IoT y hackathon Azure Machine Learning: cómo hicimos el proyecto fuera de competencia
 No hace mucho tiempo, tuvo lugar otro hackathon de Microsoft. Esta vez, se dedicó al aprendizaje automático . El tema es muy relevante y prometedor, sin embargo, para mí es bastante vago. Al comienzo del hackathon, solo tenía una idea general de lo que era, por qué era necesario, y vi los resultados de los modelos entrenados un par de veces. Después de enterarme de que el anuncio prometía a muchos expertos ayudar a los principiantes, decidí combinar negocios con placer e intentar utilizar el aprendizaje automático cuando trabaje con algún tipo de solución de IoT . A continuación, te diré lo que sucedió.Durante mucho tiempo he estado involucrado en los sistemas de seguridad perimetral, con base en el análisis de las vibraciones de la valla, por lo que una vez que la idea de trabajar con acelerómetro. La idea era simple: enseñar al sistema a distinguir entre la vibración de varios teléfonos, en base a los datos del acelerómetro. Experimentos similares ya han sido realizados con éxito por mis colegas, por lo que no tuve dudas de que esto era posible.Inicialmente, quería hacer todo en Raspberry Pi 2 y Windows IoT . Se preparó una placa especial (en la foto a continuación) con acelerómetros digitales y analógicos, pero no pude probarlo en la práctica, después de haber decidido hacer todo en un hackathon. Por si acaso, también capturé nuestro sensor , que también le permite aprender datos "en bruto" sobre las fluctuaciones.
No hace mucho tiempo, tuvo lugar otro hackathon de Microsoft. Esta vez, se dedicó al aprendizaje automático . El tema es muy relevante y prometedor, sin embargo, para mí es bastante vago. Al comienzo del hackathon, solo tenía una idea general de lo que era, por qué era necesario, y vi los resultados de los modelos entrenados un par de veces. Después de enterarme de que el anuncio prometía a muchos expertos ayudar a los principiantes, decidí combinar negocios con placer e intentar utilizar el aprendizaje automático cuando trabaje con algún tipo de solución de IoT . A continuación, te diré lo que sucedió.Durante mucho tiempo he estado involucrado en los sistemas de seguridad perimetral, con base en el análisis de las vibraciones de la valla, por lo que una vez que la idea de trabajar con acelerómetro. La