Aufgaben wie maschineller Übersetzung, Textzusammenfassung, Bildanmerkung usw. große Erfolge erzielt haben. Beispielsweise wurde Ende 2016 ein ähnliches Modell in Google Translate integriert. Die Grundlagen der seq2seq-Modelle wurden 2014 mit der Veröffentlichung von zwei Artikeln gelegt - Sutskever et al., 2014 , Cho et al., 2014 .
Um diese Modelle ausreichend zu verstehen und anzuwenden, müssen zunächst einige Konzepte geklärt werden. Die in diesem Artikel vorgeschlagenen Visualisierungen sind eine gute Ergänzung zu den oben genannten Artikeln.
Sequenz-zu-Sequenz-Modell ist ein Modell, das eine Eingabesequenz von Elementen (Wörter, Buchstaben, Bildattribute usw.) akzeptiert und eine andere Sequenz von Elementen zurückgibt. Das trainierte Modell funktioniert wie folgt:
Bei der neuronalen maschinellen Übersetzung ist eine Folge von Elementen eine Sammlung von Wörtern, die nacheinander verarbeitet werden. Die Schlussfolgerung ist auch eine Reihe von Wörtern:
Schau mal unter die Motorhaube
Unter der Haube hat das Modell einen Encoder und einen Decoder.
Der Codierer verarbeitet jedes Element der Eingabesequenz und übersetzt die empfangenen Informationen in einen als Kontext bezeichneten Vektor. Nach der Verarbeitung der gesamten Eingabesequenz sendet der Encoder den Kontext an den Decoder, der dann Element für Element die Ausgabesequenz generiert.
Dasselbe passiert mit maschineller Übersetzung.
Bei der maschinellen Übersetzung ist der Kontext ein Vektor (ein Array von Zahlen), und der Codierer und der Decodierer sind wiederum am häufigsten wiederkehrende neuronale Netze (siehe die Einführung in RNN - Eine benutzerfreundliche Einführung in wiederkehrende neuronale Netze ).

Der Kontext ist ein Vektor von Gleitkommazahlen. Weiter im Artikel werden Vektoren in Farbe dargestellt, so dass die hellere Farbe Zellen mit großen Werten entspricht.
Beim Trainieren des Modells können Sie die Größe des Kontextvektors festlegen - die Anzahl der verborgenen Neuronen (verborgenen Einheiten) im RNN-Encoder. Die Visualisierungsdaten zeigen einen 4-dimensionalen Vektor, aber in realen Anwendungen hat der Kontextvektor eine Dimension in der Größenordnung von 256, 512 oder 1024.
Standardmäßig empfängt RNN in jedem Zeitintervall zwei Elemente zur Eingabe: das Eingabeelement selbst (im Falle eines Encoders ein Wort aus dem ursprünglichen Satz) und den verborgenen Zustand. Das Wort muss jedoch durch einen Vektor dargestellt werden. Um ein Wort in einen Vektor umzuwandeln, greifen sie auf eine Reihe von Algorithmen zurück, die als Worteinbettungen bezeichnet werden. Einbettungen übersetzen Wörter in Vektorräume, die semantische und semantische Informationen über sie enthalten (z. B. "König" - "Mann" + "Frau" = "Königin" ).
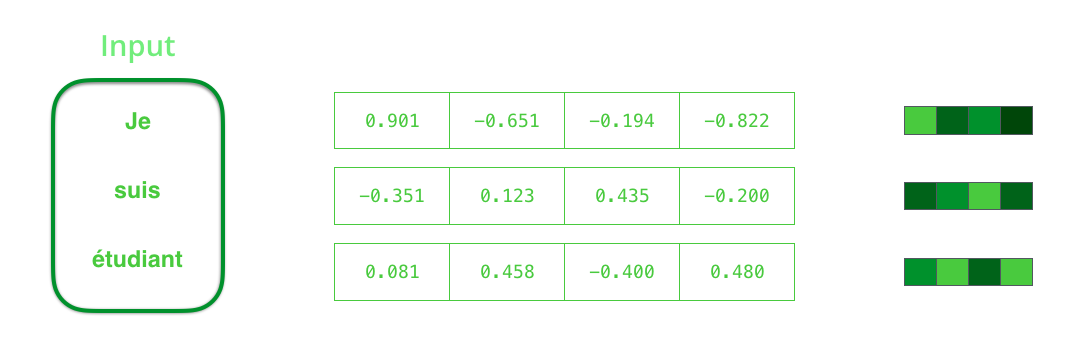
Bevor Sie Wörter verarbeiten, müssen Sie sie in Vektoren konvertieren. Diese Transformation wird unter Verwendung des Worteinbettungsalgorithmus ausgeführt. Sie können sowohl vorab trainierte Einbettungen als auch Train-Einbettungen für Ihren Datensatz verwenden. 200-300 - typische Dimension des Einbettungsvektors; In diesem Artikel wird der Einfachheit halber Dimension 4 verwendet.
