¿Tiene AlphaGo una oportunidad en el partido contra Lee Sedol: opiniones y valoraciones de jugadores profesionales en el
El noveno partido de Google Go-Pro y la IA de Google tendrán lugar en marzo
 Ninguna computadora puede vencer a un jugador profesional en el juego de mesa asiático. La cuestión se trata de las características del juego: hay demasiadas posiciones y es difícil describir la intuición humana algorítmicamente. El mundo tuvo opiniones similares hasta el 27 de enero. Hace unos días, Google publicó datos de investigación de su división DeepMind . Habla sobre el sistema AlphaGo, que en octubre del año pasado pudo vencer al segundo jugador profesional Dan Fan en 5 de los cinco juegos.Sin embargo, los jugadores profesionales y conocidos desde el principio tenían preguntas sobre la calidad del juego. Hui es tres veces campeón, pero es un campeón europeo, donde el nivel del juego no es demasiado alto. No solo es la elección del jugador demostrar el poder de AlphaGo lo que genera preguntas, sino también algunos movimientos en los juegos.
Ninguna computadora puede vencer a un jugador profesional en el juego de mesa asiático. La cuestión se trata de las características del juego: hay demasiadas posiciones y es difícil describir la intuición humana algorítmicamente. El mundo tuvo opiniones similares hasta el 27 de enero. Hace unos días, Google publicó datos de investigación de su división DeepMind . Habla sobre el sistema AlphaGo, que en octubre del año pasado pudo vencer al segundo jugador profesional Dan Fan en 5 de los cinco juegos.Sin embargo, los jugadores profesionales y conocidos desde el principio tenían preguntas sobre la calidad del juego. Hui es tres veces campeón, pero es un campeón europeo, donde el nivel del juego no es demasiado alto. No solo es la elección del jugador demostrar el poder de AlphaGo lo que genera preguntas, sino también algunos movimientos en los juegos.Algoritmo
Guo ha sido considerado un juego para entrenar en el que la inteligencia artificial es difícil debido al enorme espacio de búsqueda y la complejidad de la elección de los movimientos. Go pertenece a la clase de juegos con información perfecta, es decir, los jugadores son conscientes de todos los movimientos que otros jugadores han realizado previamente. La solución al problema de encontrar el resultado del juego consiste en calcular la función de valor óptimo en un árbol de búsqueda que contiene aproximadamente b d posibles movimientos. Aquí b es el número de movimientos correctos en cada posición, yd es la duración del juego. Para el ajedrez, estos valores son b ≈ 35 y d ≈ 80, y una búsqueda completa no es posible. Por lo tanto, se evalúan las posiciones de las figuras, y luego la evaluación se tiene en cuenta en la búsqueda. En 1996, por primera vez, una computadora ganó el ajedrez contra un campeón, y desde 2005, ningún campeón ha podido vencer a una computadora.Para ir b ≈ 250, d ≈ 150. Las posibles posiciones de las piedras en un tablero estándar son más que googol (10 100 ) veces más que en el ajedrez. El número de posiciones posibles es mayor que los átomos en el universo. Para complicar la situación, es difícil predecir el valor de los