idea era simple: enseñar al sistema a distinguir entre la vibración de varios teléfonos, en base a los datos del acelerómetro. Experimentos similares ya han sido realizados con éxito por mis colegas, por lo que no tuve dudas de que esto era posible.Inicialmente, quería hacer todo en Raspberry Pi 2 y Windows IoT . Se preparó una placa especial (en la foto a continuación) con acelerómetros digitales y analógicos, pero no pude probarlo en la práctica, después de haber decidido hacer todo en un hackathon. Por si acaso, también capturé nuestro sensor , que también le permite aprender datos "en bruto" sobre las fluctuaciones. En el hackathon, se pidió a todos los participantes que se dividieran en equipos y resolvieran uno de los 3 problemas utilizando datos previamente preparados. Mi tarea resultó estar "fuera de competencia", pero el equipo se reunió lo suficientemente rápido:
En el hackathon, se pidió a todos los participantes que se dividieran en equipos y resolvieran uno de los 3 problemas utilizando datos previamente preparados. Mi tarea resultó estar "fuera de competencia", pero el equipo se reunió lo suficientemente rápido: ninguno de nosotros tenía experiencia en el uso de Azure Machine Learning, ¡así que había mucho que hacer! ¡Gracias a los colegas, entre los cuales estaba psfinaki , por sus esfuerzos!Se decidió dividir en 3 direcciones:
ninguno de nosotros tenía experiencia en el uso de Azure Machine Learning, ¡así que había mucho que hacer! ¡Gracias a los colegas, entre los cuales estaba psfinaki , por sus esfuerzos!Se decidió dividir en 3 direcciones:- preparación de datos para análisis
- subir datos a la nube
- trabajar con Azure Machine Learning
La preparación de los datos fue obtenerlos del acelerómetro y luego presentarlos en un formulario disponible para descargar a la nube. La carga a la nube se planeó a través de Event Hub . Bueno, entonces tenía que entender cómo usar estos datos en Azure Machine Learning.Los problemas comenzaron en los tres puntos. Tomó mucho tiempo configurar Windows IoT en Raspberry. Ella no dio una imagen en el monitor. Fue posible resolver esto solo ingresando las siguientes líneas en config.txt:
