La red neuronal de Pix2pix colorea realista bocetos a lápiz y fotos en blanco y negro
 Cuatro ejemplos del programa, cuyo código se publica en el dominio público. Las imágenes de origen se muestran a la izquierda, el resultado del procesamiento automático a la derecha.Muchas tareas de procesamiento de imágenes, gráficos por computadora y visión por computadora pueden reducirse a la tarea de "traducir" una imagen (en la entrada) a otra (en la salida). Así como el mismo texto puede representarse en inglés o ruso, la imagen puede representarse en colores RGB, en gradientes, como un mapa de los límites de los objetos, un mapa de etiquetas semánticas, etc. Basado en el modelo de sistemas de traducción automática, los desarrolladores del Berkeley AI Research Laboratory (BAIR) de la Universidad de California en Berkeley crearon una aplicaciónpara transmitir automáticamente imágenes de una vista a otra. Por ejemplo, desde un boceto en blanco y negro hasta una imagen a todo color.Para una persona no informada, el trabajo de dicho programa parecerá mágico, pero se basa en un modelo de programa de redes de confrontación generativa condicional (cGAN), variedades del tipo conocido de redes de confrontación generativa (GAN).Los autores del trabajo científico escriben que la mayoría de los problemas que surgen al traducir imágenes están relacionados con la traducción de "muchos a uno" (visión por computadora - traducir fotos en mapas semánticos, segmentos, límites de objetos, etc.) o "uno a muchos" "(Gráficos por computadora: traducción de etiquetas o datos de entrada del usuario en imágenes realistas). Tradicionalmente, cada una de estas tareas se realiza mediante una aplicación especializada separada. En su trabajo, los autores intentaron crear un marco universal único para todos esos problemas. Y lo hicieron.Las redes neuronales convolucionales capacitadas para minimizar la función de pérdida son excelentes para transmitir imágenes., es decir, una medida de la discrepancia entre el valor verdadero del parámetro estimado y la estimación del parámetro. Aunque el entrenamiento en sí se lleva a cabo automáticamente, sin embargo, se requiere un trabajo manual significativo para minimizar efectivamente la función de pérdida. En otras palabras, aún necesitamos explicar y mostrar a las redes neuronales lo que específicamente necesita ser minimizado. Y aquí hay muchas dificultades que afectan negativamente el resultado, si trabajamos con una función de pérdida de bajo nivel como "minimizar la distancia euclidiana entre los píxeles predichos y reales", esto conducirá a la generación de imágenes borrosas.
Cuatro ejemplos del programa, cuyo código se publica en el dominio público. Las imágenes de origen se muestran a la izquierda, el resultado del procesamiento automático a la derecha.Muchas tareas de procesamiento de imágenes, gráficos por computadora y visión por computadora pueden reducirse a la tarea de "traducir" una imagen (en la entrada) a otra (en la salida). Así como el mismo texto puede representarse en inglés o ruso, la imagen puede representarse en colores RGB, en gradientes, como un mapa de los límites de los objetos, un mapa de etiquetas semánticas, etc. Basado en el modelo de sistemas de traducción automática, los desarrolladores del Berkeley AI Research Laboratory (BAIR) de la Universidad de California en Berkeley crearon una aplicaciónpara transmitir automáticamente imágenes de una vista a otra. Por ejemplo, desde un boceto en blanco y negro hasta una imagen a todo color.Para una persona no informada, el trabajo de dicho programa parecerá mágico, pero se basa en un modelo de programa de redes de confrontación generativa condicional (cGAN), variedades del tipo conocido de redes de confrontación generativa (GAN).Los autores del trabajo científico escriben que la mayoría de los problemas que surgen al traducir imágenes están relacionados con la traducción de "muchos a uno" (visión por computadora - traducir fotos en mapas semánticos, segmentos, límites de objetos, etc.) o "uno a muchos" "(Gráficos por computadora: traducción de etiquetas o datos de entrada del usuario en imágenes realistas). Tradicionalmente, cada una de estas tareas se realiza mediante una aplicación especializada separada. En su trabajo, los autores intentaron crear un marco universal único para todos esos problemas. Y lo hicieron.Las redes neuronales convolucionales capacitadas para minimizar la función de pérdida son excelentes para transmitir imágenes., es decir, una medida de la discrepancia entre el valor verdadero del parámetro estimado y la estimación del parámetro. Aunque el entrenamiento en sí se lleva a cabo automáticamente, sin embargo, se requiere un trabajo manual significativo para minimizar efectivamente la función de pérdida. En otras palabras, aún