Google escucha mejor, la búsqueda es más fácil
Google anunció que habían finalizado su sistema de búsqueda por voz para lograr un mejor reconocimiento del discurso del usuario en lugares ruidosos. Siempre ha sido uno de los mejores sistemas de reconocimiento de voz, es especialmente conveniente cuando se busca utilizando teléfonos inteligentes. Ahora la función de búsqueda por voz se ha desarrollado aún más que nunca. El blog de Google Research describe las mejoras que se han realizado en el sistema actualizado.Desde 2012, el gigante de las búsquedas se ha alejado del uso del Método Gaussian Mixes (MGS) hace treinta años en el reconocimiento de voz. Los nuevos sistemas comenzaron a utilizar redes neuronales profundas ( Redes neuronales profundas ). STS puede reconocer mejor los sonidos que emite el usuario en un determinado momento, lo que aumenta considerablemente la precisión del reconocimiento.
Siempre ha sido uno de los mejores sistemas de reconocimiento de voz, es especialmente conveniente cuando se busca utilizando teléfonos inteligentes. Ahora la función de búsqueda por voz se ha desarrollado aún más que nunca. El blog de Google Research describe las mejoras que se han realizado en el sistema actualizado.Desde 2012, el gigante de las búsquedas se ha alejado del uso del Método Gaussian Mixes (MGS) hace treinta años en el reconocimiento de voz. Los nuevos sistemas comenzaron a utilizar redes neuronales profundas ( Redes neuronales profundas ). STS puede reconocer mejor los sonidos que emite el usuario en un determinado momento, lo que aumenta considerablemente la precisión del reconocimiento.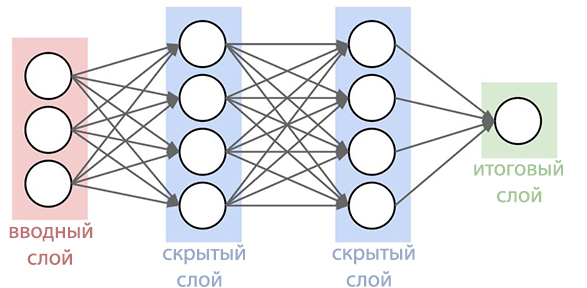 Ahora, los expertos de Google han anunciado que han logrado crear una red neuronal más avanzada de modelos acústicos que utilizan clasificación temporal conexionista y algoritmos de aprendizaje discriminatorios . Estos modelos representan una extensión especial de redes neuronales periódicas que son más precisas, especialmente en entornos ruidosos, ¡e increíblemente rápidas!En el reconocimiento de voz tradicional, la forma de voz que el usuario completaba se dividía en cuadros consecutivos (segmentos) de 10 milisegundos. Cada cuadro se sometió a un análisis de frecuencia y el vector resultante con las características se pasó a través de modelos acústicos, como GNS, que dan probabilidades para todas las coincidencias de sonido. El modelo oculto de Markov (SMM) ayuda a desentrañar detalles desconocidos sobre la base de los ya obtenidos; esto permite introducir un tipo de estructuración de esta secuencia de distribuciones de probabilidad. Este modelo se combina además con otras fuentes de conocimiento, como el Modelo de Pronunciación, que vincula las secuencias de sonidos con ciertas palabras, el idioma seleccionado y el Modelo de Idioma, que a su vez expresa cuánto se refiere la palabra al idioma seleccionado.El reconocedor luego concilia toda esta información para determinar la oración que hace el usuario. Si el usuario dice, por ejemplo, la palabra "museo" (mju: 'zɪəm es una forma fonética), entonces puede ser difícil determinar cuándo termina el sonido "j" y comienza el sonido "u". Sin embargo, en verdad, al determinante no le importa cuándo ocurre esta transición. Lo único que le molesta es precisamente los sonidos que se pronunciaron.El nuevo modelo acústico mejorado se basa en redes neuronales periódicas (PNS). En la topología del PNS, hay bucles de retroalimentación que le permiten simular la dependencia del tiempo. Cuando el usuario pronuncia / U / en el ejemplo anterior, el aparato de articulación de la persona se mueve suavemente del sonido / J / al sonido / M / en primer lugar. Intente pronunciar la palabra "museo", para las personas que hablan inglés con fluidez, no será difícil y la palabra se pronunciará fácilmente de una sola vez, PNS puede captar este momento.