Tomó mucho tiempo configurar Windows IoT en Raspberry. Ella no dio una imagen en el monitor. Fue posible resolver esto solo ingresando las siguientes líneas en config.txt:hdmi_ignore_edid=0xa5000080hdmi_drive=2hdmi_group=2hdmi_mode=16Esto sintonizó el controlador de video al formato, resolución y frecuencia deseados. Sin embargo, el tiempo dedicado a esta lección dejó en claro que es posible que no tenga tiempo para organizar la recepción de datos del acelerómetro. Por lo tanto, se decidió utilizar el sensor que había tomado en reserva.Muchas aplicaciones ya se han escrito para el sensor. Uno de ellos mostraba en la pantalla un gráfico de datos "en bruto":
Sin embargo, el tiempo dedicado a esta lección dejó en claro que es posible que no tenga tiempo para organizar la recepción de datos del acelerómetro. Por lo tanto, se decidió utilizar el sensor que había tomado en reserva.Muchas aplicaciones ya se han escrito para el sensor. Uno de ellos mostraba en la pantalla un gráfico de datos "en bruto":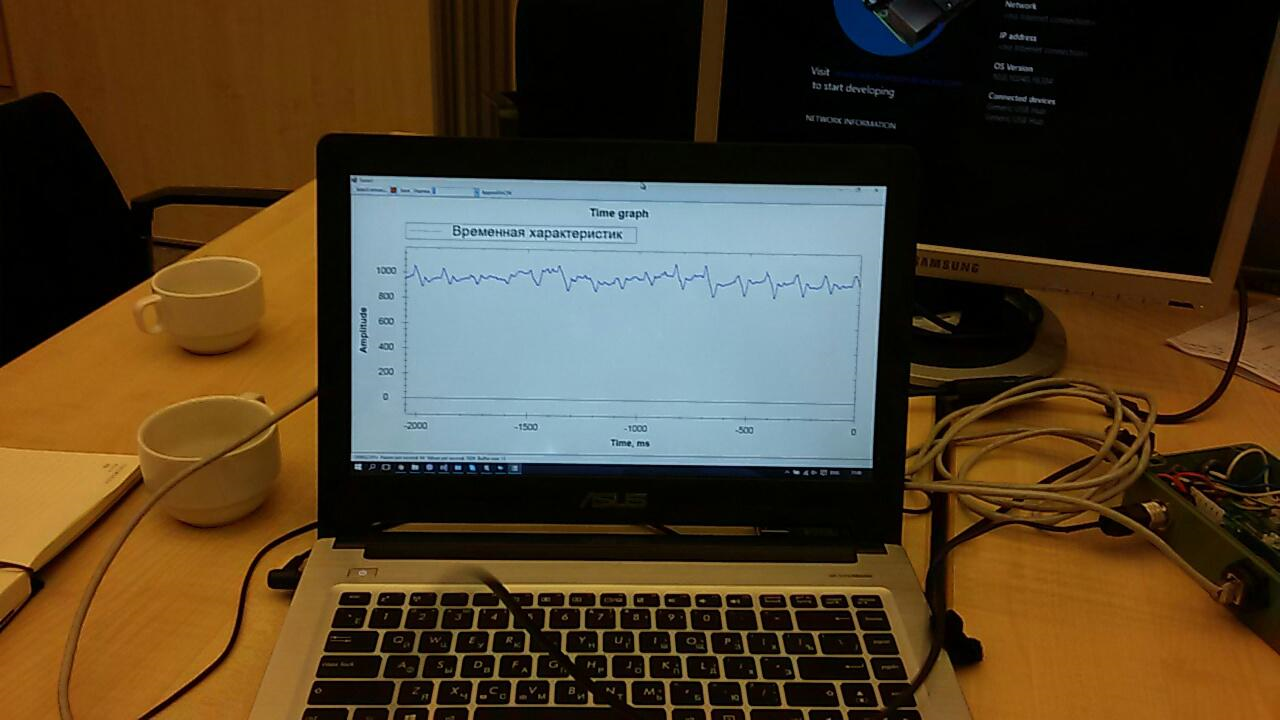 era necesario completarlo un poco para preparar los datos para enviarlos a la nube.Event Hub tampoco funcionó de inmediato. Para empezar, tratamos de enviar allí solo una secuencia aleatoria. Pero los datos no querían aparecer en los informes. Hubo varios problemas y, como resultó, todos eran "infantiles": en algún lugar lo configuraron mal, en algún lugar usaron la tecla incorrecta, y así sucesivamente. Trabajar en esta dirección fue difícil y requirió mucha energía:
era necesario completarlo un poco para preparar los datos para enviarlos a la nube.Event Hub tampoco funcionó de inmediato. Para empezar, tratamos de enviar allí solo una secuencia aleatoria. Pero los datos no querían aparecer en los informes. Hubo varios problemas y, como resultó, todos eran "infantiles": en algún lugar lo configuraron mal, en algún lugar usaron la tecla incorrecta, y así sucesivamente. Trabajar en esta dirección fue difícil y requirió mucha energía: pero, al anochecer del primer día, pudimos enviar y recibir datos del sensor sobre la marcha ... Es cierto, esto no era necesario en la solución final. Hablaré de las razones un poco más tarde.Con Machine Learning, nada estaba claro en absoluto. Al principio juntos estudiamos lo belloartículo con un ejemplo de uso de una aplicación móvil como cliente. Luego descubrimos el formato de datos y cómo trabajar con ellos. Luego pensaron en cómo crear secuencias de entrenamiento.Azure Mashine Learning tiene muchos algoritmos para varias clasificaciones. Estos algoritmos deben ser entrenados en un conjunto de datos de prueba. Luego, aquellos que dan el mejor resultado pueden publicarse como un servicio web y conectarse a ellos desde la aplicación.Aprender un algoritmo se llama "experimento". Todas las acciones se llevan a cabo en un editor visual:
