Cómo se creó el centro de datos estatal regional
 "No es un lugar que pinta a una persona, sino a una persona: un lugar"Todos vemos regularmente revisiones de varios tipos de Centros de Procesamiento de Datos (DPC): grandes, pequeños, submarinos, árticos, innovadores, productivos, etc. Sin embargo, prácticamente no hay revisiones de esos héroes invisibles, que trabajan para nuestro bien en las mazmorras estatales, y aún más en las regiones. Por lo tanto, quiero compartir mi propia experiencia en la creación de un centro de datos en el Territorio de Stavropol.
"No es un lugar que pinta a una persona, sino a una persona: un lugar"Todos vemos regularmente revisiones de varios tipos de Centros de Procesamiento de Datos (DPC): grandes, pequeños, submarinos, árticos, innovadores, productivos, etc. Sin embargo, prácticamente no hay revisiones de esos héroes invisibles, que trabajan para nuestro bien en las mazmorras estatales, y aún más en las regiones. Por lo tanto, quiero compartir mi propia experiencia en la creación de un centro de datos en el Territorio de Stavropol.Conocido
Era un cálido día de verano, como recuerdo ahora: 18 de junio de 2012. Ese día, al entrar en las paredes de nuestro futuro centro de datos, vi exactamente esta imagen, que, francamente, me dejó conmocionado. Conozca GKU SK "Centro Regional de Tecnologías de la Información" en los albores de su existencia. Todas las imágenes son clicables. Parecía el único rack dentro de nuestro futuro centro de datos en junio de 2012.
Era una organización bastante joven. Su tarea principal en el momento del comienzo de mi actividad fue el apoyo a la gestión electrónica de documentos de las autoridades públicas (OGV). Mi objetivo era crear un centro de datos y una organización que lo atendiera. Todos los sistemas de información de estado existentes deberían haberse trasladado al centro de datos, así como todos los recién creados. En ese momento, hubo un rápido crecimiento de los servicios públicos electrónicos y la automatización general de las autoridades públicas.En ese momento, no había una comprensión particular de lo que era el gobierno electrónico. Lo principal era entender que "no es el lugar el que colorea a la persona, sino la persona, el lugar". Tenía un equipo pequeño, compuesto por mí, pero esto fue suficiente para comenzar, especialmente porque la automatización de los procesos de rutina evita la hinchazón innecesaria del personal. Y así es como se veía el centro de datos antes de mi partida, julio de 2014.
Mi objetivo era crear un centro de datos y una organización que lo atendiera. Todos los sistemas de información de estado existentes deberían haberse trasladado al centro de datos, así como todos los recién creados. En ese momento, hubo un rápido crecimiento de los servicios públicos electrónicos y la automatización general de las autoridades públicas.En ese momento, no había una comprensión particular de lo que era el gobierno electrónico. Lo principal era entender que "no es el lugar el que colorea a la persona, sino la persona, el lugar". Tenía un equipo pequeño, compuesto por mí, pero esto fue suficiente para comenzar, especialmente porque la automatización de los procesos de rutina evita la hinchazón innecesaria del personal. Y así es como se veía el centro de datos antes de mi partida, julio de 2014. Antes de unirme a esta organización, trabajé como especialista líder en el departamento de soporte de uno de los principales bancos. Y esta experiencia fue muy útil para la implementación en el OGV . En general, me gustó mucho el sector bancario desde el punto de vista de TI, pero esta es una historia diferente. Aquí, tuve que cumplir en cierta medida las funciones del "cardenal gris": el ingeniero jefe que estaba ausente en el personal.El centro de datos que creo no solo debe ser confiable, sino también desastroso, productivo y económico. Me parece que por eso me invitaron a trabajar aquí, porque primero tenía que lograr el uso efectivo de lo que ya está allí. Y los integradores solo tenían una sugerencia: si me das más dinero ... Incluyendo esta es la razón por la que no recurrí a los servicios de integradores, etc., contratistas.Dado que todos los recursos realmente se trasladaron a nuestra "nube", tuvimos que introducir el concepto de "nube privada pública", debido al hecho de que el aparato conceptual existente, que consiste en "nubes" "públicas" y "privadas", no satisfizo completamente la lógica de proporcionar recursos En el exterior era una "nube privada", desde el interior era una "nube pública", pero solo para la UGA. En este sentido, hubo algunas características de las licencias de software.Me las arreglé para decidir sobre algunos momentos conceptuales antes de llegar a la organización, tuvieron que darse por sentados. El proyecto se desarrolló en estrecha colaboración con IBM, Microsoft, Cisco. ¿Por qué exactamente estos vendedores? Para mí, así es como sucedió históricamente. ¿Me arrepiento? ¡Para nada! ¿Se podrían usar otros proveedores? Por supuesto, por ejemplo, DELL, HP o cualquier otro, así como sus combinaciones arbitrarias.Como se compró una plataforma de virtualización - VMWare, en ese momento 5 versiones. Aquí, creo, todos estarán de acuerdo en que la elección es prácticamente indiscutible, porque otros no proporcionaron capacidades similares a Fault Tolerance.Durante la auditoría inicial de la capacidad disponible en los estantes de la ciudad, encontré un par de chasis IBM BladeCenter: E y H. El chasis estaba equipado con cuchillas HS22, que estaban lejos de ser lo peor, un medio duro en ese momento. La condición, por supuesto, era algo deplorable; los indicadores de error de grabación eran especialmente molestos. Vista de uno de los bastidores disponibles en junio de 2012. Preste atención a la instalación de equipos "a través de la caja", especialmente equipos Cisco.