Ahora, los expertos de Google han anunciado que han logrado crear una red neuronal más avanzada de modelos acústicos que utilizan clasificación temporal conexionista y algoritmos de aprendizaje discriminatorios . Estos modelos representan una extensión especial de redes neuronales periódicas que son más precisas, especialmente en entornos ruidosos, ¡e increíblemente rápidas!En el reconocimiento de voz tradicional, la forma de voz que el usuario completaba se dividía en cuadros consecutivos (segmentos) de 10 milisegundos. Cada cuadro se sometió a un análisis de frecuencia y el vector resultante con las características se pasó a través de modelos acústicos, como GNS, que dan probabilidades para todas las coincidencias de sonido. El modelo oculto de Markov (SMM) ayuda a desentrañar detalles desconocidos sobre la base de los ya obtenidos; esto permite introducir un tipo de estructuración de esta secuencia de distribuciones de probabilidad. Este modelo se combina además con otras fuentes de conocimiento, como el Modelo de Pronunciación, que vincula las secuencias de sonidos con ciertas palabras, el idioma seleccionado y el Modelo de Idioma, que a su vez expresa cuánto se refiere la palabra al idioma seleccionado.El reconocedor luego concilia toda esta información para determinar la oración que hace el usuario. Si el usuario dice, por ejemplo, la palabra "museo" (mju: 'zɪəm es una forma fonética), entonces puede ser difícil determinar cuándo termina el sonido "j" y comienza el sonido "u". Sin embargo, en verdad, al determinante no le importa cuándo ocurre esta transición. Lo único que le molesta es precisamente los sonidos que se pronunciaron.El nuevo modelo acústico mejorado se basa en redes neuronales periódicas (PNS). En la topología del PNS, hay bucles de retroalimentación que le permiten simular la dependencia del tiempo. Cuando el usuario pronuncia / U / en el ejemplo anterior, el aparato de articulación de la persona se mueve suavemente del sonido / J / al sonido / M / en primer lugar. Intente pronunciar la palabra "museo", para las personas que hablan inglés con fluidez, no será difícil y la palabra se pronunciará fácilmente de una sola vez, PNS puede captar este momento.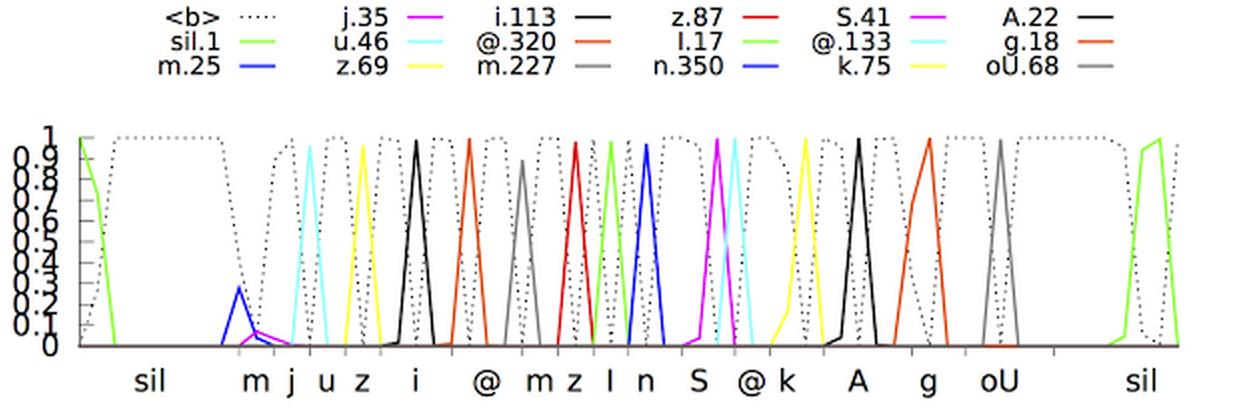 Un tipo de redes neuronales periódicas en este sistema es una memoria a largo plazo a corto plazo, que con la ayuda de las células de memoria y un complejo mecanismo de activación recuerda mejor la información que otros PNS. Gating es un método para asignar un cierto intervalo de tiempo para aumentar la probabilidad de detectar señales útiles en un contexto de interferencia. La adopción de tales modelos ya ha mejorado significativamente la calidad del reconocimiento de voz.El siguiente paso fue enseñar al modelo acústico a reconocer fonemas (sonidos) en el discurso entregado sin hacer una predicción para cada cuadro. Los modelos con la Clasificación de tiempo asociativa preparan un gráfico con una secuencia de "picos" que muestran la secuencia de sonidos en la señal recibida, que pueden hacer hasta que la secuencia se interrumpa.De hecho, el sistema de reconocimiento de voz de Google ahora puede examinar el contexto en el que se pronunció la palabra, alejándose de los sonidos de fondo.
