Los chips en la mayoría de las computadoras de escritorio modernas tienen cuatro núcleos, pero los fabricantes de chips ya han anunciado planes para actualizar a seis núcleos, y los procesadores de 16 núcleos distan mucho de ser poco comunes para los servidores de alto rendimiento.
Cuantos más núcleos, mayor es el problema de asignación de memoria entre todos los núcleos mientras trabajan juntos. Con el aumento en el número de núcleos, se está volviendo cada vez más rentable minimizar la pérdida de tiempo en la gestión de los núcleos durante el procesamiento de datos, porque la tasa de intercambio de datos va a la zaga de la velocidad del procesador y el procesamiento de datos en la memoria. Puede recurrir físicamente al caché rápido de otra persona, o puede usar su propio lento, pero ahorre tiempo de transferencia de datos. La tarea se complica por el hecho de que la cantidad de memoria solicitada por los programas no corresponde claramente a los tamaños de caché de cada tipo.
Solo se puede ubicar físicamente una cantidad muy limitada de memoria lo más cerca posible del procesador, un caché de procesador de nivel L1, cuya cantidad es extremadamente pequeña. Daniel Sánchez, Po-An Tsai y Nathan Beckmann, investigadores del Laboratorio del Instituto de Ciencias de la Computación e Inteligencia Artificial de Massachusetts, le
enseñaron a la computadora
cómo configurar diferentes tipos de memoria para adaptarse a una jerarquía flexible de programas en en tiempo real El nuevo sistema, llamado Jenga, analiza las necesidades volumétricas y la frecuencia del acceso del programa a la memoria y redistribuye la potencia de cada uno de los 3 tipos de caché del procesador en combinaciones que proporcionan una mayor eficiencia y ahorro de energía.

Para empezar, los investigadores probaron el aumento del rendimiento con una combinación de memoria estática y dinámica al trabajar en programas para un procesador de un solo núcleo y obtuvieron la jerarquía principal, cuando es la mejor combinación para usar. De 2 tipos de memoria o de uno. Se evaluaron dos parámetros: retraso de la señal (latencia) y consumo de energía durante la operación de cada programa. Alrededor del 40% de los programas comenzaron a funcionar peor con una combinación de tipos de memoria, el resto, mejor. Después de haber arreglado qué programas "gustaban" del rendimiento mixto y cuáles, el tamaño de la memoria, los investigadores construyeron su sistema Jenga.
Prácticamente probaron 4 tipos de programas en una computadora virtual con 36 núcleos. Probado el programa:
- omnet: banco de pruebas de red modular objetivo, biblioteca de modelado C y plataforma de herramientas de modelado de red (azul en la imagen)
- mcf - Meta Content Framework (rojo)
- astar - software para mostrar realidad virtual (verde)
- bzip2 - archivador (color morado)
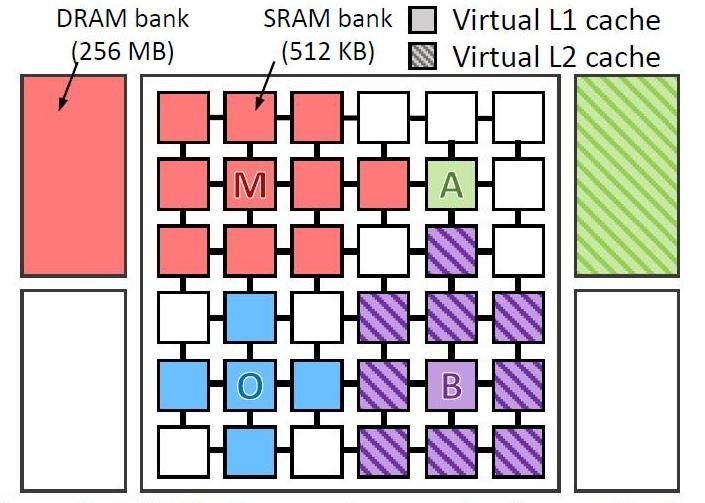
La imagen muestra dónde y cómo se procesaron los datos de cada programa. Las letras indican dónde se ejecuta cada aplicación (una por cuadrante), los colores indican dónde se encuentran sus datos y la eclosión indica el segundo nivel de la jerarquía virtual cuando está presente.
