
Hoy, el gráfico es una de las formas más aceptables para describir los modelos creados en el sistema de aprendizaje automático. Estos gráficos computacionales están compuestos por vértices neuronales conectados por bordes de sinapsis que describen las conexiones entre vértices.
A diferencia de un procesador escalar central o de gráficos vectoriales, IPU, un nuevo tipo de procesador diseñado para el aprendizaje automático, le permite construir tales gráficos. Una computadora diseñada para la gestión de gráficos es una máquina ideal para modelos de gráficos computacionales creados como parte del aprendizaje automático.
Una de las formas más fáciles de describir cómo funciona la inteligencia artificial es visualizarla. El equipo de desarrollo de Graphcore ha creado una colección de estas imágenes que se muestran en la UIP. La base fue el software Poplar, que visualiza el trabajo de la inteligencia artificial. Los investigadores de esta compañía también descubrieron por qué las redes profundas requieren tanta memoria y qué soluciones existen.
Poplar incluye un compilador gráfico que se creó desde cero para traducir las operaciones estándar utilizadas como parte del aprendizaje automático en código de aplicación altamente optimizado para IPU. Le permite recopilar estos gráficos en el mismo principio que se ensamblan los POPNN. La biblioteca contiene un conjunto de diferentes tipos de vértices para primitivas generalizadas.
Los gráficos son el paradigma en el que se basa todo el software. En Poplar, los gráficos le permiten definir el proceso de cálculo, donde los vértices realizan operaciones y los bordes describen la relación entre ellos. Por ejemplo, si desea agregar dos números juntos, puede definir un vértice con dos entradas (los números que desea agregar), algunos cálculos (la función de sumar dos números) y la salida (resultado).
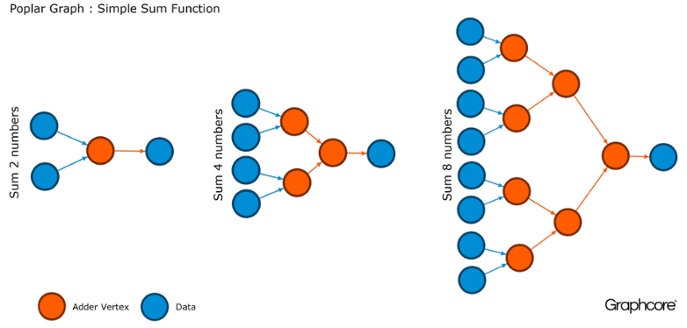
Por lo general, las operaciones de vértice son mucho más complicadas que en el ejemplo descrito anteriormente. A menudo se definen por pequeños programas llamados codelets (nombres de código). La abstracción gráfica es atractiva porque no hace suposiciones sobre la estructura de los cálculos y descompone el cálculo en componentes que el procesador de la IPU puede usar para trabajar.
Poplar utiliza esta simple abstracción para construir gráficos muy grandes que se representan como imágenes. La generación programática del gráfico significa que podemos adaptarlo a los cálculos específicos necesarios para garantizar el uso más eficiente de los recursos de la UIP.
El compilador traduce las operaciones estándar utilizadas en los sistemas de aprendizaje automático en código de aplicación altamente optimizado para IPU. Un compilador de gráficos crea una imagen intermedia de un gráfico computacional que se implementa en uno o más dispositivos de IPU. El compilador puede mostrar este gráfico computacional, por lo que una aplicación escrita en el nivel de estructura de la red neuronal muestra una imagen del gráfico computacional que se ejecuta en la IPU.
 Gráfico de aprendizaje de ciclo completo de AlexNet hacia adelante y hacia atrás
Gráfico de aprendizaje de ciclo completo de AlexNet hacia adelante y hacia atrásEl compilador gráfico Poplar convirtió
la descripción
de AlexNet en un gráfico computacional de 18,7 millones de vértices y 115,8 millones de aristas. La agrupación claramente visible es el resultado de una fuerte conexión entre los procesos en cada capa de la red con una conexión más fácil entre los niveles.
Otro ejemplo es una red simple con conectividad completa, capacitada en
MNIST : un conjunto de datos simple para visión por computadora, una especie de "Hola, mundo" en el aprendizaje automático. Una red simple para explorar este conjunto de datos ayuda a comprender los gráficos controlados por las aplicaciones de Poplar. Al integrar bibliotecas de gráficos con entornos como TensorFlow, la compañía proporciona una de las formas más fáciles de usar las IPU en aplicaciones de aprendizaje automático.
