 Nosotros, en el equipo de servicio de pago de blockchain de Wirex , estamos familiarizados con la experiencia de la necesidad de refinar y mejorar constantemente la solución tecnológica existente. El autor del material a continuación habla sobre la historia de la evolución del despliegue de código de la famosa plataforma de noticias sociales Reddit.
Nosotros, en el equipo de servicio de pago de blockchain de Wirex , estamos familiarizados con la experiencia de la necesidad de refinar y mejorar constantemente la solución tecnológica existente. El autor del material a continuación habla sobre la historia de la evolución del despliegue de código de la famosa plataforma de noticias sociales Reddit."Es importante seguir la dirección de su desarrollo para poder enviarlo en una buena dirección a tiempo".
El equipo de Reddit está implementando constantemente código. Todos los miembros del equipo de desarrollo escriben regularmente código que es revisado por el propio autor, y se prueba desde el exterior, para que luego pueda ir a la "producción". Cada semana realizamos al menos 200 "implementaciones", cada una de las cuales suele durar menos de 10 minutos.
El sistema que proporciona todo esto ha evolucionado a lo largo de los años. Veamos qué ha cambiado todo este tiempo y qué ha permanecido sin cambios.
Comienzo de la historia: implementaciones estables y recurrentes (2007-2010)
Todo el sistema que tenemos hoy ha crecido a partir de una semilla: un script de Perl llamado push. Fue escrito hace mucho tiempo, en tiempos muy diferentes para Reddit. Todo nuestro equipo técnico era tan pequeño en ese momento que
cabía silenciosamente
en una pequeña "sala de reuniones" . No usamos AWS entonces. El sitio funcionaba en un número finito de servidores, y cualquier capacidad adicional tenía que agregarse manualmente. Todo funcionó en una gran aplicación Python monolítica llamada r2.
Una cosa a lo largo de los años se ha mantenido sin cambios. Las solicitudes se clasificaron en el equilibrador de carga y se distribuyeron entre los "grupos" que contenían servidores de aplicaciones más o menos idénticos. Por ejemplo, las páginas de
listas de temas y
comentarios son procesadas por diferentes grupos de servidores. De hecho, cualquier proceso r2 puede manejar cualquier tipo de solicitud, sin embargo, la división en grupos le permite proteger a cada uno de ellos de saltos repentinos en el tráfico en grupos vecinos. Por lo tanto, en caso de crecimiento del tráfico, la falla no amenaza a todo el sistema, sino a sus grupos individuales.
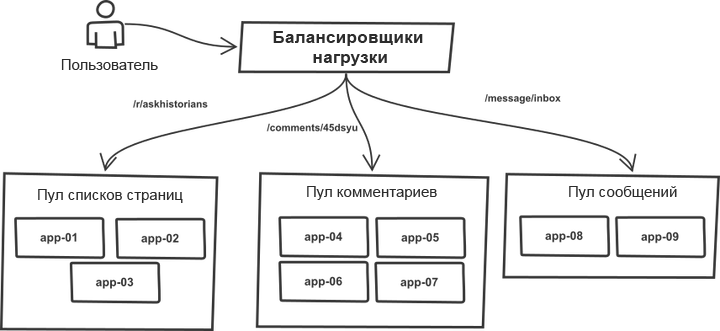
La lista de servidores de destino se escribió manualmente en el código de la herramienta de inserción, y el proceso de implementación funcionó con un sistema monolítico. La herramienta ejecutó la lista de servidores, revisó SSH, ejecutó una de las secuencias de comandos predefinidas que actualizaban la copia actual del código usando git y reinició todos los procesos de la aplicación. La esencia del proceso (el código se simplifica enormemente para una comprensión general):
# `make -C /home/reddit/reddit static` `rsync /home/reddit/reddit/static public:/var/www/` # app- # , foreach $h (@hostlist) { `git push $h:/home/reddit/reddit master` `ssh $h make -C /home/reddit/reddit` `ssh $h /bin/restart-reddit.sh` }
El despliegue tuvo lugar secuencialmente, un servidor tras otro. A pesar de su simplicidad, el esquema tenía una ventaja importante: es muy similar al "
despliegue canario ". Al implementar el código en varios servidores y al notar errores, inmediatamente se dio cuenta de que había errores, podía interrumpir (Ctrl-C) el proceso y retroceder antes de que surjan problemas con todas las solicitudes a la vez. La facilidad de implementación hizo que fuera fácil y sin consecuencias serias verificar las cosas en producción y revertirlas si no funcionaban. Además, fue conveniente determinar qué implementación en particular causó errores, dónde específicamente y qué debe revertirse.
