
A principios del siglo XX, Wilhelm von Austin, un entrenador y matemático alemán de caballos, anunció al mundo que había enseñado a un caballo a contar. Durante años, von Austin viajó por Alemania con una demostración de este fenómeno. Le pidió a su caballo, apodado
Clever Hans (
trotón Orlov de raza), que calculara los resultados de ecuaciones simples. Hans respondió, golpeando su casco. ¿Dos más dos? Cuatro golpes
Pero los científicos no creían que Hans fuera tan inteligente como von Austin afirmó. El psicólogo
Karl Stumpf realizó una investigación exhaustiva, que se denominó el "Comité Hans". Descubrió que Smart Hans no resuelve ecuaciones, sino que responde a señales visuales. Hans golpeó su casco hasta que obtuvo la respuesta correcta, después de lo cual su entrenador y una multitud entusiasta estallaron en gritos. Y luego se detuvo. Cuando no vio estas reacciones, continuó tocando.
La informática puede aprender mucho de Hans. El ritmo acelerado de desarrollo en esta área sugiere que la mayor parte de la IA que creamos ha entrenado lo suficiente como para proporcionar las respuestas correctas, pero realmente no comprende la información. Y es fácil engañar.
Los algoritmos de aprendizaje automático se convirtieron rápidamente en pastores que todo lo ven del rebaño humano. El software nos conecta a Internet, monitorea el spam y el contenido malicioso en nuestro correo, y pronto conducirá nuestros autos. Su engaño cambia la base tectónica de Internet y amenaza nuestra seguridad en el futuro.
Pequeños grupos de investigación, de la Universidad Estatal de Pensilvania, de Google, del ejército de EE. UU., Están desarrollando planes para protegerse contra posibles ataques contra la IA. Las teorías presentadas en el estudio dicen que un atacante puede cambiar lo que "ve" un robot robótico. O active el reconocimiento de voz en el teléfono y forzarlo a ingresar a un sitio web malicioso utilizando sonidos que solo serán ruido para una persona. O deje que el virus se filtre a través del firewall de la red.
 A la izquierda está la imagen del edificio, a la derecha está la imagen modificada, que la red neuronal profunda se relaciona con las avestruces. En el medio, se muestran todos los cambios aplicados a la imagen principal.
A la izquierda está la imagen del edificio, a la derecha está la imagen modificada, que la red neuronal profunda se relaciona con las avestruces. En el medio, se muestran todos los cambios aplicados a la imagen principal.En lugar de tomar el control del control de un robot robótico, este método le muestra algo así como una alucinación, una imagen que en realidad no existe.
Tales ataques usan imágenes con un truco [ejemplos adversos: no existe un término ruso establecido, textualmente resulta algo así como "ejemplos con contraste" o "ejemplos rivales" - aprox. transl.]: imágenes, sonidos, textos que parecen normales para las personas pero que son percibidos por una máquina completamente diferente. Los pequeños cambios realizados por los atacantes pueden hacer que la red neuronal profunda saque conclusiones erróneas sobre lo que muestra.
"Cualquier sistema que utilice el aprendizaje automático para tomar decisiones críticas para la seguridad es potencialmente vulnerable a este tipo de ataque", dijo Alex Kanchelyan, investigador de la Universidad de Berkeley que estudia los ataques de aprendizaje automático utilizando imágenes falsas.
Conocer estos matices en las primeras etapas del desarrollo de IA les brinda a los investigadores una herramienta para comprender cómo corregir estas deficiencias. Algunos ya han asumido esto, y dicen que sus algoritmos se han vuelto más y más eficientes debido a esto.
La mayor parte del flujo principal de investigación de IA se basa en redes neuronales profundas, que a su vez se basan en un campo más amplio de aprendizaje automático. Las tecnologías MoD utilizan cálculos y estadísticas diferenciales e integrales para crear el software utilizado por la mayoría de nosotros, como los filtros de spam en el correo o la búsqueda en Internet. En los últimos 20 años, los investigadores han comenzado a aplicar estas técnicas a una nueva idea, las redes neuronales: estructuras de software que imitan la función cerebral. La idea es descentralizar los cálculos a través de miles de ecuaciones pequeñas ("neuronas") que reciben datos, los procesan y los transmiten aún más, a la siguiente capa de miles de ecuaciones pequeñas.
Estos algoritmos de IA se entrenan de la misma manera que en el caso de MO, que, a su vez, copia el proceso de aprendizaje de una persona. Se muestran ejemplos de diferentes cosas y sus etiquetas asociadas. Muestre a la computadora (o al niño) la imagen de un gato, diga que el gato se ve así, y el algoritmo aprenderá a reconocer a los gatos. Pero para esto, la computadora tendrá que ver miles y millones de imágenes de gatos y gatos.
