¿Cómo se comportan los mercados de Bitcoin? ¿Cuáles son las razones del repentino aumento y caída de los precios de las criptomonedas? ¿Existe una estrecha conexión inseparable entre los mercados de altcoin o son en su mayoría independientes entre sí? ¿Cómo podemos predecir lo que sucederá en el futuro?
Enfoque analítico de información para el razonamiento de criptomonedas
Los artículos dedicados a las criptomonedas como Bitcoin y Ethereum abundan en razonamientos y teorías. Cientos de autoproclamados expertos abogan por tendencias que creen que se mostrarán pronto. Lo que muchos de estos análisis carecen con certeza es una base sólida en forma de datos y estadísticas que puedan respaldar ciertas declaraciones.
El propósito de este artículo es proporcionar una introducción simple al análisis de criptomonedas usando Python. En él, veremos paso a paso un simple script de Python para recibir, analizar y visualizar datos en varias criptomonedas. En el curso del trabajo, descubriremos una tendencia interesante en el comportamiento de los mercados volátiles y descubriremos qué cambios han ocurrido en ellos.

Esta publicación no estará dedicada a explicar qué son las criptomonedas (si necesita tal explicación, le recomendaría esta excelente
revisión ). No habrá discusión sobre qué monedas específicas subirán o bajarán de valor. En cambio, la guía se centrará en obtener acceso a datos brutos y sin procesar y en encontrar el historial oculto bajo capas de números.
Etapa 1. Equipamos nuestro laboratorio.
Esta guía está destinada a una amplia gama de entusiastas, ingenieros y profesionales del procesamiento de datos, independientemente de su nivel de profesionalismo. A partir de las habilidades, solo necesitará una comprensión básica de Python y las habilidades mínimas de línea de comando necesarias para configurar el proyecto.
La versión completa del trabajo realizado y todos sus resultados están disponibles
aquí .
1.1 Instalar Anaconda
La forma más fácil de instalar dependencias desde cero para este proyecto es utilizar Anaconda, un ecosistema de Python y administrador de dependencias que contiene todos los paquetes necesarios para trabajar con datos y analizarlos.
Para instalar Anaconda, recomendaría usar las instrucciones oficiales disponibles
aquí .
Si eres un usuario avanzado, y Anaconda no es de tu agrado, entonces no es necesario instalarlo. En este caso, creo que no necesita ayuda para instalar las dependencias necesarias, y puede pasar directamente a la segunda etapa.1.2 Configuración del entorno del proyecto en Anaconda
Tan pronto como se instale Anaconda, querremos crear un nuevo entorno para organizar el trabajo con dependencias.
Ingrese el comando
conda create --name cryptocurrency-analysis python=3 para crear un nuevo entorno Anaconda para nuestro proyecto.
Luego, ingrese la
source activate cryptocurrency-analysis y (en Linux / macOS) o
activate cryptocurrency-analysis (en Windows) para activar el entorno.
Y finalmente, el
conda install numpy pandas nb_conda jupyter plotly quandl instalará las dependencias necesarias en el entorno. Este proceso puede llevar varios minutos.
¿Por qué usamos el medio ambiente? Si planea trabajar simultáneamente con muchos proyectos de Python en su computadora, es útil colocar las dependencias (bibliotecas de software y paquetes) por separado para evitar conflictos. Dentro de cada proyecto, Anaconda crea un directorio especial para dependencias en el entorno, que le permite separarlos de las dependencias de otros proyectos y organizar el trabajo con ellos.1.3 Lanzamiento del cuaderno interactivo Jupyter Notebook
Una vez que el entorno y las dependencias estén instaladas, escriba
jupyter notebook en la consola para iniciar el kernel de iPython y abra el enlace
http: // localhost: 8888 / en el navegador. Cree un nuevo cuaderno de Python, verificando que usa el núcleo de
Python [conda env:cryptocurrency-analysis] .

1.4 Importar dependencias a la parte superior del cuaderno
Tan pronto como vea un registro limpio de Jupyter, primero deberá importar las dependencias necesarias.
import os import numpy as np import pandas as pd import pickle import quandl from datetime import datetime
Además, debe importar Plotly y habilitar el modo fuera de línea para ello.
import plotly.offline as py import plotly.graph_objs as go import plotly.figure_factory as ff py.init_notebook_mode(connected=True)
Etapa 2. Obtención de datos de precios de Bitcoin
Ahora que todas las configuraciones están completas, estamos listos para comenzar a recibir información para su análisis. En primer lugar, necesitamos solicitar datos de precios de Bitcoin utilizando la
API gratuita
Bitcoin API Quandl .