estados debido a la complejidad del juego. Dos jugadores colocan piedras de dos colores en un tablero de cierto tamaño, el campo estándar es de 19 × 19 líneas. Las reglas varían en detalles, pero el objetivo principal del juego es simple: debes cercar un área más grande en el tablero con piedras de tu color que tu oponente.Los programas existentes pueden jugar ir a nivel aficionado. Utilizan la búsqueda en el árbol de Monte Carlo para evaluar el valor de cada estado en el árbol de búsqueda. Los programas también incluyen políticas que predicen los movimientos de jugadores fuertes.Recientemente, las redes neuronales convolucionales profundas han podido lograr buenos resultados en reconocimiento facial y clasificación de imágenes. En Google, AI incluso aprendió a jugar 49 juegos antiguos de Atari por su cuenta . En AlphaGo, redes neuronales similares interpretan la posición de las piedras en el tablero, lo que ayuda a evaluar y seleccionar movimientos. En Google, los investigadores adoptaron el siguiente enfoque: utilizaron redes de valor y redes de políticas. Luego, estas redes neuronales profundas se entrenan tanto en un conjunto de grupos de personas como en un juego contra sus copias. Una búsqueda también es nueva, combinando el método de Monte Carlo con redes de política y valor. Esquema y arquitectura de entrenamiento de redes neuronales.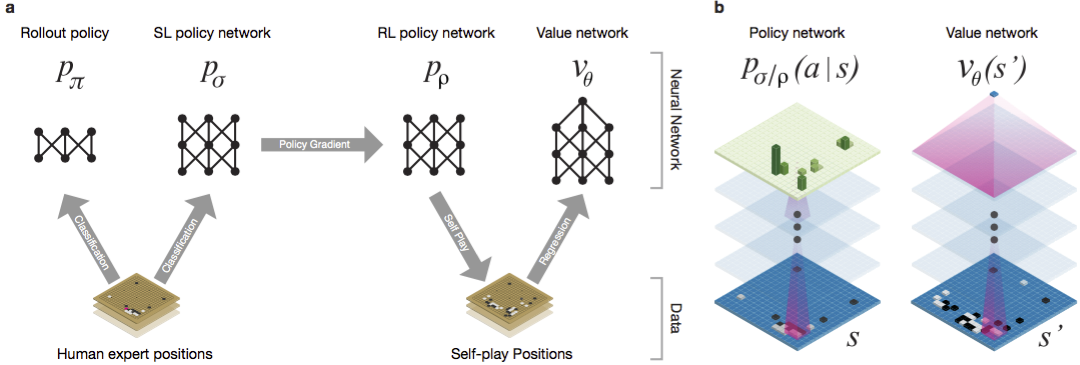 Las redes neuronales fueron entrenadas en varias etapas del aprendizaje automático. Al principio, el entrenamiento controlado de la red de políticas se realizó directamente utilizando los movimientos de jugadores humanos. Otra red política ha sido el aprendizaje reforzado. El segundo jugó con el primero y lo optimizó para que la política cambiara a una victoria, y no solo predicciones de movimientos. Finalmente, se realizó una capacitación, reforzada por una red de valor que predice el ganador de los juegos que juegan las redes políticas. El resultado final es AlphaGo, una combinación del método de Monte Carlo y las redes de política y valor. El resultado de la predicción correcta del próximo movimiento se logró en el 57% de los casos. Antes de AlphaGo, el mejor resultado era del 44% .Se utilizaron 160 mil juegos con 29.4 millones de posiciones del servidor KGS como entrada para el entrenamiento. Se tomaron los partidos de jugadores del sexto al noveno dan. Se asignaron un millón de puestos para las pruebas, y la capacitación misma se realizó para 28,4 millones de puestos. La fortaleza y precisión de las políticas y valores de redes.
Para que los algoritmos funcionen, requieren varios órdenes de magnitud mayor potencia informática que con la búsqueda tradicional. AlphaGo es un programa asincrónico multiproceso que realiza simulación en los núcleos del procesador central y ejecuta redes de políticas y valores en chips de video. La versión final parecía una aplicación de 40 subprocesos que se ejecuta en 48 procesadores (probablemente significaba núcleos separados o incluso hiperprocesadores) y 8 aceleradores gráficos. También se creó una versión distribuida de AlphaGo, que utiliza varias máquinas, 40 flujos de búsqueda, 1202 núcleos y 176 aceleradores de video.