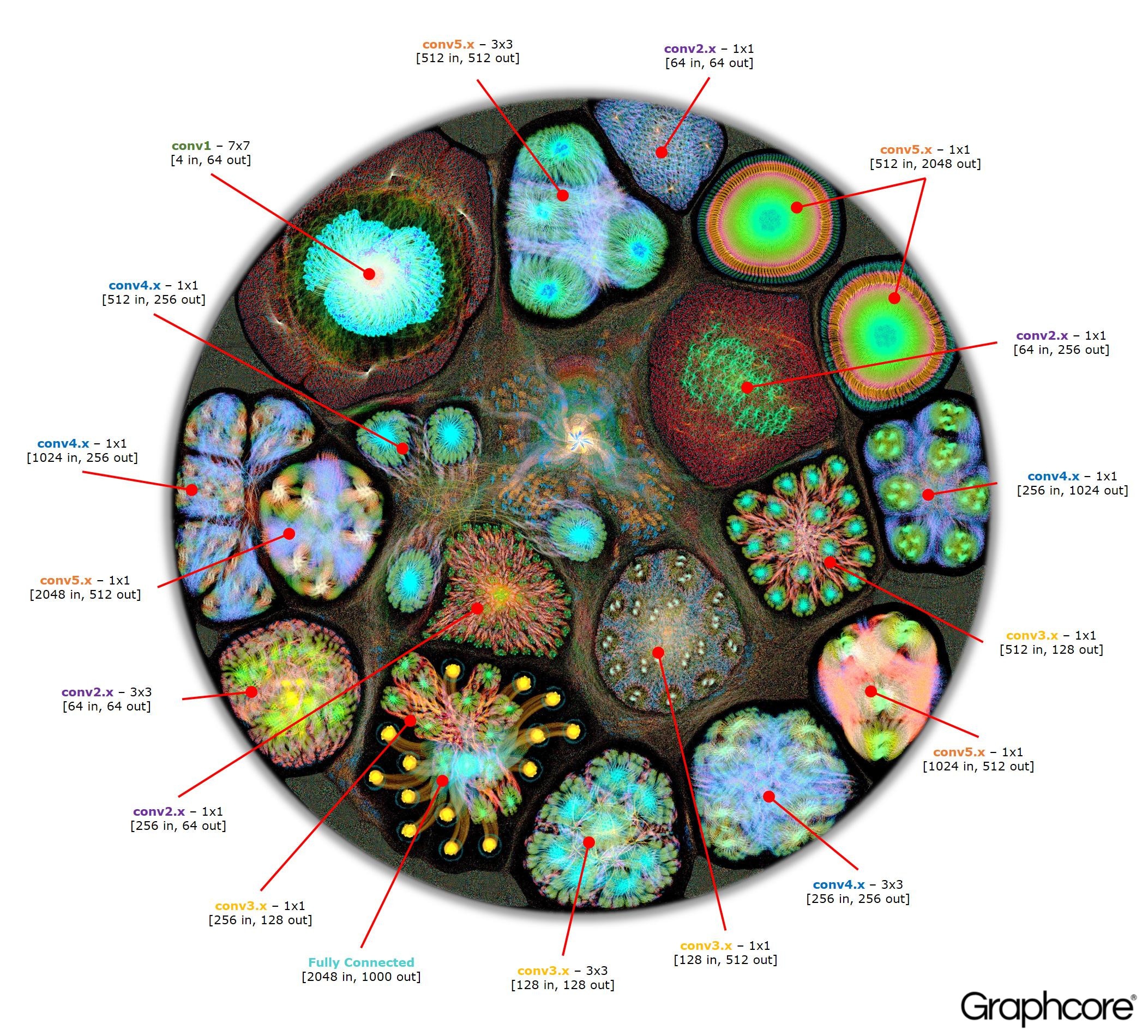
Una vez que el gráfico se construye con el compilador, debe ejecutarse. Esto es posible usando Graph Engine. Usando ResNet-50 como ejemplo, se demuestra su funcionamiento.