pero, al anochecer del primer día, pudimos enviar y recibir datos del sensor sobre la marcha ... Es cierto, esto no era necesario en la solución final. Hablaré de las razones un poco más tarde.Con Machine Learning, nada estaba claro en absoluto. Al principio juntos estudiamos lo belloartículo con un ejemplo de uso de una aplicación móvil como cliente. Luego descubrimos el formato de datos y cómo trabajar con ellos. Luego pensaron en cómo crear secuencias de entrenamiento.Azure Mashine Learning tiene muchos algoritmos para varias clasificaciones. Estos algoritmos deben ser entrenados en un conjunto de datos de prueba. Luego, aquellos que dan el mejor resultado pueden publicarse como un servicio web y conectarse a ellos desde la aplicación.Aprender un algoritmo se llama "experimento". Todas las acciones se llevan a cabo en un editor visual: arrastrar y soltar elementos de la lista de la izquierda le permite recibir datos, modificarlos y transformarlos, entrenar modelos y evaluar su trabajo.Así es como se ve un experimento típico:
arrastrar y soltar elementos de la lista de la izquierda le permite recibir datos, modificarlos y transformarlos, entrenar modelos y evaluar su trabajo.Así es como se ve un experimento típico: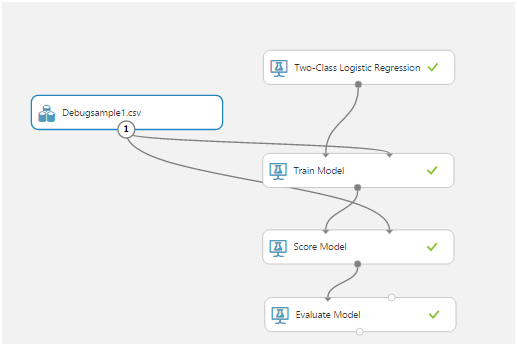 el modelo de tren, el modelo de puntuación y el modelo de evaluación resultaron ser los más importantes.El primero, utilizando los datos de entrada, entrena el algoritmo, el segundo prueba el algoritmo entrenado en el conjunto de datos, el tercero evalúa el resultado de la prueba.La fuente de datos en nuestro caso es un archivo csv. Pero, ¿qué debe contener?El elemento sensible de nuestro sensor se sondea 1024 veces por segundo. Cada encuesta es un valor de dos bytes correspondiente a la amplitud de la oscilación actual. Además, la amplitud se mide no desde cero, sino desde el número de referencia correspondiente a un sensor fijo.Después de reflexionar, decidimos usar cortes temporales. Por ejemplo, todas las