Las redes neuronales fueron entrenadas en varias etapas del aprendizaje automático. Al principio, el entrenamiento controlado de la red de políticas se realizó directamente utilizando los movimientos de jugadores humanos. Otra red política ha sido el aprendizaje reforzado. El segundo jugó con el primero y lo optimizó para que la política cambiara a una victoria, y no solo predicciones de movimientos. Finalmente, se realizó una capacitación, reforzada por una red de valor que predice el ganador de los juegos que juegan las redes políticas. El resultado final es AlphaGo, una combinación del método de Monte Carlo y las redes de política y valor. El resultado de la predicción correcta del próximo movimiento se logró en el 57% de los casos. Antes de AlphaGo, el mejor resultado era del 44% .Se utilizaron 160 mil juegos con 29.4 millones de posiciones del servidor KGS como entrada para el entrenamiento. Se tomaron los partidos de jugadores del sexto al noveno dan. Se asignaron un millón de puestos para las pruebas, y la capacitación misma se realizó para 28,4 millones de puestos. La fortaleza y precisión de las políticas y valores de redes.
Para que los algoritmos funcionen, requieren varios órdenes de magnitud mayor potencia informática que con la búsqueda tradicional. AlphaGo es un programa asincrónico multiproceso que realiza simulación en los núcleos del procesador central y ejecuta redes de políticas y valores en chips de video. La versión final parecía una aplicación de 40 subprocesos que se ejecuta en 48 procesadores (probablemente significaba núcleos separados o incluso hiperprocesadores) y 8 aceleradores gráficos. También se creó una versión distribuida de AlphaGo, que utiliza varias máquinas, 40 flujos de búsqueda, 1202 núcleos y 176 aceleradores de video.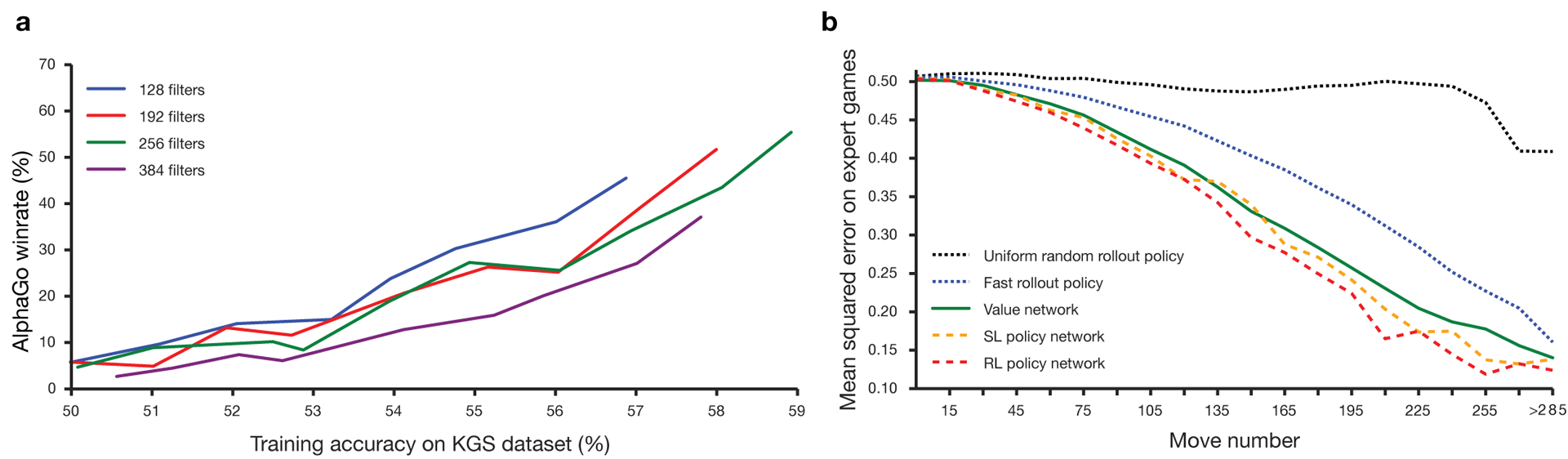 El informe completo de DeepMind se puede encontrar en el documento . Buscar Monte Carlo en AlphaGo.
