La red neuronal de visión artificial está entrenada en juegos de computadora realistas.
 Disparos del juego de computadora Grand Theft Auto V y marcado semántico para entrenar unared neuronal de visión artificial Las redes neuronales establecen nuevos récords en casi todas las competiciones de visión por computadora, y también se usan cada vez más en otras aplicaciones de inteligencia artificial. Uno de los componentes clave de un rendimiento de red neuronal tan increíble es la disponibilidad de grandes conjuntos de datos para capacitación y evaluación. Por ejemplo, el desafío de reconocimiento visual a gran escala Imagenet (ILSVRC) con más de 1 millón de imágenes se utiliza para evaluar las redes neuronales modernas. Pero a juzgar por los últimos resultados (ResNet muestra el resultado de solo el 3.57% de los errores), pronto los investigadores tendrán que compilar conjuntos de datos más extensos. Y luego, aún más extenso. Por cierto, anotar esas fotos es mucho trabajo, parte del cual debe hacerse manualmente.Algunos desarrolladores de sistemas de visión por computadora ofrecen una forma alternativa de entrenar y probar dichos sistemas. En lugar de anotar manualmente las fotos de entrenamiento, usan cuadros sintetizados de juegos de computadora realistas.Este es un enfoque completamente lógico. En los juegos modernos, los gráficos han alcanzado un nivel de realismo tal que las imágenes sintetizadas son solo ligeramente diferentes de las fotografías del mundo real. Al mismo tiempo, el motor del juego puede generar una cantidad infinita de tales cuadros, lo que resuelve de manera dramática el problema de recolectar millones de fotos para entrenar y evaluar la red neuronal.Aunque el motor del juego utiliza un número finito de texturas, existe una amplia variedad de combinaciones de ángulos de visión, iluminación, clima y nivel de detalle, lo que proporciona una variedad suficiente de conjuntos de datos.Este año, dos grupos de investigadores comprobaron en la práctica si es posible usar los fotogramas generados de los juegos de computadora para entrenar redes neuronales de visión por computadora. Un grupo de investigadores del departamento de informática de la Universidad de Columbia Británica (Canadá) publicó un artículo científico para el que recopilaron más de 60,000 cuadros de un juego de computadora con vistas de carretera similares a los conjuntos de datos CamVid y Cityscapes . Los investigadores lograron demostrar que la red neuronal después del entrenamiento en imágenes sintéticas muestra un nivel de error similar al del entrenamiento en fotografías reales. Además, el entrenamiento en imágenes sintetizadas usando fotos reales muestra un resultado aún mejor.Todos los 60,000 cuadros fueron tomados en tiempo soleado virtual, a la hora virtual a las 11:00, con una resolución de 1024 × 768 y la configuración máxima de gráficos (el nombre del juego no fue revelado debido a las preocupaciones sobre los derechos de autor). Un vehículo no tripulado condujo accidentalmente por las calles de juego, observando las reglas de la carretera. Los marcos fueron filmados una vez por segundo. Cada uno de ellos va acompañado de una segmentación semántica automática (cielo, peatones, automóviles, árboles, fondo: la segmentación es absolutamente precisa y tomada del juego), una imagen profunda (imagen de profundidad, mapa con el marcado de objetos), así como normales a la superficie.Además del conjunto de datos VG básico, los investigadores crearon otro conjunto de datos VG + con mucha información semántica, no limitada a cinco etiquetas, aquí la segmentación no es precisa. El marcado se realizó automáticamente utilizando SegNet .
Disparos del juego de computadora Grand Theft Auto V y marcado semántico para entrenar unared neuronal de visión artificial Las redes neuronales establecen nuevos récords en casi todas las competiciones de visión por computadora, y también se usan cada vez más en otras aplicaciones de inteligencia artificial. Uno de los componentes clave de un rendimiento de red neuronal tan increíble es la disponibilidad de grandes conjuntos de datos para capacitación y evaluación. Por ejemplo, el desafío de reconocimiento visual a gran escala Imagenet (ILSVRC) con más de 1 millón de imágenes se utiliza para evaluar las redes neuronales modernas. Pero a juzgar por los últimos resultados (ResNet muestra el resultado de solo el 3.57% de los errores), pronto los investigadores tendrán que compilar conjuntos de datos más extensos. Y luego, aún más extenso. Por cierto, anotar esas fotos es mucho trabajo, parte del cual debe hacerse manualmente.Algunos desarrolladores de sistemas de visión por computadora ofrecen una forma alternativa de entrenar y probar dichos sistemas. En lugar de anotar manualmente las fotos de entrenamiento, usan cuadros sintetizados de juegos de computadora realistas.Este es un enfoque completamente lógico. En los juegos modernos, los gráficos han alcanzado un nivel de realismo tal que las imágenes sintetizadas son solo ligeramente diferentes de las fotografías del mundo real. Al mismo tiempo, el motor del juego puede generar una cantidad infinita de tales cuadros, lo que resuelve de manera dramática el problema de recolectar millones de fotos para entrenar y evaluar la red neuronal.Aunque el motor del juego utiliza un número finito de texturas, existe una amplia variedad de combinaciones de ángulos de visión, iluminación, clima y nivel de detalle, lo que proporciona una variedad suficiente de conjuntos de datos.Este año, dos grupos de investigadores comprobaron en la práctica si es posible usar los fotogramas generados de los juegos de computadora para entrenar redes neuronales de visión por computadora. Un grupo de investigadores del departamento de informática de la Universidad de Columbia Británica (Canadá) publicó un artículo científico para el que recopilaron más de 60,000 cuadros de un juego de computadora con vistas de carretera similares a los conjuntos de datos CamVid y Cityscapes . Los investigadores lograron demostrar que la red neuronal después del entrenamiento en imágenes sintéticas muestra un nivel de error similar al del entrenamiento en fotografías reales. Además, el entrenamiento en imágenes sintetizadas usando fotos reales muestra un resultado aún mejor.Todos los 60,000 cuadros fueron tomados en tiempo soleado virtual, a la hora virtual a las 11:00, con una resolución de 1024 × 768 y la configuración máxima de gráficos (el nombre del juego no fue revelado debido a las preocupaciones sobre los derechos de autor). Un vehículo no tripulado condujo accidentalmente por las calles de juego, observando las reglas de la carretera. Los marcos fueron filmados una vez por segundo. Cada uno de ellos va acompañado de una segmentación semántica automática (cielo, peatones, automóviles, árboles, fondo: la segmentación es absolutamente precisa y tomada del juego), una imagen profunda (imagen de profundidad, mapa con el marcado de objetos), así como normales a la superficie.Además del conjunto de datos VG básico, los investigadores crearon otro conjunto de datos VG + con mucha información semántica, no limitada a cinco etiquetas, aquí la segmentación no es precisa. El marcado se realizó automáticamente utilizando SegNet . Tramas marcadas con etiqueta del conjunto VG +Para comparar la efectividad del entrenamiento de redes neuronales, se prepararon conjuntos de datos CamVid y Cityscapes (cinco etiquetas), así como CamVid + y Cityscapes + con conjuntos de etiquetas extendidas.
Tramas marcadas con etiqueta del conjunto VG +Para comparar la efectividad del entrenamiento de redes neuronales, se prepararon conjuntos de datos CamVid y Cityscapes (cinco etiquetas), así como CamVid + y Cityscapes + con conjuntos de etiquetas extendidas. Fotos originales de CamVid con anotaciones
Fotos originales de CamVid con anotaciones Se utilizaron dos imágenes aleatorias del conjunto Cityscapes + con anotaciones detalladas.Para la clasificación semántica, se utilizó una red neuronal convolucional larga con una arquitectura FCN8 simple en la parte superior de la red VGG de 16 capas de Simonyan y Sisserman..Los investigadores realizaron varios experimentos para evaluar la eficiencia de reconocimiento de objetos por una red neuronal que fue entrenada en diferentes conjuntos de datos. En casi todos los casos, una red neuronal entrenada en datos sintéticos mostró un mejor resultado que una red neuronal entrenada en fotografías reales. Mostró el mejor resultado incluso al ver fotos reales.Por ejemplo, la tabla muestra el rendimiento de redes neuronales idénticas entrenadas en tres conjuntos de datos (fotos reales, datos sintéticos del juego, conjuntos mixtos) cuando los objetos se reconocen en fotos reales de los conjuntos CamVid + y Cityscapes +.
Se utilizaron dos imágenes aleatorias del conjunto Cityscapes + con anotaciones detalladas.Para la clasificación semántica, se utilizó una red neuronal convolucional larga con una arquitectura FCN8 simple en la parte superior de la red VGG de 16 capas de Simonyan y Sisserman..Los investigadores realizaron varios experimentos para evaluar la eficiencia de reconocimiento de objetos por una red neuronal que fue entrenada en diferentes conjuntos de datos. En casi todos los casos, una red neuronal entrenada en datos sintéticos mostró un mejor resultado que una red neuronal entrenada en fotografías reales. Mostró el mejor resultado incluso al ver fotos reales.Por ejemplo, la tabla muestra el rendimiento de redes neuronales idénticas entrenadas en tres conjuntos de datos (fotos reales, datos sintéticos del juego, conjuntos mixtos) cuando los objetos se reconocen en fotos reales de los conjuntos CamVid + y Cityscapes +.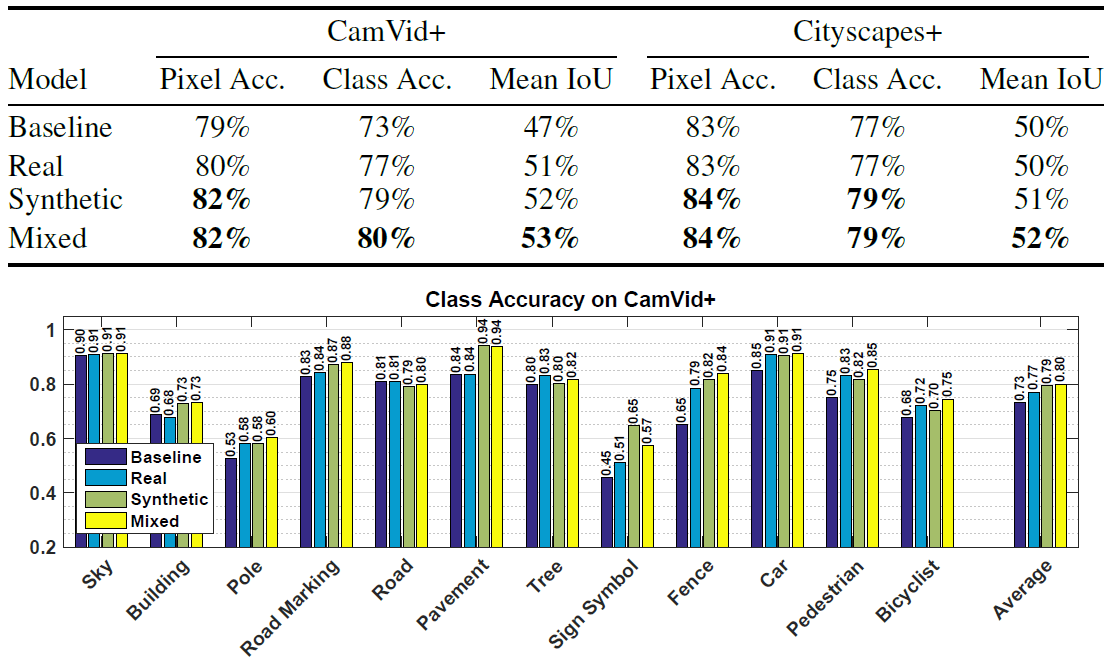 Como puede ver, cuando entrena una red neuronal, es mejor complementar las imágenes sintéticas de un juego de computadora con fotografías reales.Artículo cientificopublicado el 5 de agosto de 2016 en arXiv.org, la segunda versión es el 15 de agosto ( pdf ).Además de los investigadores de la Universidad de Columbia Británica, casi simultáneamente el mismo trabajo fue realizado por otro grupo de científicos de la Universidad Técnica de Darmstadt (Alemania) e Intel Labs . Tomaron 24,966 cuadros del juego de computadora de mundo abierto Grand Theft Auto V. Para el entrenamiento. Los investigadores llegaron al mismo resultado: al usar un conjunto de datos de entrenamiento compuesto por 2/3 de imágenes sintéticas y 1/3 de fotos CamVid, precisión el reconocimiento es mayor que solo cuando se usan fotos CamVid.