Nachdem wir uns mit unseren Hauptvektoren / Tensoren vertraut gemacht haben, wollen wir uns an den Mechanismus von RNN erinnern und Visualisierungen erstellen, um ihn zu beschreiben:
Im nächsten Schritt nimmt RNN den zweiten Eingangsvektor und den latenten Zustand # 1, um in diesem Zeitintervall den Ausgang zu bilden. Später in diesem Artikel wird eine ähnliche Animation verwendet, um Vektoren in einem neuronalen maschinellen Übersetzungsmodell zu beschreiben.
In der folgenden Visualisierung beschreibt jeder Frame die Verarbeitung von Eingaben durch einen Codierer und die Erzeugung von Ausgaben durch einen Decodierer in einem Zeitintervall. Da sowohl der Codierer als auch der Decodierer RNN sind, ist das neuronale Netzwerk in jedem Zeitintervall damit beschäftigt, seine verborgenen Zustände basierend auf den aktuellen und allen vorherigen Eingaben zu verarbeiten und zu aktualisieren. In diesem Fall ist der letzte der verborgenen Zustände des Codierers der Kontext, der an den Decodierer übertragen wird.
Der Decoder enthält auch versteckte Zustände, die er von einem Zeitschlitz zu einem anderen überträgt. (Dies ist nicht in der Visualisierung enthalten und zeigt nur die Hauptteile des Modells.)
Wir wenden uns nun einer anderen Art der Visualisierung von Sequenz-zu-Sequenz-Modellen zu. Diese Animation wird helfen, die statischen Grafiken zu verstehen, die diese Modelle beschreiben - die sogenannten Eine nicht gerollte Ansicht, bei der anstelle eines Decoders für jedes Zeitintervall eine Kopie angezeigt wird. So können wir uns die Eingabe- und Ausgabeelemente in jedem Zeitintervall ansehen.
Beachten Sie!
Der Kontextvektor ist ein Engpass für diese Art von Modell, der es ihnen erschwert, mit langen Sätzen umzugehen. Die Lösung wurde in Artikeln von Bahdanau et al., 2014 und Luong et al., 2015 vorgeschlagen , die eine Technik vorstellten, die als Aufmerksamkeitsmechanismus bezeichnet wird. Dieser Mechanismus verbessert die Qualität von maschinellen Übersetzungssystemen erheblich und ermöglicht es den Modellen, sich auf die relevanten Teile der Eingabesequenzen zu konzentrieren.
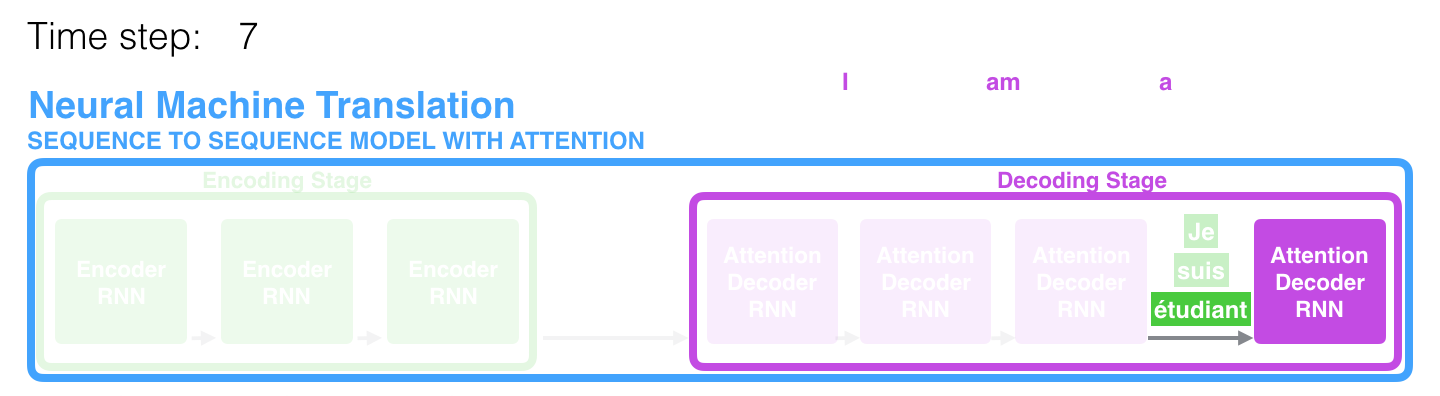
In der 7. Zeitspanne ermöglicht der Aufmerksamkeitsmechanismus dem Decoder, sich auf das Wort étudiant (Student in Französisch) zu konzentrieren, bevor eine Übersetzung ins Englische erstellt wird. Diese Fähigkeit, das Signal aus dem relevanten Teil der Eingabesequenz zu verstärken, ermöglicht es Modellen, die auf dem Aufmerksamkeitsmechanismus basieren, ein besseres Ergebnis im Vergleich zu anderen Modellen zu erzielen.