Para evaluar las habilidades de AlphaGo, se realizaron partidos internos contra otras versiones del programa, así como otros productos similares. Se incluyó una comparación con programas comerciales populares como Crazy Stone y Zen, y los proyectos de código abierto más fuertes Pachi y Fuego. Todos ellos están basados en algoritmos Monte Carlo de alto rendimiento. Pero también AlphaGo en comparación con GnuGo no Monte Carlo. Los programas recibieron 5 segundos por movimiento. Se realizó una comparación tanto del AlphaGo que se ejecuta en una sola máquina como de la versión distribuida del algoritmo.
El informe completo de DeepMind se puede encontrar en el documento . Buscar Monte Carlo en AlphaGo.
Para evaluar las habilidades de AlphaGo, se realizaron partidos internos contra otras versiones del programa, así como otros productos similares. Se incluyó una comparación con programas comerciales populares como Crazy Stone y Zen, y los proyectos de código abierto más fuertes Pachi y Fuego. Todos ellos están basados en algoritmos Monte Carlo de alto rendimiento. Pero también AlphaGo en comparación con GnuGo no Monte Carlo. Los programas recibieron 5 segundos por movimiento. Se realizó una comparación tanto del AlphaGo que se ejecuta en una sola máquina como de la versión distribuida del algoritmo.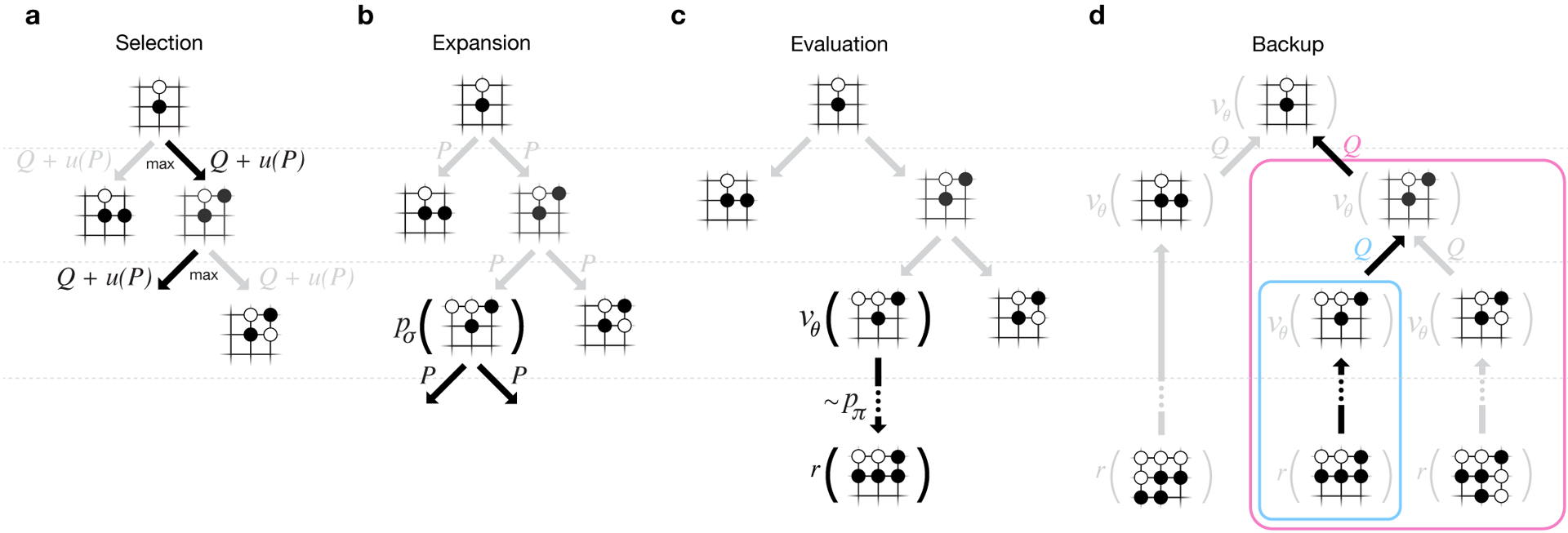 Según los desarrolladores, los resultados mostraron que AlphaGo es mucho más fuerte que cualquier programa anterior. AlphaGo ganó 494 de 495 juegos, que es el 99.8% de los partidos contra otros productos similares. Las reglas de go permiten un hándicap , hándicap: se pueden colocar hasta 9 piedras negras en el campo antes de que se muevan las blancas. Pero incluso con 4 piedras de handicap, la máquina individual AlphaGo ganó el 77%, 86% y 99% del tiempo contra Crazy Stone, Zen y Pachi, respectivamente. La versión distribuida de AlphaGo fue significativamente más fuerte: en el 77% de los juegos, derrotó a la versión para una sola máquina y en el 100% de los juegos, todos los demás programas. AlphaGo vs otros programas.