Antes de unirme a esta organización, trabajé como especialista líder en el departamento de soporte de uno de los principales bancos. Y esta experiencia fue muy útil para la implementación en el OGV . En general, me gustó mucho el sector bancario desde el punto de vista de TI, pero esta es una historia diferente. Aquí, tuve que cumplir en cierta medida las funciones del "cardenal gris": el ingeniero jefe que estaba ausente en el personal.El centro de datos que creo no solo debe ser confiable, sino también desastroso, productivo y económico. Me parece que por eso me invitaron a trabajar aquí, porque primero tenía que lograr el uso efectivo de lo que ya está allí. Y los integradores solo tenían una sugerencia: si me das más dinero ... Incluyendo esta es la razón por la que no recurrí a los servicios de integradores, etc., contratistas.Dado que todos los recursos realmente se trasladaron a nuestra "nube", tuvimos que introducir el concepto de "nube privada pública", debido al hecho de que el aparato conceptual existente, que consiste en "nubes" "públicas" y "privadas", no satisfizo completamente la lógica de proporcionar recursos En el exterior era una "nube privada", desde el interior era una "nube pública", pero solo para la UGA. En este sentido, hubo algunas características de las licencias de software.Me las arreglé para decidir sobre algunos momentos conceptuales antes de llegar a la organización, tuvieron que darse por sentados. El proyecto se desarrolló en estrecha colaboración con IBM, Microsoft, Cisco. ¿Por qué exactamente estos vendedores? Para mí, así es como sucedió históricamente. ¿Me arrepiento? ¡Para nada! ¿Se podrían usar otros proveedores? Por supuesto, por ejemplo, DELL, HP o cualquier otro, así como sus combinaciones arbitrarias.Como se compró una plataforma de virtualización - VMWare, en ese momento 5 versiones. Aquí, creo, todos estarán de acuerdo en que la elección es prácticamente indiscutible, porque otros no proporcionaron capacidades similares a Fault Tolerance.Durante la auditoría inicial de la capacidad disponible en los estantes de la ciudad, encontré un par de chasis IBM BladeCenter: E y H. El chasis estaba equipado con cuchillas HS22, que estaban lejos de ser lo peor, un medio duro en ese momento. La condición, por supuesto, era algo deplorable; los indicadores de error de grabación eran especialmente molestos. Vista de uno de los bastidores disponibles en junio de 2012. Preste atención a la instalación de equipos "a través de la caja", especialmente equipos Cisco. Como sistema de almacenamiento, se instaló un estante DS3512, conectado ópticamente, con unidades de 2TB instaladas, en un sitio. En otro sitio, se instaló el estante DS3512 y DS3524.En el sitio de copia de seguridad, se asignó el espacio libre para que VMWare no se iniciara sin intervención manual: detectó otras copias instaladas y se detuvo, solo comenzando con la clave correspondiente. La distribución en sí fue de acuerdo con el principio: cada máquina virtual tiene su propio LUN. Cuando era necesario asignar espacio adicional a la máquina virtual, pero en el LUN existente no era ... Lossitios estaban conectados entre sí por una red de datos delgada con un ancho de 1 Gbit / s. No había una red dedicada para el mismo tráfico de virtualización y servicio.Después de una breve revisión y auditoría de la infraestructura de TI (y fue breve, ya que prácticamente no había infraestructura), se concluyó que tengo un ejemplo clásico de cómo hacerlo. No había esquemas, ni documentación adjunta, incluso las contraseñas de administrador estaban lejos de ser conocidas, tuvieron que restablecerse y restaurarse.Resueltamente me puse a trabajar.
Como sistema de almacenamiento, se instaló un estante DS3512, conectado ópticamente, con unidades de 2TB instaladas, en un sitio. En otro sitio, se instaló el estante DS3512 y DS3524.En el sitio de copia de seguridad, se asignó el espacio libre para que VMWare no se iniciara sin intervención manual: detectó otras copias instaladas y se detuvo, solo comenzando con la clave correspondiente. La distribución en sí fue de acuerdo con el principio: cada máquina virtual tiene su propio LUN. Cuando era necesario asignar espacio adicional a la máquina virtual, pero en el LUN existente no era ... Lossitios estaban conectados entre sí por una red de datos delgada con un ancho de 1 Gbit / s. No había una red dedicada para el mismo tráfico de virtualización y servicio.Después de una breve revisión y auditoría de la infraestructura de TI (y fue breve, ya que prácticamente no había infraestructura), se concluyó que tengo un ejemplo clásico de cómo hacerlo. No había esquemas, ni documentación adjunta, incluso las contraseñas de administrador estaban lejos de ser conocidas, tuvieron que restablecerse y restaurarse.Resueltamente me puse a trabajar.Inicio del viaje
En una organización tan seria en el futuro, en el momento de mi llegada de la infraestructura de TI, no había absolutamente nada: un interruptor inteligente solitario, una red punto a punto, recursos compartidos en cada lugar de trabajo ... En general, todo es exactamente como te imaginas la situación en la región.En consecuencia, la infraestructura empresarial se creó rápidamente al principio. Por lo que se ordenó todo lo que estaba disponible en ese momento. Armado con un probador de red, encontré y firmé todos los cables. Porque en el momento del cableado, no había un plan para trabajos: en algún lugar, en lugar de teléfonos, había PC, en algún lugar allí no había suficientes cables y muchos otros "encantos" estándar.Desafortunadamente, al diseñar la sala de servidores para el futuro centro de datos, nadie hizo un piso elevado o una bandeja de alambre debajo del techo. Naturalmente, ya no había dinero para ninguno, así que tuve que traer belleza por mi cuenta.Como nadie me permitió simplemente acortar los cables en ese momento: "de repente tienes que mover el estante a la esquina más alejada de la habitación, ¿entonces qué?" - Tuve que hacer la cruz número 110 debajo del techo, desde donde bajar los cables hasta el estante. De modo que, en caso de movimiento del bastidor, se pueden quitar los cables cortos de la cruz, instalando allí cables más largos. Vista del panel cruzado 110 de la pared durante la instalación, así como un cuchillo para terminar los cables. También se determinó de inmediato que los cables de conexión estarían codificados por colores, ya que solo había un cable azul y rojo, la telefonía tenía que ser roja y todo lo relacionado con la red era azul. Tipo de estante antes y después de la instalación.
