La red neuronal LipNet lee los labios con una precisión del 93,4%
 El comandante Dave Bowman y el copiloto Frank Poole, que no confiaban en la computadora, decidieron desconectarla del control de la nave. Para hacer esto, se reúnen en una habitación insonorizada, pero HAL 9000 lee su conversación en los labios. Tomada de la película "Space Odyssey of 2001" Lalectura de labios juega un papel importante en la comunicación. Más experimentos en 1976 mostraron que las personas "escuchan" fonemas completamente diferentes si pones el sonido incorrecto en el movimiento de los labios (ver "Escuchar labios y ver voces" , Nature 264, 746-748, 23 de diciembre de 1976, doi: 10.1038 / 264746a0) .Desde un punto de vista práctico, la lectura de labios es una habilidad importante y útil. Puede entender al interlocutor sin apagar la música en los auriculares, leer las conversaciones de todas las personas en el campo de visión (por ejemplo, todos los pasajeros en la sala de espera), escuchar a las personas a través de binoculares o un telescopio. El alcance de la habilidad es muy amplio. Un profesional que lo domine encontrará fácilmente un trabajo bien remunerado. Por ejemplo, en el campo de la seguridad o la inteligencia competitiva.Los sistemas automáticos de lectura de labios también tienen un gran potencial práctico. Estos son los audífonos médicos de nueva generación con reconocimiento de voz, sistemas para conferencias silenciosas en lugares públicos, identificación biométrica, sistemas para la transmisión secreta de información para espionaje, reconocimiento de voz por video desde cámaras de vigilancia, etc. Al final, las computadoras del futuro también leerán los labios, como el HAL 9000 .Por lo tanto, los científicos han intentado durante muchos años desarrollar sistemas automáticos de lectura de labios, pero sin mucho éxito. Incluso para un inglés relativamente simple, en el que la cantidad de fonemas es mucho menor que en ruso, la precisión del reconocimiento es baja.Comprender el habla basada en expresiones faciales humanas es una tarea desalentadora. Las personas que han dominado esta habilidad intentan reconocer docenas de fonemas consonantes, muchos de los cuales son muy similares en apariencia. Es especialmente difícil para una persona no capacitada distinguir entre cinco categorías de fonemas visuales (es decir, visemas) del idioma inglés. En otras palabras, distinguir la pronunciación de algunas consonantes por los labios es casi imposible. No es sorprendente que a las personas les vaya muy mal la lectura precisa de los labios. Incluso las mejores personas con discapacidad auditiva muestran una precisión de solo 17 ± 12% de 30 monosílabos o 21 ± 11% de palabras polisilábicas (en adelante, los resultados para el idioma inglés).La lectura automática de labios es una de las tareas de la visión artificial, que se reduce al procesamiento cuadro por cuadro de una secuencia de video. La tarea se complica en gran medida por la baja calidad