 “Un científico puede descubrir una nueva estrella, pero no puede crearla. Para hacer esto, tendría que contactar a un ingeniero ”. Gordon Lindsay Glass, Diseño de diseño (1969)
“Un científico puede descubrir una nueva estrella, pero no puede crearla. Para hacer esto, tendría que contactar a un ingeniero ”. Gordon Lindsay Glass, Diseño de diseño (1969)Hace unos meses, escribí sobre las diferencias entre los expertos en teoría y métodos de análisis de datos (científico de datos) y los especialistas en procesamiento de datos (ingeniero de datos). Hablé sobre sus habilidades y puntos de partida comunes. Algo interesante sucedió: los científicos de datos comenzaron a avanzar, alegando que en realidad eran tan competentes en el campo de la ingeniería de datos como los especialistas en procesamiento de datos. Esto fue interesante porque los expertos en procesamiento de datos no se opusieron y no dijeron que eran especialistas en la teoría del análisis de datos.
Por lo tanto, durante los últimos meses he estado recopilando información y monitoreando el comportamiento de especialistas en la teoría del análisis de datos en su entorno de trabajo natural. En esta publicación, hablaré más sobre por qué un científico de datos no es un ingeniero de datos.
¿Por qué es esto tan importante?
Algunos se quejan de que la diferencia entre un especialista en la teoría del análisis de datos y un especialista en procesamiento de datos radica solo en el nombre. "Los
nombres no deberían impedir que las personas aprendan o hagan algo nuevo ", dicen. Estoy de acuerdo, debes aprender tanto como sea posible. Pero tenga en cuenta que su capacitación solo puede relacionarse de manera remota con lo que deberá hacerse en la práctica. De lo contrario, esto puede conducir al fracaso de proyectos con big data.
Mucho también depende del nivel de gestión en las empresas. La gerencia contrata especialistas en teoría de análisis de datos, esperando que sean especialistas en procesamiento de datos.
Escuché la misma historia en diferentes compañías: una compañía decide que la ciencia de datos es una forma de obtener dinero de los inversores, toneladas de ganancias, ganar credibilidad en su comunidad empresarial, etc. Esta decisión se toma a nivel de la alta gerencia. Por ejemplo, deje que cierta Alice pertenezca a esos altos directivos. Después de una larga búsqueda, la compañía encuentra al mejor especialista en teoría del análisis de datos del mundo. Llamémoslo Bob.
Llegó el primer día hábil de Bob. Alice se le acerca y habla con entusiasmo sobre todos sus planes.
“Genial. ¿Dónde están las tuberías de datos y su clúster Spark? ”Pregunta Bob.
Alice responde: “Esto es lo que esperamos de ti. Te contratamos para hacer análisis de datos.
"No sé cómo hacer esto", dice Bob.
Alice se ve sorprendida: “Pero usted es especialista en teoría del procesamiento de datos. Derecho? Esto es lo que estás haciendo ".
"No, yo uso tuberías y datos ya creados".
Alice regresa a su oficina para averiguar qué pasó. Ella mira gráficos simplificados como el que se muestra en la Figura 1, y no puede entender por qué Bob no puede realizar tareas simples con grandes datos.
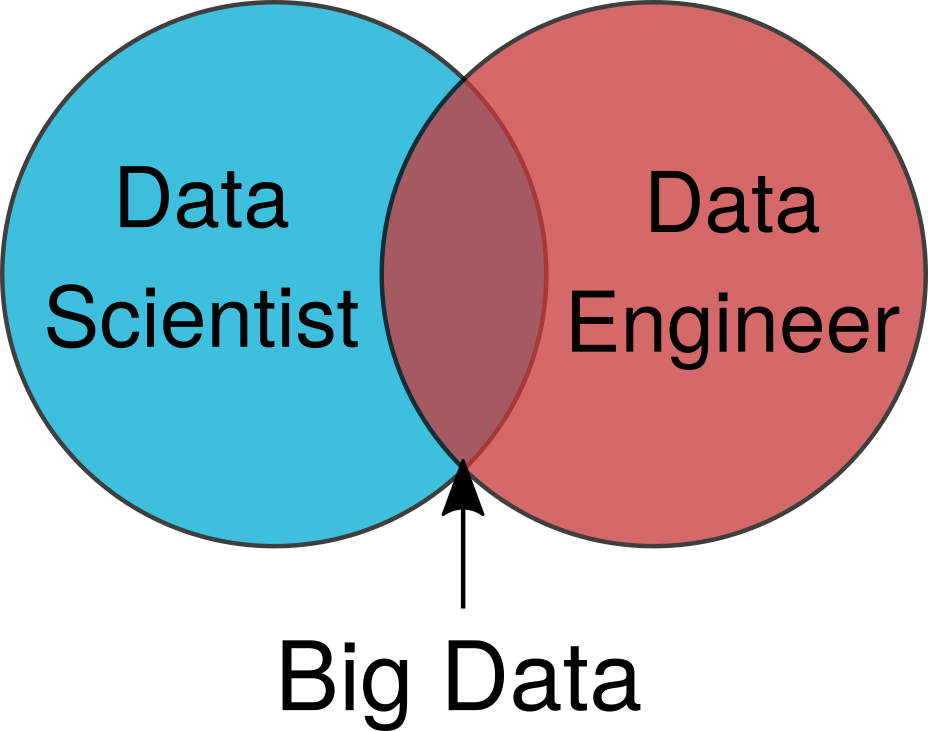 Figura 1. Un diagrama de Venn simplificado con un especialista en teoría de análisis de datos y un especialista en procesamiento de datos.
