La red neuronal lee el 46.8% de las palabras en los labios en la televisión, mientras que solo el 12.4% de las personas
 Los marcos de los cuatro programas en los que se estudió el programa, así como la palabra "tarde", pronunciada por dos oradores diferentesHace dos semanas, hablaron sobre la red neuronal LipNet , que mostró una calidad de registro del 93,4% del reconocimiento del habla humana en los labios. Incluso entonces, se suponían muchas aplicaciones para tales sistemas informáticos: una nueva generación de audífonos médicos con reconocimiento de voz, sistemas para conferencias silenciosas en lugares públicos, identificación biométrica, sistemas para la transmisión secreta de información para espionaje, reconocimiento de voz por video desde cámaras de vigilancia, etc. Y ahora, expertos de la Universidad de Oxford junto con un empleado de Google DeepMind hablaron sobre sus propios desarrollos en esta área.La nueva red neuronal fue entrenada en textos arbitrarios de personas que actúan en el canal de televisión de la BBC. Curiosamente, el entrenamiento se realizó automáticamente, sin anotar primero el discurso manualmente. El sistema mismo reconoció el habla, anotó el video, encontró caras en el cuadro y luego aprendió a determinar la relación entre las palabras (sonidos) y el movimiento de los labios.Como resultado, este sistema reconoce efectivamente textos arbitrarios , en lugar de instancias del corpus especial de oraciones GRID, como lo hizo LipNet. El caso GRID tiene una estructura y vocabulario estrictamente limitados; por lo tanto, solo son posibles 33,000 oraciones. Por lo tanto, el número de opciones se reduce en órdenes de magnitud y se simplifica el reconocimiento.El caso especial GRID se compone de la siguiente manera:comando (4) + color (4) + preposición (4) + letra (25) + dígito (10) + adverbio (4),donde el número corresponde al número de variantes de palabras para cada una de las seis categorías verbales.A diferencia de LipNet, el desarrollo de DeepMind y especialistas de la Universidad de Oxford trabaja en flujos de voz arbitrarios en calidad de imagen de televisión. Es mucho más como un sistema real, listo para su uso práctico.AI entrenó 5,000 horas de video grabado de seis programas de televisión del canal de televisión británico de la BBC desde enero de 2010 hasta diciembre de 2015: estos son comunicados de prensa regulares (1584 horas), noticias de la mañana (1997 horas), emisiones de Newsnight (590 horas), World News (194 horas), turno de preguntas (323 horas) y Mundo de hoy (272 horas). En total, los videos contienen 118,116 oraciones de habla humana continua.Después de eso, el programa se verificó en las transmisiones que se emitieron entre marzo y septiembre de 2016.
Los marcos de los cuatro programas en los que se estudió el programa, así como la palabra "tarde", pronunciada por dos oradores diferentesHace dos semanas, hablaron sobre la red neuronal LipNet , que mostró una calidad de registro del 93,4% del reconocimiento del habla humana en los labios. Incluso entonces, se suponían muchas aplicaciones para tales sistemas informáticos: una nueva generación de audífonos médicos con reconocimiento de voz, sistemas para conferencias silenciosas en lugares públicos, identificación biométrica, sistemas para la transmisión secreta de información para espionaje, reconocimiento de voz por video desde cámaras de vigilancia, etc. Y ahora, expertos de la Universidad de Oxford junto con un empleado de Google DeepMind hablaron sobre sus propios desarrollos en esta área.La nueva red neuronal fue entrenada en textos arbitrarios de personas que actúan en el canal de televisión de la BBC. Curiosamente, el entrenamiento se realizó