de la mayoría de los materiales de video prácticos, que no permiten una lectura precisa del espacio-temporal, es decir, las características espacio-temporales de una persona durante una conversación. Las caras se mueven y giran en diferentes direcciones. Los desarrollos recientes en el campo de la visión artificial están tratando de rastrear el movimiento de la cara en el marco para resolver este problema. A pesar de los éxitos, hasta hace poco, solo podían reconocer palabras individuales, pero no oraciones.Los desarrolladores de la Universidad de Oxford lograron un avance significativo en esta área. El LipNet que entrenaronse convirtió en el primero en el mundo en reconocer con éxito los labios a nivel de oraciones completas, procesando imágenes de video. Mapas de relevancia
El comandante Dave Bowman y el copiloto Frank Poole, que no confiaban en la computadora, decidieron desconectarla del control de la nave. Para hacer esto, se reúnen en una habitación insonorizada, pero HAL 9000 lee su conversación en los labios. Tomada de la película "Space Odyssey of 2001" Lalectura de labios juega un papel importante en la comunicación. Más experimentos en 1976 mostraron que las personas "escuchan" fonemas completamente diferentes si pones el sonido incorrecto en el movimiento de los labios (ver "Escuchar labios y ver voces" , Nature 264, 746-748, 23 de diciembre de 1976, doi: 10.1038 / 264746a0) .Desde un punto de vista práctico, la lectura de labios es una habilidad importante y útil. Puede entender al interlocutor sin apagar la música en los auriculares, leer las conversaciones de todas las personas en el campo de visión (por ejemplo, todos los pasajeros en la sala de espera), escuchar a las personas a través de binoculares o un telescopio. El alcance de la habilidad es muy amplio. Un profesional que lo domine encontrará fácilmente un trabajo bien remunerado. Por ejemplo, en el campo de la seguridad o la inteligencia competitiva.Los sistemas automáticos de lectura de labios también tienen un gran potencial práctico. Estos son los audífonos médicos de nueva generación con reconocimiento de voz, sistemas para conferencias silenciosas en lugares públicos, identificación biométrica, sistemas para la transmisión secreta de información para espionaje, reconocimiento de voz por video desde cámaras de vigilancia, etc. Al final, las computadoras del futuro también leerán los labios, como el HAL 9000 .Por lo tanto, los científicos han intentado durante muchos años desarrollar sistemas automáticos de lectura de labios, pero sin mucho éxito. Incluso para un inglés relativamente simple, en el que la cantidad de fonemas es mucho menor que en ruso, la precisión del reconocimiento es baja.Comprender el habla basada en expresiones faciales humanas es una tarea desalentadora. Las personas que han dominado esta habilidad intentan reconocer docenas de fonemas consonantes, muchos de los cuales son muy similares en apariencia. Es especialmente difícil para una