encuestas de sensores durante 256 ms nos dieron una línea en la tabla csv. Estos datos, en una columna adicional, podrían marcarse de una forma u otra, dependiendo de lo que esté sucediendo con el sensor. Por ejemplo, utilizamos 0 para indicar ruido (agitar el sensor con las manos, tocar, etc.) y 1 para indicar la señal (hay un teléfono vibrante en el sensor).Así es como registramos las secuencias de prueba:
el modelo de tren, el modelo de puntuación y el modelo de evaluación resultaron ser los más importantes.El primero, utilizando los datos de entrada, entrena el algoritmo, el segundo prueba el algoritmo entrenado en el conjunto de datos, el tercero evalúa el resultado de la prueba.La fuente de datos en nuestro caso es un archivo csv. Pero, ¿qué debe contener?El elemento sensible de nuestro sensor se sondea 1024 veces por segundo. Cada encuesta es un valor de dos bytes correspondiente a la amplitud de la oscilación actual. Además, la amplitud se mide no desde cero, sino desde el número de referencia correspondiente a un sensor fijo.Después de reflexionar, decidimos usar cortes temporales. Por ejemplo, todas las encuestas de sensores durante 256 ms nos dieron una línea en la tabla csv. Estos datos, en una columna adicional, podrían marcarse de una forma u otra, dependiendo de lo que esté sucediendo con el sensor. Por ejemplo, utilizamos 0 para indicar ruido (agitar el sensor con las manos, tocar, etc.) y 1 para indicar la señal (hay un teléfono vibrante en el sensor).Así es como registramos las secuencias de prueba: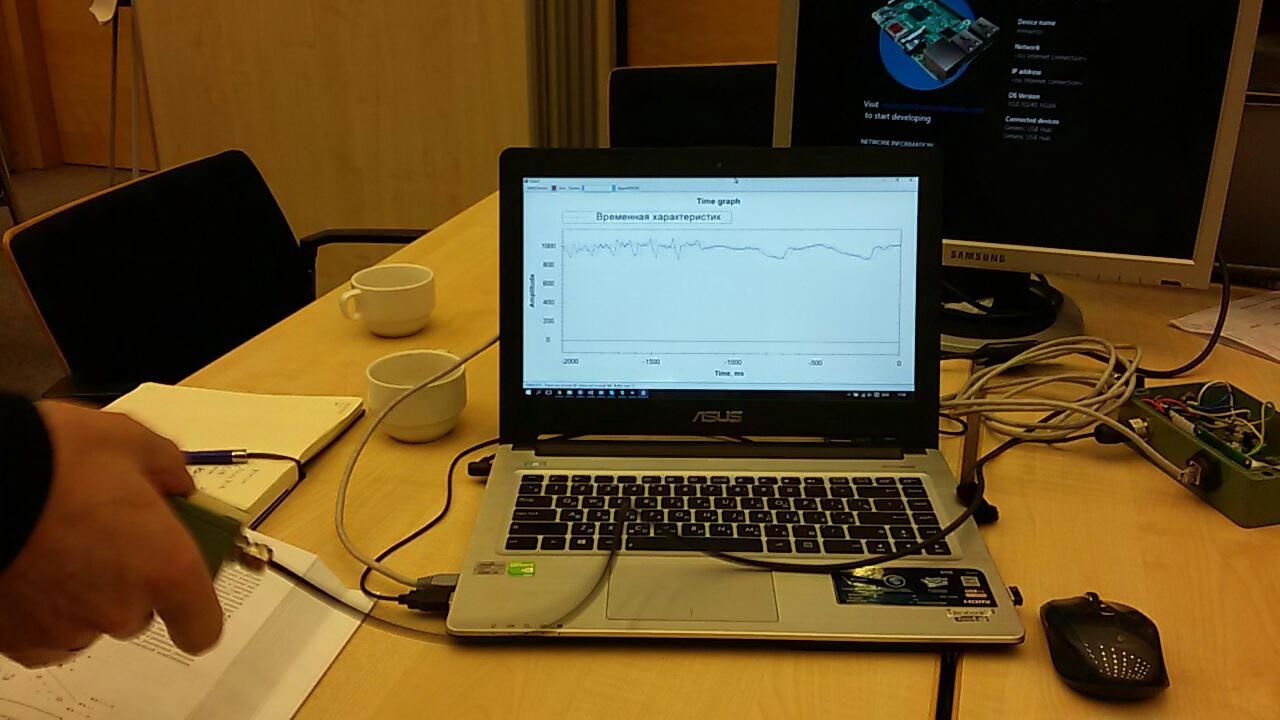 después de recibir los datos y de darnos cuenta de lo que hay que hacer con ellos, comenzamos a aprender el primer modelo:
después de recibir los datos y de darnos cuenta de lo que hay que hacer con ellos, comenzamos a aprender el primer modelo: el primer panqueque resultó ser grumoso:
el primer panqueque resultó ser grumoso: En ese momento, incluso el significado de estos indicadores no estaba claro. Fuimos salvados por un representante del equipo de soporte, Yevgeny Grigorenko, hablando sobre las curvas ROC. ¡Lo principal fue que si el gráfico está debajo de la línea media en algún lugar, entonces el modelo funciona aún peor que si se obtuviera un resultado aleatorio! Eugene continuó ayudándonos tanto como pudo, ¡por lo que muchas gracias a él!
