Generación de música clásica usando una red neuronal recurrente
Hoy en día, las redes neuronales entrenadas hacen cosas asombrosas, pero los experimentos en esta área continúan descubriendo algo nuevo. Por ejemplo, el programador Daniel Johnson publicó los resultados de sus experimentos sobre el uso de redes neuronales para generar música clásica.Desafortunadamente, no puede incrustar un archivo de audio en GT, por lo que debe proporcionar un enlace directo para escuchar uno de los resultados: http://hexahedria.com/files/nnet_music_2.mp3 .¿Cómo lo hizo?Daniel Johnson dice que se centró en la propiedad de la invariancia. La mayoría de las redes neuronales existentes para la generación de música son invariantes en el tiempo, pero no invariables en las notas. Por lo tanto, la transposición de un solo paso conducirá a un resultado completamente diferente. Para la mayoría de las otras aplicaciones, este enfoque funciona bien, pero no en la música. Aquí me gustaría lograr la armonía de las armonías.Daniel encontró solo un tipo de redes neuronales populares donde hay invariancia en varias direcciones: estas son redes neuronales convolucionales para el reconocimiento de imágenes.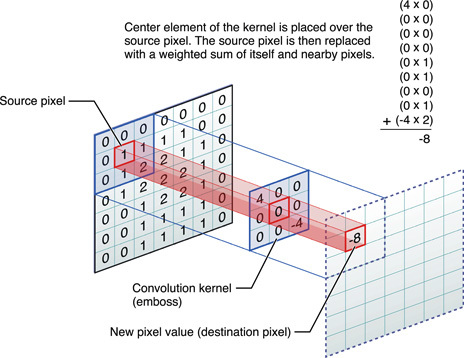 El autor adaptó el modelo convolucional, agregando una red neuronal recurrente para cada píxel con su propia memoria y reemplazando los píxeles con notas. Por lo tanto, recibió un sistema que es invariable tanto en el tiempo como en las notas.
El autor adaptó el modelo convolucional, agregando una red neuronal recurrente para cada píxel con su propia memoria y reemplazando los píxeles con notas. Por lo tanto, recibió un sistema que es invariable tanto en el tiempo como en las notas.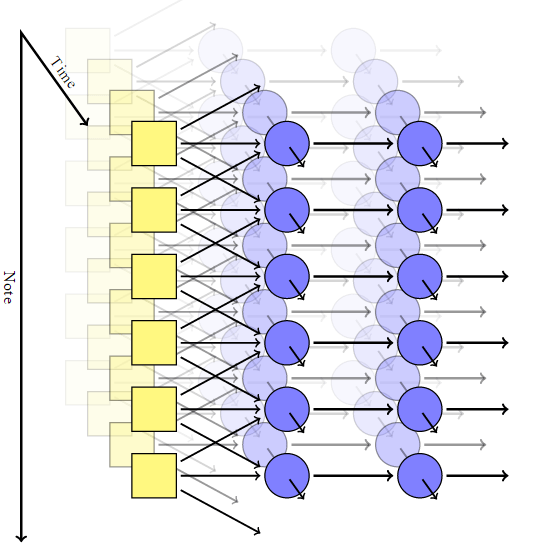 Pero en una red de este tipo no existe un mecanismo para obtener acordes armoniosos: en la salida, cada nota es completamente independiente de las demás.Para lograr una combinación de notas, Johnson usó un modelo como RNN-RBM, donde una parte de la red neuronal es responsable del tiempo, y la otra parte es para acordes consonantes. Para sortear las limitaciones de RBM, se le ocurrió la introducción de dos ejes: para el tiempo y para las notas (y un pseudoeje para la dirección de los cálculos).
