 Dio la casualidad de que el idioma principal para trabajar con microcontroladores es C. Muchos proyectos grandes están escritos en él. Pero la vida no se detiene. Las herramientas de desarrollo modernas han podido usar C ++ durante mucho tiempo al desarrollar software para sistemas integrados. Sin embargo, este enfoque sigue siendo raro. No hace mucho tiempo, intenté usar C ++ cuando trabajaba en otro proyecto. Hablaré sobre esta experiencia en este artículo.
Dio la casualidad de que el idioma principal para trabajar con microcontroladores es C. Muchos proyectos grandes están escritos en él. Pero la vida no se detiene. Las herramientas de desarrollo modernas han podido usar C ++ durante mucho tiempo al desarrollar software para sistemas integrados. Sin embargo, este enfoque sigue siendo raro. No hace mucho tiempo, intenté usar C ++ cuando trabajaba en otro proyecto. Hablaré sobre esta experiencia en este artículo.Entrada
La mayor parte de mi trabajo con microcontroladores está relacionado con C. Primero, fueron requisitos del cliente, y luego se convirtió en un hábito. Al mismo tiempo, cuando se trataba de aplicaciones para Windows, C ++ se usaba allí primero, y luego C # en general.No ha habido preguntas sobre C o C ++ durante mucho tiempo. Incluso el lanzamiento de la próxima versión del MDK de Keil con soporte C ++ para ARM no me molestó mucho. Si observa los proyectos de demostración de Keil, todo está escrito allí en C. Al mismo tiempo, C ++ se mueve a una carpeta separada junto con el proyecto Blinky. CMSIS y LPCOpen también están escritos en C. Y si "todos" usan C, entonces hay algunas razones.Pero mucho ha cambiado .Net Micro Framework. Si alguien no lo sabe, entonces esta es una implementación .Net que le permite escribir aplicaciones para microcontroladores en C # en Visual Studio. Puedes aprender más sobre él enestos articulos.Entonces, .Net Micro Framework está escrito usando C ++. Impresionado por esto, decidí intentar escribir otro proyecto en C ++. Debo decir de inmediato que no encontré ningún argumento definitivo a favor de C ++, pero hay algunos puntos interesantes y útiles en este enfoque.¿Cuál es la diferencia entre los proyectos C y C ++?
Una de las principales diferencias entre C y C ++ es que el segundo es un lenguaje orientado a objetos. La encapsulación, el polimorfismo y la herencia bien conocidos son comunes aquí. C es un lenguaje de procedimiento. Solo hay funciones y procedimientos, y para la agrupación lógica del código, se utilizan módulos (un par de .h + .c). Pero si observa de cerca cómo se usa C en los microcontroladores, puede ver el enfoque orientado a objetos habitual.Veamos el código para trabajar con LED del ejemplo de Keil para MCB1000 ( Keil_v5 \ ARM \ Boards \ Keil \ MCB1000 \ MCB11C14 \ CAN_Demo ):LED.h:#ifndef __LED_H
#define __LED_H
#define LED_NUM 8
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:#include "LPC11xx.h"
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6);
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
Si observa de cerca, puede hacer una analogía con OOP. El LED es un objeto que tiene una constante pública, un constructor, 3 métodos públicos y un campo privado:class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED();
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
A pesar de que el código está escrito en C, utiliza el paradigma de la programación de objetos. Un archivo .C es un objeto que le permite encapsular dentro de los mecanismos de implementación de los métodos públicos descritos en el archivo .h. Pero aquí no hay herencia y, por lo tanto, también polimorfismo.La mayor parte del código en los proyectos que conocí está escrito en el mismo estilo. Y si se utiliza el enfoque OOP, ¿por qué no utilizar un lenguaje que lo admita por completo? Al mismo tiempo, cuando se cambia a C ++, en general, solo cambiará la sintaxis, pero no los principios de desarrollo.Considere otro ejemplo. Supongamos que tenemos un dispositivo que utiliza un sensor de temperatura conectado a través de I2C. Pero salió una nueva revisión del dispositivo y el mismo sensor ahora está conectado al SPI. Que hacer Es necesario admitir la primera y la segunda revisión del dispositivo, lo que significa que el código debe tener en cuenta estos cambios de manera flexible. En C, puede usar #definir predefiniciones para evitar escribir dos archivos casi idénticos. Por ejemplo#ifdef REV1
#include “i2c.h”
#endif
#ifdef REV2
#include “spi.h”
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
Y así sucesivamente.En C ++, puede resolver este problema un poco más elegante. Hacer interfazclass ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
y hacer 2 implementacionesclass Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
Y luego use esta o aquella implementación según la revisión:class TemperatureGetter
{
private:
ITemperature* _temperature;
pubic:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
Parece que la diferencia no es muy grande entre el código C y C ++. La opción orientada a objetos se ve aún más engorrosa. Pero le permite tomar una decisión más flexible.Cuando se usa C, se pueden distinguir dos soluciones principales:- Use #define como se muestra arriba. Esta opción no es muy buena porque "erosiona" la responsabilidad del módulo. Resulta que él es responsable de varias revisiones del proyecto. Cuando hay muchos de estos archivos, se hace bastante difícil mantenerlos.