Figura 1. Un diagrama de Venn simplificado con un especialista en teoría de análisis de datos y un especialista en procesamiento de datos.Spotlight
Dos problemas surgen de estas interacciones:
- ¿Por qué la gerencia no entiende que un especialista en teoría de análisis de datos no es un especialista en procesamiento de datos?
- ¿Por qué algunos teóricos del análisis piensan que son especialistas en procesamiento?
Comenzaré desde el lado del liderazgo. Más adelante hablaremos de los propios especialistas en teoría de análisis de datos.
Seamos realistas: el procesamiento de datos no está en el centro de atención. No es declarada la mejor obra del siglo XXI. No se la suele escribir en los medios. En las conferencias, a las primeras personas de la empresa no se les informa sobre los beneficios del procesamiento de datos. Todos los mensajes se relacionan con el análisis de datos y la búsqueda de especialistas en teoría y métodos de análisis de datos.
Pero las cosas están empezando a cambiar. Tenemos conferencias sobre procesamiento de datos. La necesidad de desarrollar herramientas técnicas de procesamiento de datos se reconoce gradualmente. Espero que mi trabajo ayude a las organizaciones a darse cuenta de esta necesidad urgente.
Reconocimiento y apreciación
Incluso en los casos en que las organizaciones cuentan con equipos de especialistas en procesamiento de datos, su trabajo a menudo todavía no se evalúa adecuadamente.
Una falta de reconocimiento se puede ver durante las conferencias. Un especialista en la teoría del análisis de datos dice que él creó. Veo una tecnología integral de procesamiento de datos que formó la base de su modelo, pero nunca se menciona durante una conversación. No espero que se examine en detalle, pero sería bueno tener en cuenta el trabajo realizado para que la creación de su modelo sea posible. La gerencia y los novatos en el campo del análisis de datos creen que todo es posible con las habilidades de un especialista en teoría del análisis de datos.
Cómo lograr el reconocimiento
Recientemente, los expertos en procesamiento de datos me han estado preguntando cómo llamar la atención en sus empresas. Sienten que cuando los expertos en la teoría del análisis muestran sus últimos desarrollos, obtienen toda la gratitud del liderazgo. La pregunta principal que me hacen los ingenieros es: "¿Cómo hago para que un científico de datos deje de considerar nuestro trabajo común como mi mérito?"
Esta es una pregunta bien fundada, basada en las situaciones que veo en las empresas. La gerencia no reconoce (y no revela) el trabajo de procesamiento de datos, que se relaciona con todo lo relacionado con el análisis de datos. Si lees esto y piensas:
- Mis especialistas en teoría de análisis de datos son especialistas en procesamiento de datos.
- Mis expertos en teoría de análisis de datos crean tuberías de datos realmente complejas.
- El autor no debe saber de qué está hablando.
... entonces probablemente tenga un especialista en procesamiento de datos que no esté en el centro de atención.
A medida que los especialistas en teoría de análisis de datos renuncian en ausencia de ingenieros, también renuncia un ingeniero que no recibe suficiente reconocimiento de su trabajo. No te dejes engañar; Para los especialistas calificados en procesamiento de datos, el mercado laboral es tan popular como para los especialistas en teoría del análisis de datos.
El análisis de datos solo es posible con el apoyo de nuestros amigos.
Probablemente hayas escuchado el
mito de Atlanta . Como castigo, se vio obligado a mantener la esfera mundo / cielo / celestial en sí mismo. La Tierra existe en su forma actual solo porque Atlas la posee.