En el estante, encontré una central de oficina Panasonic KX-NCP500 equipada con 4 líneas de ciudad y 8 de extensión. Estaba menos interesado en las líneas telefónicas internas, de todos modos era una IP PBX: gradualmente transferí todo a VOIP. Como no tenía una experiencia seria en la configuración de la central, tuve que jugar un poco. Simplemente valió la pena comprender la necesidad de crear su propio servidor STUN ...
También se determinó de inmediato que los cables de conexión estarían codificados por colores, ya que solo había un cable azul y rojo, la telefonía tenía que ser roja y todo lo relacionado con la red era azul. Tipo de estante antes y después de la instalación.
En el estante, encontré una central de oficina Panasonic KX-NCP500 equipada con 4 líneas de ciudad y 8 de extensión. Estaba menos interesado en las líneas telefónicas internas, de todos modos era una IP PBX: gradualmente transferí todo a VOIP. Como no tenía una experiencia seria en la configuración de la central, tuve que jugar un poco. Simplemente valió la pena comprender la necesidad de crear su propio servidor STUN ... Como tal, la organización no tenía su propia red; todas las computadoras estaban ubicadas en una intranet grande. Yo, como persona que no tenía conocimiento de primera mano de la seguridad de la información, no estaba contento con esto: en el borde de la red instalé y configuré un enrutador basado en FreeBSD, y segmenté la propia red para la posibilidad de un control completo del interfuncionamiento. Con este enfoque, generalmente solo un segmento sufre.Sobre la propia red OGV , solo estaba claro que existía en alguna parte. Tuve que restaurar toda la topología de la red en función de las configuraciones del equipo, esbozar y documentar cuidadosamente. Las configuraciones adquirieron gradualmente una forma humana; aparecieron la descripción y la lógica de denominación.Después de casi seis meses, finalmente encontré documentación en la red OGV. Pero, desafortunadamente, era 90% inconsistente con lo que en realidad era. Se hizo de muy alta calidad, era uno de los pocos documentos en los que era posible trabajar. Pero nadie, a juzgar por la configuración, funcionó.Cuando se examinó la red, actualicé todos los nodos, ya que casi todos los equipos tenían instalado un software muy desactualizado. En algún lugar esto no era necesario, pero en algún lugar solucionó los problemas existentes. Las vistas antiguas (izquierda, 2012) y nuevas (derecha, 2016) de la página principal del sitio.
Como tal, la organización no tenía su propia red; todas las computadoras estaban ubicadas en una intranet grande. Yo, como persona que no tenía conocimiento de primera mano de la seguridad de la información, no estaba contento con esto: en el borde de la red instalé y configuré un enrutador basado en FreeBSD, y segmenté la propia red para la posibilidad de un control completo del interfuncionamiento. Con este enfoque, generalmente solo un segmento sufre.Sobre la propia red OGV , solo estaba claro que existía en alguna parte. Tuve que restaurar toda la topología de la red en función de las configuraciones del equipo, esbozar y documentar cuidadosamente. Las configuraciones adquirieron gradualmente una forma humana; aparecieron la descripción y la lógica de denominación.Después de casi seis meses, finalmente encontré documentación en la red OGV. Pero, desafortunadamente, era 90% inconsistente con lo que en realidad era. Se hizo de muy alta calidad, era uno de los pocos documentos en los que era posible trabajar. Pero nadie, a juzgar por la configuración, funcionó.Cuando se examinó la red, actualicé todos los nodos, ya que casi todos los equipos tenían instalado un software muy desactualizado. En algún lugar esto no era necesario, pero en algún lugar solucionó los problemas existentes. Las vistas antiguas (izquierda, 2012) y nuevas (derecha, 2016) de la página principal del sitio. También se desarrolló un sitio, mientras que al mismo tiempo se crearon sus propios servidores de nombres, alojamiento virtual y servicio de correo. Sospecho extremadamente de las organizaciones donde los empleados tienen direcciones postales en servicios de correo claramente público, especialmente en agencias gubernamentales.En general, los primeros dos meses de trabajo han pasado, creo, es muy fructífero.