- 2 , C++. “” , . , #ifdef. , , . , . , , .
El uso del polimorfismo da un resultado más hermoso. Por un lado, cada clase resuelve un problema atómico claro, por otro lado, el código no está lleno de basura y es fácil de leer.La "ramificación" del código en la revisión todavía tendrá que hacerse en el primer y segundo caso, pero el uso de polimorfismo hace que sea más fácil transferir el lugar de ramificación entre las capas del programa, sin saturar el código con #ifdef innecesarios.El uso del polimorfismo hace que sea más fácil tomar una decisión aún más interesante.Digamos que se lanza una nueva revisión, en la que se instalan ambos sensores de temperatura.El mismo código con cambios mínimos le permite elegir su implementación de SPI e I2C en tiempo real, simplemente usando el método Init (y temperatura).El ejemplo está muy simplificado, pero en un proyecto real utilicé el mismo enfoque para implementar el mismo protocolo sobre dos interfaces de transferencia de datos físicos diferentes. Esto facilitó la elección de la interfaz en la configuración del dispositivo.Sin embargo, con todo lo anterior, la diferencia entre usar C y C ++ sigue siendo no muy grande. Las ventajas de C ++ relacionadas con la POO no son tan obvias y pertenecen a la categoría de "aficionado". Pero el uso de C ++ en microcontroladores tiene problemas bastante serios.¿Por qué es peligroso usar C ++?
La segunda diferencia importante entre C y C ++ es el uso de memoria. El lenguaje C es mayormente estático. Todas las funciones y procedimientos tienen direcciones fijas, y el trabajo con un grupo se lleva a cabo solo cuando es necesario. C ++ es un lenguaje más dinámico. Por lo general, su uso implica un trabajo activo con asignación y liberación de memoria. Esto es lo que C ++ es peligroso. Los microcontroladores tienen muy pocos recursos, por lo que el control sobre ellos es importante. El uso incontrolado de RAM está plagado de daños en los datos almacenados allí y de tales "milagros" en el trabajo del programa, que a nadie le parecerá. Muchos desarrolladores han encontrado tales problemas.Si observa detenidamente los ejemplos anteriores, puede observarse que las clases no tienen constructores ni destructores. Esto se debe a que nunca se crean dinámicamente.Cuando se usa memoria dinámica (y cuando se usa new), siempre se llama a la función malloc, que asigna el número requerido de bytes del montón. Incluso si lo piensa (aunque es muy difícil) y controla el uso de la memoria, puede encontrar el problema de la fragmentación.Un grupo se puede representar como una matriz. Por ejemplo, le asignamos 20 bytes: cada vez que se asigna memoria, se escanea toda la memoria (de izquierda a derecha o de derecha a izquierda; esto no es tan importante) para detectar la presencia de un número determinado de bytes desocupados. Además, todos estos bytes deberían estar ubicados cerca:
asignamos 20 bytes: cada vez que se asigna memoria, se escanea toda la memoria (de izquierda a derecha o de derecha a izquierda; esto no es tan importante) para detectar la presencia de un número determinado de bytes desocupados. Además, todos estos bytes deberían estar ubicados cerca: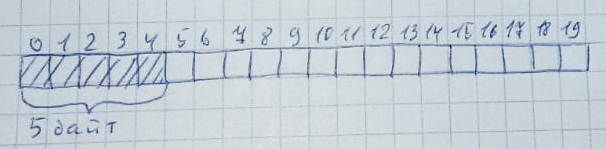 cuando la memoria ya no se necesita, vuelve a su estado original:Muy fácilmente esto puede suceder cuando hay suficientes bytes libres, pero no están organizados en una fila. Deje que se asignen 10 zonas de 2 bytes cada una:
cuando la memoria ya no se necesita, vuelve a su estado original:Muy fácilmente esto puede suceder cuando hay suficientes bytes libres, pero no están organizados en una fila. Deje que se asignen 10 zonas de 2 bytes cada una: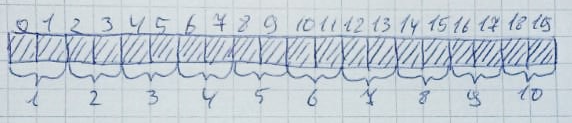 Luego, se liberarán 2,4,6,8,10 zonas:
Luego, se liberarán 2,4,6,8,10 zonas: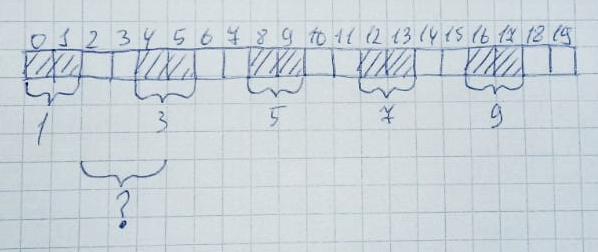 Formalmente, la mitad del montón completo (10 bytes) permanece libre. Sin embargo, la asignación de un área de memoria de 3 bytes seguirá fallando, ya que la matriz no tiene 3 celdas libres en una fila. Esto se llama fragmentación de la memoria.Y lidiar con esto en sistemas sin virtualización de memoria es bastante difícil. Especialmente en grandes proyectos.Esta situación se puede emular fácilmente. Lo hice en Keil mVision en el microcontrolador LPC11C24.Establezca el tamaño de almacenamiento dinámico en 256 bytes:
Formalmente, la mitad del montón completo (10 bytes) permanece libre. Sin embargo, la asignación de un área de memoria de 3 bytes seguirá fallando, ya que la matriz no tiene 3 celdas libres en una fila. Esto se llama fragmentación de la memoria.Y lidiar con esto en sistemas sin virtualización de memoria es bastante difícil. Especialmente en grandes proyectos.Esta situación se puede emular fácilmente. Lo hice en Keil mVision en el microcontrolador LPC11C24.Establezca el tamaño de almacenamiento dinámico en 256 bytes: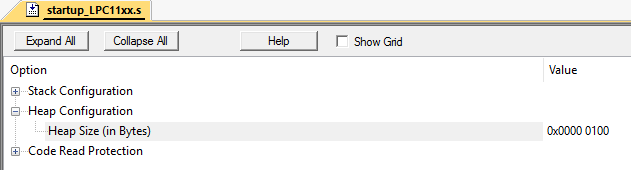 supongamos que tenemos 2 clases:
supongamos que tenemos 2 clases:#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
Como puede ver, la clase de barra ocupará más memoria que foo.Se colocan 14 instancias de la clase de barra en el montón y la instancia de la clase foo ya no se ajusta:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
Si crea solo 7 instancias de barra, entonces foo también se creará normalmente:int main(void)
{
foo *f;
bar *b[14];
b[1] = new bar();
b[3] = new bar();
b[5] = new bar();
b[7] = new bar();
b[9] = new bar();
b[11] = new bar();
b[13] = new bar();
f = new foo();
}
Sin embargo, si primero crea 14 instancias de barra, luego elimina 0,2,4,6,8,10 y 12 instancias, entonces foo no podrá asignar memoria debido a la fragmentación del montón:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
Resulta que no puedes usar C ++ completamente, y este es un significativo menos. Desde un punto de vista arquitectónico, C ++, aunque superior a C, es insignificante. Como resultado, la transición a C ++ no trae beneficios significativos (aunque tampoco hay grandes puntos negativos). Por lo tanto, debido a una pequeña diferencia, la elección del idioma seguirá siendo simplemente la preferencia personal del desarrollador.Pero para mí, encontré un punto positivo significativo al usar C ++. El hecho es que con el enfoque correcto de C ++, el código para microcontroladores se puede cubrir fácilmente con pruebas unitarias en Visual Studio.Una gran ventaja de C ++ es la capacidad de usar Visual Studio.