2.1 Definir una función auxiliar Quandl
Para ayudar con la adquisición de datos, definiremos una función que descarga y almacena en caché los conjuntos de datos de Quandl.
def get_quandl_data(quandl_id): '''Download and cache Quandl dataseries''' cache_path = '{}.pkl'.format(quandl_id).replace('/','-') try: f = open(cache_path, 'rb') df = pickle.load(f) print('Loaded {} from cache'.format(quandl_id)) except (OSError, IOError) as e: print('Downloading {} from Quandl'.format(quandl_id)) df = quandl.get(quandl_id, returns="pandas") df.to_pickle(cache_path) print('Cached {} at {}'.format(quandl_id, cache_path)) return df
Para convertir los datos descargados y guardarlos en un archivo, usaremos
pickle . Esto evitará que los mismos datos se descarguen nuevamente cada vez que ejecutemos el script. La función devolverá datos como un marco de datos
Pandas . Si no está familiarizado con los marcos de datos, puede presentarlos en forma de hojas de cálculo muy potentes.
2.2 Tomamos datos de precios del intercambio de Kraken
Para comenzar, obtengamos los datos históricos sobre el tipo de cambio de Bitcoin del intercambio de
Kraken .
# Pull Kraken BTC price exchange data btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')
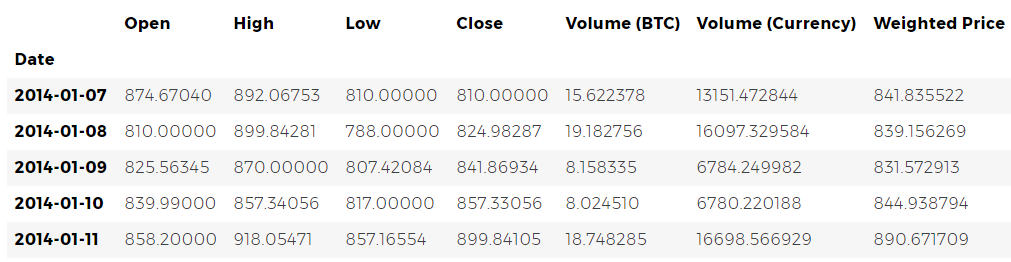
Podemos verificar las primeras 5 filas del marco de datos utilizando el método
head() .
btc_usd_price_kraken.head()
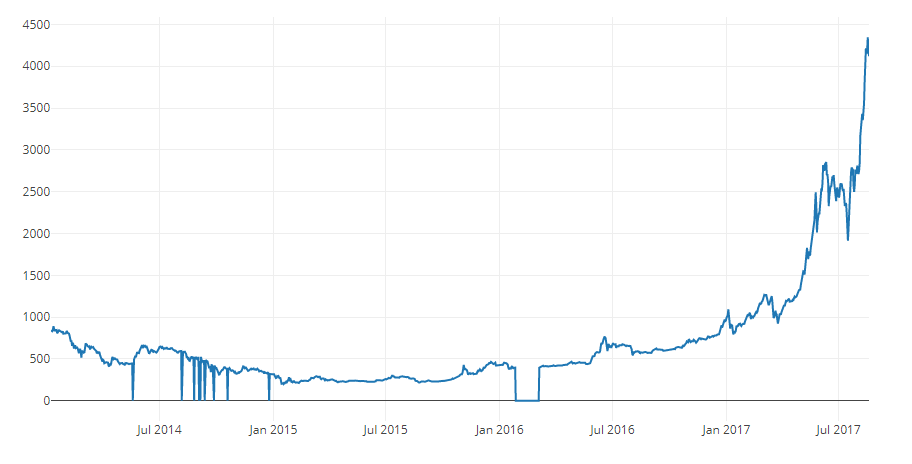
A continuación, generemos un gráfico simple para una verificación visual rápida de la exactitud de los datos.
# Chart the BTC pricing data btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price']) py.iplot([btc_trace])
Para la visualización,
Plotly se usa
aquí . Este es un enfoque menos tradicional en comparación con las bibliotecas de visualización de Python más autorizadas como
Matplotlib , pero en mi opinión, Plotly es una excelente opción, ya que le permite crear gráficos totalmente interactivos mediante el uso de
D3.js. Como resultado, puede obtener buenos diagramas visuales en la salida sin ninguna configuración. Además, Plotly es fácil de aprender y sus resultados se insertan fácilmente en las páginas web.
