
Hace cuatro años, Google se dio cuenta del potencial real de usar redes neuronales en sus aplicaciones. Luego comenzó a presentarlos en todas partes: en traducción de texto, búsqueda por voz con reconocimiento de voz, etc. Pero de inmediato quedó claro que el uso de redes neuronales aumenta en gran medida la carga en los servidores de Google. En términos generales, si todos realizaran una búsqueda por voz en Android (o dictaran texto con reconocimiento de voz) durante solo tres minutos al día, Google tendría que duplicar el número de centros de datos (!) Solo para que las redes neuronales procesen tal cantidad de tráfico de voz.
Había que hacer algo, y Google encontró una solución. En 2015, desarrolló su propia arquitectura de hardware para el aprendizaje automático (Tensor Processing Unit, TPU), que es hasta 70 veces más rápido que las GPU y CPU tradicionales en términos de rendimiento y hasta 196 veces más en términos de la cantidad de cálculos por vatio. Las GPU / CPU tradicionales se refieren a procesadores de propósito general Xeon E5 v3 (Haswell) y GPU Nvidia Tesla K80.
La arquitectura de TPU se describió por primera vez esta semana en un
documento científico (pdf) que se presentará en el 44 ° Simposio Internacional sobre Arquitecturas de Computadoras (ISCA), 26 de junio de 2017 en Toronto. Un destacado autor de más de 70 autores de este trabajo científico,
un destacado ingeniero Norman Jouppi, conocido como uno de los creadores del procesador MIPS, en
una entrevista con
The Next Platform, explicó en sus propias palabras las características de la arquitectura única de TPU, que en realidad es un ASIC especializado, es decir. circuito integrado para fines especiales.
A diferencia de los FPGA convencionales o ASIC altamente especializados, los módulos de TPU se programan de la misma manera que una GPU o CPU; no es un equipo de rango estrecho para una sola red neuronal. Norman Yuppy dice que TPU admite instrucciones CISC para diferentes tipos de redes neuronales: redes neuronales convolucionales, modelos LSTM y modelos grandes y totalmente conectados. Para que siga siendo programable, solo utiliza la matriz como primitiva, y no primitivas vectoriales o escalares.
Google enfatiza que mientras otros desarrolladores están optimizando sus microchips para redes neuronales convolucionales, tales redes neuronales proporcionan solo el 5% de la carga en los centros de datos de Google. La mayoría de las aplicaciones de Google usan los
perceptrones multicapa Rumelhart , por lo que era tan importante crear una arquitectura más universal que no se "afilara" solo para redes neuronales convolucionales.
 Uno de los elementos de la arquitectura es el motor de flujo de datos sistólico, una matriz de 256 × 256, que recibe la activación (pesos) de las neuronas de la izquierda, y luego todo cambia paso a paso, multiplicado por los pesos en la célula. Resulta que la matriz sistólica realiza 65 536 cálculos por ciclo. Esta arquitectura es ideal para redes neuronales.
Uno de los elementos de la arquitectura es el motor de flujo de datos sistólico, una matriz de 256 × 256, que recibe la activación (pesos) de las neuronas de la izquierda, y luego todo cambia paso a paso, multiplicado por los pesos en la célula. Resulta que la matriz sistólica realiza 65 536 cálculos por ciclo. Esta arquitectura es ideal para redes neuronales.Según Uppy, la arquitectura de las TPU es más similar al coprocesador de FPU que a una GPU normal, aunque numerosas matrices para la multiplicación no almacenan ningún programa en sí mismas, simplemente ejecutan instrucciones recibidas del host.
