"Photoshop" para el habla humana
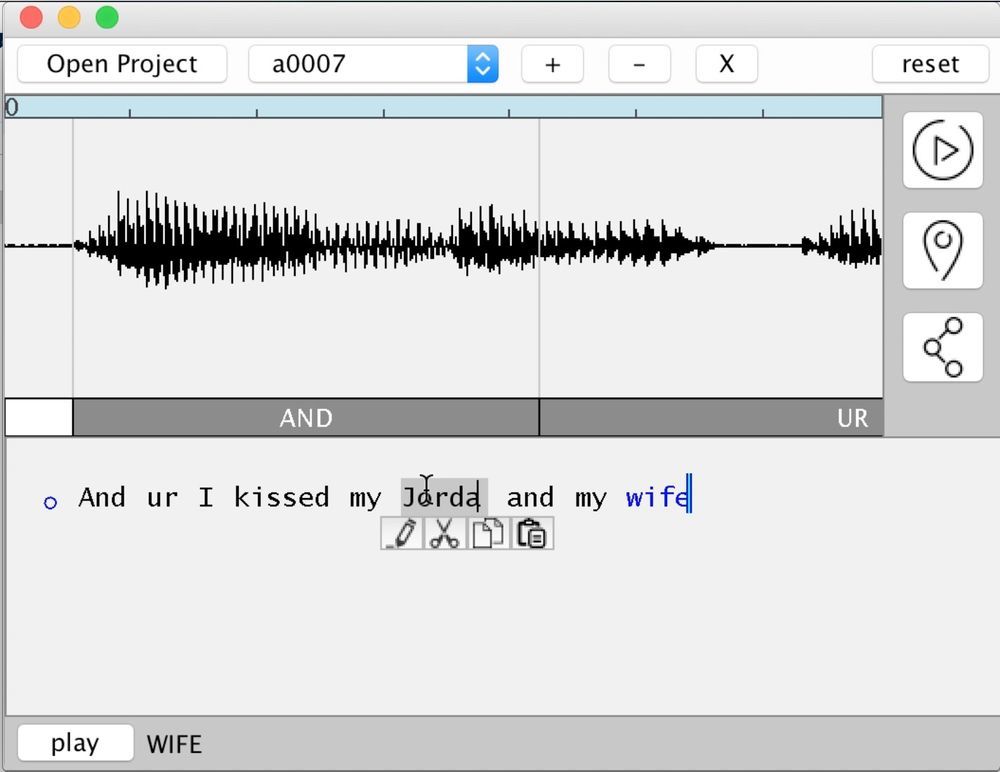 El 3 de noviembre de 2016 en la conferencia de tecnología Adobe MAX, Adobe presentó un desarrollo científico y técnico muy interesante, que en el futuro podría convertirse en una aplicación de software popular. En resumen, la invención es un programa para la edición semántica del habla humana. En este caso, no solo se utiliza el método estándar de síntesis a partir de fonemas recopilados (síntesis de compilación), sino también métodos auxiliares que aumentan el realismo. Esta es una elección inteligente de trifones y el uso de las características específicas de la voz de muestra.Como resultado, el usuario escribe texto arbitrario, y el programa lo expresa con la voz en la que fue entrenado. Puede agregar rápidamente cualquier palabra al discurso o eliminar las innecesarias.En la práctica, el programa presentado como parte del proyecto VoCo funciona de la siguiente manera. Primero, la base del fonema se ensambla para la voz de una persona en particular en un idioma en particular. Para obtener resultados realistas, el programa necesita un mínimo de 20 minutos de discurso humano. Cuanto más, mejor. Basado en los fonemas recopilados (trifones), el programa puede recopilar casi cualquier palabra nueva como si fuera de ladrillos.Fragmento de la presentación de VoCo en la conferencia MAXEn cierto sentido, VoCo funciona como el trabajo de un pincel de contexto en Photoshop. También toma fragmentos de diferentes lugares de la imagen, y recoge una nueva imagen de estos fragmentos. Un trozo de madera de una fotografía del bosque, un trozo de hierba de otra imagen y una niña de la tercera fotografía, y obtenemos un trabajo fotorrealista completamente nuevo con un bosque, hierba y una niña en primer plano. Si el trabajo se realiza profesionalmente, la instalación es muy difícil de determinar. Entonces, en la época soviética , las personas que de repente se convirtieron en enemigas de la gente fueron borradas de la historia . Había una persona en la fotografía, y ahora hay un vacío u otra persona.Entonces, la tecnología VoCo le permite complementar el habla humana con palabras y frases arbitrarias.En la conferencia MAX, uno de los desarrolladores, Zeyu Jin, hizo una presentación. En un artículo científico publicado anteriormente , aparece como empleado de la Universidad de Princeton, junto con su colega Adam Finkelstein. La tecnología fue desarrollada por Adobe Research en colaboración con la Universidad de Princeton.Tal como lo concibió Adobe, la tecnología ayudará a los creadores de contenido a editar más fácilmente la pista de audio: cuadros de diálogo y texto de voz en off para corregir rápidamente un error o realizar cambios en la historia.Adobe enfatiza que en este caso es más apropiado hablar sobre "conversión de voz" que sobre la síntesis de voz clásica. El propósito de la conversión de voz es transformar la voz original