necesitamos explicar y mostrar a las redes neuronales lo que específicamente necesita ser minimizado. Y aquí hay muchas dificultades que afectan negativamente el resultado, si trabajamos con una función de pérdida de bajo nivel como "minimizar la distancia euclidiana entre los píxeles predichos y reales", esto conducirá a la generación de imágenes borrosas. El efecto de varias funciones de pérdida en el resultadoSería mucho más simple establecer redes neuronales con tareas de alto nivel como "generar una imagen indistinguible de la realidad", y luego entrenar automáticamente la red neuronal para minimizar la función de pérdida que mejor realiza la tarea. Así es como funcionan las redes de confrontación generativas (GAN), una de las áreas más prometedoras en el desarrollo de redes neuronales en la actualidad. La red GAN entrena la función de pérdida, cuya tarea es clasificar la imagen como "real" o "falsa", mientras entrena el modelo generativo para minimizar esta función. Aquí, las imágenes borrosas no se pueden producir de ninguna manera, ya que no pasarán la verificación de clasificación como "real".Los desarrolladores utilizaron redes de confrontación generativa condicional (cGAN) para la tarea, es decir, GAN con un parámetro condicional. Del mismo modo que la GAN asimila el modelo de datos generativos, cGAN asimila el modelo generativo bajo ciertas condiciones, lo que lo hace adecuado para transmitir imágenes "uno a uno".
El efecto de varias funciones de pérdida en el resultadoSería mucho más simple establecer redes neuronales con tareas de alto nivel como "generar una imagen indistinguible de la realidad", y luego entrenar automáticamente la red neuronal para minimizar la función de pérdida que mejor realiza la tarea. Así es como funcionan las redes de confrontación generativas (GAN), una de las áreas más prometedoras en el desarrollo de redes neuronales en la actualidad. La red GAN entrena la función de pérdida, cuya tarea es clasificar la imagen como "real" o "falsa", mientras entrena el modelo generativo para minimizar esta función. Aquí, las imágenes borrosas no se pueden producir de ninguna manera, ya que no pasarán la verificación de clasificación como "real".Los desarrolladores utilizaron redes de confrontación generativa condicional (cGAN) para la tarea, es decir, GAN con un parámetro condicional. Del mismo modo que la GAN asimila el modelo de datos generativos, cGAN asimila el modelo generativo bajo ciertas condiciones, lo que lo hace adecuado para transmitir imágenes "uno a uno". Transmita diseños de paisajes urbanos a fotos realistas. A la izquierda está el marcado, en el centro está el original, y a la derecha está la imagen generada.Enlos últimos dos años, se han descrito muchas aplicaciones GAN y la base teórica de su trabajo ha sido bien estudiada. Pero en todos estos trabajos, GAN se usa solo para tareas especializadas (por ejemplo, la generación de imágenes aterradoras o la generación de imágenes pornográficas)) No estaba del todo claro cómo la GAN es adecuada para la traducción eficiente de imágenes uno a uno. El objetivo principal de este trabajo es demostrar que dicha red neuronal es capaz de realizar una gran lista de diversas tareas, mostrando un resultado bastante aceptable.Por ejemplo, el color de los dibujos a lápiz en blanco y negro (columna izquierda) se ve muy bien, sobre la base de los cuales la red neuronal genera imágenes fotorrealistas (columna derecha). En algunos casos, el resultado de la operación de la red neuronal parece aún más realista que una fotografía real (la columna central, en comparación).
Transmita diseños de paisajes urbanos a fotos realistas. A la izquierda está el marcado, en el centro está el original, y a la derecha está la imagen generada.Enlos últimos dos años, se han descrito muchas aplicaciones GAN y la base teórica de su trabajo ha sido bien estudiada. Pero en todos estos trabajos, GAN se usa solo para tareas especializadas (por ejemplo, la generación de imágenes aterradoras o la generación de imágenes pornográficas)) No estaba del todo claro cómo la GAN es adecuada para la traducción eficiente de imágenes uno a uno. El objetivo principal de este trabajo es demostrar que dicha red neuronal es capaz de realizar una gran lista de diversas tareas, mostrando un resultado bastante aceptable.Por ejemplo, el color de los dibujos a lápiz en blanco y negro (columna izquierda) se ve muy bien, sobre la base de los cuales la red neuronal genera imágenes fotorrealistas (columna derecha). En algunos casos, el resultado de la operación de la red neuronal parece aún más realista que una fotografía real (la columna central, en comparación). Lanza bocetos a lápiz a fotos realistas. A la izquierda hay un dibujo a lápiz, en el centro está el original, y a la derecha hay una imagen generada.
