El algoritmo DeepStereo pega las tomas de Google Street View en video fluido
Los investigadores de Google John Flynn, Ivan Nyulander, James Filbin y Noah Sneyvli crearon un algoritmo que puede combinar imágenes del servicio de vista panorámica de Street View en videos suaves con artefactos apenas perceptibles. El algoritmo se llama DeepStereo, un ejemplo de su operación se presenta arriba. El uso probable de la tecnología creada incluye la creación de animaciones simples, procesamiento de imágenes, cine y realidad virtual.No siempre es posible evaluar adecuadamente un lugar determinado solo mediante mapas o fotografías digitales. Mirar la calle desde una altura justo por encima de la altura humana ayuda a servicios como Google Street View. Pero estas son fotos pegadas en el panorama, no videos.Si necesita crear una animación para avanzar de disparos individuales, entonces la decisión de simplemente perder la secuencia de imágenes no funcionará, resultará demasiado rápida, porque las imágenes cambiarán a una frecuencia de al menos 24 cuadros por segundo. Si conduce por una carretera o carretera ancha y plana, puede crear una buena animación al estilo de cámara lenta. Pero Google Street View tiene panoramas de museos y calles adornadas: el lapso de tiempo de un cambio rápido de marco no funcionará aquí. Necesita imágenes faltantes entre disparos. El algoritmo creado está involucrado en esto.El equipo de investigadores utilizó el amplio conocimiento de la compañía para entrenar el algoritmo. En la entrada hay un conjunto de imágenes de algunos puntos, y el objetivo es crear nuevos cuadros a partir de otros puntos. La solución exacta a este problema requiere la construcción de un modelo de entorno 3D, que a menudo es imposible debido a los obstáculos. El desafío no es nuevo. Algunos métodos anteriores tienen problemas que conducen a lagunas cerca de las barreras, alias y borrosidad. Las dificultades particulares son causadas por árboles y otros objetos cuyos elementos individuales pueden oscurecer la vista.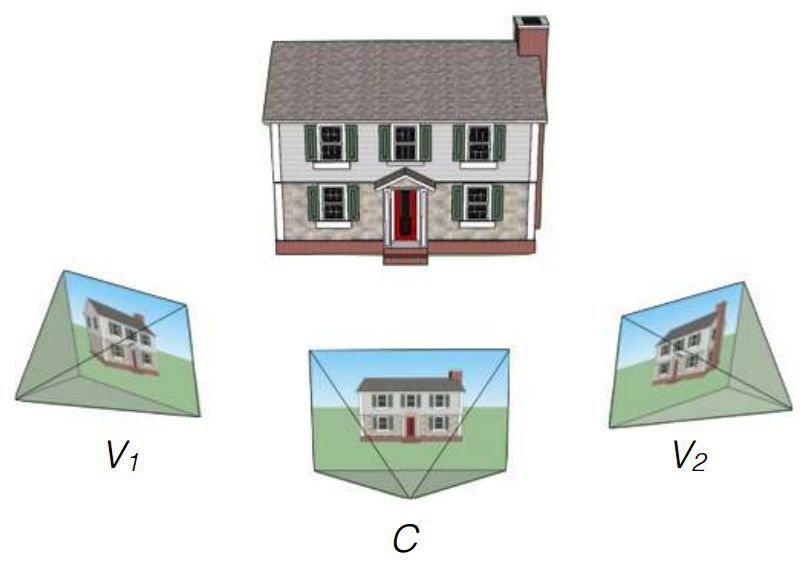 El nuevo método de Flynn utiliza el entrenamiento de visión por computadora para que pueda entender qué objetos deberían estar en los cuadros faltantes. Para el entrenamiento, se utilizaron conjuntos de imágenes de un automóvil en movimiento. Los investigadores dicen que el volumen de la base para el entrenamiento ascendió a 100 mil conjuntos de imágenes.Luego, las pruebas se llevaron a cabo utilizando secuencias de tres tomas de Google Street View. El algoritmo se vio obligado a procesar dos imágenes extremas y presentar una variante del intermedio. Comparación con el original permitido para evaluar el trabajo.El resultado final del equipo DeepStereo es creíble. A primera vista, no es tan fácil distinguirlo de la fotografía real. Los artefactos notables incluyen una ligera pérdida de resolución y la desaparición de estructuras finas en primer plano. Los objetos con una estructura compleja que se superpone a sus propios detalles pueden aparecer borrosos. El algoritmo tampoco puede crear superficies que no están en las imágenes originales. Los objetos en movimiento (peatones, automóviles) se difuminan intencionalmente para crear un efecto de movimiento.Se requiere una potencia de cálculo impresionante para el renderizado. Para crear solo una imagen con una resolución de 512 × 512 píxeles, se requieren aproximadamente 12 minutos de funcionamiento de un sistema multinúcleo con características técnicas sin nombre. Crear imágenes de mayor resolución requiere demasiada RAM. Los investigadores expresan sus esperanzas de optimizar el algoritmo con la posibilidad de reducir el tiempo de representación a varios minutos o incluso segundos al usar procesadores de tarjetas de video. En el futuro, con un refinamiento significativo, el funcionamiento del algoritmo en la GPU es posible incluso en tiempo real.Basado en el texto del estudio y MIT Technology Review . arXiv: 1506.06825 [cs.CV]
El nuevo método de Flynn utiliza el entrenamiento de visión por computadora para que pueda entender qué objetos deberían estar en los cuadros faltantes. Para el entrenamiento, se utilizaron conjuntos de imágenes de un automóvil en movimiento. Los investigadores dicen que el volumen de la base para el entrenamiento ascendió a 100 mil conjuntos de imágenes.Luego, las pruebas se llevaron a cabo utilizando secuencias de tres tomas de Google Street View. El algoritmo se vio obligado a procesar dos imágenes extremas y presentar una variante del intermedio. Comparación con el original permitido para evaluar el trabajo.El resultado final del equipo DeepStereo es creíble. A primera vista, no es tan fácil distinguirlo de la fotografía real. Los artefactos notables incluyen una ligera pérdida de resolución y la desaparición de estructuras finas en primer plano. Los objetos con una estructura compleja que se superpone a sus propios detalles pueden aparecer borrosos. El algoritmo tampoco puede crear superficies que no están en las imágenes originales. Los objetos en movimiento (peatones, automóviles) se difuminan intencionalmente para crear un efecto de movimiento.Se requiere una potencia de cálculo impresionante para el renderizado. Para crear solo una imagen con una resolución de 512 × 512 píxeles, se requieren aproximadamente 12 minutos de funcionamiento de un sistema multinúcleo con características técnicas sin nombre. Crear imágenes de mayor resolución requiere demasiada RAM. Los investigadores expresan sus esperanzas de optimizar el algoritmo con la posibilidad de reducir el tiempo de representación a varios minutos o incluso segundos al usar procesadores de tarjetas de video. En el futuro, con un refinamiento significativo, el funcionamiento del algoritmo en la GPU es posible incluso en tiempo real.Basado en el texto del estudio y MIT Technology Review . arXiv: 1506.06825 [cs.CV] Source: https://habr.com/ru/post/es381787/
All Articles