En ese momento, incluso el significado de estos indicadores no estaba claro. Fuimos salvados por un representante del equipo de soporte, Yevgeny Grigorenko, hablando sobre las curvas ROC. ¡Lo principal fue que si el gráfico está debajo de la línea media en algún lugar, entonces el modelo funciona aún peor que si se obtuviera un resultado aleatorio! Eugene continuó ayudándonos tanto como pudo, ¡por lo que muchas gracias a él! Luego reescribimos la secuencia de entrenamiento durante mucho tiempo y observamos los resultados:
Luego reescribimos la secuencia de entrenamiento durante mucho tiempo y observamos los resultados: resultó que trabajar con una grabación de 2 segundos (2048 encuestas de sensores) fue menos óptimo. Esto nos permitió hacer que las filas de la tabla csv sean más significativas. Pero el resultado aún estaba lejos de ser bueno.Esto terminó el primer día.Pasé la noche estudiando el material. El artículo realmente ayudósobre la clasificación binaria. También leí cuidadosamente el artículo con consejos para este hackathon. En general, al comienzo del trabajo estaba lleno de nuevas ideas.Pasamos toda la primera mitad del segundo día estudiando diferentes modelos. El resultado del trabajo fue una "hoja": en
resultó que trabajar con una grabación de 2 segundos (2048 encuestas de sensores) fue menos óptimo. Esto nos permitió hacer que las filas de la tabla csv sean más significativas. Pero el resultado aún estaba lejos de ser bueno.Esto terminó el primer día.Pasé la noche estudiando el material. El artículo realmente ayudósobre la clasificación binaria. También leí cuidadosamente el artículo con consejos para este hackathon. En general, al comienzo del trabajo estaba lleno de nuevas ideas.Pasamos toda la primera mitad del segundo día estudiando diferentes modelos. El resultado del trabajo fue una "hoja": en este momento ya estaba claro que simplemente no teníamos tiempo para distinguir entre dos anillos de vibración, ya que la calidad de los datos de entrenamiento dejaba mucho que desear, y no había suficiente tiempo para grabar nuevos. Por lo tanto, nos centramos en la separación de datos en "señal" y "ruido".Para el trabajo, utilizamos 3 conjuntos de datos:
este momento ya estaba claro que simplemente no teníamos tiempo para distinguir entre dos anillos de vibración, ya que la calidad de los datos de entrenamiento dejaba mucho que desear, y no había suficiente tiempo para grabar nuevos. Por lo tanto, nos centramos en la separación de datos en "señal" y "ruido".Para el trabajo, utilizamos 3 conjuntos de datos:- Un conjunto de entrenamiento en el que había una señal (líneas del archivo csv marcadas con 1) y ruido (líneas marcadas con 0)
- Un conjunto que contiene solo ruido (líneas de 0)
- Un conjunto que contiene solo la señal (líneas de 1)
Los modelos fueron entrenados primero, luego probados y evaluados en cada uno de los conjuntos de datos. Los resultados fueron alentadores: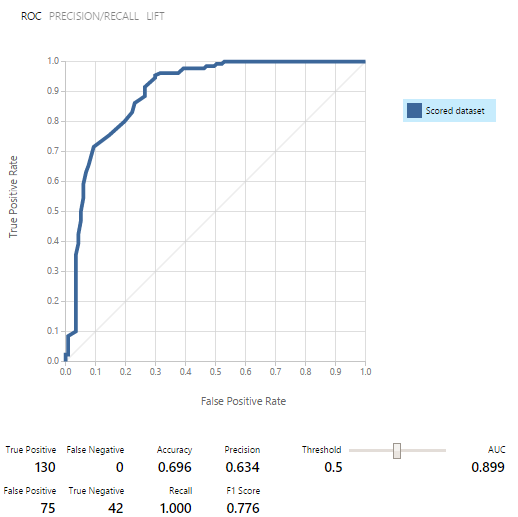 como resultado, de nueve modelos de clasificación binaria, seleccionamos cinco.Al final resultó que, usar el modelo como un servicio web es mucho más fácil que atornillarlo al centro de eventos. Por lo tanto, decidimos publicar los 5 modelos y trabajar con ellos a través de SOLICITUD / RESPUESTA, que se acompaña de un muy buen ejemplo.