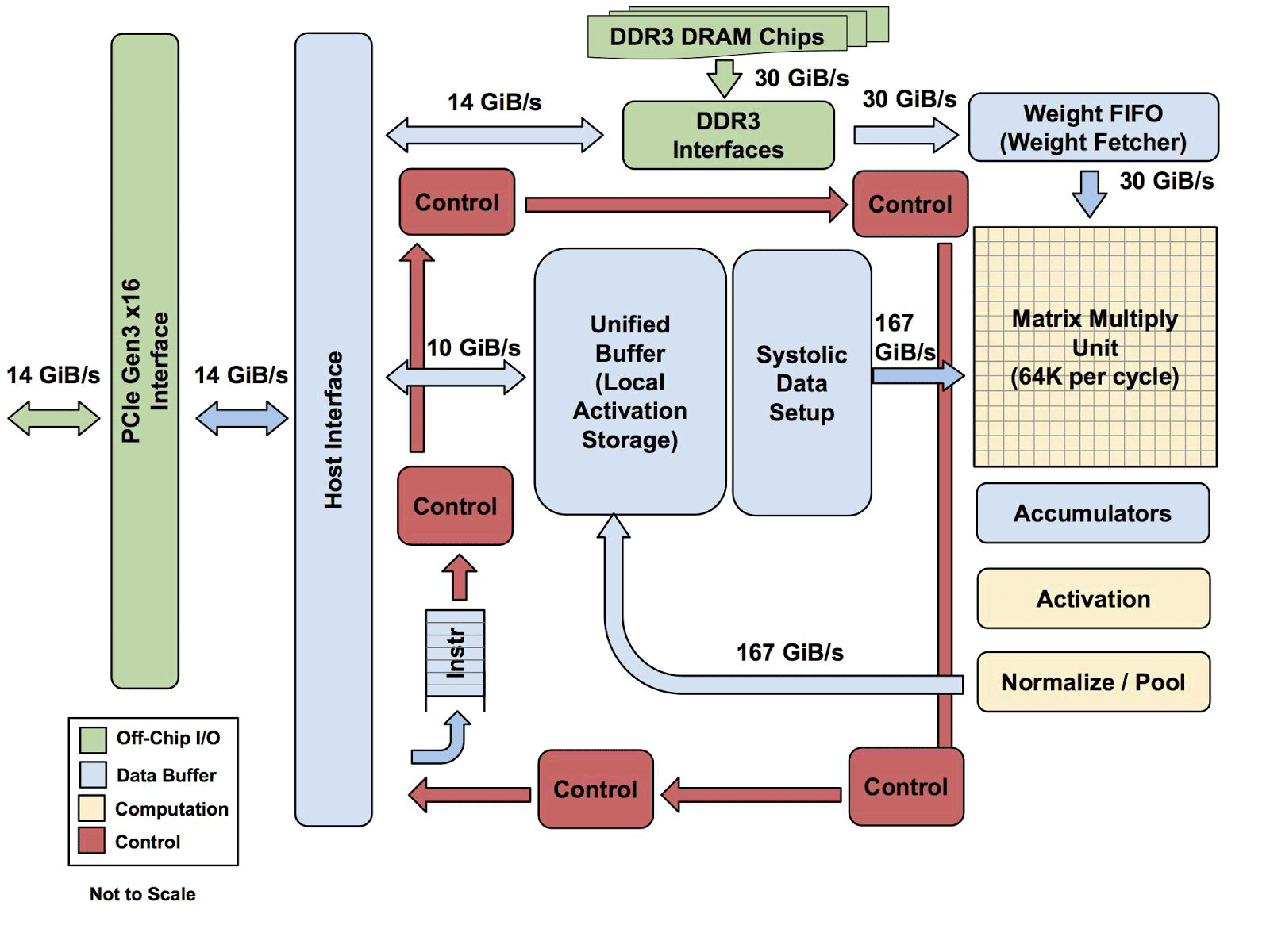 Toda la arquitectura TPU con la excepción de la memoria DDR3. Las instrucciones se envían desde el host (izquierda) a la cola. Luego, la lógica de control, dependiendo de la instrucción, puede ejecutar cada uno de ellos repetidamente
Toda la arquitectura TPU con la excepción de la memoria DDR3. Las instrucciones se envían desde el host (izquierda) a la cola. Luego, la lógica de control, dependiendo de la instrucción, puede ejecutar cada uno de ellos repetidamenteTodavía no se sabe cuán escalable es esta arquitectura. Yuppy dice que en un sistema con este tipo de host siempre habrá algún tipo de cuello de botella.