Tal mecanismo hizo un buen trabajo al garantizar la estabilidad y el control durante el despliegue. La herramienta funcionó bastante rápido. Las cosas salieron bien.
Nuestro regimiento llegó (2011)
Luego contratamos a más personas, ahora había seis desarrolladores y nuestra nueva
"sala de reuniones" se hizo más espaciosa . Comenzamos a darnos cuenta de que el proceso de implementación del código ahora necesitaba más coordinación, especialmente cuando los colegas trabajaban desde casa. La utilidad de inserción se ha actualizado: ahora anunció el comienzo y el final de las implementaciones utilizando el chatbot IRC, que simplemente se sentó en el IRC y anunció eventos. Los procesos llevados a cabo durante las implementaciones no sufrieron casi ningún cambio, pero ahora el sistema hizo todo por el desarrollador y les informó a todos los demás sobre las modificaciones realizadas.
A partir de ese momento, el uso del chat comenzó en el flujo de trabajo de implementación. Hablar de administrar la implementación desde chats era bastante popular en ese momento, sin embargo, dado que utilizamos servidores IRC de terceros, no podíamos confiar en el chat al cien por cien para administrar el entorno de producción y, por lo tanto, el proceso se mantuvo al nivel de un flujo de información unidireccional.
A medida que el tráfico hacia el sitio creció, también lo hizo la infraestructura que lo soportaba. De vez en cuando, teníamos que lanzar un nuevo grupo de servidores de aplicaciones y ponerlos en funcionamiento. El proceso aún no estaba automatizado. En particular, la lista de hosts en inserción todavía necesitaba actualizarse manualmente.
El poder de los grupos generalmente aumentaba al agregar varios servidores a la vez. Como resultado, empujar sucesivamente a través de la lista logró transferir cambios a un grupo completo de servidores en el mismo grupo, sin afectar a los demás, es decir, no hubo diversificación por grupos.

UWSGI se utilizó para controlar los procesos de los trabajadores y, por lo tanto, cuando le dimos a la aplicación un comando de reinicio, eliminó todos los procesos existentes a la vez y los reemplazó por otros nuevos. Los nuevos procesos tardaron un tiempo en prepararse para procesar las solicitudes. En el caso de un reinicio involuntario de un grupo de servidores ubicados en el mismo grupo, la combinación de estas dos circunstancias afectó seriamente la capacidad de este grupo para atender solicitudes. Así que nos topamos con un límite en la velocidad de implementación segura de código en todos los servidores. A medida que crecía el número de servidores, también lo hacía la duración de todo el procedimiento.
Reciclar despliegue de instrumentos (2012)
Rediseñamos completamente la herramienta de implementación. Y aunque su nombre, a pesar de una alteración completa, siguió siendo el mismo (push), esta vez fue escrito en Python. La nueva versión ha tenido algunas mejoras importantes.
En primer lugar, tomó la lista de hosts del DNS, y no de la secuencia que estaba codificada en el código. Esto permitió que solo se actualizara la lista, sin la necesidad de actualizar el código de inserción. Los comienzos de un sistema de descubrimiento de servicios han surgido.
Para resolver el problema de los reinicios sucesivos, barajamos la lista de hosts antes de las implementaciones. El barajado reduce los riesgos y permite acelerar el proceso.

La versión original barajó la lista aleatoriamente cada vez, sin embargo, esto dificultó la reversión rápida, porque cada vez que la lista del primer grupo de servidores era diferente. Por lo tanto, corregimos la mezcla: ahora generaba un cierto orden que podría usarse durante la implementación repetida después de la reversión.
Otro cambio pequeño pero importante fue el despliegue constante de alguna versión fija del código. La versión anterior de la herramienta siempre actualizaba la rama maestra en el host de destino, pero ¿qué sucede si el maestro cambia correctamente durante la implementación debido a que alguien lanzó el código por error? La implementación de una revisión git determinada en lugar de llamar por nombre de sucursal hizo posible asegurarse de que se usara la misma versión de código en cada servidor de producción.
Y finalmente, la nueva herramienta distinguió su código (trabajó principalmente con una lista de hosts y accedió a ellos a través de SSH) y los comandos ejecutados en los servidores. Todavía dependía mucho de las necesidades de r2, pero tenía algo así como un prototipo de API. Esto permitió que r2 siguiera sus propios pasos de implementación, lo que facilitó los cambios continuos y liberó el flujo. El siguiente es un ejemplo de comandos ejecutados en un servidor separado. El código, nuevamente, no es el código exacto, pero en general esta secuencia describe bien el flujo de trabajo de r2:
sudo /opt/reddit/deploy.py fetch reddit sudo /opt/reddit/deploy.py deploy reddit f3bbbd66a6 sudo /opt/reddit/deploy.py fetch-names sudo /opt/reddit/deploy.py restart all
Especialmente vale la pena mencionar los nombres de búsqueda: esta instrucción es exclusiva de r2.