como resultado, de nueve modelos de clasificación binaria, seleccionamos cinco.Al final resultó que, usar el modelo como un servicio web es mucho más fácil que atornillarlo al centro de eventos. Por lo tanto, decidimos publicar los 5 modelos y trabajar con ellos a través de SOLICITUD / RESPUESTA, que se acompaña de un muy buen ejemplo. La solicitud es una matriz de entrada de 2048 valores tomados del sensor. La respuesta se ve así:
La solicitud es una matriz de entrada de 2048 valores tomados del sensor. La respuesta se ve así: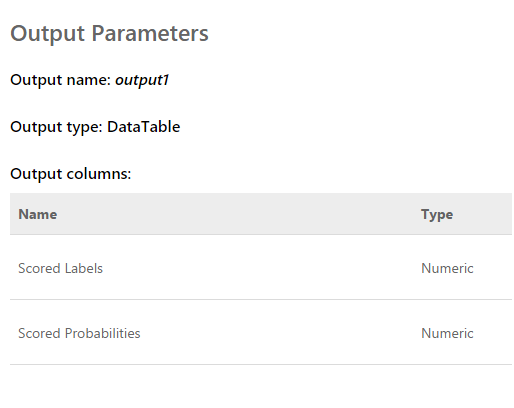 Las etiquetas puntuadas son 0 o 1. Es decir, el resultado de la clasificación. Probabilidades puntuadas: un número decimal que refleja la corrección de la evaluación. Según tengo entendido, el primer valor es redondear el segundo. Es decir, cuanto más cercano sea el segundo valor a 0, el puntaje 0 es más probable y viceversa. Cuanto más cercano sea el valor a 1, la puntuación 1 es más probable.Una vez finalizado el programa que muestra el gráfico de "datos en bruto" en la pantalla, pudimos recibir simultáneamente datos de los cinco servicios web de varias transmisiones. Además, después de observar un poco las estimaciones, excluimos una, ya que dio un resultado que era completamente diferente de las demás y echó a perder todo el panorama.El resultado es el siguiente:
Las etiquetas puntuadas son 0 o 1. Es decir, el resultado de la clasificación. Probabilidades puntuadas: un número decimal que refleja la corrección de la evaluación. Según tengo entendido, el primer valor es redondear el segundo. Es decir, cuanto más cercano sea el segundo valor a 0, el puntaje 0 es más probable y viceversa. Cuanto más cercano sea el valor a 1, la puntuación 1 es más probable.Una vez finalizado el programa que muestra el gráfico de "datos en bruto" en la pantalla, pudimos recibir simultáneamente datos de los cinco servicios web de varias transmisiones. Además, después de observar un poco las estimaciones, excluimos una, ya que dio un resultado que era completamente diferente de las demás y echó a perder todo el panorama.El resultado es el siguiente: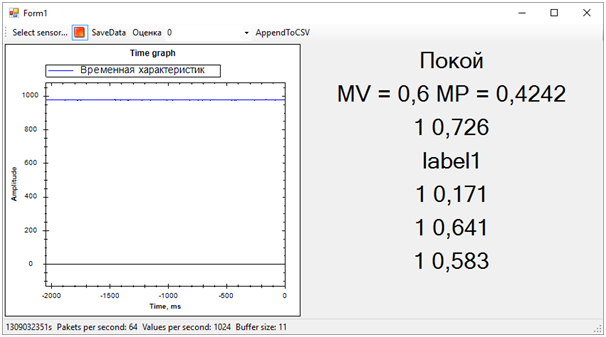
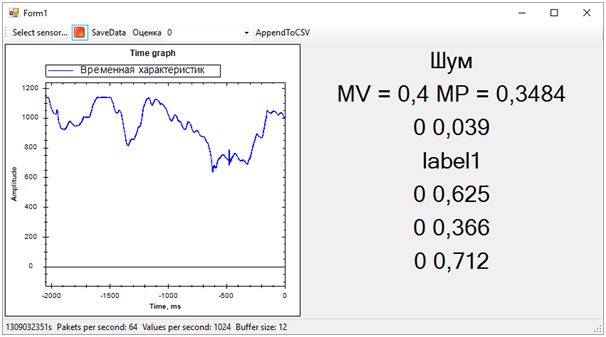
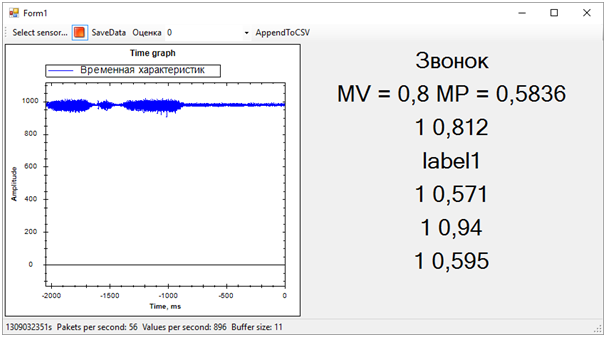 Entonces todos los problemas de la secuencia de entrenamiento salieron inmediatamente. Aunque tratamos de separar la alerta de vibración de todo lo demás (ruido y descanso), el estado de descanso resultó estar muy cerca de la llamada, esto estaba lejos de ser siempre determinado. La diferencia entre la llamada y el resto, la determinamos por el número promedio de probabilidades para cada modelo. Un valor más cercano a 1 significa una llamada, un valor de aproximadamente 0.5 con un puntaje de 1 es paz. Bueno, si el puntaje es 0, esto definitivamente es ruido.En este momento, el hackathon llegó a su fin. Ni siquiera tuvimos tiempo de mostrar los resultados a los expertos, ya que estaban ocupados evaluando las entradas.Pero todo esto ya