 Un ejemplo de una red neuronal después del entrenamiento basado en caras de celebridades. A la izquierda está el conjunto inicial de imágenes de 8 × 8 píxeles en la entrada de la red neuronal, en el centro es el resultado de la interpolación de hasta 32 × 32 píxeles de acuerdo con la predicción del modelo. A la derecha hay fotografías reales de caras de celebridades, reducidas a 32 × 32, de las cuales se obtuvieron muestras para la columna izquierda.
Un ejemplo de una red neuronal después del entrenamiento basado en caras de celebridades. A la izquierda está el conjunto inicial de imágenes de 8 × 8 píxeles en la entrada de la red neuronal, en el centro es el resultado de la interpolación de hasta 32 × 32 píxeles de acuerdo con la predicción del modelo. A la derecha hay fotografías reales de caras de celebridades, reducidas a 32 × 32, de las cuales se obtuvieron muestras para la columna izquierda.¿Es posible aumentar la resolución de las fotos hasta el infinito? ¿Es posible generar imágenes creíbles basadas en 64 píxeles? La lógica sugiere que esto es imposible.
La nueva red neuronal de Google Brain piensa de manera diferente. Realmente eleva la resolución de las fotos a un nivel increíble.
Tal "sobre-resolución" no es una restauración de la imagen original de una copia de baja resolución. Esta es una síntesis de una fotografía creíble que
probablemente podría ser la imagen original. Este es un proceso probabilístico.
Cuando la tarea es "aumentar la resolución" de una fotografía, pero no hay detalles para mejorarla, la tarea del modelo es generar la imagen más plausible desde el punto de vista humano. A su vez, es imposible generar una imagen realista hasta que el modelo haya creado los contornos y haya tomado una decisión "decidida" sobre qué texturas, formas y patrones estarán presentes en diferentes partes de la imagen.
Por ejemplo, solo mire el KDPV, donde en la columna izquierda hay imágenes de prueba reales para la red neuronal. Carecen de detalles de piel y cabello. De ninguna manera pueden restaurarse mediante métodos de interpolación tradicionales como lineal o bicúbico. Sin embargo, si primero tiene un conocimiento profundo sobre toda la diversidad de caras y sus contornos típicos (y sabe que es necesario aumentar la resolución de la cara aquí), entonces la red neuronal puede lograr algo fantástico, y "dibujar" los detalles faltantes que es más probable que estén allí.
Los especialistas de Google Brain han publicado el artículo científico
Recursive Pixel Super Resolution, que describe un modelo totalmente probabilístico entrenado en un conjunto de fotografías de alta resolución y sus copias reducidas de 8 × 8 para generar imágenes de 32 × 32 a partir de pequeñas muestras de 8 × 8.
El modelo consta de dos componentes que se entrenan simultáneamente: una red neuronal de acondicionamiento y una red anterior. El primero de ellos superpone efectivamente una imagen de baja resolución en la distribución de las imágenes de alta resolución correspondientes, y el segundo modela detalles de alta resolución para hacer que la versión final sea más realista. Una red neuronal con aire acondicionado consta de unidades
ResNet , y la anterior es una arquitectura
PixelCNN .
Esquemáticamente, el modelo se representa en la ilustración.
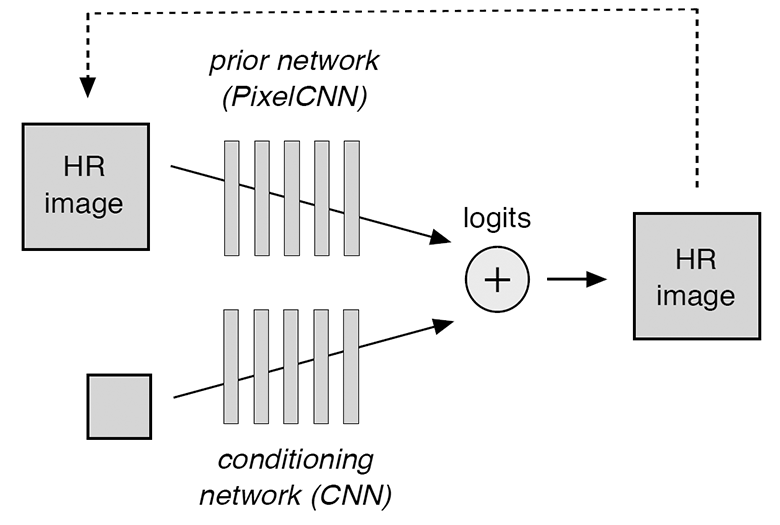
Una red neuronal convolucional condicionada recibe imágenes de baja resolución en la entrada y produce logits, valores que predicen la probabilidad de logit condicional para cada píxel en una imagen de alta resolución. A su vez, la red neuronal convolucional previa realiza predicciones basadas en predicciones aleatorias previas (indicadas por una línea discontinua en el diagrama). La distribución de probabilidad para todo el modelo se calcula como un operador softmax sobre la suma de dos conjuntos de logits de una red neuronal condicionada y anterior.