Los investigadores han descubierto que estos sistemas pueden ser atacados con datos engañosos especialmente seleccionados, a los que llamaron "ejemplos adversos".
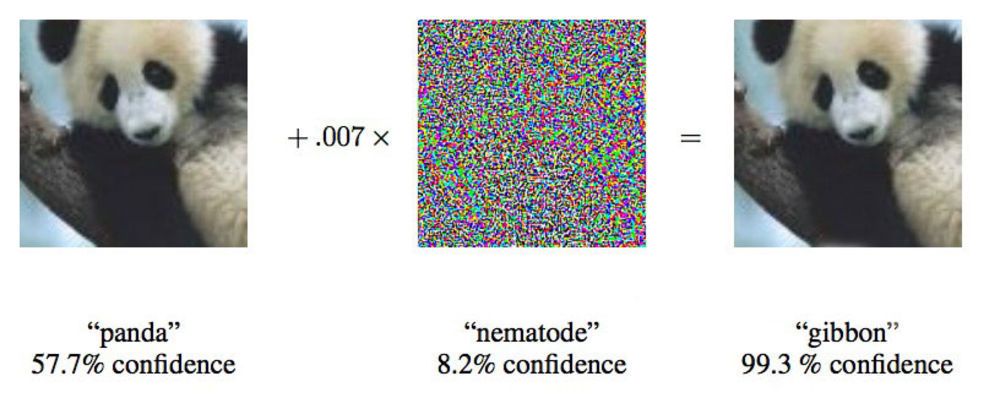 En un artículo de 2015, los investigadores de Google mostraron que las redes neuronales profundas pueden verse obligadas a atribuir esta imagen de un panda a los gibones.
En un artículo de 2015, los investigadores de Google mostraron que las redes neuronales profundas pueden verse obligadas a atribuir esta imagen de un panda a los gibones."Te mostramos una foto que muestra claramente el autobús escolar y te hace pensar que es un avestruz", dijo Ian Goodfellow, un investigador de Google que está trabajando activamente en tales ataques en redes neuronales.
Cambiando las imágenes proporcionadas a las redes neuronales en solo un 4%, los investigadores pudieron engañarlas para que cometieran errores con la clasificación en el 97% de los casos. Incluso si no supieran exactamente cómo procesa las imágenes la red neuronal, podrían engañarla en el 85% de los casos.
La última variante de fraude sin datos en la arquitectura de red se llama "ataque de caja negra". Este es el primer caso documentado de un ataque funcional de este tipo en una red neuronal profunda, y su importancia es que aproximadamente en este escenario pueden tener lugar ataques en el mundo real.
En el estudio, investigadores de la Universidad Estatal de Pensilvania, Google y el Laboratorio de Investigación de la Marina de los EE. UU. Atacaron una red neuronal que clasifica las imágenes respaldadas por el proyecto MetaMind y sirve como una herramienta en línea para desarrolladores. El equipo construyó y entrenó la red atacada, pero su algoritmo de ataque funcionó independientemente de la arquitectura. Con dicho algoritmo, pudieron engañar a la red neuronal de la caja negra con una precisión del 84,24%.
 La fila superior de fotos y personajes: reconocimiento correcto de caracteres.
La fila superior de fotos y personajes: reconocimiento correcto de caracteres.
Fila inferior: la red se vio obligada a reconocer signos completamente incorrectos.El suministro de datos inexactos a las máquinas no es una idea nueva, pero Doug Tygar, profesor de la Universidad de Berkeley, que ha estado estudiando el aprendizaje automático durante 10 años en contraste, dice que esta tecnología de ataque ha evolucionado desde un simple MO a redes neuronales profundas complejas. Los hackers maliciosos han estado utilizando esta técnica en filtros de spam durante años.
La investigación de Tiger proviene de
su trabajo en
2006 sobre ataques de este tipo en una red con el Ministerio de Defensa, que
amplió en 2011 con la ayuda de investigadores de la Universidad de California en Berkeley y Microsoft Research. El equipo de Google, el primero en utilizar redes neuronales profundas, publicó su
primer trabajo en 2014, dos años después de descubrir la posibilidad de tales ataques. Querían asegurarse de que esto no fuera algún tipo de anomalía, sino una posibilidad real. En 2015, publicaron otro
trabajo en el que describieron una forma de proteger las redes y aumentar su eficiencia, y desde entonces, Ian Goodfellow ha dado consejos sobre otros trabajos científicos en esta área, incluido
el ataque de la caja negra .
Los investigadores llaman a la idea más general de información poco confiable "datos bizantinos", y gracias al progreso de la investigación, han llegado al aprendizaje profundo. El término proviene de la conocida "
tarea de los generales bizantinos "
, un experimento mental en el campo de la informática, en el que un grupo de generales debe coordinar sus acciones con la ayuda de mensajeros, sin tener la confianza de que uno de ellos es un traidor. No pueden confiar en la información recibida de sus colegas.