Niveles de cachéEl caché de la CPU se divide en varios niveles. Para procesadores universales: hasta 3. La memoria más rápida es el caché de primer nivel: caché L1, porque está ubicado en el mismo chip que el procesador. Consiste en un caché de comandos y un caché de datos. Algunos procesadores sin caché L1 no pueden funcionar. El caché L1 se ejecuta a la frecuencia del procesador y se puede acceder a él en cada ciclo de reloj. A menudo es posible realizar múltiples operaciones de lectura / escritura al mismo tiempo. El volumen suele ser pequeño, no más de 128 KB.
El caché L1 interactúa con un caché de segundo nivel: L2. Es el segundo más rápido. Por lo general, se encuentra en el chip, como L1, o en las inmediaciones del núcleo, por ejemplo, en un cartucho de procesador. En procesadores más antiguos, un chipset en la placa base. El tamaño del caché L2 es de 128 KB a 12 MB. En los procesadores modernos de varios núcleos, el caché de segundo nivel, ubicado en el mismo chip, es una memoria compartida, con un tamaño de caché total de 8 MB, 2 MB por núcleo. Por lo general, la latencia de la caché L2 ubicada en el chip central es de entre 8 y 20 ciclos de reloj. En tareas relacionadas con numerosos accesos a un área limitada de memoria, por ejemplo, un DBMS, su uso completo hace que la productividad se multiplique por diez.
El caché L3 suele ser aún más grande, aunque un poco más lento que L2 (debido al hecho de que el bus entre L2 y L3 es más estrecho que el bus entre L1 y L2). L3 generalmente se encuentra separado del núcleo de la CPU, pero puede ser grande: más de 32 MB. El caché L3 es más lento que los cachés anteriores, pero aún más rápido que la RAM. En sistemas multiprocesador es de uso común. El uso de la caché de tercer nivel se justifica en un rango muy limitado de tareas y puede no solo no aumentar la productividad, sino viceversa y conducir a una disminución general en el rendimiento del sistema.
Deshabilitar el caché del segundo y tercer nivel es más útil en problemas matemáticos cuando la cantidad de datos es menor que el tamaño del caché. En este caso, puede cargar todos los datos inmediatamente en la memoria caché L1 y luego procesarlos.
Periódicamente, Jenga a nivel del sistema operativo reconfigura las jerarquías virtuales para minimizar el intercambio de datos, dadas las limitaciones de recursos y el comportamiento de la aplicación. Cada reconfiguración consta de cuatro pasos.
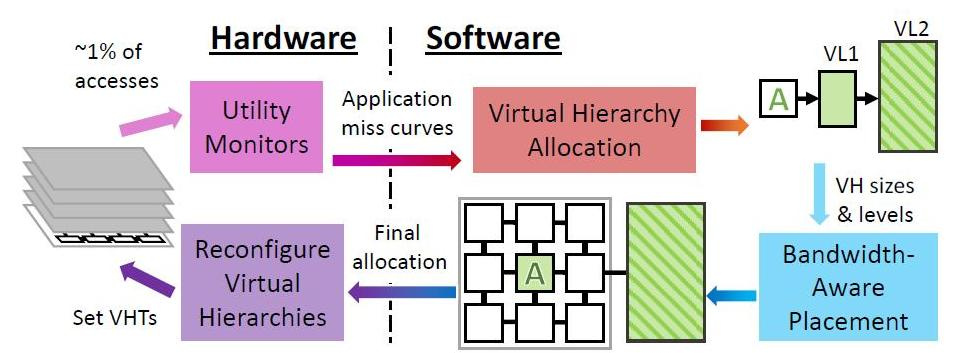
Jenga distribuye datos no solo en función de los programas que se envían: amando la memoria grande de una sola velocidad o amando el rendimiento de cachés mixtas, sino también dependiendo de la proximidad física de las celdas de memoria a los datos que se procesan. Independientemente del tipo de caché que el programa requiera por defecto o jerarquía. Lo principal es minimizar el retraso de la señal y el consumo de energía. Dependiendo de cuántos tipos de memoria le gusta al programa, Jenga modela la latencia de cada jerarquía virtual con uno o dos niveles. Las jerarquías de dos niveles forman una superficie, las jerarquías de un solo nivel forman una curva. Jenga luego diseña el retraso mínimo en tamaños VL1, lo que da dos curvas. Finalmente, Jenga usa estas curvas para seleccionar la mejor jerarquía (es decir, el tamaño VL1).
