 Los dobles digitales de políticos y actores famosos están bajo el control total del "titiritero". Ilustración: Universidad de Washington, 2015
Los dobles digitales de políticos y actores famosos están bajo el control total del "titiritero". Ilustración: Universidad de Washington, 2015Los programas de gráficos en 3D, junto con las redes neuronales, han alcanzado una calidad tal que el video falso es casi indistinguible del real. Pronto no será posible decir con certeza que la persona en la pantalla del televisor es un verdadero político, no una simulación de computadora.
En diciembre de 2015, científicos de la Universidad de Washington introdujeron la
tecnología de "dobles digitales" : la creación de modelos 3D "en vivo" a partir de cientos de fotografías de un personaje. Se ha compilado un gran archivo de fotos para celebridades y políticos en Internet. El programa crea un modelo, y ese es como una muñeca en una cuerda: se puede controlar a su gusto, dar diferentes expresiones faciales, pronunciar cualquier discurso con los labios.
Ahora, en vísperas de la conferencia de gráficos por computadora
SIGGRAPH 2017 , el mismo grupo de investigadores ha publicado un nuevo
trabajo científico con una versión avanzada de "contrapartes digitales".
Ahora, al enseñar el programa, no solo se utilizan fotografías, sino también videos, por lo que la capacitación se ha vuelto mucho más efectiva. Para demostrar la tecnología, los científicos han elegido un personaje famoso: el ex presidente de Estados Unidos, Barack Obama. Esta es una buena opción, porque Internet tiene una gran cantidad de material de video HD. Millones de cuadros de video están disponibles para entrenar una red neuronal.
La red neuronal ha estudiado en detalle las características de las expresiones faciales de Obama: movimientos de los labios en cada sonido, aparición de arrugas cerca de los ojos, cambios en la forma de las cejas y la inclinación de la cabeza. La expresión facial del personaje experimental se asoció con los sonidos que pronuncia: la red neuronal procesó no solo los fotogramas de los videos, sino también las pistas de audio.
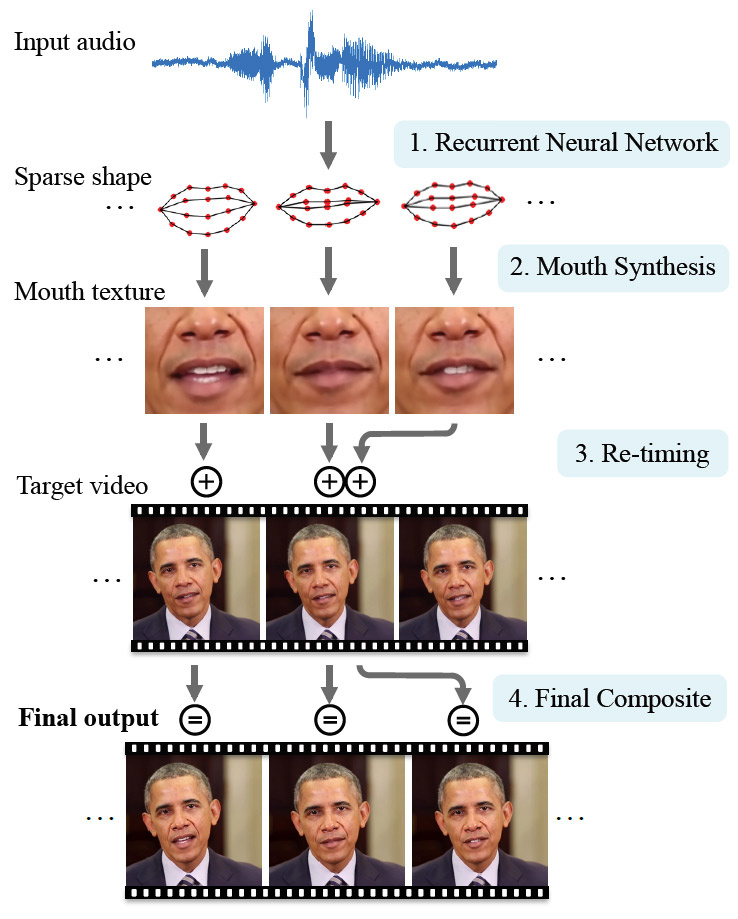
Por lo tanto, una IA débil aprendió a sincronizar las expresiones faciales y los movimientos de los labios con cualquier discurso arbitrario que los investigadores alimentan a la entrada de una red neuronal.
En un avance para el trabajo científico, se comparan grabaciones de video de la vida real de los discursos de Obama y el resultado sintetizado por una red neuronal.
Cabe señalar que el resultado sintetizado difiere notablemente del original, pero aún se ve muy realista.
Los investigadores enfatizan que antes, para obtener "dobles digitales", las personas se veían obligadas a repetir repetidamente las mismas frases frente a las cámaras para registrar todas las combinaciones de morfemas y expresiones faciales. Ahora puede hacerlo en videos disponibles públicamente. Es cierto que no todas las personas en Internet tienen suficientes materiales de video para fingir su personalidad, pero con el tiempo, los propios usuarios resuelven este problema al subir gigabytes de sus fotos y videos a las redes sociales.
Desde un punto de vista práctico, esta tecnología también se puede utilizar. Por ejemplo, Ira Kemelmacher-Shlizerman, uno de los coautores del trabajo científico,
dice que mejorará la calidad de la videoconferencia al sintetizar los cuadros faltantes si se caen del flujo de video. Si el sonido se produce sin interferencias y el video se retrasa, dicha síntesis complementará la imagen o aumentará su resolución. Por supuesto, la tecnología puede encontrar aplicación en juegos de computadora y realidad virtual si el jugador se comunica con un personaje virtual. Ahora el discurso del personaje virtual se volverá más realista, y puede ser una copia digital de alguna persona real. Por ejemplo, puede "revivir" alguna figura histórica del pasado reciente solo mediante sus grabaciones de audio. Por supuesto, será más fácil crear falsificaciones con fines políticos. Si ahora se
moldean en "Photoshop" y se lanzan a las redes sociales , en el futuro se mostrarán videos falsos en la televisión.
Los autores reconocen que la tecnología hasta ahora no es perfecta. Por ejemplo, si Obama aparta un poco su rostro de la cámara, entonces partes de su boca pueden separarse de su rostro y superponerse con el fondo. Pero estos son errores menores que pueden corregirse mediante entrenamiento adicional de la red neuronal.
Otro inconveniente del modelo creado es que no modela las emociones. Las expresiones faciales son absolutamente neutrales y casi siempre iguales. Por lo tanto, en algunos casos, el doble digital pierde su realismo: su expresión facial parece demasiado seria para las frívolas palabras que pronuncia. O viceversa: demasiado frívolo para discursos muy serios. Sin embargo, tales incidentes ocurren con políticos reales en la vida real.

La tecnología creada es similar en principio a trabajar en un
programa para crear dobles digitales Face2Face , donde las expresiones faciales y el habla de una persona se transfieren a la cara de otra. En su trabajo científico, los autores de Washington comparan los resultados de su red neuronal con Face2Face. Explican que en el caso de Face2Face, siempre se requiere una transmisión de video para simular, y su modelo solo funciona mediante grabación de sonido.