Pero, ¿cómo evaluar la calidad de dicha red? Los autores del trabajo científico llegaron a la conclusión de que las métricas estándar como la señal pico a la relación de ruido (pSNR) y la similitud estructural (SSIM) no pueden evaluar correctamente la calidad de la predicción para tales problemas de aumento súper fuerte en la resolución. Según estas métricas, resulta que el mejor resultado son imágenes borrosas, no imágenes fotorrealistas en las que los detalles claros y creíbles no coinciden en el lugar de colocación con los detalles claros de la imagen real. Es decir, estas métricas pSNR y SSIM son extremadamente conservadoras. Los estudios han demostrado que las personas pueden distinguir fácilmente las fotos reales de las opciones borrosas creadas por métodos de regresión, pero no les resulta tan fácil distinguir entre las muestras generadas por una red neuronal de las fotos reales.
Veamos qué resultados muestra el modelo desarrollado por Google Brain y entrenado en un conjunto de 200,000 caras de celebridades (conjunto de fotos CelebA) y 2,000,000 dormitorios (conjunto de fotos de dormitorios LSUN). En todos los casos, las fotos antes de entrenar el sistema se redujeron a un tamaño de 32 × 32 píxeles, y luego nuevamente a 8 × 8 utilizando el método de interpolación bicúbico. Redes neuronales TensorFlow formadas en 8 GPU.
Los resultados se compararon en dos bases principales: 1) regresión independiente de píxel por píxel (Regresión) con una arquitectura similar a la red neuronal
SRResNet , que muestra resultados sobresalientes en métricas estándar para evaluar la calidad de la interpolación; 2) busque el elemento vecino más cercano (NN), que busca en la base de datos de muestras educativas de baja resolución la imagen más similar por la proximidad de píxeles en el espacio euclidiano, y luego devuelve la imagen de alta resolución correspondiente a partir de la cual se generó esta muestra educativa.
Cabe señalar que el modelo probabilístico produce resultados de diferente calidad, dependiendo de la temperatura softmax. Se estableció manualmente que los valores óptimos
tau mienten entre 1.1 y 1.3. Pero incluso si instalas
tau=1.2 entonces de todos modos los resultados serán diferentes cada vez.
 Diferentes resultados al iniciar un modelo con temperatura softmax tau=1.2
Diferentes resultados al iniciar un modelo con temperatura softmax tau=1.2Puede evaluar la calidad del trabajo del modelo probabilístico mediante las muestras bajo el spoiler.
Comparación de resultados de dormitorios Comparación de resultados de caras de famosos Para verificar el realismo de los resultados, los científicos realizaron una encuesta de crowdsourcing. A los participantes se les mostraron dos fotografías: una real, y la segunda generada por varios métodos a partir de una copia reducida de 8 × 8 y se les pidió que indicaran qué fotografía fue tomada por la cámara.
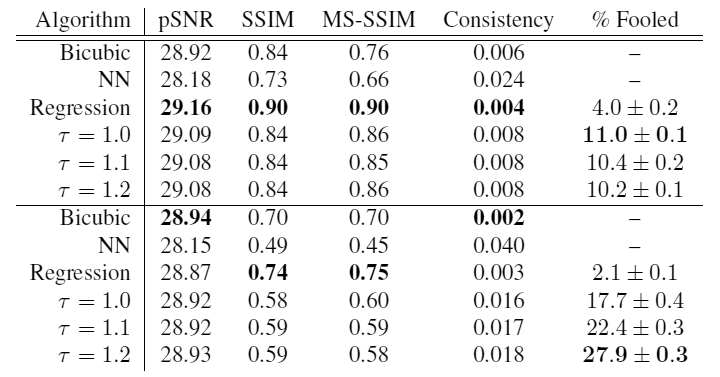
En la parte superior de la tabla están los resultados para la base de celebridades, y debajo para las habitaciones. Como puedes ver, a temperatura
tau=1.2 En las fotografías de las habitaciones, el modelo mostró el máximo resultado: ¡en el 27,9% de los casos, su entrega resultó ser más realista que la imagen real! Este es un claro éxito.
La siguiente ilustración muestra el trabajo más exitoso de la red neuronal, en el que "venció" a los originales en términos de realismo. Por objetividad, y algunas de las peores.

En el campo de la generación de imágenes fotorrealistas utilizando redes neuronales, ahora se observa un desarrollo muy rápido. En 2017, sin duda escucharemos muchas noticias sobre este tema.