Según los desarrolladores, los resultados mostraron que AlphaGo es mucho más fuerte que cualquier programa anterior. AlphaGo ganó 494 de 495 juegos, que es el 99.8% de los partidos contra otros productos similares. Las reglas de go permiten un hándicap , hándicap: se pueden colocar hasta 9 piedras negras en el campo antes de que se muevan las blancas. Pero incluso con 4 piedras de handicap, la máquina individual AlphaGo ganó el 77%, 86% y 99% del tiempo contra Crazy Stone, Zen y Pachi, respectivamente. La versión distribuida de AlphaGo fue significativamente más fuerte: en el 77% de los juegos, derrotó a la versión para una sola máquina y en el 100% de los juegos, todos los demás programas. AlphaGo vs otros programas.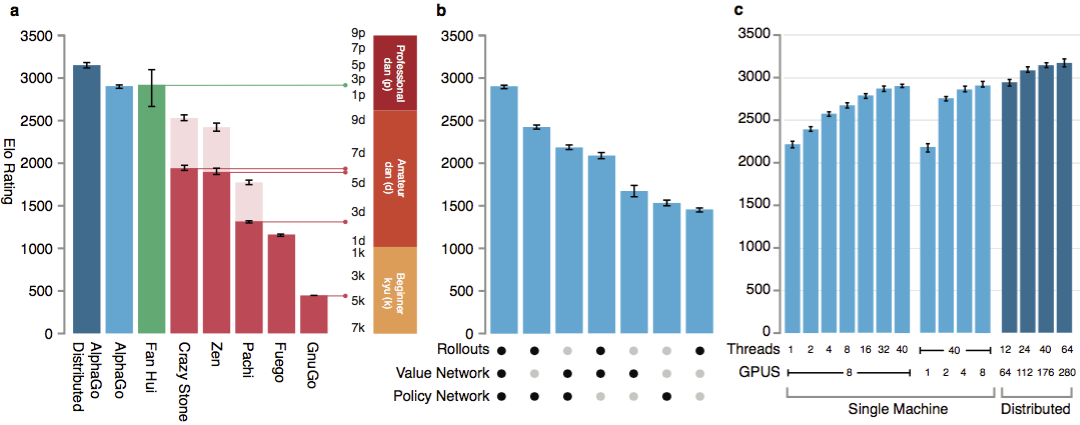 Finalmente, el producto creado se comparó con una persona. El jugador profesional 2 dan luchó contra la versión distribuida de AlphaGo, Fan Hui, el ganador del Campeonato Europeo de Go en 2013, 2014 y 2015. Los juegos se llevaron a cabo con la participación de un juez de la Federación Británica de go y el editor de la revista Nature. Se celebraron 5 juegos en el período del 5 al 9 de octubre de 2015. Todos ganaron el algoritmo de desarrollo Google DeepMind. Fueron estos juegos los que llevaron a la afirmación de que la computadora fue la primera en vencer a un jugador profesional. Además de 5 partidos oficiales, se llevaron a cabo 5 partidos no oficiales, que no contaron. Fan ganó dos de ellos.Disponible grabación pasa cinco juegos , la visualización en un widget web y vídeos en YouTube .