Bei der Betrachtung eines Modells mit einem Aufmerksamkeitsmechanismus auf einer hohen Abstraktionsebene können zwei Hauptunterschiede zum klassischen Sequenz-zu-Sequenz-Modell unterschieden werden.
Erstens überträgt der Encoder deutlich mehr Daten an den Decoder: Anstatt nur den letzten versteckten Zustand nach der Codierungsstufe zu übertragen, sendet der Encoder alle seine versteckten Zustände an ihn:
Zweitens durchläuft der Decoder einen zusätzlichen Schritt, bevor er die Ausgabe erzeugt. Um sich auf die Teile der Eingabesequenz zu konzentrieren, die für die entsprechende Zeitspanne relevant sind, führt der Decoder Folgendes aus:
- Betrachtet eine Reihe latenter Zustände, die von einem Codierer empfangen wurden. Jeder der latenten Zustände korreliert am besten mit einem der Wörter in der Eingabesequenz.
- Weist jedem latenten Zustand eine bestimmte Bewertung zu (lassen Sie uns zunächst den Ablauf des Bewertungsverfahrens auslassen).
- Multipliziert jeden verborgenen Zustand mit einer softmax-konvertierten Bewertungsfunktion, um verborgene Zustände mit einer hohen Bewertung hervorzuheben und verborgene Zustände mit einem kleinen Zustand in den Hintergrund zu rücken.
Diese „Bewertungsübung“ wird in jedem Zeitintervall am Decoder durchgeführt.
Zusammenfassend betrachten wir also den Prozess des Modells mit dem Aufmerksamkeitsmechanismus:
- Beim Decodierer empfängt der RNN die Einbettung <ENDE> des Tokens und des anfänglichen verborgenen Zustands.
- Die RNN verarbeitet das Eingabeelement, generiert die Ausgabe und einen neuen verborgenen Zustandsvektor (h4). Die Ausgabe wird verworfen.
- Der Aufmerksamkeitsmechanismus verwendet die verborgenen Zustände des Codierers und den Vektor h4, um den Kontextvektor (C4) in einem gegebenen Zeitintervall zu berechnen.
- Die Vektoren h4 und C4 sind zu einem einzigen Vektor verkettet.
- Dieser Vektor wird durch ein Feedforward-Neuronales Netzwerk (FFN) geleitet, das zusammen mit dem Modell trainiert wird.
- Der Ausgang des FFN-Netzwerks zeigt das Ausgangswort in einem bestimmten Zeitintervall an.
- Der Algorithmus wird für das nächste Zeitintervall wiederholt.
Ein anderer Weg, um zu sehen, welchen Teil des ursprünglichen Satzes das Modell auf jeder Stufe des Decoders fokussiert:
Beachten Sie, dass das Modell nicht nur das erste Wort in der Eingabe mit dem ersten Wort in der Ausgabe sinnlos verbindet. Während des Trainings verstand sie tatsächlich, wie man die Wörter in diesem betrachteten Sprachpaar (in unserem Fall Französisch und Englisch) zusammenbringt. Ein Beispiel dafür, wie genau dieser Mechanismus funktionieren kann, finden Sie in den Artikeln über den oben erwähnten Aufmerksamkeitsmechanismus.

Wenn Sie das Gefühl haben, dass Sie bereit sind, die Anwendung dieses Modells zu erlernen, lesen Sie das Handbuch für die neuronale maschinelle Übersetzung (seq2seq) in TensorFlow.
Die Autoren