Autoescalado (2013)
Luego, finalmente decidimos cambiar a una nube con escala automática (un tema para una publicación completamente separada). Esto nos permitió ahorrar un montón de dinero en esos momentos en que el sitio no estaba cargado de tráfico y aumentar automáticamente la capacidad para hacer frente a cualquier aumento brusco de las solicitudes.
Las mejoras anteriores, cargando automáticamente la lista de hosts desde DNS, han hecho que esta transición sea algo natural. La lista de hosts cambió con más frecuencia que antes, pero desde el punto de vista de la herramienta de implementación, esto no jugó ningún papel. El cambio, que se introdujo originalmente como una mejora de la calidad, se ha convertido en uno de los componentes clave necesarios para ejecutar el escalado automático.
Sin embargo, el escalado automático ha llevado a algunos casos límite interesantes. Era necesario controlar los lanzamientos. ¿Qué sucede si el servidor se inicia correctamente durante la implementación? Necesitábamos asegurarnos de que cada nuevo servidor que se estaba ejecutando verificaba la disponibilidad del nuevo código y lo tomaba, si había uno. No podríamos olvidarnos de que los servidores se desconectaron en el momento de la implementación. La herramienta necesitaba ser más inteligente y aprender a determinar que el servidor se desconectó como parte del procedimiento, y no como resultado de un error que ocurrió durante la implementación. En el último caso, tuvo que advertir en voz alta a todos los colegas involucrados en el problema.
Al mismo tiempo, nosotros, por cierto, y por varias razones, cambiamos de uWSGI a
Gunicorn . Sin embargo, desde el punto de vista del tema de esta publicación, dicha transición no condujo a ningún cambio significativo.
Entonces funcionó por un tiempo.
Demasiados servidores (2014)
Con el tiempo, la cantidad de servidores necesarios para atender el tráfico pico aumentó. Esto condujo al hecho de que las implementaciones requerían más y más tiempo. En el peor de los casos, una implementación normal tomó aproximadamente una hora, un resultado pobre.
Reescribimos la herramienta para que pueda admitir el trabajo paralelo con hosts. La nueva versión se llama
rollingpin . La versión anterior requería mucho tiempo para inicializar las conexiones ssh y esperar la finalización de todos los comandos, por lo que la paralelización dentro de límites razonables nos permitió acelerar la implementación. El tiempo de implementación nuevamente disminuyó a cinco minutos.

Para reducir el impacto de reiniciar simultáneamente varios servidores, el componente de mezcla de la herramienta se ha vuelto más inteligente. En lugar de barajar a ciegas la lista, ordenó los grupos de servidores de modo que los hosts de un grupo estuvieran
lo más separados
posible .
El cambio más importante en la nueva herramienta fue que la
API entre la herramienta de implementación y las herramientas en cada servidor se definió mucho más claramente y se separó de las necesidades de r2. Inicialmente, esto se hizo por el deseo de hacer que el código esté más orientado al código abierto, pero pronto este enfoque fue muy útil de otra manera. El siguiente es un ejemplo de implementación con la selección de comandos API lanzados de forma remota:

Demasiada gente (2015)
De repente, llegó un momento en que, como resultó, muchas personas ya estaban trabajando en r2. Fue genial, y al mismo tiempo significaba que habría aún más implementaciones. Cumplir con la regla de un despliegue a la vez se hizo más y más difícil. Los desarrolladores tuvieron que ponerse de acuerdo el procedimiento para emitir el código. Para optimizar la situación, agregamos otro elemento al chatbot que coordina la cola de implementación. Los ingenieros solicitaron una reserva de implementación y la recibieron o su código "en cola". Esto ayudó a simplificar los despliegues, y aquellos que querían completarlos podían esperar tranquilamente su turno.
Otra adición importante a medida que el equipo creció fue rastrear las implementaciones en
un solo lugar . Cambiamos la herramienta de implementación para enviar métricas a Graphite. Esto facilitó el seguimiento de la correlación entre implementaciones y cambios métricos.