El uso de Jenga le dio un efecto tangible. El chip virtual de 36 núcleos era un 30 por ciento más rápido y usaba un 85 por ciento menos de energía. Por supuesto, si bien Jenga es solo una simulación de una computadora en funcionamiento, tomará algún tiempo antes de que vea ejemplos reales de este caché e incluso antes de que los fabricantes de chips lo acepten si les gusta la tecnología.
Configuración condicional de 36 máquinas nucleares
- Procesadores . 36 núcleos, x86-64 ISA, 2.4 GHz, tipo Silvermont OOO: ancho 8B
ifetch Bpred de 2 niveles con BHSR de 512 × 10 bits + PHT de 1024 × 2 bits, decodificación / emisión / cambio de nombre / confirmación de 2 vías, IQ y ROB de 32 entradas, LQ de 10 entradas, SQ de 16 entradas; 371 pJ / instrucción, 163 mW / núcleo de potencia estática - Caches de nivel L1 . 32 KB, conjunto asociativo de 8 vías, datos divididos y cachés de instrucciones,
Latencia de 3 ciclos; 15/33 pJ por hit / miss - Prefetchers Prefetch Service . Prefetchers de flujo de 16 entradas modeladas y validadas según
Nehalem - Caches de nivel L2 . 128 KB privados por núcleo, latencia asociativa de 8 vías, inclusiva, de 6 ciclos; 46/93 pJ por hit / miss
- Modo coherente (coherencia) . Bancos de directorios de latencia de 16 vías y 6 ciclos para Jenga; directorios L3 en caché para otros
- Global NoC . Malla 6 × 6, flits y enlaces de 128 bits, enrutamiento XY, enrutadores canalizados de 2 ciclos, enlaces de 1 ciclo; 63/71 pJ por enrutador / enlace transversal, 12 / 4mW enrutador / enlace de energía estática
- Bloques de memoria estática SRAM . 18 MB, un banco de 512 KB por mosaico, zcache de 4 vías y 52 candidatos, latencia bancaria de 9 ciclos, partición Vantage; 240/500 pJ por hit / miss, 28 mW / banco de potencia estática
- Memoria dinámica multicapa DRAM apilada . 1152 MB, una bóveda de 128 MB por 4 mosaicos, aleación con MAP-I DDR3-3200 (1600 MHz), bus de 128 bits, 16 rangos, 8 bancos / rango, búfer de fila de 2 KB; 4.4 / 6.2 nJ por hit / miss, 88 mW / bóveda de potencia estática
- Memoria principal 4 canales DDR3-1600, bus de 64 bits, 2 rangos / canal, 8 bancos / rango, búfer de fila de 8 KB; 20 nJ / acceso, 4W de potencia estática
- Tiempos de DRAM . tCAS = 8, tRCD = 8, tRTP = 4, tRAS = 24, tRP = 8, tRRD = 4, tWTR = 4, tWR = 8, tFAW = 18 (todos los tiempos en tCK; DRAM apilada tiene la mitad de tCK como memoria principal )