También se desarrolló un sitio, mientras que al mismo tiempo se crearon sus propios servidores de nombres, alojamiento virtual y servicio de correo. Sospecho extremadamente de las organizaciones donde los empleados tienen direcciones postales en servicios de correo claramente público, especialmente en agencias gubernamentales.En general, los primeros dos meses de trabajo han pasado, creo, es muy fructífero.Primera etapa
Inicialmente, el centro de datos, a excepción del trabajo del flujo de trabajo interdepartamental, ya no se usaba para nada. Sin lugar a dudas, la gestión de documentos es una de las partes más importantes del trabajo de las autoridades estatales. A menudo, precisamente debido a la complejidad del flujo de trabajo, surgen muchos problemas en el trabajo de nuestro estado, y es el flujo de trabajo electrónico el que nos permite salir de esta situación.Creo que la pregunta más interesante es: ¿en qué trabaja el gobierno electrónico en el centro de datos?El centro de datos en sí consta de varios sitios distribuidos geográficamente, por lo que se implementa el concepto de tolerancia a desastres, el trabajo está en curso 24/7/365. Los sitios estaban interconectados por el tronco principal de 32 fibras monomodo.El núcleo del centro de datos son los blades IBM HS22 y HS23 (ahora Lenovo), que se distribuyen en pares a través de las plataformas. Cada chasis tiene capacidad para 14 cuchillas; en la etapa inicial, se instalaron cinco cuchillas.Cada blade tiene dos procesadores, si no me equivoco, E5650 (6 núcleos, 12 MB de caché), RAM para los globos oculares de 192 GB. Blades sin discos, en el interior decidí instalar USB-flash con una imagen VMWare para maximizar la separación del rendimiento y el almacenamiento, los registros se escriben en un almacenamiento común, el enlace ascendente de cada blade es de 2 Gb / s. El enlace ascendente se puede elevar a 10 Gbit / s instalando el conmutador apropiado en el chasis y una tarjeta de red en cada blade. Nuestro baúl principal de 32 fibras. Como el SO - VMWare vSphere (cuando lo dejé era 5.5) Estándar. En una versión más avanzada, no vi el punto: la funcionalidad propuesta era suficiente en exceso. Y lo que faltaba: podías escribir tú mismo.En el futuro, el número de blades se incrementó debido a servidores IBM HS23 ligeramente más potentes.La redundancia de energía en cada sitio era diferente, pero no menos de dos fuentes de energía. Además, en cada bastidor hay UPS instalados adicionalmente que alimentan el bastidor, en pares: las fuentes de alimentación de los dispositivos se alimentan de diferentes fuentes. Puede ser innecesario, pero hubo un par de momentos en que los UPS montados en bastidor acudieron al rescate. No hay mucho, pero no hay mucha redundancia en tales sistemas.El enfriamiento también fue variado. En el sitio principal, se trataba de aires acondicionados industriales montados en la pared con una unidad de equilibrio. La temperatura se mantuvo a 21 grados. En otro sitio, se trataba de aires acondicionados de piso industrial y un suministro de aire subterráneo. El IBM SVC . Controlador de nuestro sistema de almacenamiento.
El sistema de almacenamiento es escalable, basado en el controlador SVC de IBM , que permitió lograr la redundancia del mismo RAID 6 + 1, redundancia a lo largo de varias rutas, conexión entre unidades a través de una óptica de enlace ascendente de 8 Gb / s. Cualquier parte del centro de datos podría en cualquier momento entrar en funcionamiento independiente en caso de accidente o mantenimiento de rutina. Casi todos los recursos físicos se virtualizan en un centro de datos en funcionamiento: el almacenamiento se virtualiza en base a IBM
Como el SO - VMWare vSphere (cuando lo dejé era 5.5) Estándar. En una versión más avanzada, no vi el punto: la funcionalidad propuesta era suficiente en exceso. Y lo que faltaba: podías escribir tú mismo.En el futuro, el número de blades se incrementó debido a servidores IBM HS23 ligeramente más potentes.La redundancia de energía en cada sitio era diferente, pero no menos de dos fuentes de energía. Además, en cada bastidor hay UPS instalados adicionalmente que alimentan el bastidor, en pares: las fuentes de alimentación de los dispositivos se alimentan de diferentes fuentes. Puede ser innecesario, pero hubo un par de momentos en que los UPS montados en bastidor acudieron al rescate. No hay mucho, pero no hay mucha redundancia en tales sistemas.El enfriamiento también fue variado. En el sitio principal, se trataba de aires acondicionados industriales montados en la pared con una unidad de equilibrio. La temperatura se mantuvo a 21 grados. En otro sitio, se trataba de aires acondicionados de piso industrial y un suministro de aire subterráneo. El IBM SVC . Controlador de nuestro sistema de almacenamiento.
El sistema de almacenamiento es escalable, basado en el controlador SVC de IBM , que permitió lograr la redundancia del mismo RAID 6 + 1, redundancia a lo largo de varias rutas, conexión entre unidades a través de una óptica de enlace ascendente de 8 Gb / s. Cualquier parte del centro de datos podría en cualquier momento entrar en funcionamiento independiente en caso de accidente o mantenimiento de rutina. Casi todos los recursos físicos se virtualizan en un centro de datos en funcionamiento: el almacenamiento se virtualiza en base a IBM SVC ; Los recursos de procesador y RAM se virtualizan en base a VMWare vSphere. Si tomamos la virtualización para usar VLAN en los conmutadores, entonces podemos suponer que la infraestructura de red también está virtualizada.Casi todo el equipo que admite control remoto, me conecté a la red y lo configuré. En sitios remotos, todo funciona, incluso a través de enchufes eléctricos controlados (aparecieron más tarde, en la segunda etapa), por lo tanto, en caso de falla de cualquier equipo sin control remoto, se puede restablecer mediante alimentación.El centro de datos se creó en varias etapas. La primera fase incluyó poner en orden y crear una infraestructura en la nube. El objetivo original era crear un nivel de almacenamiento virtualizado basado en IBM SVC .A medida que se implementaba el plan, los servidores que anteriormente estaban ubicados en organizaciones de terceros comenzaron a trasladarse a nuestro sitio. Así que trasladamos varios servidores antiguos de IBM con servicios que consumían y calentaban más de un chasis BladeCenter. Por supuesto, gradualmente los servicios de ellos se trasladaron a la "nube". Tipo de bastidores en el editor.