Muchos (dos) servicios (también 2015)
De repente, llegó el momento del lanzamiento del segundo servicio en línea. Era una versión móvil del sitio web con su propia pila completamente diferente, sus propios servidores y el proceso de compilación. Esta fue la primera prueba real de una API de herramienta de implementación dividida. Agregarle la capacidad de resolver todas las etapas de ensamblaje en diferentes "ubicaciones" para cada proyecto le permitió soportar la carga y hacer frente al mantenimiento de dos servicios dentro del mismo sistema.
25 servicios (2016)
Durante el año siguiente, fuimos testigos de la rápida expansión del equipo. En lugar de dos servicios, aparecieron dos docenas, en lugar de dos equipos de desarrollo, quince. La mayoría de los servicios se
crearon en
Baseplate , nuestro marco de back-end o en aplicaciones cliente, similares a la web móvil. La infraestructura detrás de las implementaciones es la misma para todos. Pronto, muchos otros servicios nuevos se lanzarán en línea, y todo esto se debe en gran medida a la versatilidad del rodillo. Le permite simplificar el lanzamiento de nuevos servicios utilizando herramientas familiares para las personas.
Airbag (2017)
A medida que aumentaba el número de servidores en el monolito, aumentaba el tiempo de implementación. Queríamos aumentar significativamente el número de implementaciones paralelas, pero esto causaría demasiados reinicios simultáneos de los servidores de aplicaciones. Tales cosas, por supuesto, conducen a una caída en el rendimiento y una pérdida de la capacidad de atender las solicitudes entrantes debido a la sobrecarga de los servidores restantes.
El proceso principal de Gunicorn utilizaba el mismo modelo que uWSGI, recargando a todos los trabajadores al mismo tiempo. Los nuevos procesos de trabajo no pudieron atender solicitudes hasta que se cargaron por completo. El tiempo de lanzamiento de nuestro monolito osciló entre 10 y 30 segundos. Esto significaba que durante este período de tiempo no podríamos procesar solicitudes en absoluto. Para encontrar una salida a esta situación, reemplazamos el proceso principal de gunicorn con el administrador de trabajo
Einhorn de Stripe, al
tiempo que conservamos la pila HTTP Gunicorn y el contenedor WSGI . Durante el reinicio, Einhorn crea un nuevo trabajador, espera hasta que esté listo, se deshace de un antiguo trabajador y repite el proceso hasta que se complete la actualización. Esto crea una bolsa de aire y nos permite mantener el ancho de banda a un nivel durante las implementaciones.
El nuevo modelo creó otro problema. Como se mencionó anteriormente, reemplazar a un trabajador por uno nuevo y completamente terminado tomó hasta 30 segundos. Esto significaba que si había un error en el código, no aparecía inmediatamente y lograba desplegarse en muchos servidores antes de ser detectado. Para evitar esto, introdujimos un mecanismo para bloquear la transición del procedimiento de implementación al nuevo servidor, que estuvo vigente hasta que se reiniciaron todos los procesos de trabajo. Se implementó simplemente: encuestando el estado de Einhorn y esperando la preparación de todos los nuevos trabajadores. Para mantener la velocidad al mismo nivel, ampliamos la cantidad de servidores que se procesan en paralelo, lo que era completamente seguro en las nuevas condiciones.
Dicho mecanismo nos permite implementar simultáneamente en un número mucho mayor de máquinas, y el tiempo de implementación, que abarca aproximadamente 800 servidores, se reduce a 7 minutos, teniendo en cuenta pausas adicionales para verificar errores.
Mirando hacia atrás
La infraestructura de implementación descrita aquí es un producto nacido de muchos años de mejoras consistentes, en lugar de un esfuerzo enfocado de una sola vez. Los ecos de las decisiones tomadas una vez y alcanzadas en las primeras etapas de los compromisos aún se hacen sentir en el sistema actual, y este siempre ha sido el caso en todas las etapas. Tal enfoque evolutivo tiene sus pros y sus contras: requiere un mínimo de esfuerzo en cualquier etapa, sin embargo, tarde o temprano existe el riesgo de detenerse. Es importante seguir la dirección de su desarrollo para poder enviarlo en una buena dirección a tiempo.
El futuro
La infraestructura de Reddit debería estar lista para el apoyo continuo del equipo a medida que crece y lanza cosas nuevas. La tasa de crecimiento de la empresa es más rápida que nunca, y estamos trabajando en proyectos aún más interesantes y a gran escala que todos los que hicimos antes. Los problemas que enfrentamos hoy son de doble naturaleza: por un lado, es la necesidad de aumentar la autonomía de los desarrolladores, por otro lado, para mantener la seguridad de la infraestructura de producción y mejorar el airbag, lo que permite a los desarrolladores realizar implementaciones de manera rápida y segura.