persona no capacitada distinguir entre cinco categorías de fonemas visuales (es decir, visemas) del idioma inglés. En otras palabras, distinguir la pronunciación de algunas consonantes por los labios es casi imposible. No es sorprendente que a las personas les vaya muy mal la lectura precisa de los labios. Incluso las mejores personas con discapacidad auditiva muestran una precisión de solo 17 ± 12% de 30 monosílabos o 21 ± 11% de palabras polisilábicas (en adelante, los resultados para el idioma inglés).La lectura automática de labios es una de las tareas de la visión artificial, que se reduce al procesamiento cuadro por cuadro de una secuencia de video. La tarea se complica en gran medida por la baja calidad de la mayoría de los materiales de video prácticos, que no permiten una lectura precisa del espacio-temporal, es decir, las características espacio-temporales de una persona durante una conversación. Las caras se mueven y giran en diferentes direcciones. Los desarrollos recientes en el campo de la visión artificial están tratando de rastrear el movimiento de la cara en el marco para resolver este problema. A pesar de los éxitos, hasta hace poco, solo podían reconocer palabras individuales, pero no oraciones.Los desarrolladores de la Universidad de Oxford lograron un avance significativo en esta área. El LipNet que entrenaronse convirtió en el primero en el mundo en reconocer con éxito los labios a nivel de oraciones completas, procesando imágenes de video. Mapas de relevancia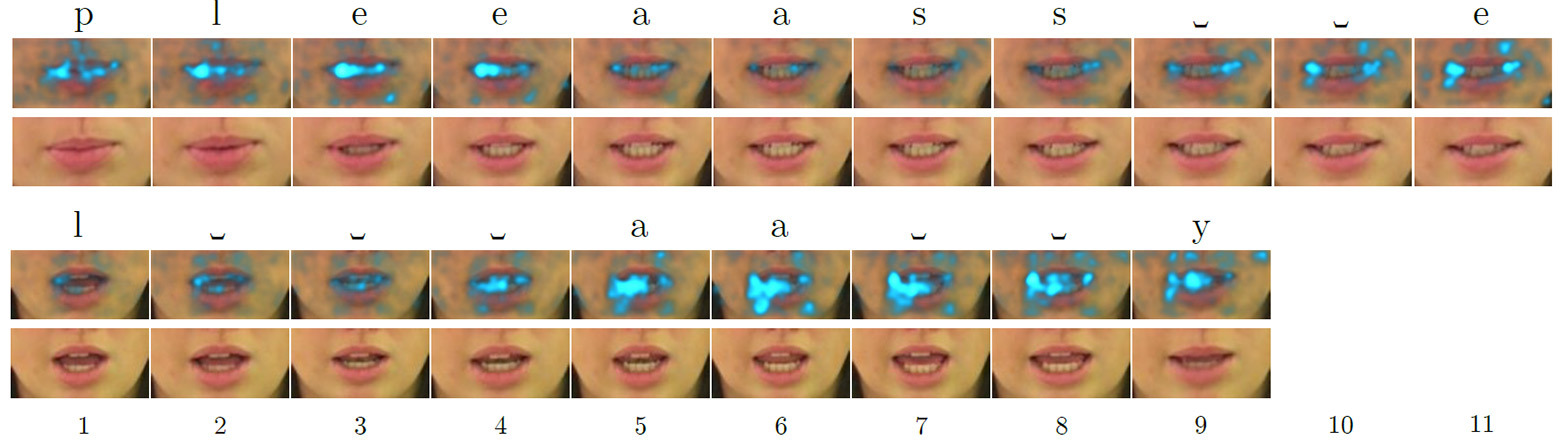 cuadro por cuadro para las palabras en inglés "please" (arriba) y "lay" (abajo) cuando son procesadas por una red neuronal que lee los labios, destacando las características más llamativas (salientes) deLipNet, una red neuronal recurrente del tipo LSTM (memoria a largo plazo). La arquitectura se muestra en la ilustración. La red neuronal se entrenó utilizando el método de Clasificación Temporal Connectionist (CTC), que se usa ampliamente en los sistemas modernos de reconocimiento de voz, ya que elimina la necesidad de entrenamiento en un conjunto de datos de entrada sincronizados con el resultado correcto.
cuadro por cuadro para las palabras en inglés "please" (arriba) y "lay" (abajo) cuando son procesadas por una red neuronal que lee los labios, destacando las características más llamativas (salientes) deLipNet, una red neuronal recurrente del tipo LSTM (memoria a largo plazo). La arquitectura se muestra en la ilustración. La red neuronal se entrenó utilizando el método de Clasificación Temporal Connectionist (CTC), que se usa ampliamente en los sistemas modernos de reconocimiento de voz, ya que elimina la necesidad de entrenamiento en un conjunto de datos de entrada sincronizados con el resultado correcto.