Lo primero es el plan. En ese momento, ya podía trabajar como creía conveniente (de todos modos, ya había algunos proyectos terminados, y ya me había ganado la confianza de que había trabajos sin fallas). Por lo tanto, al principio reuní los bastidores en el editor, simultáneamente discutiendo y discutiendo conmigo mismo. El proceso de montaje de equipos en un estante.
SVC ; Los recursos de procesador y RAM se virtualizan en base a VMWare vSphere. Si tomamos la virtualización para usar VLAN en los conmutadores, entonces podemos suponer que la infraestructura de red también está virtualizada.Casi todo el equipo que admite control remoto, me conecté a la red y lo configuré. En sitios remotos, todo funciona, incluso a través de enchufes eléctricos controlados (aparecieron más tarde, en la segunda etapa), por lo tanto, en caso de falla de cualquier equipo sin control remoto, se puede restablecer mediante alimentación.El centro de datos se creó en varias etapas. La primera fase incluyó poner en orden y crear una infraestructura en la nube. El objetivo original era crear un nivel de almacenamiento virtualizado basado en IBM SVC .A medida que se implementaba el plan, los servidores que anteriormente estaban ubicados en organizaciones de terceros comenzaron a trasladarse a nuestro sitio. Así que trasladamos varios servidores antiguos de IBM con servicios que consumían y calentaban más de un chasis BladeCenter. Por supuesto, gradualmente los servicios de ellos se trasladaron a la "nube". Tipo de bastidores en el editor.
Lo primero es el plan. En ese momento, ya podía trabajar como creía conveniente (de todos modos, ya había algunos proyectos terminados, y ya me había ganado la confianza de que había trabajos sin fallas). Por lo tanto, al principio reuní los bastidores en el editor, simultáneamente discutiendo y discutiendo conmigo mismo. El proceso de montaje de equipos en un estante.
 La instalación se realizó de acuerdo con los estándares, las mejores prácticas y recomendaciones descritas, incluso en IBM RedBook. Por supuesto, por primera vez me reí de mi "vamos a leer la documentación", pero después del "método de búsqueda científica" los servidores se negaron a encajar porque, por un lado, la distancia entre las guías es demasiado grande, por el otro es demasiado pequeña. tamaños estándar de redbook para el montaje de bastidores, después de eso todo se unió por primera vez. La primera etapa del centro de datos, junio de 2013. Al fondo está la pandereta del Administrador Supremo.
La instalación se realizó de acuerdo con los estándares, las mejores prácticas y recomendaciones descritas, incluso en IBM RedBook. Por supuesto, por primera vez me reí de mi "vamos a leer la documentación", pero después del "método de búsqueda científica" los servidores se negaron a encajar porque, por un lado, la distancia entre las guías es demasiado grande, por el otro es demasiado pequeña. tamaños estándar de redbook para el montaje de bastidores, después de eso todo se unió por primera vez. La primera etapa del centro de datos, junio de 2013. Al fondo está la pandereta del Administrador Supremo. Para entonces, ya había pasado casi un año desde que trabajé en esta organización en beneficio del estado. Para este año, nunca hemos recurrido a los servicios de integradores u otros contratistas. No voy a disimular, varias veces pedí ayuda a colegas de IBM con preguntas sobre sus equipos y resolvimos conjuntamente los problemas que aparecieron, por lo que muchas gracias a ellos.El centro de datos ya en esta etapa se volvió indicativo y recibió regularmente visitantes para demostrar cómo debería funcionar y verse la infraestructura de TI. Esto no debería parecerse a la infraestructura de TI. La foto fue tomada el segundo día de mi trabajo, 2012.
Para entonces, ya había pasado casi un año desde que trabajé en esta organización en beneficio del estado. Para este año, nunca hemos recurrido a los servicios de integradores u otros contratistas. No voy a disimular, varias veces pedí ayuda a colegas de IBM con preguntas sobre sus equipos y resolvimos conjuntamente los problemas que aparecieron, por lo que muchas gracias a ellos.El centro de datos ya en esta etapa se volvió indicativo y recibió regularmente visitantes para demostrar cómo debería funcionar y verse la infraestructura de TI. Esto no debería parecerse a la infraestructura de TI. La foto fue tomada el segundo día de mi trabajo, 2012. En el proceso de implementación del centro de datos, me quedó claro que los recursos debían entregarse de manera eficiente a los consumidores: organismos gubernamentales. Además, algunos sistemas de información escrita "originales" que se trasladaron a la nube generaron grandes cantidades de información a través de la red.El acceso exclusivo a través de Internet no parecía una buena idea, ya que no ofrecía suficiente velocidad de acceso. Y ampliar la conexión a Internet en todos los grupos públicos es un procedimiento extremadamente costoso. Por lo tanto, se decidió implementar nuestra propia red: económicamente, desde el punto de vista de la seguridad, resultó ser mucho más rentable que arrendar canales de comunicación del mismo Rostelecom.¿Por qué no se hizo esto inicialmente? La respuesta es simple: no había especialistas calificados para este trabajo, solo contratistas externos. Y buscan engancharse a la subcontratación.En este punto, tenía que planificar y construir la infraestructura del proveedor. Al mismo tiempo, muchas redes OGV tuvieron que ser auditadas . Por supuesto, en algunos OGV había servicios de TI bastante fuertes (por ejemplo, en el Ministerio de Finanzas, en el Ministerio de Defensa, en el aparato del gobierno y otros). Pero también había francamente débiles, donde ni siquiera podían comprimir el cable. Tuve que tomar completamente bajo mi ala, ya que la calificación lo permitió.Por lo tanto, en particular, tuve que desarrollar una arquitectura de red típica del OGVpor cuál tenía que luchar. La estandarización y la tipificación son la clave para una operación efectiva. Según mis cálculos preliminares, debería haber habido al menos 100-150 objetos de administración por persona en nuestra organización. Uno de los suministros de equipos de Cisco.
