Solo piense, ¿cuál es la potencia informática total de todos los teléfonos inteligentes del mundo? Este es un gran recurso informático que incluso puede emular el trabajo del cerebro humano. Tal recurso no puede estar inactivo, inactivo, quemando estúpidamente kilovatios de energía en las salas de chat y en las redes sociales. Si le da estos recursos informáticos a una única IA mundial distribuida, e incluso le proporciona datos de los teléfonos inteligentes de los usuarios, para capacitación, ese sistema puede dar un salto cuántico en esta área.
Los métodos estándar de aprendizaje automático requieren que el conjunto de datos para entrenar el modelo ("primario") se recopile en un solo lugar: en una computadora, servidor o en un centro de datos o nube. A partir de aquí, es llevado por un modelo que está capacitado en estos datos. En el caso de un grupo de computadoras en el centro de datos, se utiliza el
método de Descenso de gradiente estocástico (SGD), un algoritmo de optimización que se ejecuta constantemente en partes de un conjunto de datos distribuidos de manera homogénea en los servidores de la nube.
Google, Apple, Facebook, Microsoft y otros jugadores de IA han estado haciendo eso durante mucho tiempo: recopilan datos, a veces confidenciales, de las computadoras y teléfonos inteligentes de los usuarios en un único almacenamiento (presumiblemente) seguro en el que se entrenan sus redes neuronales.
Ahora los científicos de Google Research han propuesto una adición interesante a este método estándar de aprendizaje automático. Propusieron un enfoque innovador llamado aprendizaje federado. ¡Permite que todos los dispositivos que participan en el aprendizaje automático compartan un solo modelo para el pronóstico, pero
no compartan datos primarios para el entrenamiento del modelo !
Este enfoque inusual, tal vez, reduce la efectividad del aprendizaje automático (aunque esto no es un hecho), pero reduce significativamente los costos de Google para mantener los centros de datos. ¿Por qué una empresa invertiría grandes cantidades de dinero en su equipo si tiene miles de millones de dispositivos Android en todo el mundo que pueden compartir la carga? Los usuarios pueden estar contentos con tal carga, porque de ese modo ayudan a hacer mejores servicios que ellos mismos usan. Y protegen sus datos confidenciales sin enviarlos al centro de datos.
Google enfatiza que en este caso no se trata solo del hecho de que el modelo ya entrenado se ejecuta directamente en el dispositivo del usuario, como sucede en la
API de Mobile Vision y los servicios de
respuesta inteligente en el dispositivo . No, se trata de un
entrenamiento modelo que se lleva a cabo en los dispositivos finales.
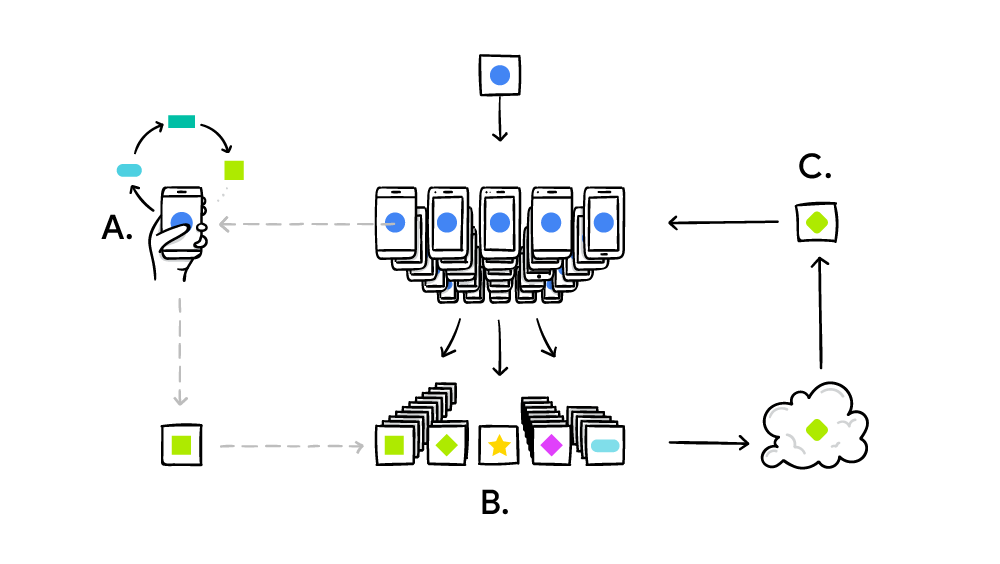
El sistema de aprendizaje federado funciona de acuerdo con el principio estándar de la informática distribuida, como SETI @ Home, cuando millones de computadoras resuelven un gran problema complejo. En el caso de SETI @ Home, fue una búsqueda de anomalías en la señal de radio desde el espacio en todo el ancho del espectro. Y en el caso del aprendizaje automático federado, Google está perfeccionando un modelo único y común de IA (hasta ahora) débil. En la práctica, el ciclo de capacitación se implementa de la siguiente manera:
- el teléfono inteligente descarga el modelo actual;
- con la ayuda de la mini versión, TensorFlow lleva a cabo un ciclo de capacitación sobre los datos únicos de un usuario específico;
- mejora el modelo;
- calcula la diferencia entre los modelos fuente mejorados, compila un parche utilizando el protocolo criptográfico Secure Aggregation , que permite el descifrado de datos solo si hay cientos o miles de parches de otros usuarios;
- envía el parche al servidor central;
- el parche adoptado se promedia de inmediato con miles de parches recibidos de otros participantes en el experimento utilizando el algoritmo de promedio federado;
- se lanza una nueva versión del modelo;
- Se envía un modelo mejorado a los participantes en el experimento.