Un tipo de redes neuronales periódicas en este sistema es una memoria a largo plazo a corto plazo, que con la ayuda de las células de memoria y un complejo mecanismo de activación recuerda mejor la información que otros PNS. Gating es un método para asignar un cierto intervalo de tiempo para aumentar la probabilidad de detectar señales útiles en un contexto de interferencia. La adopción de tales modelos ya ha mejorado significativamente la calidad del reconocimiento de voz.El siguiente paso fue enseñar al modelo acústico a reconocer fonemas (sonidos) en el discurso entregado sin hacer una predicción para cada cuadro. Los modelos con la Clasificación de tiempo asociativa preparan un gráfico con una secuencia de "picos" que muestran la secuencia de sonidos en la señal recibida, que pueden hacer hasta que la secuencia se interrumpa.De hecho, el sistema de reconocimiento de voz de Google ahora puede examinar el contexto en el que se pronunció la palabra, alejándose de los sonidos de fondo. Una pregunta completamente diferente: ¿cómo hacer que todo sea accesible y conveniente en tiempo real? Después de una gran cantidad de iteraciones, los programadores de Google lograron crear modelos de transmisión de flujo único que procesan las señales entrantes con bloques que son más grandes que los bloques en los modelos acústicos estándar, pero al mismo tiempo hacen menos cálculos reales. Reducir el número de operaciones computacionales acelera significativamente el proceso de reconocimiento. Además, el ruido artificial y la reverberación (reducción artificial de los sonidos) se agregaron al programa de entrenamiento del sistema para hacer que el sistema de reconocimiento sea más resistente al ruido extraño. En el video a continuación, puede ver cómo el sistema aprende la oración.Sin embargo, quedaba un problema más por resolver: el sistema produce menos pronósticos, pero al mismo tiempo se retrasan aproximadamente 300 milisegundos. Al generar el resultado después de completar la oración, el nivel de reconocimiento aumentó, pero al mismo tiempo se crearon demoras adicionales para los usuarios, lo que es completamente inaceptable para los especialistas de Goolge. Para resolver el problema, el sistema fue entrenado para analizar y producir el resultado de cada frase antes de que se complete. Esto hizo que el proceso de reconocimiento estuviera más sincronizado con la tasa normal de pronunciación de una persona. Ya no se requiere que el usuario espere hasta que el programa muestre su propia versión de la frase hablada.Ya se utilizan nuevos modelos acústicos para búsqueda por voz y comandos en la aplicación Google(en Android e iOS) y para dictado en dispositivos Android. Los nuevos modelos comenzaron a requerir menos recursos, se volvieron más resistentes al ruido ambiental y pudieron producir resultados mucho más rápido que sus predecesores. Esto hace que la búsqueda por voz sea más agradable para el usuario.
Una pregunta completamente diferente: ¿cómo hacer que todo sea accesible y conveniente en tiempo real? Después de una gran cantidad de iteraciones, los programadores de Google lograron crear modelos de transmisión de flujo único que procesan las señales entrantes con bloques que son más grandes que los bloques en los modelos acústicos estándar, pero al mismo tiempo hacen menos cálculos reales. Reducir el número de operaciones computacionales acelera significativamente el proceso de reconocimiento. Además, el ruido artificial y la reverberación (reducción artificial de los sonidos) se agregaron al programa de entrenamiento del sistema para hacer que el sistema de reconocimiento sea más resistente al ruido extraño. En el video a continuación, puede ver cómo el sistema aprende la oración.Sin embargo, quedaba un problema más por resolver: el sistema produce menos pronósticos, pero al mismo tiempo se retrasan aproximadamente 300 milisegundos. Al generar el resultado después de completar la oración, el nivel de reconocimiento aumentó, pero al mismo tiempo se crearon demoras adicionales para los usuarios, lo que es completamente inaceptable para los especialistas de Goolge. Para resolver el problema, el sistema fue entrenado para analizar y producir el resultado de cada frase antes de que se complete. Esto hizo que el proceso de reconocimiento estuviera más sincronizado con la tasa normal de pronunciación de una persona. Ya no se requiere que el usuario espere hasta que el programa muestre su propia versión de la frase hablada.Ya se utilizan nuevos modelos acústicos para búsqueda por voz y comandos en la aplicación Google(en Android e iOS) y para dictado en dispositivos Android. Los nuevos modelos comenzaron a requerir menos recursos, se volvieron más resistentes al ruido ambiental y pudieron producir resultados mucho más rápido que sus predecesores. Esto hace que la búsqueda por voz sea más agradable para el usuario. Source: https://habr.com/ru/post/es384747/
All Articles