automáticamente, sin anotar primero el discurso manualmente. El sistema mismo reconoció el habla, anotó el video, encontró caras en el cuadro y luego aprendió a determinar la relación entre las palabras (sonidos) y el movimiento de los labios.Como resultado, este sistema reconoce efectivamente textos arbitrarios , en lugar de instancias del corpus especial de oraciones GRID, como lo hizo LipNet. El caso GRID tiene una estructura y vocabulario estrictamente limitados; por lo tanto, solo son posibles 33,000 oraciones. Por lo tanto, el número de opciones se reduce en órdenes de magnitud y se simplifica el reconocimiento.El caso especial GRID se compone de la siguiente manera:comando (4) + color (4) + preposición (4) + letra (25) + dígito (10) + adverbio (4),donde el número corresponde al número de variantes de palabras para cada una de las seis categorías verbales.A diferencia de LipNet, el desarrollo de DeepMind y especialistas de la Universidad de Oxford trabaja en flujos de voz arbitrarios en calidad de imagen de televisión. Es mucho más como un sistema real, listo para su uso práctico.AI entrenó 5,000 horas de video grabado de seis programas de televisión del canal de televisión británico de la BBC desde enero de 2010 hasta diciembre de 2015: estos son comunicados de prensa regulares (1584 horas), noticias de la mañana (1997 horas), emisiones de Newsnight (590 horas), World News (194 horas), turno de preguntas (323 horas) y Mundo de hoy (272 horas). En total, los videos contienen 118,116 oraciones de habla humana continua.Después de eso, el programa se verificó en las transmisiones que se emitieron entre marzo y septiembre de 2016.Un ejemplo de lectura de labios desde una pantalla de televisión El programa mostró una calidad de lectura bastante alta. Ella reconoció correctamente incluso oraciones muy complejas con construcciones gramaticales inusuales y el uso de nombres propios. Ejemplos de oraciones perfectamente reconocidas:- MUCHAS MÁS PERSONAS QUE PARTICIPARON EN LOS ATAQUES
- CLOSE TO THE EUROPEAN COMMISSION’S MAIN BUILDING
- WEST WALES AND THE SOUTH WEST AS WELL AS WESTERN SCOTLAND
- WE KNOW THERE WILL BE HUNDREDS OF JOURNALISTS HERE AS WELL
- ACCORDING TO PROVISIONAL FIGURES FROM THE ELECTORAL COMMISSION
- THAT’S THE LOWEST FIGURE FOR EIGHT YEARS
- MANCHESTER FOOTBALL CORRESPONDENT FOR THE DAILY MIRROR
- LAYING THE GROUNDS FOR A POSSIBLE SECOND REFERENDUM
- ACCORDING TO THE LATEST FIGURES FROM THE OFFICE FOR NATIONAL STATISTICS
- IT COMES AFTER A DAMNING REPORT BY THE HEALTH WATCHDOG
AI superó significativamente la efectividad del trabajo de una persona, un experto en lectura de labios, que intentó reconocer 200 videoclips aleatorios de un archivo de video de verificación grabado.El profesional pudo anotar sin un solo error solo el 12.4% de las palabras, mientras que la IA registró correctamente el 46.8%. Los investigadores señalan que muchos errores se pueden llamar menores. Por ejemplo, la "s" que falta al final de las palabras. Si abordamos el análisis de los resultados de manera menos estricta, en realidad el sistema reconoció mucho más de la mitad de las palabras en el aire.Con este resultado, DeepMind es significativamente superior a todos los demás lectores de labios, incluido el mencionado LipNet, que también se desarrolla en la Universidad de Oxford. Sin embargo, es demasiado pronto para hablar de la superioridad máxima, porque LipNet no fue entrenado en un conjunto de datos tan grande.Según los expertos , DeepMind es un gran paso hacia el desarrollo de un sistema de lectura de labios totalmente automático.