"Estos algoritmos están diseñados para manejar el ruido aleatorio, pero no los datos bizantinos", dice Taigar. Para comprender cómo funcionan estos ataques, Goodfello sugiere imaginar una red neuronal en forma de diagrama de dispersión.
Cada punto en el diagrama representa un píxel de la imagen procesada por la red neuronal. Por lo general, la red intenta dibujar una línea a través de los datos que mejor se ajustan al conjunto de todos los puntos. En la práctica, esto es un poco más complicado, porque diferentes píxeles tienen diferentes valores para la red. En realidad, este es un gráfico multidimensional complejo procesado por una computadora.
Pero en nuestra analogía simple de un diagrama de dispersión, la forma de la línea dibujada a través de los datos determina lo que la red cree que ve. Para un ataque exitoso en tales sistemas, los investigadores necesitan cambiar solo una pequeña parte de estos puntos y hacer que la red tome una decisión que en realidad no existe. En el ejemplo de un autobús que parece un avestruz, la foto del autobús escolar está salpicada de píxeles dispuestos de acuerdo con el patrón asociado con las características únicas de las fotos de avestruz familiares para la red. Este es un contorno invisible para el ojo, pero cuando el algoritmo
procesa y simplifica los datos , los puntos de datos extremos para el avestruz le parecen una opción de clasificación adecuada. En la versión de caja negra, los investigadores probaron trabajar con diferentes datos de entrada para determinar cómo el algoritmo ve ciertos objetos.
Al dar una entrada falsa al clasificador de objetos y al estudiar las decisiones tomadas por la máquina, los investigadores pudieron restaurar el algoritmo para engañar al sistema de reconocimiento de imágenes. Potencialmente, tal sistema en robomobiles en este caso puede ver la señal de "ceder el paso" en lugar de la señal de stop. Cuando entendieron cómo funcionaba la red, pudieron hacer que la máquina viera cualquier cosa.
 Un ejemplo de cómo el clasificador de imágenes dibuja diferentes líneas dependiendo de los diferentes objetos en la imagen. Los ejemplos falsos pueden considerarse valores extremos en el gráfico.
Un ejemplo de cómo el clasificador de imágenes dibuja diferentes líneas dependiendo de los diferentes objetos en la imagen. Los ejemplos falsos pueden considerarse valores extremos en el gráfico.Los investigadores dicen que dicho ataque puede ingresarse directamente en el sistema de procesamiento de imágenes, sin pasar por la cámara, o estas manipulaciones pueden llevarse a cabo con una señal real.
Pero la especialista en seguridad de la Universidad de Columbia, Alison Bishop, dijo que tal pronóstico no es realista y depende del sistema utilizado en el robot robótico. Si los atacantes ya tienen acceso al flujo de datos desde la cámara, ya pueden darle cualquier entrada.
"Si pueden llegar a la entrada de la cámara, esas dificultades no son necesarias", dice ella. "Puedes mostrarle la señal de alto".
Otros métodos de ataque, además de pasar por alto la cámara, por ejemplo, dibujar marcas visuales en una señal real, parecen obvios para ser poco probable. Duda que las cámaras de baja resolución utilizadas en robomobiles en general puedan distinguir entre pequeños cambios en el letrero.
 La imagen prístina de la izquierda está clasificada como un autobús escolar. Corregido a la derecha, como un avestruz. En el medio - la imagen cambia.
La imagen prístina de la izquierda está clasificada como un autobús escolar. Corregido a la derecha, como un avestruz. En el medio - la imagen cambia.Dos grupos, uno en la Universidad de Berkeley y el otro en la Universidad de Georgetown, han desarrollado con éxito algoritmos que pueden emitir comandos de voz a asistentes digitales como Siri y Google Now, que suenan como un ruido inaudible. Para una persona, tales comandos parecerán ruido aleatorio, pero al mismo tiempo pueden dar comandos a dispositivos como Alexa, no previstos por su propietario.
Nicholas Carlini, uno de los investigadores en ataques de audio bizantinos, dice que en sus pruebas pudieron activar los programas de reconocimiento de audio de código abierto, Siri y Google Now, con una precisión de más del 90%.
El ruido es como una especie de negociación alienígena de ciencia ficción. Esta es una mezcla de ruido blanco y una voz humana, pero no se parece en nada a un comando de voz.
Según Carlini, en tal ataque, cualquiera que escuche el ruido de un teléfono (si bien es necesario planear ataques en iOS y Android por separado) puede verse obligado a ir a una página web que también reproduce ruido, lo que infectará los teléfonos ubicados cerca. O esta página puede descargar silenciosamente un programa de malware. También es posible que tales ruidos se pierdan en la radio y estén ocultos en el ruido blanco o en paralelo con otra información de audio.
Tales ataques pueden ocurrir porque la máquina está entrenada para garantizar que casi cualquier información contenga información importante, así como que una cosa es más común que la otra, como explica Goodfello.
Engañar a la red, obligándola a creer que ve un objeto común, es más fácil, porque cree que debería ver esos objetos con más frecuencia. Por lo tanto, Goodfellow y otro grupo de la Universidad de Wyoming lograron que la red clasificara imágenes que no existían en absoluto: identificó objetos en ruido blanco, creó píxeles aleatorios en blanco y negro.
En un estudio de Goodfellow, el ruido blanco aleatorio que pasaba a través de una red fue clasificado por ella como un caballo. Casualmente, esto nos lleva de vuelta a la historia de Clever Hans, un caballo no muy dotado matemáticamente.
Goodfellow dice que las redes neuronales, como Smart Hans, en realidad no aprenden ideas, sino que solo aprenden a descubrir cuándo encuentran la idea correcta. La diferencia es pequeña pero importante. La falta de conocimiento fundamental facilita los intentos maliciosos de recrear la apariencia de encontrar los resultados del algoritmo "correcto", que de hecho resultan ser falsos. Para comprender qué es algo, una máquina también debe comprender lo que no es.
Goodfello, después de haber capacitado a la red para clasificar imágenes tanto en imágenes naturales como en imágenes procesadas (falsas), descubrió que no solo podía reducir la efectividad de tales ataques en un 90%, sino que también hacía que la red afrontara mejor la tarea inicial.
"Al hacer posible explicar imágenes falsas realmente inusuales, puede obtener una explicación aún más confiable de los conceptos subyacentes", dice Goodfellow.
Dos grupos de investigadores de audio utilizaron un enfoque similar al del equipo de Google, protegiendo sus redes neuronales de sus propios ataques mediante sobreentrenamiento. También lograron éxitos similares, reduciendo su eficiencia de ataque en más del 90%.
No es sorprendente que esta área de investigación interese al ejército estadounidense. El Laboratorio de Investigación del Ejército incluso patrocinó dos de los trabajos más recientes sobre este tema, incluido el ataque de la caja negra. Y aunque la agencia está financiando la investigación, esto no significa que la tecnología se vaya a utilizar en la guerra. Según el representante del departamento, pueden pasar hasta 10 años desde la investigación hasta las tecnologías adecuadas para el uso de un soldado.
Ananthram Swami, investigador del Laboratorio del Ejército de EE. UU., Ha participado en varios trabajos recientes relacionados con el engaño de la IA. El ejército está interesado en la cuestión de detectar y detener datos fraudulentos en nuestro mundo, donde no todas las fuentes de información se pueden verificar cuidadosamente. Swami señala un conjunto de datos obtenidos de sensores públicos ubicados en universidades y que trabajan en proyectos de código abierto.
“No siempre controlamos todos los datos. Es bastante fácil para nuestro adversario engañarnos ", dice Swami. "En algunos casos, las consecuencias de tal fraude pueden ser frívolas, en algunos casos lo contrario".
También dice que el ejército está interesado en robots autónomos, tanques y otros vehículos, por lo que el objetivo de dicha investigación es obvio. Al estudiar estos problemas, el ejército podrá ganar ventaja en el desarrollo de sistemas que no sean susceptibles a ataques de este tipo.
Pero cualquier grupo que use una red neuronal debería tener preocupaciones sobre el potencial de ataques con falsificación de IA. El aprendizaje automático y la IA están en su infancia, y las fallas de seguridad pueden tener graves consecuencias en este momento. Muchas compañías confían información altamente sensible a los sistemas de IA que no han pasado la prueba del tiempo. Nuestras redes neuronales aún son demasiado jóvenes para que sepamos todo lo que necesitamos sobre ellas.
Una supervisión similar llevó
al bot de Twitter de Microsoft, Tay , a convertirse rápidamente en racista con una inclinación por el genocidio. El flujo de datos maliciosos y la función "repetir después de mí" llevaron al hecho de que Tay se desvió en gran medida de la ruta prevista. El bot fue engañado por una entrada deficiente, y esto sirve como un ejemplo conveniente de una implementación deficiente del aprendizaje automático.
Kanchelyan dice que no cree que las posibilidades de tales ataques se hayan agotado después de una investigación exitosa realizada por el equipo de Google.
"En el área de seguridad informática, los atacantes siempre están por delante de nosotros", dice Kanchelyan. "Será bastante peligroso afirmar que hemos resuelto todos los problemas con el engaño de las redes neuronales mediante su entrenamiento repetido".