Del mismo modo, los científicos de datos apoyan el mundo del análisis de datos. Una persona que sostiene todo el mundo sobre sus hombros no recibe tanto aprecio, aunque debería hacerlo. En todos los niveles de la organización, debe entenderse que el análisis de datos solo es posible gracias al trabajo de un grupo de especialistas en procesamiento de datos.
 Fig. 2. Incluso los italianos en la década de 1400 sabían sobre la importancia de los especialistas en procesamiento de datos.
Fig. 2. Incluso los italianos en la década de 1400 sabían sobre la importancia de los especialistas en procesamiento de datos.Los científicos de datos no son ingenieros de datos.
Esto nos lleva a por qué la teoría del análisis de datos cree que son especialistas en procesamiento de datos.
Antes de continuar, algunas reservas para advertir comentarios:
- Sé que los expertos en teoría de análisis de datos son realmente muy inteligentes, y me gusta trabajar con ellos.
- Me pregunto si tal intelecto causa un efecto más fuerte del coeficiente intelectual de Dunning-Kruger.
- Algunos de los mejores expertos en teoría de análisis de datos que conocía eran expertos en procesamiento de datos, pero había muy pocos.
- Evaluamos constantemente nuestras propias habilidades.
 Fig. 3. Un diagrama empírico de la percepción de sus habilidades por parte de especialistas en la teoría del análisis en comparación con sus habilidades reales.
Fig. 3. Un diagrama empírico de la percepción de sus habilidades por parte de especialistas en la teoría del análisis en comparación con sus habilidades reales.Al analizar sus habilidades de procesamiento de datos con expertos en teoría de análisis de datos, descubrí que su autoestima varía mucho. Este es un experimento social interesante con prejuicios. La mayoría de los expertos en teoría de análisis de datos han sobreestimado sus propias capacidades de procesamiento de datos. Algunos dieron una evaluación precisa, pero nadie dio una calificación más baja que sus habilidades reales.
Faltan dos cosas en este diagrama:
- ¿Cuál es el nivel de habilidad de los profesionales de procesamiento de datos?
- ¿Qué nivel de habilidad se requiere para una tubería de datos moderadamente compleja?
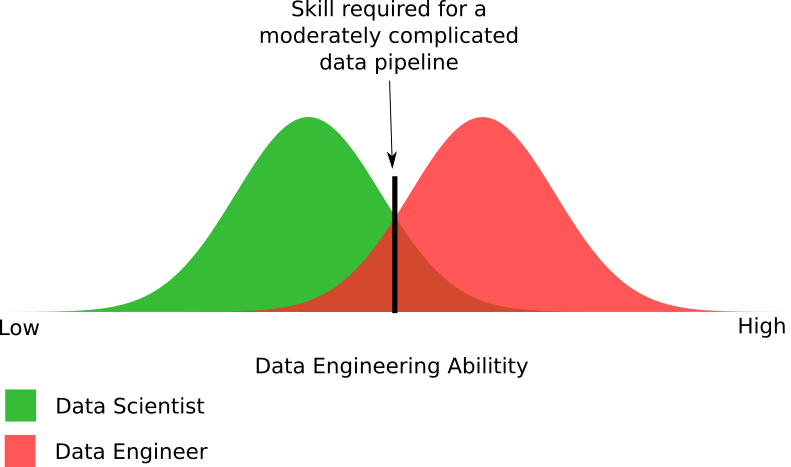 Figura 4. Un diagrama empírico de las habilidades de los especialistas en la teoría del análisis y el procesamiento de datos necesarios para crear una tubería de datos moderadamente compleja.
Figura 4. Un diagrama empírico de las habilidades de los especialistas en la teoría del análisis y el procesamiento de datos necesarios para crear una tubería de datos moderadamente compleja.La figura muestra las diferencias en las capacidades requeridas para el procesamiento de datos. De hecho, exageré un poco con la cantidad de científicos capaces de crear una tubería de datos moderadamente compleja. La realidad puede ser que los expertos en la teoría del análisis representan la mitad de la parte que se muestra en el diagrama.
En general, presenta las partes aproximadas de estos dos grupos, que pueden y no pueden crear canalizaciones de datos. Sí, algunos especialistas en procesamiento de datos no pueden crear una tubería moderadamente compleja, como la mayoría de los expertos en teoría de análisis. Esto nos lleva de vuelta al problema urgente: las organizaciones entregan sus proyectos con big data a aquellos que no tienen la oportunidad de implementarlos correctamente.
¿Qué es una tubería de datos moderadamente compleja?