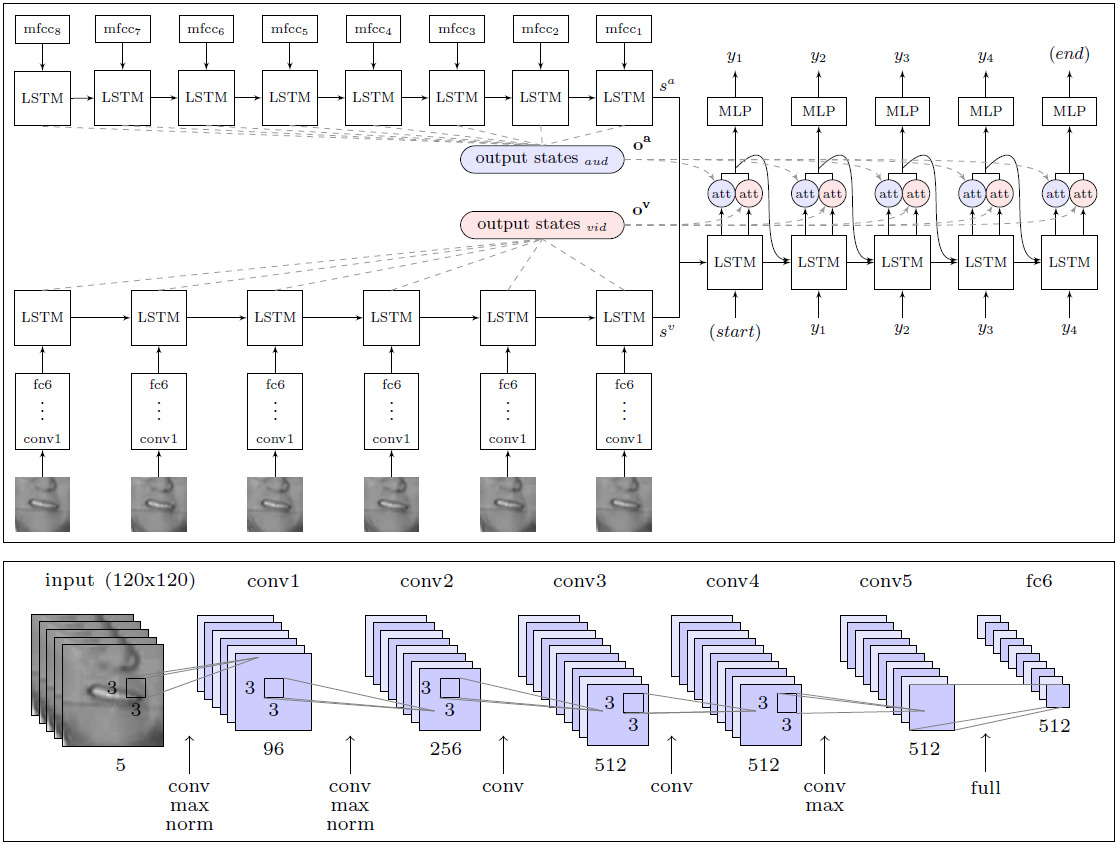 La arquitectura del módulo WLAS (Watch, Listen, Attend and Spell) y una red neuronal convolucional para leer los labios.El gran mérito de los investigadores radica en el hecho de que compilaron un gigantesco conjunto de datos para entrenar y probar el sistema con 17,500 palabras únicas. Después de todo, no se trata solo de cinco años de grabación continua de programas de televisión en inglés, sino también de una sincronización clara de video y sonido (en la televisión a menudo hay una sincronización de hasta 1 segundo, incluso en la televisión profesional en inglés), así como el desarrollo de un módulo para reconocimiento de voz, que se superpone en video y se usa para enseñar el sistema de lectura de labios (módulo WLAS, ver diagrama arriba).En el caso del rassynchron más leve, entrenar el sistema se vuelve prácticamente inútil, ya que el programa no puede determinar la correspondencia correcta de los sonidos y los movimientos de los labios. Después de un exhaustivo trabajo preparatorio, la capacitación del programa fue completamente automática: procesó de forma independiente los 5000 videos.Anteriormente, tal conjunto simplemente no existía, por lo tanto, los mismos autores de LipNet se vieron obligados a limitarse a la base GRID. Para crédito de los desarrolladores de DeepMind, prometieron publicar un conjunto de datos en el dominio público para entrenar a otras IA. Los colegas del equipo de desarrollo de LipNet ya han dicho que lo esperan con ansias.El trabajo científico se publica en el dominio público en el sitio web arXiv (arXiv: 1611.05358v1).Si los sistemas comerciales de lectura de labios aparecen en el mercado, la vida de la gente común será mucho más simple. Se puede suponer que tales sistemas se incorporarán de inmediato a televisores y otros electrodomésticos para mejorar el control por voz y el reconocimiento de voz casi sin errores.
La arquitectura del módulo WLAS (Watch, Listen, Attend and Spell) y una red neuronal convolucional para leer los labios.El gran mérito de los investigadores radica en el hecho de que compilaron un gigantesco conjunto de datos para entrenar y probar el sistema con 17,500 palabras únicas. Después de todo, no se trata solo de cinco años de grabación continua de programas de televisión en inglés, sino también de una sincronización clara de video y sonido (en la televisión a menudo hay una sincronización de hasta 1 segundo, incluso en la televisión profesional en inglés), así como el desarrollo de un módulo para reconocimiento de voz, que se superpone en video y se usa para enseñar el sistema de lectura de labios (módulo WLAS, ver diagrama arriba).En el caso del rassynchron más leve, entrenar el sistema se vuelve prácticamente inútil, ya que el programa no puede determinar la correspondencia correcta de los sonidos y los movimientos de los labios. Después de un exhaustivo trabajo preparatorio, la capacitación del programa fue completamente automática: procesó de forma independiente los 5000 videos.Anteriormente, tal conjunto simplemente no existía, por lo tanto, los mismos autores de LipNet se vieron obligados a limitarse a la base GRID. Para crédito de los desarrolladores de DeepMind, prometieron publicar un conjunto de datos en el dominio público para entrenar a otras IA. Los colegas del equipo de desarrollo de LipNet ya han dicho que lo esperan con ansias.El trabajo científico se publica en el dominio público en el sitio web arXiv (arXiv: 1611.05358v1).Si los sistemas comerciales de lectura de labios aparecen en el mercado, la vida de la gente común será mucho más simple. Se puede suponer que tales sistemas se incorporarán de inmediato a televisores y otros electrodomésticos para mejorar el control por voz y el reconocimiento de voz casi sin errores.Source: https://habr.com/ru/post/es399429/
All Articles