Lanza bocetos a lápiz a fotos realistas. A la izquierda hay un dibujo a lápiz, en el centro está el original, y a la derecha hay una imagen generada.
 Traducción de bocetos a lápiz en fotos realistas.Como en otras redes generativas, en esta GAN las redes neuronales están en guerra entre ellas . Uno de ellos (el generador) está tratando de crear una imagen falsa para engañar al otro (discriminador). Con el tiempo, el generador aprende a engañar mejor al discriminador, es decir, generar imágenes más realistas. A diferencia de las GAN convencionales, en Pix2Pix, tanto el discriminador como el generador tienen acceso a la imagen original.
Traducción de bocetos a lápiz en fotos realistas.Como en otras redes generativas, en esta GAN las redes neuronales están en guerra entre ellas . Uno de ellos (el generador) está tratando de crear una imagen falsa para engañar al otro (discriminador). Con el tiempo, el generador aprende a engañar mejor al discriminador, es decir, generar imágenes más realistas. A diferencia de las GAN convencionales, en Pix2Pix, tanto el discriminador como el generador tienen acceso a la imagen original.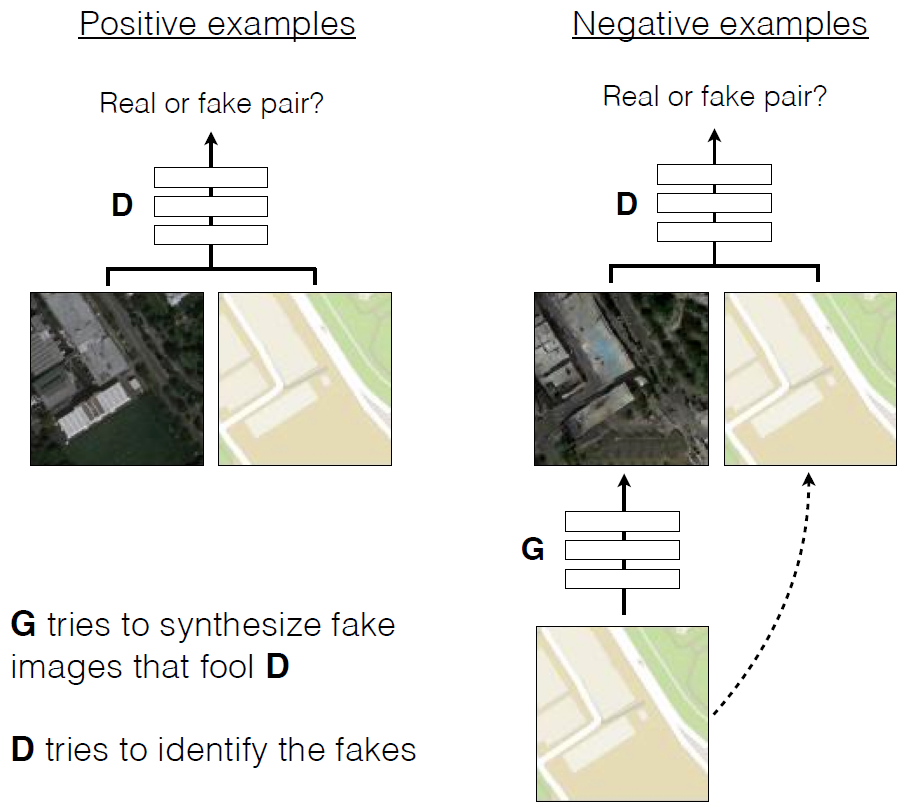 Capacitación de cGAN para predecir fotografías aéreas a partir de mapas de terreno
Capacitación de cGAN para predecir fotografías aéreas a partir de mapas de terreno Ejemplos del trabajo de cGAN en la traducción de fotografías aéreas en mapas de terreno y viceversa. Se publica unartículo científico en el dominio público, el código fuente de Pix2pix está en GitHub . Los autores ofrecen a todos experimentar el programa.
Ejemplos del trabajo de cGAN en la traducción de fotografías aéreas en mapas de terreno y viceversa. Se publica unartículo científico en el dominio público, el código fuente de Pix2pix está en GitHub . Los autores ofrecen a todos experimentar el programa.Source: https://habr.com/ru/post/es399469/
All Articles