Por supuesto, en la red en construcción, además de las tecnologías VLAN obvias, se utilizaron otras tecnologías modernas para facilitar la administración: OSPF, VTP, PVST, MSTP, HSRP, QoS, etc. Por supuesto, quería aumentar la redundancia con estado, pero, desafortunadamente, ASR no tenía suficientes recursos de hardware. Desafortunadamente, no funcionó para llegar a MPLS. Sí, y no había necesidad. A medida que la red se expandió, comencé a tomar el control del equipo OGV
En el proceso de implementación del centro de datos, me quedó claro que los recursos debían entregarse de manera eficiente a los consumidores: organismos gubernamentales. Además, algunos sistemas de información escrita "originales" que se trasladaron a la nube generaron grandes cantidades de información a través de la red.El acceso exclusivo a través de Internet no parecía una buena idea, ya que no ofrecía suficiente velocidad de acceso. Y ampliar la conexión a Internet en todos los grupos públicos es un procedimiento extremadamente costoso. Por lo tanto, se decidió implementar nuestra propia red: económicamente, desde el punto de vista de la seguridad, resultó ser mucho más rentable que arrendar canales de comunicación del mismo Rostelecom.¿Por qué no se hizo esto inicialmente? La respuesta es simple: no había especialistas calificados para este trabajo, solo contratistas externos. Y buscan engancharse a la subcontratación.En este punto, tenía que planificar y construir la infraestructura del proveedor. Al mismo tiempo, muchas redes OGV tuvieron que ser auditadas . Por supuesto, en algunos OGV había servicios de TI bastante fuertes (por ejemplo, en el Ministerio de Finanzas, en el Ministerio de Defensa, en el aparato del gobierno y otros). Pero también había francamente débiles, donde ni siquiera podían comprimir el cable. Tuve que tomar completamente bajo mi ala, ya que la calificación lo permitió.Por lo tanto, en particular, tuve que desarrollar una arquitectura de red típica del OGVpor cuál tenía que luchar. La estandarización y la tipificación son la clave para una operación efectiva. Según mis cálculos preliminares, debería haber habido al menos 100-150 objetos de administración por persona en nuestra organización. Uno de los suministros de equipos de Cisco.
Por supuesto, en la red en construcción, además de las tecnologías VLAN obvias, se utilizaron otras tecnologías modernas para facilitar la administración: OSPF, VTP, PVST, MSTP, HSRP, QoS, etc. Por supuesto, quería aumentar la redundancia con estado, pero, desafortunadamente, ASR no tenía suficientes recursos de hardware. Desafortunadamente, no funcionó para llegar a MPLS. Sí, y no había necesidad. A medida que la red se expandió, comencé a tomar el control del equipo OGV , ajustándolo simultáneamente como debería. En el proceso de conectar a las administraciones de la región, tuve que llevar a cabo actividades de divulgación y educación y ayudar a colegas en las administraciones distritales y rurales.El enlace ascendente total entre los sitios en la primera etapa fue de solo unos pocos gigabits. Pero ya he asignado un canal para que vSphere funcione.La red en sí resultó estar geográficamente altamente distribuida, incluido un número bastante grande de nodos remotos conectados a través de L2 / L3 VPN.Mucho, por supuesto, podría resolverse mediante inversiones financieras serias, pero me las arreglé con lo que tengo. A menudo, el equipo disponible se usaba de manera ineficiente, así que solo encontré mejores lugares para él. Especialmente en el primer año de vida, todos eran muy escépticos sobre las perspectivas para implementar este proyecto.Pero después del primer año, cuando, gracias a nuestra organización, se mostraron ahorros presupuestarios directos e indirectos de decenas de millones de rublos, y la actitud cambió drásticamente. Uno de los diagramas de red. La mayoría de los nodos por razones obvias están ocultos.