Una tubería de datos moderadamente compleja está un paso por encima del nivel mínimo requerido para crear
una tubería de datos . Un ejemplo de nivel mínimo es el procesamiento de archivos de texto almacenados en HDFS / S3 utilizando Spark: digamos, el comienzo de la optimización del almacenamiento utilizando la base de datos NoSQL utilizada correctamente.
Creo que los expertos en la teoría del análisis de datos piensan que su canalización simple es el procesamiento de datos. Pero en realidad están hablando de las soluciones más simples, y se requiere una cinta transportadora mucho más compleja. En el pasado, un especialista en procesamiento de datos entre bastidores realizaba una ingeniería realmente compleja, y los expertos en teoría de análisis no tenían que lidiar con eso.
Puede pensar: “Bueno, el 20% de mis expertos en teoría de análisis de datos pueden manejar esto. Al final, no necesito un especialista en procesamiento ”. Primero, recuerde que este gráfico exagera las capacidades de los expertos en teoría de análisis de datos. Un nivel moderadamente difícil sigue siendo un nivel bastante bajo. Necesito crear otro diagrama para mostrar cuán pocos teóricos del análisis de datos pueden dar el siguiente paso. Es en esta etapa que su participación entre los especialistas involucrados en la teoría del análisis de datos disminuye a 1% o menos.
¿Por qué los científicos de datos no son ingenieros de datos?
A veces prefiero considerar las manifestaciones reflejadas de los problemas. Estos son algunos de estos problemas que hacen que los expertos en teoría de análisis de datos carezcan de habilidades de procesamiento.
Universidad y cursos
Data Analysis es un nuevo programa popular para universidades y cursos en línea. Hay todo tipo de sugerencias, pero el mismo problema se encuentra en casi todas partes: el plan de estudios no contiene ninguna clase de procesamiento de datos o solo se destaca un par.
Cuando veo un nuevo programa de capacitación en análisis de datos, lo reviso. A veces me piden que comente sobre los cursos ofrecidos por las universidades. Les digo a todos lo mismo: “¿Necesitas programadores experimentados? Porque su curso no tiene nada que ver con la programación o los sistemas necesarios para usar la tubería de datos creada ".
El curso, en términos generales, se centra en las herramientas estadísticas y matemáticas necesarias. Esto refleja cómo, según las empresas y los científicos, debería ser el análisis de datos. Pero el mundo real se ve muy diferente. Los estudiantes pobres solo pueden influir hasta el final de estas clases no triviales.
Podemos dar un paso atrás y ver todo desde un punto de vista académico, considerando los requisitos para una maestría en el campo de los sistemas distribuidos. Obviamente, un especialista en teoría de análisis de datos no necesita un nivel tan profundo, pero ayuda a mostrar qué vacíos existen en las habilidades de un especialista en teoría de análisis de datos. Hay varias lagunas graves.
Procesamiento de datos! = Spark
Un error común entre los expertos en la teoría del análisis y la gestión de datos es que piensan que el procesamiento de datos solo está escribiendo algún tipo de código Spark para procesar el archivo. Spark es una buena solución por lotes, pero no es la única tecnología que necesita. Una solución de Big Data requerirá entre 10 y 30 tecnologías diferentes que funcionarán juntas.
Esta falacia está en el corazón de las fallas de Big Data. La gerencia cree que la compañía tiene una nueva solución universal para resolver problemas con big data. La realidad es mucho más complicada.
Cuando asesoro a la organización en temas de big data, verifico la presencia de este error en todos los niveles de la empresa. Si es así, debo asegurarme de que enumeraré todas las tecnologías que necesitarán. Esto elimina la idea errónea de que en el área de big data hay un botón simple y una tecnología única para resolver todos los problemas.
¿De dónde vino el código?
A veces los expertos en teoría de análisis de datos me dicen cuán simple es la tecnología de procesamiento de datos. Les pregunto por qué piensan eso. “Puedo obtener el código que necesito de StackOverflow o Reddit. Si necesito crear algo desde cero, puedo copiar el proyecto de alguien en una conferencia en una conferencia o en un documento técnico ".
Para un extraño, esto puede parecer normal. Para un especialista en procesamiento de datos, esto es una alarma. Dejando de lado los problemas legales, esto no es procesamiento de datos. En el área de big data hay muy pocos problemas de plantilla. Todo lo que sucede después de "hola, mundo" tiene una estructura más compleja, que requiere un especialista en procesamiento de datos, ya que no existe un enfoque de plantilla para trabajar con él. Copiar un proyecto de la documentación técnica puede conducir a un
bajo rendimiento o algo peor .