Para mí personalmente, el tema de las pruebas de código para microcontroladores siempre ha sido bastante complejo. Naturalmente, el código se verificó de todas las maneras posibles, pero la creación de un sistema de prueba automático completo siempre requirió enormes costos, ya que era necesario ensamblar un soporte de hardware y escribir un firmware especial para él. Especialmente cuando se trata de un sistema IoT distribuido que consta de cientos de dispositivos.Cuando comencé a escribir un proyecto en C ++, inmediatamente quise intentar poner el código en Visual Studio y usar Keil mVision solo para la depuración. En primer lugar, Visual Studio tiene un editor de código muy potente y conveniente, y en segundo lugar, Keil mVision no tiene una integración conveniente con los sistemas de control de versiones, y en Visual Studio todo se resuelve automáticamente. En tercer lugar, tenía la esperanza de poder cubrir al menos parte del código con pruebas unitarias, que también son compatibles con Visual Studio. Y en cuarto lugar, esta es la aparición de Resharper C ++, una extensión de Visual Studio para trabajar con código C ++, gracias a la cual puede evitar muchos posibles errores de antemano y controlar el estilo del código.Crear un proyecto en Visual Studio y conectarlo al sistema de control de versiones no causó ningún problema. Pero con las pruebas unitarias tuvieron que retocar.Las clases extraídas del hardware (por ejemplo, analizadores de protocolos) fueron fáciles de probar. ¡Pero quería más! En mis proyectos para trabajar con periféricos, uso archivos de encabezado de Keil. Por ejemplo, para LPC11C24 es LPC11xx.h. Estos archivos describen todos los registros necesarios de acuerdo con el estándar CMSIS. La definición directa de un registro específico se realiza a través de #define:#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
Resultó que si redefine correctamente los registros y crea un par de stubs, entonces el código que usa periféricos puede compilarse muy bien en VisualStudio. No solo eso, si crea una clase estática y especifica sus campos como direcciones de registro, obtendrá un emulador de microcontrolador completo que le permite probar completamente incluso el trabajo con periféricos:#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
Y luego haz esto:#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
De esta manera, puede compilar y probar todo el código del proyecto para microcontroladores en VisualStudio con cambios mínimos.En el proceso de desarrollo de un proyecto en C ++, escribí más de 300 pruebas que cubren aspectos puramente de hardware y código abstraído del hardware. Al mismo tiempo, se encontraron por adelantado aproximadamente 20 errores bastante serios que, debido al tamaño del proyecto, no serían fáciles de detectar sin una prueba automática.Conclusiones
Usar o no usar C ++ cuando se trabaja con microcontroladores es una pregunta bastante complicada. Mostré anteriormente que, por un lado, las ventajas arquitectónicas de una OOP completa no son tan grandes, y la incapacidad de trabajar completamente con un grupo es un problema bastante grande. Dados estos aspectos, no existe una gran diferencia entre C y C ++ para trabajar con microcontroladores, la elección entre ellos puede estar justificada por las preferencias personales del desarrollador.Sin embargo, logré encontrar un gran punto positivo al usar C ++ al trabajar con Visaul Studio. Esto le permite aumentar significativamente la confiabilidad del desarrollo debido al trabajo completo con los sistemas de control de versiones, el uso de pruebas unitarias completas (incluidas las pruebas para trabajar con periféricos) y otras ventajas de Visual Studio.Espero que mi experiencia sea útil y ayude a alguien a aumentar la efectividad de su trabajo.Actualización :En los comentarios sobre la versión en inglés de este artículo se dieron enlaces útiles sobre este tema: