Network Security Services (
NSS ) es un conjunto de bibliotecas utilizadas en el desarrollo multiplataforma de aplicaciones seguras de cliente y servidor.
El paquete NSS, como OpenSSL, proporciona la capacidad de utilizar utilidades de línea de comandos para implementar diversas funciones PKI (generación de claves, emisión de certificados x509v3, trabajo con firmas electrónicas, soporte TLS, etc.). Una de estas utilidades, Pretty-print (PP), le permite ver convenientemente el contenido del certificado x509 v3 y la firma electrónica (pkcs # 7), etc. Además, el certificado puede estar en las codificaciones DER y PEM:
bash-4.3$ pp -h Usage: pp [-t type] [-a] [-i input] [-o output] [-w] [-u] Pretty prints a file containing ASN.1 data in DER or ascii format. -t type Specify input and display type: public-key (pk), certificate (c), certificate-request (cr), certificate-identity (ci), pkcs7 (p7), crl or name (n). (Use either the long type name or the shortcut.) -a Input is in ascii encoded form (RFC1113) -i input Define an input file to use (default is stdin) -o output Define an output file to use (default is stdout) -w Don't wrap long output lines -u Use UTF-8 (default is to show non-ascii as .) bash-4.3$
Además, la presencia del parámetro –u (codificación UTF-8) permite ver el certificado en codificación rusa. Pero al
observar detenidamente las capturas de pantalla de la GUI de las utilidades de línea de comandos del paquete NSS, observa que algunos de los datos del certificado simplemente desaparecieron:
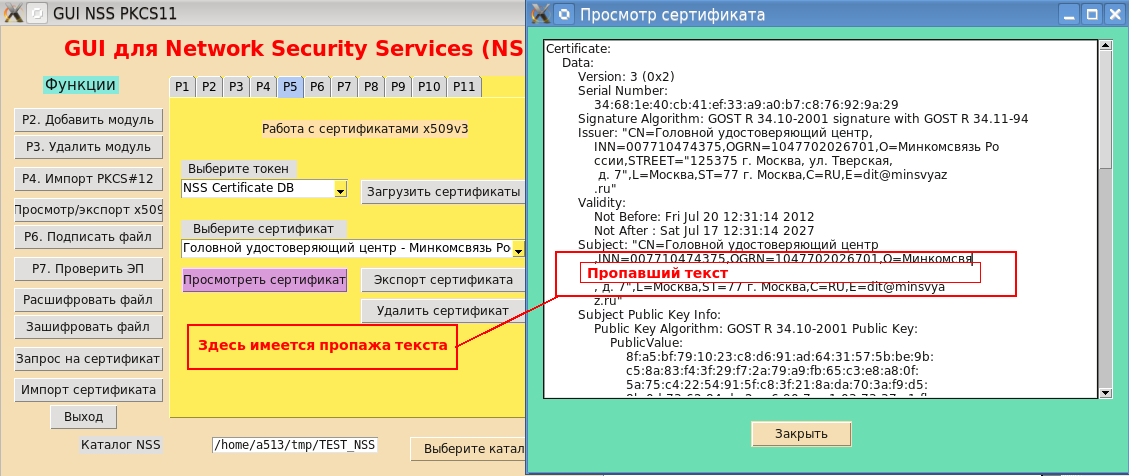
Comenzó la búsqueda de la información faltante. La utilidad "cute print" (que es cómo se traduce Pretty-print) para ver el certificado raíz de la CA principal del Ministerio de Comunicaciones se lanzó en la línea de comando:
$pp – certificate –u –i _.cer … Subject: "CN= ,INN=007710474375,OGRN=1047702026701,O= ,STREET="125375 . , . , . 7",L=,ST=77 . ,C=RU,E=dit@minsvya z.ru" …. $
El resultado confirmó la pérdida de datos. Además, en la pantalla aparecieron dos símbolos que no se pueden mostrar (¿un rombo de color negro con un signo de interrogación?). El análisis mostró que estos caracteres no visualizables tienen códigos 0xD0 y 0xBE, respectivamente:
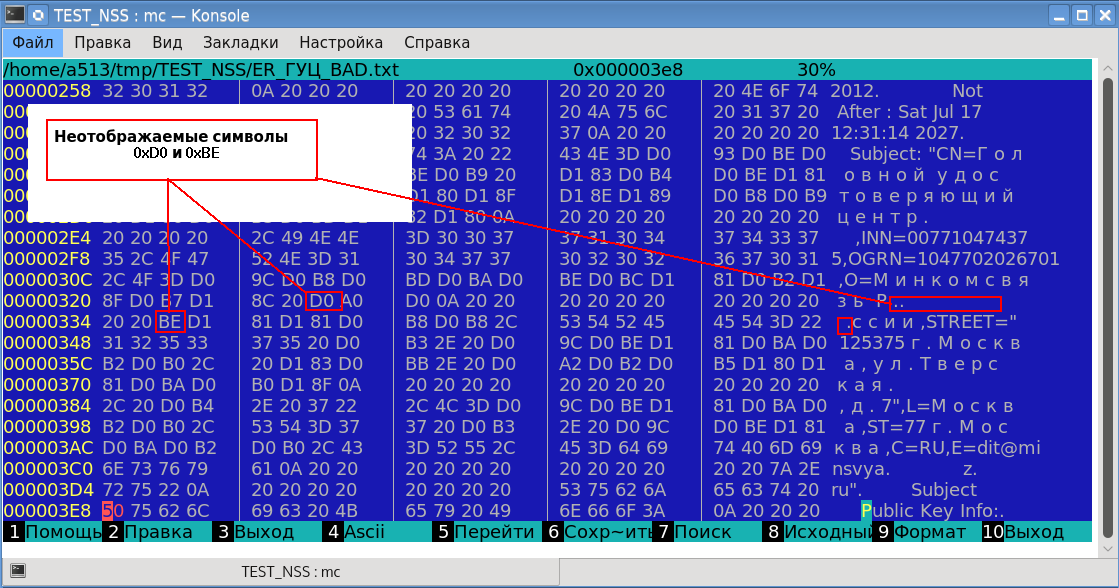
La letra rusa "o" desapareció con una representación hexadecimal en codificación UTF-8 como 0xD00xBE. Y los códigos 0xD0 y 0xBE son nuestros caracteres no visualizables. ¿Y qué tipo de caracteres aparecieron entre estos bytes? Y esta es una impresión "bonita": símbolos de alineación del texto impreso.