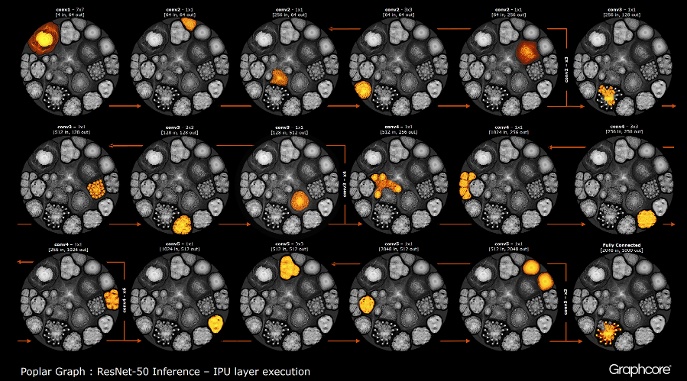 Count ResNet-50
Count ResNet-50La arquitectura ResNet-50 le permite crear redes profundas a partir de particiones repetitivas. El procesador solo necesita determinar estas particiones una vez y volver a llamarlas. Por ejemplo, un clúster de nivel conv4 se ejecuta seis veces, pero solo una vez se aplica al gráfico. La imagen también muestra la variedad de formas de capas convolucionales, ya que cada una de ellas tiene un gráfico construido de acuerdo con la forma natural de cálculo.
El motor crea y controla la ejecución de un modelo de aprendizaje automático utilizando un gráfico creado por el compilador. Una vez implementado, Graph Engine monitorea y responde a las IPU o dispositivos utilizados por las aplicaciones.
La imagen ResNet-50 muestra el modelo completo. En este nivel, es difícil distinguir entre vértices individuales, por lo que debe mirar imágenes ampliadas. Los siguientes son algunos ejemplos de secciones dentro de capas de una red neuronal.


¿Por qué las redes profundas necesitan tanta memoria?
Grandes cantidades de memoria ocupada es uno de los mayores problemas de las redes neuronales profundas. Los investigadores están tratando de lidiar con el ancho de banda limitado de los dispositivos DRAM, que deberían ser utilizados por los sistemas modernos para almacenar una gran cantidad de pesos y activaciones en una red neuronal profunda.
Las arquitecturas se desarrollaron utilizando chips de procesador diseñados para el procesamiento secuencial y la optimización de DRAM para memoria de alta densidad. La interfaz entre los dos dispositivos es un cuello de botella que introduce limitaciones de ancho de banda y agrega una sobrecarga significativa al consumo de energía.
Aunque todavía no tenemos una imagen completa del cerebro humano y cómo funciona, en general está claro que no hay una gran instalación de almacenamiento separada para la memoria. Se cree que la función de la memoria a largo y corto plazo en el cerebro humano está incrustada en la estructura de las neuronas + sinapsis. Incluso los organismos simples como los
gusanos con una estructura neuronal del cerebro, que consta de poco más de 300 neuronas,
tienen algún grado de función de memoria.
Construir memoria en procesadores convencionales es una forma de sortear los cuellos de botella de la memoria abriendo un gran ancho de banda con mucho menos consumo de energía. Sin embargo, la memoria en un chip es algo costoso que no está diseñado para cantidades realmente grandes de memoria, que están conectadas a los procesadores centrales y gráficos que se utilizan actualmente para la preparación y despliegue de redes neuronales profundas.
Por lo tanto, es útil observar cómo se usa la memoria hoy en día en unidades centrales de procesamiento y sistemas de aprendizaje profundo en aceleradores gráficos y preguntarse: ¿por qué necesitan dispositivos de almacenamiento de memoria tan grandes cuando el cerebro humano funciona bien sin ellos?
Las redes neuronales necesitan memoria para almacenar datos de entrada, parámetros de peso y funciones de activación, ya que la entrada se distribuye a través de la red. En el entrenamiento, la activación en la entrada debe conservarse hasta que pueda usarse para calcular los errores de los gradientes en la salida.
Por ejemplo, una red ResNet de 50 capas tiene aproximadamente 26 millones de parámetros de ponderación y calcula 16 millones de activaciones hacia adelante. Si usa un número de coma flotante de 32 bits para almacenar cada peso y activación, esto requerirá aproximadamente 168 MB de espacio. Usando un valor de precisión más bajo para almacenar estas escalas y activaciones, podríamos reducir a la mitad o incluso cuadruplicar este requisito de almacenamiento.
Un problema grave de memoria surge del hecho de que las GPU se basan en datos representados como vectores densos. Por lo tanto, pueden usar una sola secuencia de instrucciones (SIMD) para lograr computación de alta densidad. El procesador central utiliza bloques de vectores similares para la informática de alto rendimiento.