Pero en una red de este tipo no existe un mecanismo para obtener acordes armoniosos: en la salida, cada nota es completamente independiente de las demás.Para lograr una combinación de notas, Johnson usó un modelo como RNN-RBM, donde una parte de la red neuronal es responsable del tiempo, y la otra parte es para acordes consonantes. Para sortear las limitaciones de RBM, se le ocurrió la introducción de dos ejes: para el tiempo y para las notas (y un pseudoeje para la dirección de los cálculos).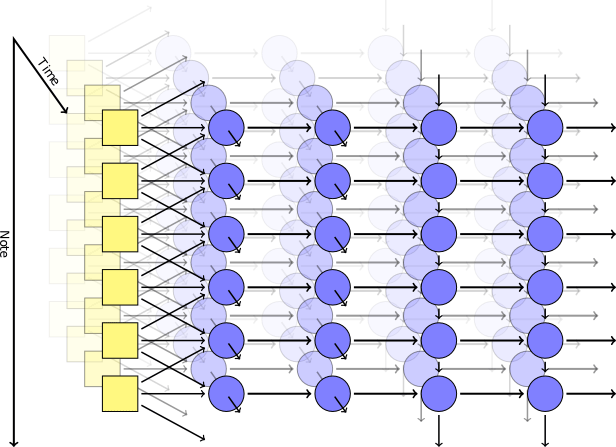 Usando Theano LibraryEl autor generó una red neuronal según su modelo. La primera capa con el eje de tiempo tomó los siguientes parámetros en la entrada: posición, tono, valor de las notas circundantes, contexto anterior, ritmo. Luego, se activaron bloques autogenerados basados en memoria a corto plazo (LSTM): en uno, las conexiones recurrentes se dirigen a lo largo del eje del tiempo, en el otro a lo largo del eje de las notas. Después del bloque LSTM final, hay una capa simple no recurrente para emitir el resultado final, tiene dos valores de salida: la probabilidad de tocar para una nota en particular y la probabilidad de articulación (es decir, la probabilidad de que la nota se combine con otra).Durante el entrenamiento, utilizamos un conjunto de fragmentos musicales cortos seleccionados al azar de la colección MIDI Classical Piano Midi Page. Luego jugamos un poco con los logaritmos para que el parámetro de entropía cruzada en la salida fuera al menos no demasiado bajo. Para garantizar la especialización de las capas, utilizamos una técnica como el abandono , cuando en cada paso del entrenamiento, la mitad de los nodos ocultos fueron excluidos accidentalmente.El modelo práctico consistió en dos capas ocultas en el tiempo, cada una de 300 nodos, y dos capas a lo largo del eje de notas, para 100 y 50 nodos, respectivamente. La capacitación se realizó en la máquina virtual g2.2xlarge en la nube de Amazon Web Services.
Usando Theano LibraryEl autor generó una red neuronal según su modelo. La primera capa con el eje de tiempo tomó los siguientes parámetros en la entrada: posición, tono, valor de las notas circundantes, contexto anterior, ritmo. Luego, se activaron bloques autogenerados basados en memoria a corto plazo (LSTM): en uno, las conexiones recurrentes se dirigen a lo largo del eje del tiempo, en el otro a lo largo del eje de las notas. Después del bloque LSTM final, hay una capa simple no recurrente para emitir el resultado final, tiene dos valores de salida: la probabilidad de tocar para una nota en particular y la probabilidad de articulación (es decir, la probabilidad de que la nota se combine con otra).Durante el entrenamiento, utilizamos un conjunto de fragmentos musicales cortos seleccionados al azar de la colección MIDI Classical Piano Midi Page. Luego jugamos un poco con los logaritmos para que el parámetro de entropía cruzada en la salida fuera al menos no demasiado bajo. Para garantizar la especialización de las capas, utilizamos una técnica como el abandono , cuando en cada paso del entrenamiento, la mitad de los nodos ocultos fueron excluidos accidentalmente.El modelo práctico consistió en dos capas ocultas en el tiempo, cada una de 300 nodos, y dos capas a lo largo del eje de notas, para 100 y 50 nodos, respectivamente. La capacitación se realizó en la máquina virtual g2.2xlarge en la nube de Amazon Web Services.resultados
El código fuente del programa se publica en Github . Source: https://habr.com/ru/post/es382711/
All Articles