Otro paso en el autoaprendizaje automático.
, Data Science , ? , : , .
Data Science , , , , . , –
.
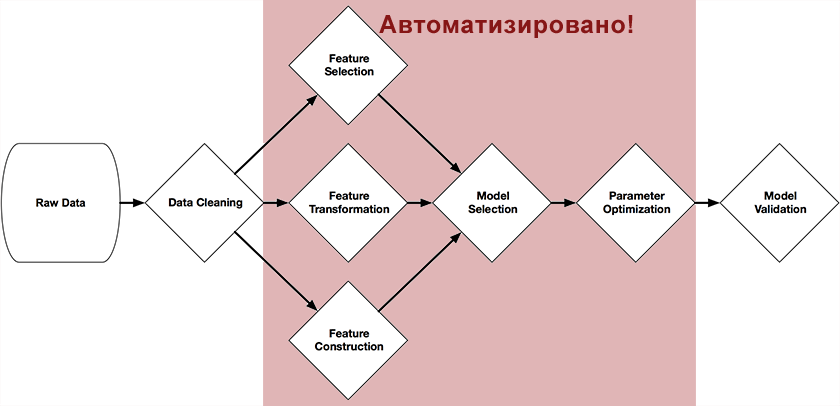
Es la persona la que necesita construir la cadena de aprendizaje y ajustar los parámetros que pueden convertir fácilmente el mejor modelo en absolutamente inútil. La construcción de esta cadena, que convierte los datos iniciales en un modelo predictivo, puede llevar varias semanas, dependiendo de la complejidad de la tarea, y a menudo se realiza simplemente por prueba y error.Esta es una falla grave y, por lo tanto, surgió la idea: ¿puede el aprendizaje automático educarse de la misma manera que una persona? Tal sistema fue creado, y es sorprendente que esta noticia aún no haya llegado a la sociedad.TROT (Herramienta de optimización de tuberías basada en árboles)
Randy Olson, un estudiante graduado en Computational Genetics Lab (Universidad de Pennsylvania), desarrolló una herramienta de optimización de tuberías basada en árboles como parte de su proyecto de graduación .Este sistema se posiciona como un asistente de Data Science. Automatiza la parte más tediosa del aprendizaje automático, estudiando y eligiendo entre las miles de posibles cadenas de construcción exactamente la que mejor se adapta para procesar sus datos.scikit-learn, . , : , , .
–
.
, , .
,
,
« »(Recomiendo para aquellos interesados en este tema, hay una red en forma electrónica).En función de la selección (función Fitness), se utiliza la precisión de la predicción en la muestra de prueba, ya que un objeto de la población son los métodos scikit y sus parámetros.Resultados
El autor tiene un ejemplo simple de cómo usar TPOT para resolver el problema de referencia para la clasificación de dígitos escritos a mano del conjunto MNISTfrom tpot import TPOT
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75)
tpot = TPOT(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print( tpot.score(X_train, y_train, X_test, y_test) )
tpot.export('tpot_exported_pipeline.py')
, TPOT , 98%. , TPOT Random Forest MNIST.
, , random_state – , , 5 SVC KNeighborsClassifier.
,
, 97% 10 .
– , ( ) . Data Scientists ,
(https://github.com/rhiever/tpot)
, , – . – , , , . :
?