Finalmente, el producto creado se comparó con una persona. El jugador profesional 2 dan luchó contra la versión distribuida de AlphaGo, Fan Hui, el ganador del Campeonato Europeo de Go en 2013, 2014 y 2015. Los juegos se llevaron a cabo con la participación de un juez de la Federación Británica de go y el editor de la revista Nature. Se celebraron 5 juegos en el período del 5 al 9 de octubre de 2015. Todos ganaron el algoritmo de desarrollo Google DeepMind. Fueron estos juegos los que llevaron a la afirmación de que la computadora fue la primera en vencer a un jugador profesional. Además de 5 partidos oficiales, se llevaron a cabo 5 partidos no oficiales, que no contaron. Fan ganó dos de ellos.Disponible grabación pasa cinco juegos , la visualización en un widget web y vídeos en YouTube .Críticas de jugadores profesionales
La elección de un jugador profesional y el juego débil del campeón están siendo cuestionados. Las reglas elegidas tampoco son claras: una hora por juego en lugar de varias horas de juegos serios. Sin embargo, el formato fue elegido por el propio Hui. En marzo, AlphaGo jugará contra Lee Sedola. ¿Puede el algoritmo vencer al profesional coreano del noveno dan, considerado uno de los mejores jugadores del mundo? Está en juego un millón de dólares. Si una persona gana, Li Sedol lo recibirá; si el algoritmo gana, irá a la caridad.Los investigadores dicen que durante la batalla de octubre con los humanos, el sistema AlphaGo consideró miles de veces menos posiciones que Deep Blue durante un partido histórico con Kasparov. En cambio, el programa utilizó una red de políticas para elecciones más inteligentes y una red de valores para medir posiciones con mayor precisión. Quizás este enfoque esté más cerca de cómo juegan las personas, dicen los investigadores. Además, el sistema de clasificación Deep Blue se programó manualmente, mientras que las redes neuronales AlphaGo se entrenaron directamente desde los juegos utilizando algoritmos universales de aprendizaje supervisado y aprendizaje por refuerzo. Lee Sedoll intentará su mano contra AlphaGo en marzo. Los jugadores profesionales tienen diferentes puntos de vista. A algunos les parece que Google eligió específicamente un jugador no muy fuerte, alguien está seguro de que Sedol perderá este marzo.Uno de los jugadores profesionales más fuertes de habla inglesa, Kim Mengwang (noveno dan) cree que Fan Hui no jugó con toda su fuerza. En el minuto 51 del video, da un ejemplo concreto de la segunda entrega. Puede que Fan haya jugado tanto con uno más débil para probar el poder de la computadora, dice Kim. Mengwan admitió que AlphaGo es un programa sorprendentemente poderoso, pero es poco probable que derrote a Lee Sedol.El árbitro del partido, Toby Manning, le contó al British Go Journal sobre el partido. Analizó los cinco juegos y destacó algunos puntos. AlphaGo cometió errores en el segundo, tercer y cuarto juego, pero Fan no los usó. El tres veces campeón europeo respondió con el suyo. El artículo en la revista termina con una evaluación general positiva de AlphaGo: el programa es sólido, pero no está claro cuánto.Además, al preparar el material, recibí comentarios de profesionales rusos y amantes. Alexander Dinerstein (Kazan), tercer dan (profesional), siete veces campeón de Europa:
Los jugadores profesionales tienen diferentes puntos de vista. A algunos les parece que Google eligió específicamente un jugador no muy fuerte, alguien está seguro de que Sedol perderá este marzo.Uno de los jugadores profesionales más fuertes de habla inglesa, Kim Mengwang (noveno dan) cree que Fan Hui no jugó con toda su fuerza. En el minuto 51 del video, da un ejemplo concreto de la segunda entrega. Puede que Fan haya jugado tanto con uno más débil para probar el poder de la computadora, dice Kim. Mengwan admitió que AlphaGo es un programa sorprendentemente poderoso, pero es poco probable que derrote a Lee Sedol.El árbitro del partido, Toby Manning, le contó al British Go Journal sobre el partido. Analizó los cinco juegos y destacó algunos puntos. AlphaGo cometió errores en el segundo, tercer y cuarto juego, pero Fan no los usó. El tres veces campeón europeo respondió con el suyo. El artículo en la revista termina con una evaluación general positiva de AlphaGo: el programa es sólido, pero no está claro cuánto.Además, al preparar el material, recibí comentarios de profesionales rusos y amantes. Alexander Dinerstein (Kazan), tercer dan (profesional), siete veces campeón de Europa:Deep Blue . , , , . Google . .