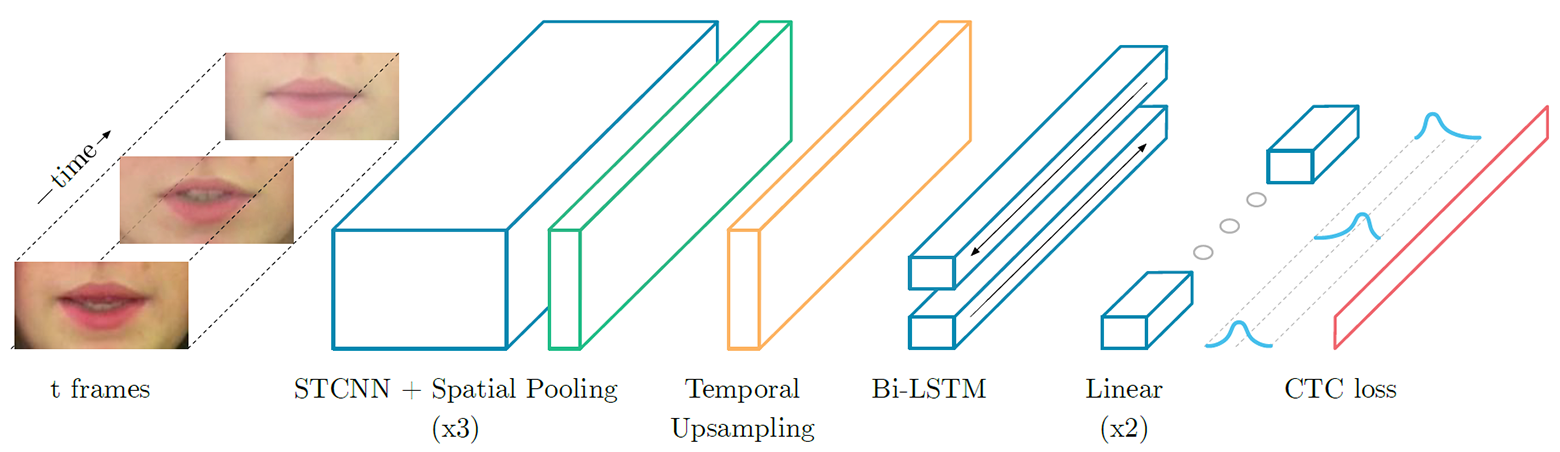 Arquitectura de red neuronal LipNet. En la entrada, se suministra una secuencia de tramas T, que luego son procesadas por tres capas de la red neuronal convolucional espacio-temporal (espacio-temporal) (STCNN), cada una de las cuales está acompañada por una capa de muestreo espacial. Para las características extraídas, la frecuencia de muestreo en la línea de tiempo (muestreo ascendente) aumenta, y luego se procesan con doble LTSM. Cada paso de tiempo en la salida LTSM es procesado por una red de distribución directa de dos capas y la última capa SoftMax.En un paquete especial de oferta GRID, la red neuronal muestra una precisión de reconocimiento del 93.4%. Esto no solo excede la precisión de reconocimiento de otros desarrollos de software (que se indican en la tabla a continuación), sino que también excede la eficiencia de la lectura en boca de personas especialmente capacitadas.
Arquitectura de red neuronal LipNet. En la entrada, se suministra una secuencia de tramas T, que luego son procesadas por tres capas de la red neuronal convolucional espacio-temporal (espacio-temporal) (STCNN), cada una de las cuales está acompañada por una capa de muestreo espacial. Para las características extraídas, la frecuencia de muestreo en la línea de tiempo (muestreo ascendente) aumenta, y luego se procesan con doble LTSM. Cada paso de tiempo en la salida LTSM es procesado por una red de distribución directa de dos capas y la última capa SoftMax.En un paquete especial de oferta GRID, la red neuronal muestra una precisión de reconocimiento del 93.4%. Esto no solo excede la precisión de reconocimiento de otros desarrollos de software (que se indican en la tabla a continuación), sino que también excede la eficiencia de la lectura en boca de personas especialmente capacitadas.| Método | Conjunto de datos | Tamaño | Problema | Precisión |
|---|
| Fu y col. (2008) | AVICAR | 851 | | 37,9% |
| Zhao et al. (2009) | AVLetter | 78 | | 43,5% |
| Papandreou et al. (2009) | CUAVE | 1800 | | 83,0% |
| Chung & Zisserman (2016a) | OuluVS1 | 200 | | 91,4% |
| Chung & Zisserman (2016b) | OuluVS2 | 520 | | 94,1% |
| Chung & Zisserman (2016a) | BBC TV | >400000 | | 65,4% |
| Wand et al. (2016) | GRID | 9000 | | 79,6% |
| LipNet | GRID | 28853 | | 93,4% |
El caso especial de GRID se compone de acuerdo con la siguiente plantilla:comando (4) + color (4) + preposición (4) + letra (25) + dígito (10) + adverbio (4),donde el número corresponde al número de variantes de palabras para cada una de las seis categorías verbales .En otras palabras, la precisión del 93,4% sigue siendo el resultado obtenido en condiciones de laboratorio de invernadero. Por supuesto, con el reconocimiento del discurso humano arbitrario, el resultado será mucho peor. Sin mencionar el análisis de datos de video real, donde la cara de una persona no se toma de cerca con excelente iluminación y alta resolución.El funcionamiento de la red neuronal LipNet se muestra en el video de demostración.El artículo científico fue preparado para la conferencia ICLR 2017 y publicado el 4 de noviembre de 2016 en el dominio público.Source: https://habr.com/ru/post/es398901/
All Articles