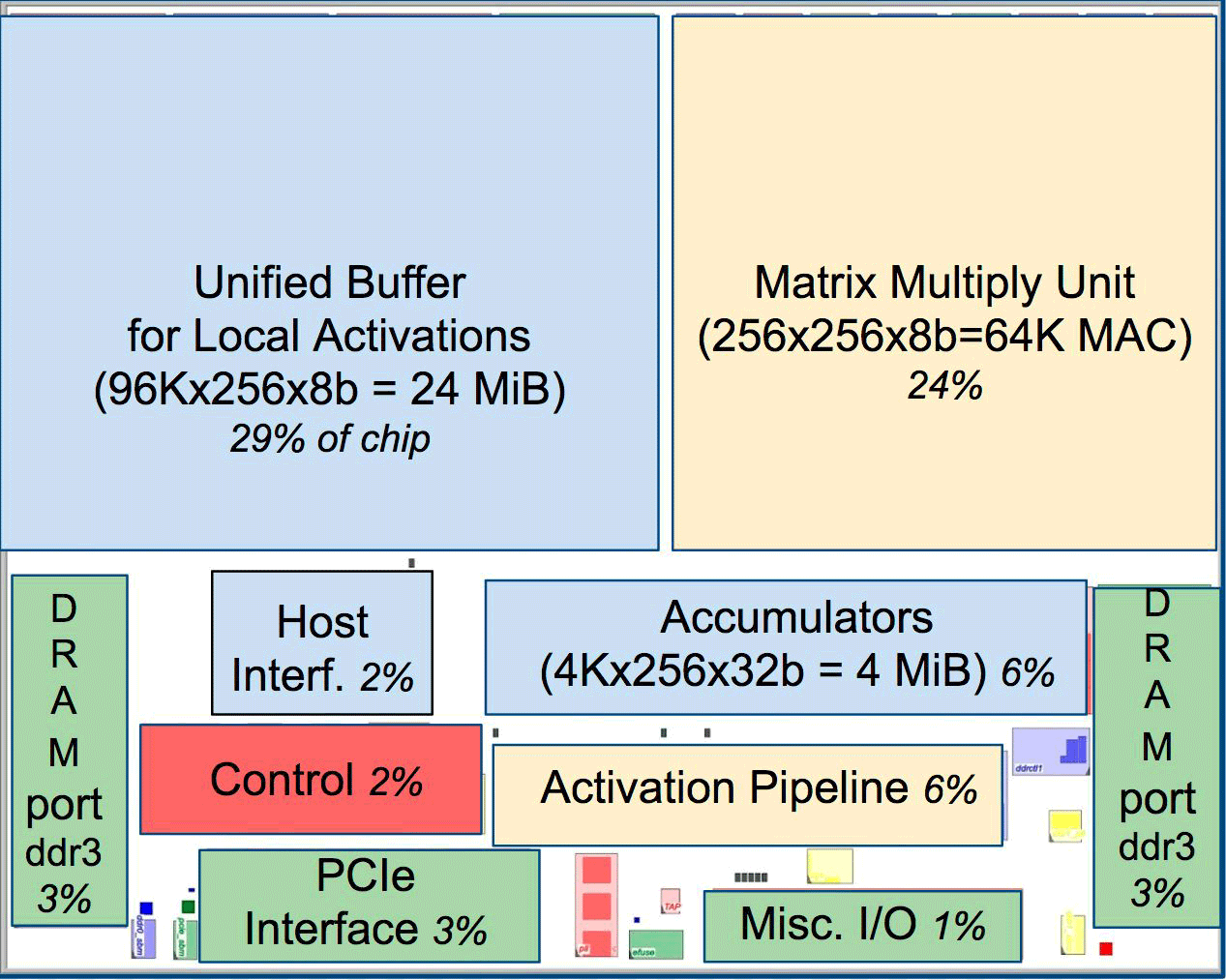
En comparación con las CPU y GPU convencionales, la arquitectura de máquina de Google las supera en diez veces. Por ejemplo, un procesador Haswell Xeon E5-2699 v3 con 18 núcleos a una frecuencia de reloj de 2.3 GHz con un punto flotante de 64 bits realiza 1.3 operaciones tera por segundo (TOPS) y muestra una velocidad de transferencia de datos de 51 GB / s. En este caso, el chip en sí consume 145 vatios y todo el sistema con 256 GB de memoria: 455 vatios.