En las GPU, la sinapsis tiene 1024 bits de ancho, por lo que utilizan datos de coma flotante de 32 bits, por lo que a menudo los dividen en un mini lote paralelo de 32 muestras para crear vectores de datos de 1024 bits. Este enfoque para organizar el paralelismo vectorial aumenta el número de activaciones en 32 veces y la necesidad de almacenamiento local con una capacidad de más de 2 GB.
Las GPU y otras máquinas diseñadas para álgebra matricial también están sujetas a la carga de memoria de los pesos o las activaciones de la red neuronal. Las GPU no pueden realizar convoluciones pequeñas de manera eficiente en redes neuronales profundas. Por lo tanto, una transformación llamada "downgrade" se usa para convertir estas convoluciones en multiplicaciones matriz-matriz (GEMM), que los aceleradores gráficos pueden manejar de manera efectiva.
También se requiere memoria adicional para almacenar datos de entrada, valores de tiempo e instrucciones del programa. La medición del uso de memoria al entrenar ResNet-50 en una GPU de alto rendimiento ha demostrado que requiere más de 7,5 GB de DRAM local.
Quizás alguien decida que una precisión menor puede reducir la cantidad de memoria necesaria, pero ese no es el caso. Cuando cambia los valores de los datos a la mitad de precisión para pesos y activaciones, completa solo la mitad del ancho del vector del SIMD, gastando la mitad de los recursos informáticos disponibles. Para compensar esto, cuando cambie de precisión completa a media precisión en la GPU, tendrá que duplicar el tamaño del mini lote para causar suficiente paralelismo de datos para usar todos los cálculos disponibles. Por lo tanto, la transición a escalas de menor precisión y activaciones en la GPU aún requiere más de 7.5GB de memoria dinámica con acceso libre.
Con tantos datos para almacenar, es simplemente imposible encajar todo esto en la GPU. En cada capa de la red neuronal convolucional, es necesario guardar el estado de la DRAM externa, cargar la siguiente capa de red y luego cargar los datos en el sistema. Como resultado, la interfaz de memoria externa, ya limitada por el ancho de banda de la memoria, sufre la carga adicional de recargar constantemente la balanza, así como guardar y recuperar funciones de activación. Esto ralentiza significativamente el tiempo de entrenamiento y aumenta significativamente el consumo de energía.
Hay varias soluciones a este problema. En primer lugar, las operaciones como las funciones de activación se pueden realizar "in situ", lo que le permite sobrescribir la entrada directamente a la salida. Por lo tanto, la memoria existente se puede reutilizar. En segundo lugar, se puede obtener la oportunidad de reutilizar la memoria analizando la dependencia de los datos entre las operaciones en la red y la distribución de la misma memoria para las operaciones que no la están utilizando en este momento.
El segundo enfoque es especialmente efectivo cuando se puede analizar toda la red neuronal en la etapa de compilación para crear una memoria asignada fija, ya que los costos de administración de memoria se reducen a casi cero. Resultó que una combinación de estos métodos reduce el uso de memoria de la red neuronal de dos a tres veces.
Un tercer enfoque significativo fue descubierto recientemente por el equipo de Baidu Deep Speech. Aplicaron varios métodos de ahorro de memoria para obtener una reducción de 16 veces en el consumo de memoria mediante funciones de activación, lo que les permitió entrenar redes con 100 capas. Anteriormente, con la misma cantidad de memoria, podían entrenar redes con nueve capas.
La combinación de recursos de memoria y procesamiento en un dispositivo tiene un potencial significativo para aumentar la productividad y la eficiencia de las redes neuronales convolucionales, así como otras formas de aprendizaje automático. Puede hacer un compromiso entre la memoria y los recursos informáticos para equilibrar las capacidades y el rendimiento del sistema.
Las redes neuronales y los modelos de conocimiento en otros métodos de aprendizaje automático se pueden considerar como gráficos matemáticos. En estos gráficos, se concentra una gran cantidad de paralelismo. Un procesador paralelo diseñado para utilizar la simultaneidad en los gráficos no se basa en mini lotes y puede reducir significativamente la cantidad de almacenamiento local requerido.
Los resultados de la investigación moderna han demostrado que todos estos métodos pueden mejorar significativamente el rendimiento de las redes neuronales. Los gráficos modernos y las unidades de procesamiento central tienen memoria interna muy limitada, solo unos pocos megabytes en total. Las nuevas arquitecturas de procesador específicamente diseñadas para el aprendizaje automático proporcionan un equilibrio entre la memoria y la computación en chip, proporcionando un aumento significativo en el rendimiento y la eficiencia en comparación con las modernas unidades de procesamiento central y aceleradores gráficos.