, ajustándolo simultáneamente como debería. En el proceso de conectar a las administraciones de la región, tuve que llevar a cabo actividades de divulgación y educación y ayudar a colegas en las administraciones distritales y rurales.El enlace ascendente total entre los sitios en la primera etapa fue de solo unos pocos gigabits. Pero ya he asignado un canal para que vSphere funcione.La red en sí resultó estar geográficamente altamente distribuida, incluido un número bastante grande de nodos remotos conectados a través de L2 / L3 VPN.Mucho, por supuesto, podría resolverse mediante inversiones financieras serias, pero me las arreglé con lo que tengo. A menudo, el equipo disponible se usaba de manera ineficiente, así que solo encontré mejores lugares para él. Especialmente en el primer año de vida, todos eran muy escépticos sobre las perspectivas para implementar este proyecto.Pero después del primer año, cuando, gracias a nuestra organización, se mostraron ahorros presupuestarios directos e indirectos de decenas de millones de rublos, y la actitud cambió drásticamente. Uno de los diagramas de red. La mayoría de los nodos por razones obvias están ocultos.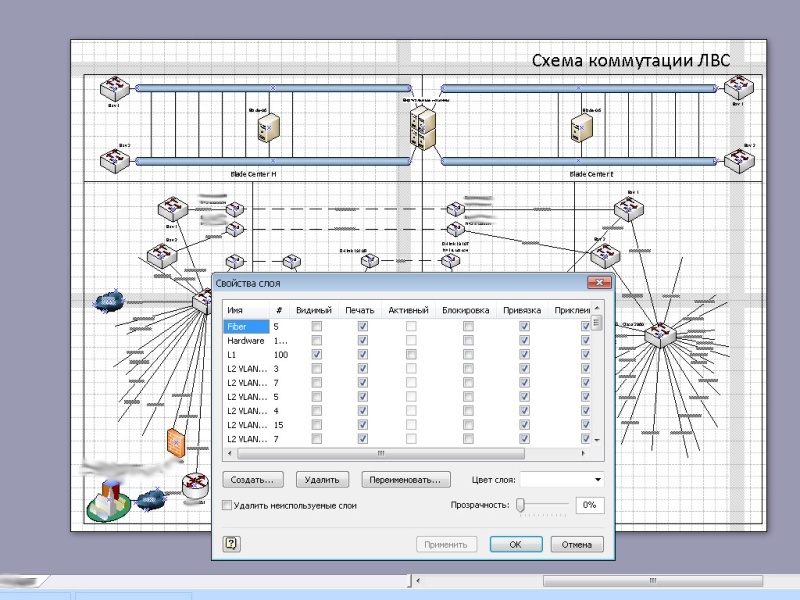
Segunda etapa
En la segunda etapa, ya teníamos que aumentar las capacidades de hardware de nuestro centro de datos. La expansión de capacidades requirió un cambio de chasis del modelo E a H, la reinstalación de los bastidores existentes. El espacio en disco se incrementó al aumentar el número de estantes del HDD. Estantes con discos duros IBM DS3512 y el estante DS3524 es visible en la parte superior.
Varios servidores físicos más se han trasladado a nosotros. El número de máquinas virtuales ha aumentado significativamente. Se agregó una herramienta de respaldo basada en la biblioteca de cintas IBM TS3200. En primer plano está la biblioteca de cintas IBM TS3200.
Naturalmente, comencé la instalación de nuevos equipos con planificación preliminar. Aquí ya tenía que modelar bastidores en ambos lados. Planificación para la expansión del centro de datos.

 El movimiento se completó lo antes posible. Como en ese momento la virtualización funcionaba por completo, el proceso de movimiento era completamente invisible, porque antes de la transferencia y desconexión del equipo en un sitio, todos los servidores virtuales migraron a otro, y al final del trabajo, todo volvió a la normalidad.Por supuesto, además del sitio principal, también se puso orden en el sitio de reserva. Al mismo tiempo, gracias a un sistema de respaldo completamente funcional, finalmente fue posible restaurar el orden allí. Tipo de bastidores después de expandir el recurso, 2014.
El movimiento se completó lo antes posible. Como en ese momento la virtualización funcionaba por completo, el proceso de movimiento era completamente invisible, porque antes de la transferencia y desconexión del equipo en un sitio, todos los servidores virtuales migraron a otro, y al final del trabajo, todo volvió a la normalidad.Por supuesto, además del sitio principal, también se puso orden en el sitio de reserva. Al mismo tiempo, gracias a un sistema de respaldo completamente funcional, finalmente fue posible restaurar el orden allí. Tipo de bastidores después de expandir el recurso, 2014. Y como en ese momento nuestro centro de datos ya era ejemplar, decidí prestar atención a los detalles: las unidades gratuitas disponibles estaban cubiertas con biseles negros, y donde se necesitaba ventilación, se instalaron biseles perforados. Incluso los pernos de montaje que aseguran el equipo en el bastidor, lo quité y pinté de negro de la lata de spray. Un poco, pero agradable. Tipo de bastidores en el sitio de reserva durante la instalación (izquierda) y al final (derecha).
Para deshacerse de los convertidores de medios que se encuentran en todas partes, se compraron un par de chasis D-Link DMC-1000, incluidos proporcionando convertidores de medios de energía de respaldo debido al par de fuentes de alimentación.
Y como en ese momento nuestro centro de datos ya era ejemplar, decidí prestar atención a los detalles: las unidades gratuitas disponibles estaban cubiertas con biseles negros, y donde se necesitaba ventilación, se instalaron biseles perforados. Incluso los pernos de montaje que aseguran el equipo en el bastidor, lo quité y pinté de negro de la lata de spray. Un poco, pero agradable. Tipo de bastidores en el sitio de reserva durante la instalación (izquierda) y al final (derecha).
Para deshacerse de los convertidores de medios que se encuentran en todas partes, se compraron un par de chasis D-Link DMC-1000, incluidos proporcionando convertidores de medios de energía de respaldo debido al par de fuentes de alimentación. Al mismo tiempo, se estaba trabajando para modernizar la red. Cerré el anillo del núcleo de la red de transmisión de datos a una velocidad de 20 Gbit / s entre sitios. Al optimizar el equipo existente, la red de servicio para el funcionamiento de la infraestructura virtual adquirió un enlace ascendente de 10 Gb / s, lo que permitió migrar casi todas las cuchillas al mismo tiempo, con suficiente ancho de banda.La compatibilidad de los equipos SNR con los equipos existentes de Cisco y Brocade resultó ser muy agradable. Por supuesto, en un momento la presencia del equipo Brocade en el chasis fue una sorpresa desagradable para mí, porque no había tenido que trabajar con él antes. Pero, afortunadamente, el conocimiento de los principios de la red nos permitió tratarlo rápidamente.Una parte importante del trabajo, considero la precisión de la ejecución. Todo no solo debería funcionar bien, sino también verse bien. Cuanto más orden en el trabajo, mayor es la confiabilidad. Fue una suerte que ninguno de mí tuviera un enfoque de trabajo así, por lo tanto, junto con uno de nuestros colegas en los estantes, me ordenaron, creo, un orden ejemplar. Debe haber orden en todas partes.