A modo de comparación, TPU en operaciones de 8 bits con 256 GB de memoria externa y 32 GB de memoria interna demuestra la velocidad de intercambio con memoria de 34 GB / s, pero al mismo tiempo la tarjeta realiza 92 TOPS, es decir, aproximadamente 71 veces más que el procesador Haswell. El consumo de energía del servidor en TPU es de 384 vatios.
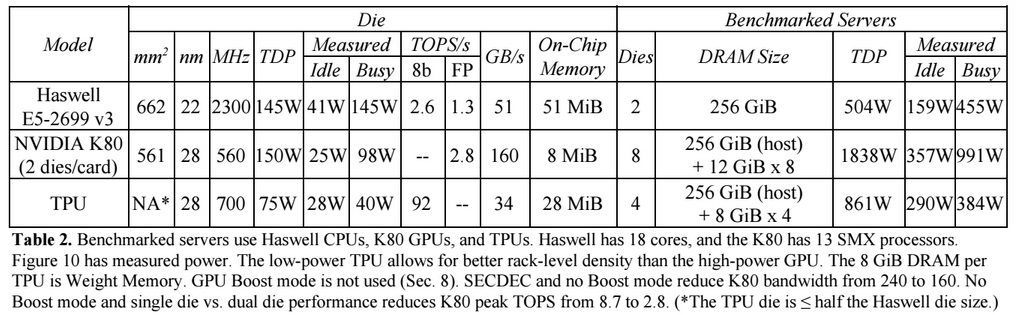
El siguiente gráfico compara el rendimiento relativo por vatio de un servidor con una GPU (columna azul), un servidor en TPU (rojo) en relación con un servidor en la CPU. También compara el rendimiento relativo por vatio del servidor con el TPU en relación con el servidor en la GPU (naranja) y la versión mejorada de TPU en relación con el servidor en la CPU (verde) y el servidor en la GPU (púrpura).

Cabe señalar que Google hizo comparaciones en las pruebas de aplicaciones en TensorFlow con la versión anterior relativa de Haswell Xeon, mientras que en la versión más reciente de Broadwell Xeon E5 v4 el número de instrucciones por ciclo aumentó en un 5% debido a mejoras arquitectónicas, y en la versión de Skylake Xeon E5 v5 , que se espera para el verano, el número de instrucciones por ciclo puede aumentar en otro 9-10%. Y con el aumento en el número de núcleos de 18 a 28 en Skylake, el rendimiento general de los procesadores Intel en las pruebas de Google puede mejorar en un 80%. Pero aun así, habrá una gran diferencia de rendimiento con TPU. En la versión de la prueba con punto flotante de 32 bits, la diferencia entre TPU y CPU se reduce a aproximadamente 3,5 veces. Pero la mayoría de los modelos se cuantizan perfectamente a 8 bits.
Google pensó en cómo usar GPU, FPGA y ASIC en sus centros de datos desde 2006, pero no los encontró hasta la última vez que introdujo el aprendizaje automático para una serie de tareas prácticas, y la carga en estas redes neuronales comenzó a crecer con miles de millones de solicitudes de los usuarios. Ahora la compañía no tiene más remedio que alejarse de las CPU tradicionales.
La compañía no planea vender sus procesadores a nadie, pero espera que el trabajo científico con el ASIC 2015 permita a otros mejorar la arquitectura y crear versiones mejoradas del ASIC que "elevarán el listón aún más". Google probablemente ya esté trabajando en una nueva versión de ASIC.