no era de particular importancia. Lo más importante, ¡hemos logrado un resultado completamente sano y al mismo tiempo hemos aprendido mucho!En dos días de arduo trabajo, completamos, aunque parcialmente, la tarea. ¡Gracias a los colegas del equipo y a los expertos que nos ayudaron!Ahora podemos observar las rutas de desarrollo de nuestro proyecto. Utilizamos características de tiempo para separar eventos. Sin embargo, si nos movemos al dominio de la frecuencia, la eficiencia de los algoritmos debería ser mayor. El ruido, la paz y la campana tienen características espectrales notablemente diferentes.Además, personas experimentadas sugirieron que los datos deberían normalizarse. Es decir, los números de la secuencia de entrada deben estar en el rango de -1 a +1. Los algoritmos funcionan de manera más eficiente con dichos datos.Bueno, aún así, es necesario trabajar en la formación de secuencias de entrenamiento para separar más claramente la señal del ruido.Estas mejoras deberían aumentar significativamente la precisión de la determinación del estado, que quiero verificar en el futuro.
Entonces todos los problemas de la secuencia de entrenamiento salieron inmediatamente. Aunque tratamos de separar la alerta de vibración de todo lo demás (ruido y descanso), el estado de descanso resultó estar muy cerca de la llamada, esto estaba lejos de ser siempre determinado. La diferencia entre la llamada y el resto, la determinamos por el número promedio de probabilidades para cada modelo. Un valor más cercano a 1 significa una llamada, un valor de aproximadamente 0.5 con un puntaje de 1 es paz. Bueno, si el puntaje es 0, esto definitivamente es ruido.En este momento, el hackathon llegó a su fin. Ni siquiera tuvimos tiempo de mostrar los resultados a los expertos, ya que estaban ocupados evaluando las entradas.Pero todo esto ya no era de particular importancia. Lo más importante, ¡hemos logrado un resultado completamente sano y al mismo tiempo hemos aprendido mucho!En dos días de arduo trabajo, completamos, aunque parcialmente, la tarea. ¡Gracias a los colegas del equipo y a los expertos que nos ayudaron!Ahora podemos observar las rutas de desarrollo de nuestro proyecto. Utilizamos características de tiempo para separar eventos. Sin embargo, si nos movemos al dominio de la frecuencia, la eficiencia de los algoritmos debería ser mayor. El ruido, la paz y la campana tienen características espectrales notablemente diferentes.Además, personas experimentadas sugirieron que los datos deberían normalizarse. Es decir, los números de la secuencia de entrada deben estar en el rango de -1 a +1. Los algoritmos funcionan de manera más eficiente con dichos datos.Bueno, aún así, es necesario trabajar en la formación de secuencias de entrenamiento para separar más claramente la señal del ruido.Estas mejoras deberían aumentar significativamente la precisión de la determinación del estado, que quiero verificar en el futuro.Source: https://habr.com/ru/post/es387857/
All Articles