Al mismo tiempo, se estaba trabajando para modernizar la red. Cerré el anillo del núcleo de la red de transmisión de datos a una velocidad de 20 Gbit / s entre sitios. Al optimizar el equipo existente, la red de servicio para el funcionamiento de la infraestructura virtual adquirió un enlace ascendente de 10 Gb / s, lo que permitió migrar casi todas las cuchillas al mismo tiempo, con suficiente ancho de banda.La compatibilidad de los equipos SNR con los equipos existentes de Cisco y Brocade resultó ser muy agradable. Por supuesto, en un momento la presencia del equipo Brocade en el chasis fue una sorpresa desagradable para mí, porque no había tenido que trabajar con él antes. Pero, afortunadamente, el conocimiento de los principios de la red nos permitió tratarlo rápidamente.Una parte importante del trabajo, considero la precisión de la ejecución. Todo no solo debería funcionar bien, sino también verse bien. Cuanto más orden en el trabajo, mayor es la confiabilidad. Fue una suerte que ninguno de mí tuviera un enfoque de trabajo así, por lo tanto, junto con uno de nuestros colegas en los estantes, me ordenaron, creo, un orden ejemplar. Debe haber orden en todas partes.
Mientras tanto
Paralelamente a la creación física del centro de datos y la red OGV , hubo un desarrollo de software para el funcionamiento del gobierno electrónico, en el que también tuve la oportunidad de participar. Tanto en términos de implementación y despliegue, como en términos de apoyo ideológico. Por el apoyo de una verdadera ideología, muchas gracias al liderazgo de entonces.Regularmente tenía que auditar las bases de datos, impulsar a los desarrolladores a usar índices en las bases de datos, capturar consultas intensivas en recursos y optimizar los cuellos de botella. Uno de los sistemas, excepto las claves primarias, no tenía más índices. El resultado: al comienzo de la operación intensiva, el rendimiento de la base de datos comenzó a degradarse bruscamente, tuvo que plantar índices por su cuenta.Gracias a la intervención oportuna en el proceso de desarrollo, todos los sistemas estatales desarrollados se hicieron multiplataforma. Y donde no había una necesidad urgente de usar Windows como base, todo funcionaba bajo el control de la familia de sistemas Linux. Al final resultó que, el principal obstáculo para la creación de aplicaciones multiplataforma fue el uso de notación no universal en las rutas de escritura. A menudo, después de reemplazar una barra oblicua por otra, el sistema estatal se convirtió abruptamente en una plataforma cruzada.La red creada cubría de una forma u otra casi todo el OGV . Estaba listo para comenzar a proporcionar conectividad a Internet, filtrar el tráfico, protección antivirus y evitar ataques desde el exterior y el interior del OGV.. En particular, se suponía que esto proporcionaría ahorros presupuestarios significativos debido al uso más eficiente del ancho de banda del canal.Habiendo creado un servicio de soporte técnico unificado para el OGV , planeé crear trabajos de alta tecnología, concentrar dentro de nuestra organización las fuerzas principales para el apoyo calificado del trabajo, dejando a los técnicos en el campo, al mismo tiempo que mejoraba el nivel de especialistas en el campo organizando conferencias y seminarios web, retiros ...La tercera etapa de la modernización del centro de datos fue la más interesante para mí. Al final de la segunda etapa, se estableció un diálogo con Elbrus, el desarrollador de procesadores domésticos, se obtuvo acceso al banco de pruebas y quedó claro que al menos un tercio de la funcionalidad de los sistemas operativos se puede transferir a la plataforma de hardware doméstico. Solo en el próximo 2015, se lanzaría una nueva versión de hardware del procesador doméstico ... El presupuesto para el próximo año incluía la suma para la compra de servidores ...
Para resumir
Pero mis sueños de transferir servicios públicos a una plataforma de hardware nacional no estaban destinados a hacerse realidad (como otros planes), porque me vi obligado a cambiar mi trabajo a no menos interesante, pero mejor pagado. Es una pena, por supuesto, creo que podría hacer un buen impulso para la implementación de la plataforma de hardware nacional. Además, esto fue antes de la ola de sustitución de importaciones.Al final de mi carrera en esta organización sobre la base de nuestro centro de datos, logré planificar, crear, implementar o participar en la creación de:En total, más de 120 servidores virtuales estaban trabajando en nuestros 7 pares de servidores físicos, utilizando aproximadamente el 30-40% de los recursos de CPU y RAM, aproximadamente el 50% del sistema de almacenamiento. En total, en ese momento nuestro personal era de aproximadamente 30-35 personas, incluido todo el personal administrativo y administrativo, servicio de procesamiento de llamadas.Eficiencia de uso, estoy seguro, en la cara.De hecho, aún puede contar muchos detalles sobre la formación de casi cada uno de los servicios, luego obtiene un volumen de recuerdos bastante pesado.Agradecimientos
- En primer lugar, a ti, querido lector, por leer en este lugar.
- Mi esposa por ayuda y apoyo.
- A la gestión de la Institución Pública del Estado SK "Centro Regional de Tecnologías de la Información" para el fideicomiso depositado.
- Gestión del Ministerio de Industria, Energía y Comunicaciones del Territorio de Stavropol para apoyo administrativo.
- Todos los colegas que tuvieron la suerte de trabajar entonces.
Source: https://habr.com/ru/post/es395197/
All Articles