para que para el oyente parezca ser la voz de otra persona siguiendo el modelo de la voz de este último.Los fundamentos técnicos de la conversión de voz se describen con más detalle en el trabajo científico mencionado anteriormente .preparado conjuntamente con la Universidad de Princeton. Sus autores muestran que la técnica CUTE desarrollada es cualitativamente superior a otros métodos de conversión de voz. Los métodos de conversión alternativos generalmente se basan en el análisis paralelo de frases idénticas de la fuente y el destino, seguido del cálculo de ciertos vectores de transformación en cualquier espacio de direcciones. Después de eso, cualquier fragmento arbitrario de la voz original se puede transformar utilizando los vectores obtenidos. Pero estos métodos sufren efectos secundarios desagradables: el discurso sintetizado de esta manera es sordo, arrastrado.Los investigadores de Adobe pudieron superar las deficiencias de otras técnicas utilizando el método híbrido CUTE. El título encripta los cuatro componentes principales de esta técnica: síntesis de compilación (síntesis concatenativa); selección de unidad; selección preliminar de trifones, es decir, unidades de tres fonemas (preselección de Triphone); Uso de propiedades de muestra (características basadas en ejemplos).La síntesis de compilación se reduce a componer un mensaje a partir de un diccionario pregrabado de fonemas. Este es el método principal para trabajar con sintetizadores de voz, que están equipados con varios dispositivos: desde aviones militares hasta dispositivos domésticos, en los servicios de ayuda de operadores móviles, etc.Como su nombre lo indica, la técnica híbrida desarrollada combina varios métodos de síntesis de voz y conversión de voz.El trabajo científico presenta los resultados de pruebas comparativas con otros métodos de conversión de voz, en los cuales CUTE es significativamente superior a los competidores. Al mismo tiempo, se mencionan algunas de sus deficiencias: él, como todos los demás, sufre de una cantidad insuficiente de fonemas en la base de datos al sintetizar nuevas palabras, lo que genera resultados fonéticamente correctos, pero no muy realistas. Además, depende del funcionamiento del motor de reconocimiento de voz para la segmentación fonética correcta.Todavía se desconoce si Adobe implementará este prometedor desarrollo en forma de un producto comercial real. Pero ahora podemos decir que dicho programa se volvería muy popular, siempre que la síntesis de voz a partir de fonemas sea realista. Por ejemplo, los podcasters podrían usarlo para generar podcasts a partir de texto. También se puede usar para grabar audiolibros con la voz de una persona arbitraria (por ejemplo, su propia niña). Es probable que dicha tecnología encuentre aplicación en Hollywood para la actuación de voz en ausencia de un actor. Por ejemplo, si se rompió un contrato con él o murió en medio de la filmación.