Como puede ver, cuando entrena una red neuronal, es mejor complementar las imágenes sintéticas de un juego de computadora con fotografías reales.Artículo cientificopublicado el 5 de agosto de 2016 en arXiv.org, la segunda versión es el 15 de agosto ( pdf ).Además de los investigadores de la Universidad de Columbia Británica, casi simultáneamente el mismo trabajo fue realizado por otro grupo de científicos de la Universidad Técnica de Darmstadt (Alemania) e Intel Labs . Tomaron 24,966 cuadros del juego de computadora de mundo abierto Grand Theft Auto V. Para el entrenamiento. Los investigadores llegaron al mismo resultado: al usar un conjunto de datos de entrenamiento compuesto por 2/3 de imágenes sintéticas y 1/3 de fotos CamVid, precisión el reconocimiento es mayor que solo cuando se usan fotos CamVid.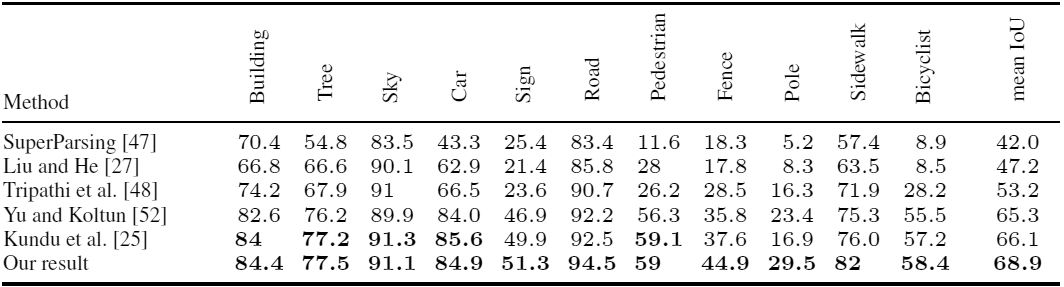 Precisión de reconocimiento de varios objetos en fotos del conjunto CamVid cuando se aprende usando métodos convencionales y cuando se usan marcos de GTA V (línea inferior)Al mismo tiempo, la anotación semiautomática en un editor especialmente desarrollado reduce significativamente el tiempo requerido para preparar un conjunto de datos para entrenar una red neuronal. Por ejemplo, anotar una foto de CamVid toma 60 minutos, una foto de Cityscapes toma 90 minutos, y la anotación semiautomática de cuadros GTA V toma solo 7 segundos, en promedio ( video, demostración del editor ).El trabajo de los investigadores de la Universidad Técnica de Darmstadt e Intel Labs se preparó para la Conferencia Europea sobre Visión por Computadora ECCV'16 (11-14 de octubre) y se publicó en el sitio web de la universidad. Los autores presentaron el código fuente para leer etiquetas y conjuntos completos de datos : tanto fotografías fuente como imágenes en profundidad con marcado semántico. Es probable que el código fuente del editor para la anotación se publique en el futuro.Gracias al progreso en la creación de juegos de computadora realistas, los desarrolladores de sistemas de inteligencia artificial tendrán a su disposición una excelente plataforma para aprender sistemas de visión artificial. Estos sistemas se utilizarán en vehículos no tripulados y robots.Quizás los juegos de computadora se pueden usar no solo para la visión artificial, sino también para crear patrones naturales de comportamiento en la sociedad. Solo con el entrenamiento de IA deberías tener cuidado al elegir un juego.
Precisión de reconocimiento de varios objetos en fotos del conjunto CamVid cuando se aprende usando métodos convencionales y cuando se usan marcos de GTA V (línea inferior)Al mismo tiempo, la anotación semiautomática en un editor especialmente desarrollado reduce significativamente el tiempo requerido para preparar un conjunto de datos para entrenar una red neuronal. Por ejemplo, anotar una foto de CamVid toma 60 minutos, una foto de Cityscapes toma 90 minutos, y la anotación semiautomática de cuadros GTA V toma solo 7 segundos, en promedio ( video, demostración del editor ).El trabajo de los investigadores de la Universidad Técnica de Darmstadt e Intel Labs se preparó para la Conferencia Europea sobre Visión por Computadora ECCV'16 (11-14 de octubre) y se publicó en el sitio web de la universidad. Los autores presentaron el código fuente para leer etiquetas y conjuntos completos de datos : tanto fotografías fuente como imágenes en profundidad con marcado semántico. Es probable que el código fuente del editor para la anotación se publique en el futuro.Gracias al progreso en la creación de juegos de computadora realistas, los desarrolladores de sistemas de inteligencia artificial tendrán a su disposición una excelente plataforma para aprender sistemas de visión artificial. Estos sistemas se utilizarán en vehículos no tripulados y robots.Quizás los juegos de computadora se pueden usar no solo para la visión artificial, sino también para crear patrones naturales de comportamiento en la sociedad. Solo con el entrenamiento de IA deberías tener cuidado al elegir un juego.Source: https://habr.com/ru/post/es397557/
All Articles