El promedio federado es muy similar al método de gradiente estocástico mencionado anteriormente, solo que aquí los cálculos iniciales no tienen lugar en servidores en la nube, sino en millones de teléfonos inteligentes remotos. El principal logro del promedio federado es de 10 a 100 veces menos tráfico con clientes que el tráfico con servidores que utilizan el método de gradiente estocástico. La optimización se logró debido a
la compresión de alta calidad de las actualizaciones que se envían desde los teléfonos inteligentes al servidor. Bueno, la ventaja aquí es el protocolo criptográfico de agregación segura.
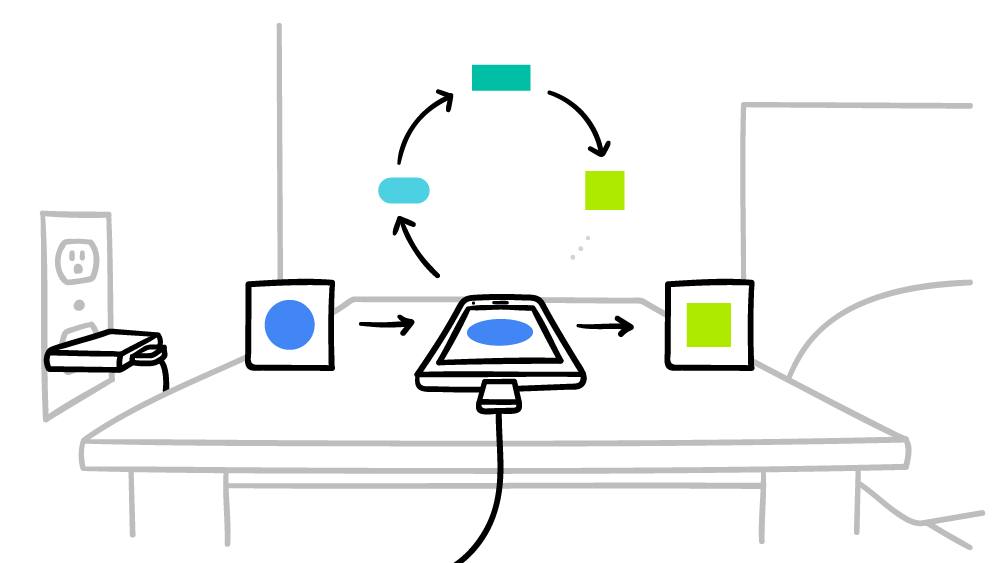
Google promete que el teléfono inteligente solo realizará cálculos para un sistema de IA global distribuido en tiempos de inactividad, de modo que esto no afectará el rendimiento de ninguna manera. Además, puede establecer el tiempo de funcionamiento solo para el momento en que el teléfono inteligente está conectado a la red eléctrica. Por lo tanto, estos cálculos ni siquiera afectarán la vida útil de la batería. El aprendizaje automático federado se está probando actualmente en mensajes contextuales en el teclado de Google:
Gboard en Android .
El algoritmo de promediado federado se describe con más detalle en el documento científico
Learning-Efficient Learning of Deep Networks from Decentralized Data , que se publicó el 17 de febrero de 2016 en arXiv.org (arXiv: 1602.05629).