El 3 de noviembre de 2016 en la conferencia de tecnología Adobe MAX, Adobe presentó un desarrollo científico y técnico muy interesante, que en el futuro podría convertirse en una aplicación de software popular. En resumen, la invención es un programa para la edición semántica del habla humana. En este caso, no solo se utiliza el método estándar de síntesis a partir de fonemas recopilados (síntesis de compilación), sino también métodos auxiliares que aumentan el realismo. Esta es una elección inteligente de trifones y el uso de las características específicas de la voz de muestra.Como resultado, el usuario escribe texto arbitrario, y el programa lo expresa con la voz en la que fue entrenado. Puede agregar rápidamente cualquier palabra al discurso o eliminar las innecesarias.En la práctica, el programa presentado como parte del proyecto VoCo funciona de la siguiente manera. Primero, la base del fonema se ensambla para la voz de una persona en particular en un idioma en particular. Para obtener resultados realistas, el programa necesita un mínimo de 20 minutos de discurso humano. Cuanto más, mejor. Basado en los fonemas recopilados (trifones), el programa puede recopilar casi cualquier palabra nueva como si fuera de ladrillos.Fragmento de la presentación de VoCo en la conferencia MAXEn cierto sentido, VoCo funciona como el trabajo de un pincel de contexto en Photoshop. También toma fragmentos de diferentes lugares de la imagen, y recoge una nueva imagen de estos fragmentos. Un trozo de madera de una fotografía del bosque, un trozo de hierba de otra imagen y una niña de la tercera fotografía, y obtenemos un trabajo fotorrealista completamente nuevo con un bosque, hierba y una niña en primer plano. Si el trabajo se realiza profesionalmente, la instalación es muy difícil de determinar. Entonces, en la época soviética , las personas que de repente se convirtieron en enemigas de la gente fueron borradas de la historia . Había una persona en la fotografía, y ahora hay un vacío u otra persona.Entonces, la tecnología VoCo le permite complementar el habla humana con palabras y frases arbitrarias.En la conferencia MAX, uno de los desarrolladores, Zeyu Jin, hizo una presentación. En un artículo científico publicado anteriormente , aparece como empleado de la Universidad de Princeton, junto con su colega Adam Finkelstein. La tecnología fue desarrollada por Adobe Research en colaboración con la Universidad de Princeton.Tal como lo concibió Adobe, la tecnología ayudará a los creadores de contenido a editar más fácilmente la pista de audio: cuadros de diálogo y texto de voz en off para corregir rápidamente un error o realizar cambios en la historia.Adobe enfatiza que en este caso es más apropiado hablar sobre "conversión de voz" que sobre la síntesis de voz clásica. El propósito de la conversión de voz es transformar la voz original para que para el oyente parezca ser la voz de otra persona siguiendo el modelo de la voz de este último.Los fundamentos técnicos de la conversión de voz se describen con más detalle en el trabajo científico mencionado anteriormente .preparado conjuntamente con la Universidad de Princeton. Sus autores muestran que la técnica CUTE desarrollada es cualitativamente superior a otros métodos de conversión de voz. Los métodos de conversión alternativos generalmente se basan en el análisis paralelo de frases idénticas de la fuente y el destino, seguido del cálculo de ciertos vectores de transformación en cualquier espacio de direcciones. Después de eso, cualquier fragmento arbitrario de la voz original se puede transformar utilizando los vectores obtenidos. Pero estos métodos sufren efectos secundarios desagradables: el discurso sintetizado de esta manera es sordo, arrastrado.Los investigadores de Adobe pudieron superar las deficiencias de otras técnicas utilizando el método híbrido CUTE. El título encripta los cuatro componentes principales de esta técnica: síntesis de compilación (síntesis concatenativa); selección de unidad; selección preliminar de trifones, es decir, unidades de tres fonemas (preselección de Triphone); Uso de propiedades de muestra (características basadas en ejemplos).La síntesis de compilación se reduce a componer un mensaje a partir de un diccionario pregrabado de fonemas. Este es el método principal para trabajar con sintetizadores de voz, que están equipados con varios dispositivos: desde aviones militares hasta dispositivos domésticos, en los servicios de ayuda de operadores móviles, etc.Como su nombre lo indica, la técnica híbrida desarrollada combina varios métodos de síntesis de voz y conversión de voz.El trabajo científico presenta los resultados de pruebas comparativas con otros métodos de conversión de voz, en los cuales CUTE es significativamente superior a los competidores. Al mismo tiempo, se mencionan algunas de sus deficiencias: él, como todos los demás, sufre de una cantidad insuficiente de fonemas en la base de datos al sintetizar nuevas palabras, lo que genera resultados fonéticamente correctos, pero no muy realistas. Además, depende del funcionamiento del motor de reconocimiento de voz para la segmentación fonética correcta.Todavía se desconoce si Adobe implementará este prometedor desarrollo en forma de un producto comercial real. Pero ahora podemos decir que dicho programa se volvería muy popular, siempre que la síntesis de voz a partir de fonemas sea realista. Por ejemplo, los podcasters podrían usarlo para generar podcasts a partir de texto. También se puede usar para grabar audiolibros con la voz de una persona arbitraria (por ejemplo, su propia niña). Es probable que dicha tecnología encuentre aplicación en Hollywood para la actuación de voz en ausencia de un actor. Por ejemplo, si se rompió un contrato con él o murió en medio de la filmación.Source: https://habr.com/ru/post/es398865/
All Articles