Que paso La entrada de una impresión "agradable" (archivo /nss/cmd/lib/secutil.c, función secu_PrintRawStringQuotesOptional) recibe datos en forma de SECITEM, es decir direcciones por conjunto de bytes y su longitud:
for (i = 0; i < si->len; i++) { unsigned char val = si->data[i]; unsigned char c; if (SECU_GetWrapEnabled() && column > 76) { SECU_Newline(out); SECU_Indent(out, level); column = level * INDENT_MULT; } if (utf8DisplayEnabled) { if (val < 32) c = '.'; else c = val; } else { c = printable[val]; } fprintf(out, "%c", c); column++; }
Y si (SECU_GetWrapEnabled () == True) se proporciona para una buena impresión (la utilidad PP no tiene un parámetro –w) y el número de bytes en una línea excede 76 (columna> 76), entonces, después del siguiente carácter, una nueva línea (SECU_Newline) y las sangrías necesarias (SECU_Indent ) Al mismo tiempo, ninguno de los desarrolladores pensó que si se usa la codificación UTF-8 (utf8DisplayEnabled), la belleza solo puede inducirse después del siguiente carácter, y no byte, ya que el concepto de un byte y un carácter en la codificación UTF-8 puede no coincidir . Si hablamos de letras rusas, cada una de ellas
está codificada en dos bytes. Tal brecha ocurrió con nuestra letra rusa "o" (0xD00xBE).
¿Cuál es la salida? Todo es lo suficientemente simple en la función secu_PrintRawStringQuotesOptional para reemplazar la línea:
if (SECU_GetWrapEnabled() && column > 76) {
en una línea de la siguiente forma:
if (SECU_GetWrapEnabled() && column > 76 && (val <= 0x7F || val == 0xD0 || val == 0xD1)) {
Si ahora reconstruye la utilidad PP e la instala en el sistema, entonces la impresión "agradable" justificará su nombre para el "excelente, poderoso, verdadero y gratuito idioma ruso". (I.S. Turgenev):
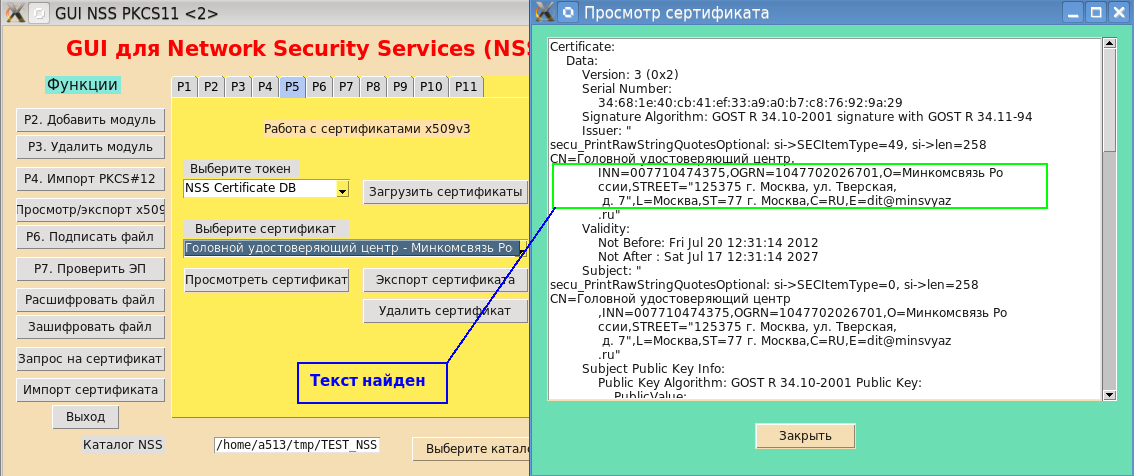
Si hablamos de la belleza de la impresión, sería posible agregar guiones no solo por el número de caracteres en la línea, sino más correctamente, por ejemplo, por espacio, coma, dos puntos y otros caracteres. No estoy hablando del análisis semántico de la transferencia. Pero esto ya es un área de inteligencia artificial.
Y finalmente, esta es la segunda inexactitud descubierta en las utilidades de NSS. El primero fue descubierto en la utilidad
oidcalc .