Tuve que tratar con varios grupos sobre la teoría del análisis de datos que probó el enfoque de "el mono ve - el mono hace". No funciona muy bien. Esto se debe a un fuerte aumento en la complejidad de los grandes datos y la
atención especial a los casos de uso. Un equipo de especialistas en teoría de análisis de datos a menudo rechaza un proyecto porque va más allá de sus capacidades en el procesamiento de datos. En pocas palabras, hay una gran diferencia entre "Puedo copiar código de StackOverflow" o "Puedo cambiar algo que ya se ha escrito" y "Puedo crear este sistema desde cero".
Personalmente, me preocupa que los grupos de especialistas en teoría del análisis de datos puedan convertirse en una fuente de enorme deuda técnica que reduzca la efectividad de los grandes datos en las organizaciones. Para cuando esto quede claro, la deuda técnica será tan grande que será imposible arreglarla.
¿Cuál fue el código más largo introducido para uso industrial?
La principal diferencia entre los especialistas en la teoría del análisis de datos es su profundidad. Esta profundidad se puede mostrar de dos maneras. ¿Cuál es el período más largo de aplicación de su código en la práctica? ¿Se puso en funcionamiento? ¿Cuál es el programa más largo, más grande o más complejo que hayan escrito?
No se trata de competencia, sino de si saben qué sucede cuando se pone en funcionamiento algo y cómo mantener el código. Escribir un programa de 20 líneas de código es relativamente simple. Otra cuestión es escribir 1000 líneas de código que sean coherentes y fáciles de mantener. Las personas que nunca han escrito más de 20 líneas no entienden la diferencia en la facilidad de mantenimiento. Todas sus quejas sobre la verbosidad de Java y la necesidad de utilizar las mejores prácticas en programación están relacionadas con grandes proyectos de software.
Al evaluar y descubrir datos, debe trabajar rápidamente y rehacer el código. Y se requiere trabajar con el código para el uso de producción en un nivel diferente y más profundo. Es por eso que el código de la mayoría de los expertos en teoría de análisis de datos debe reescribirse antes de ponerse en funcionamiento.
Diseño de sistema distribuido
Una forma de descubrir la diferencia entre los expertos en teoría de análisis de datos y los especialistas en procesamiento de datos es ver qué sucede cuando escriben sus propios sistemas distribuidos. Un experto en teoría de análisis de datos escribirá algo muy centrado en las matemáticas pero que no funciona bien. Un especialista en procesamiento de datos que escribe sistemas distribuidos creará una solución distribuida que funcionará bien (
pero no escriba mejor sus propios sistemas ). Contaré varias historias sobre mi interacción con organizaciones en las que expertos en la teoría del análisis de datos crearon un sistema distribuido.
Entonces, en compañía de mi cliente, un departamento formado por especialistas en la teoría del análisis de datos creó dicho sistema. Me enviaron para hablar con ellos y entender por qué escribieron su propia decisión y qué puede hacer. Se dedicaron al procesamiento (distribuido) de imágenes.
Comencé preguntándoles por qué crearon su propio sistema distribuido. Respondieron que era imposible distribuir el algoritmo. Para confirmar sus hallazgos, firmaron un contrato con otro especialista en teoría del análisis de datos, especializado en procesamiento de imágenes. El contratista confirmó la imposibilidad de distribuir el algoritmo.
En las dos horas que pasé con el equipo, quedó claro que el algoritmo se puede distribuir en un motor informático universal, como Spark. , . data scientist'e data engineer', -.
, , . , . . , . . RPC- , .
:
- , . , .
- , .
- : « ?» : « ?»
- , , , .
?
, , : — . , ? ?
— , big data.
, , . , . Aquí hay algunos de ellos:
, , , , . , . , , : « » « . . ». , . .
? , - , production ? «». , .
data scientist'? , ( ), . , . «» .
?
, , data scientist' data engineer'. , . : , , .
, , , .
, , data scientist' data engineer' , , . 2-5 . , , .
, . , , , . , , . , , , , , .
, . . , . , , , , .
, . , , , , . :
- . , , , .
- , — . , .
- ? , -?
- , data scientist'. .
- , . , . — , .
?
, , ? , . . .
, . , . .
, . .
big data
, big data — . , . big data-, . .
big data- , . , , . ( ) , .
Fallos similares forman un patrón repetitivo. Puede actualizar a la última tecnología, pero olvide solucionar los problemas del sistema. Solo arreglando el problema raíz puedes comenzar tu viaje hacia el éxito.