4-4 ( -, starpoint ). . : 3-3, 3-4, 5-3, , , , . , . .
, , . . – , . , - . . 20-30 , , , , . , . , . .
, - 2016 (EGC), en cuyo marco siempre se lleva a cabo un torneo de programa informático. La Federación Rusa de Go invitó a todos los programas más fuertes a participar en el torneo. Si aceptan la invitación, tal vez sea en este torneo por primera vez que los programas de Google y Facebook jueguen entre ellos. Este último, a diferencia de su competidor, sigue un camino honesto. El bot DarkForest juega miles de juegos en el servidor KGS . La versión más fuerte se acerca al sexto dan en el servidor. Este es un muy buen nivel. Fan Hui y jugadores de su nivel: se trata del octavo dan en el servidor (de nueve posibles). La diferencia es sobre dos discapacidades de piedra. Con tal diferencia, un programa a veces realmente puede vencer a una persona. Si en igualdad de condiciones, entonces aproximadamente en un lote de diez.
Maxim Podolyak, (San Petersburgo), Vicepresidente de la Federación Rusa de Go:, , , , , , , , . , Google : , . , . : , , , . , : , . Google . , . ? ?
Alexander Krainov (Moscú), amante del juego:Debido a mi actividad profesional, conozco muy bien la situación "desde el otro lado".
En 2012, hubo un salto cuántico en el aprendizaje automático en general. La cantidad de datos para el entrenamiento, el nivel de algoritmos y el poder para el entrenamiento han alcanzado un nivel tal que las redes neuronales artificiales (desarrolladas como un principio durante mucho tiempo) comenzaron a dar resultados fantásticos.
La diferencia fundamental entre el entrenamiento en redes neuronales es que no es necesario que se les den factores de entrada (en el caso de ir, explique, por ejemplo, qué formas son buenas). En el límite, incluso las reglas no se les pueden explicar. Lo principal es dar una gran cantidad de ejemplos positivos (movimientos del lado ganador) y negativos (movimientos del lado perdedor). Y la red se aprenderá sola.
, , . . : , , ( ) , .
, .
, , , . . . . , , .
Lo que dice el propio Lee Sedol
Los jugadores profesionales no compiten por el título mundial, sino por títulos. El reconocimiento y el estado del maestro está determinado por la cantidad de títulos que pudo obtener durante el año. Lee Sedol es uno de los cinco jugadores de go más fuertes del mundo, y en marzo de este año tendrá que luchar con el sistema AlphaGo.El propio campeón coreano predice que ganará con un puntaje de 4-1 o 5-0. Pero después de 2-3 años, Google querrá vengarse, y luego el juego con la versión actualizada de AlphaGo será más interesante, dice Lee.
La tarea de crear tal algoritmo plantea nuevas preguntas sobre qué son el aprendizaje y el pensamiento. Como recuerda M. Emelyanov, el tercer nivel de habilidad (pin) desde la parte superior de acuerdo con la antigua clasificación china se llama "claridad completa". Tal nivel del juego sugiere que las decisiones se toman intuitivamente, con pocas o ninguna opción. Uno de los maestros más fuertes del siglo XX, Guo Seigen, dijo que le parecía que habría ganado contra el "dios del dios" al tomar dos o tres piedras para discapacitados. Seigan creía que casi había llegado al límite de entender el juego. ¿Puede una red neuronal lograr esto? ¿Quizás la intuición humana es un algoritmo establecido por la naturaleza?El autor agradece a Alexander Dinerstein y al público go_secrets por sus comentarios y ayuda en la publicación.Source: https://habr.com/ru/post/es389825/
All Articles