 Una captura de pantalla de la tarea y la emisión de la red neuronal pix2code en su propio idioma, que el compilador luego traduce en código para la plataforma deseada (Android, iOS)
Una captura de pantalla de la tarea y la emisión de la red neuronal pix2code en su propio idioma, que el compilador luego traduce en código para la plataforma deseada (Android, iOS)El nuevo programa
pix2code (un
artículo científico ) está diseñado para facilitar el trabajo de los programadores que se dedican al tedioso negocio de codificar la GUI del cliente.
El diseñador generalmente crea diseños de interfaz, y el programador debe escribir código para implementar este diseño. Tal trabajo requiere un tiempo valioso que el desarrollador puede dedicar a tareas más interesantes y creativas, es decir, a la implementación de las funciones reales y la lógica del programa, no la GUI. Pronto, la generación de código se puede transferir a los hombros del programa. Una demostración de juguete de las posibilidades futuras del aprendizaje automático es el proyecto
pix2code , que ya ha alcanzado el primer lugar en la
lista de los repositorios más populares en GitHub , ¡aunque el autor ni siquiera ha publicado el código fuente y los conjuntos de datos para entrenar la red neuronal! Un gran interés en este tema.
Codificar una GUI es aburrido. Para empeorar las cosas, estos son diferentes lenguajes de programación en diferentes plataformas. Es decir, debe escribir un código separado para Android, separado para iOS, si el programa debe funcionar de forma nativa. Esto lleva aún más tiempo y te hace realizar las mismas tareas aburridas. Más precisamente, fue antes. El programa pix2code genera código GUI para las tres plataformas principales: Andriod, iOS y HTML / CSS multiplataforma, con una precisión del 77% (la precisión se determina en el lenguaje incorporado del programa, al comparar el código generado con el código objetivo / esperado para cada plataforma).
El autor del programa Tony Beltramelli de la startup danesa
UIzard Technologies llama a esto una demostración del concepto. Él cree que al escalar, el modelo mejorará la precisión de la codificación y es potencialmente capaz de evitar que las personas tengan que codificar manualmente la GUI.
El programa pix2code se basa en redes neuronales convolucionales y recurrentes. La capacitación en la GPU Nvidia Tesla K80 tomó un poco menos de cinco horas, tiempo durante el cual el sistema se optimizó
parámetros para un conjunto de datos. Entonces, si quieres entrenarla para tres plataformas, te llevará unas 15 horas.
El modelo puede generar código al aceptar solo valores de píxeles de una captura de pantalla en la entrada. En otras palabras, no se requiere una tubería especial para que una red neuronal extraiga características y preprocese datos de entrada.
La generación de código de computadora a partir de la captura de pantalla se puede comparar con la generación de una descripción de texto a partir de una fotografía. En consecuencia, la arquitectura del modelo pix2code consta de tres partes: 1) un módulo de visión por computadora para reconocer imágenes, objetos presentados allí, su ubicación, forma y color (botones, subtítulos, contenedores de elementos); 2) un módulo de lenguaje para comprender el texto (en este caso, un lenguaje de programación) y generar ejemplos sintácticamente y semánticamente correctos; 3) usar los dos modelos anteriores para generar descripciones de texto (código) para objetos reconocidos (elementos GUI).
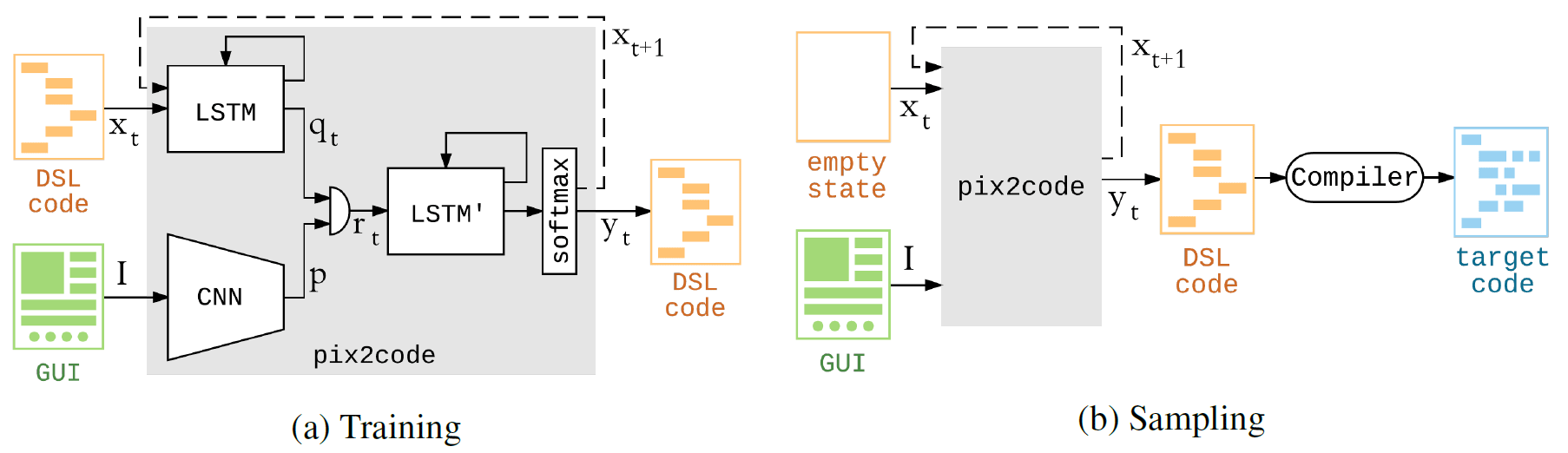
El autor llama la atención sobre el hecho de que la red neuronal se puede entrenar en un conjunto de datos diferente, y luego comenzará a generar código en otros idiomas para otras plataformas. El propio autor no planea hacer esto, porque considera que pix2code es un tipo de juguete que demuestra algunas de las tecnologías en las que está trabajando su startup. Sin embargo, cualquiera puede bifurcar el proyecto y crear una implementación para otros idiomas / plataformas.
En un artículo científico, Tony Beltramelli escribió que publicaría conjuntos de datos para entrenar la red neuronal en el dominio público en el repositorio en GitHub. El repositorio ya ha sido creado. Allí, en la sección de preguntas frecuentes, el autor aclara que publicará conjuntos de datos después de la publicación (o negativa a publicar) de su artículo en
la conferencia NIPS 2017 . Una notificación de los organizadores de la conferencia debería llegar a principios de septiembre, por lo que los conjuntos de datos aparecerán en el repositorio al mismo tiempo. Habrá capturas de pantalla de la GUI, el código correspondiente en el lenguaje del programa y la salida del compilador para las tres plataformas principales.
Con respecto al código fuente del programa, su autor no prometió publicar, pero dado el abrumador interés en su desarrollo, decidió abrirlo también. Esto se realizará simultáneamente con la publicación de conjuntos de datos.
El artículo científico fue
publicado el 22 de mayo de 2017 en el sitio de preimpresión arXiv.org (arXiv: 1705.07962).