Por supuesto, siempre debe recordar la necesidad de comparar las visualizaciones resultantes con gráficos de precios de criptomonedas disponibles públicamente (por ejemplo, en Coinbase) para una verificación básica de la confiabilidad de los datos descargados.2.3 Solicitar datos de precios de otros intercambios de BTC
Es posible que haya notado discrepancias en este conjunto: el gráfico se hunde en varios lugares a cero, especialmente a finales de 2014 y principios de 2016. Estas caídas se encuentran en el conjunto de datos de Kraken, y obviamente no queremos que se reflejen en nuestro análisis final de precios.
La naturaleza de los intercambios de bitcoin es tal que los precios están determinados por la oferta y la demanda, y por lo tanto, ninguno de los intercambios existentes puede afirmar que sus cotizaciones reflejan el único precio verdadero, "referencia" de Bitcoin. Para tener en cuenta este inconveniente, así como eliminar la caída del precio en el gráfico, que probablemente se deba a errores técnicos o de conjunto de datos, recopilaremos adicionalmente datos de otros tres grandes intercambios de bitcoin para calcular el índice de precios agregado para bitcoin.
Para comenzar, descarguemos los datos de cada intercambio en un diccionario de marcos de datos.
# Pull pricing data for 3 more BTC exchanges exchanges = ['COINBASE','BITSTAMP','ITBIT'] exchange_data = {} exchange_data['KRAKEN'] = btc_usd_price_kraken for exchange in exchanges: exchange_code = 'BCHARTS/{}USD'.format(exchange) btc_exchange_df = get_quandl_data(exchange_code) exchange_data[exchange] = btc_exchange_df
2.4 Combinando todos los datos de precios en un marco de datos
A continuación, definiremos una función simple que combine las columnas similares de cada marco de datos en un nuevo marco combinado.
def merge_dfs_on_column(dataframes, labels, col): '''Merge a single column of each dataframe into a new combined dataframe''' series_dict = {} for index in range(len(dataframes)): series_dict[labels[index]] = dataframes[index][col] return pd.DataFrame(series_dict)
Ahora, combinemos todos los marcos de datos basados en la columna Precio ponderado.
# Merge the BTC price dataseries' into a single dataframe btc_usd_datasets = merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()), 'Weighted Price')
Finalmente, eche un vistazo a las últimas cinco líneas usando el método
tail() para asegurarse de que el resultado de nuestro trabajo se vea normal.
btc_usd_datasets.tail()

Los precios se ven como se esperaba: están dentro de límites similares, pero existen ligeras diferencias basadas en la relación oferta / demanda en cada intercambio individual.
2.5 Visualizar conjuntos de datos de precios
El siguiente paso lógico es visualizar la comparación de los conjuntos de datos resultantes. Para hacer esto, definimos una función auxiliar que proporciona la capacidad de generar un gráfico basado en un marco de datos utilizando un comando de una sola línea.
def df_scatter(df, title, seperate_y_axis=False, y_axis_label='', scale='linear', initial_hide=False): '''Generate a scatter plot of the entire dataframe''' label_arr = list(df) series_arr = list(map(lambda col: df[col], label_arr)) layout = go.Layout( title=title, legend=dict(orientation="h"), xaxis=dict(type='date'), yaxis=dict( title=y_axis_label, showticklabels= not seperate_y_axis, type=scale ) ) y_axis_config = dict( overlaying='y', showticklabels=False, type=scale ) visibility = 'visible' if initial_hide: visibility = 'legendonly' # Form Trace For Each Series trace_arr = [] for index, series in enumerate(series_arr): trace = go.Scatter( x=series.index, y=series, name=label_arr[index], visible=visibility ) # Add seperate axis for the series if seperate_y_axis: trace['yaxis'] = 'y{}'.format(index + 1) layout['yaxis{}'.format(index + 1)] = y_axis_config trace_arr.append(trace) fig = go.Figure(data=trace_arr, layout=layout) py.iplot(fig)
En aras de la brevedad, no entraré en detalles sobre el funcionamiento de una función auxiliar. Si está interesado en obtener más información al respecto, consulte la
documentación de Pandas y
Plotly .
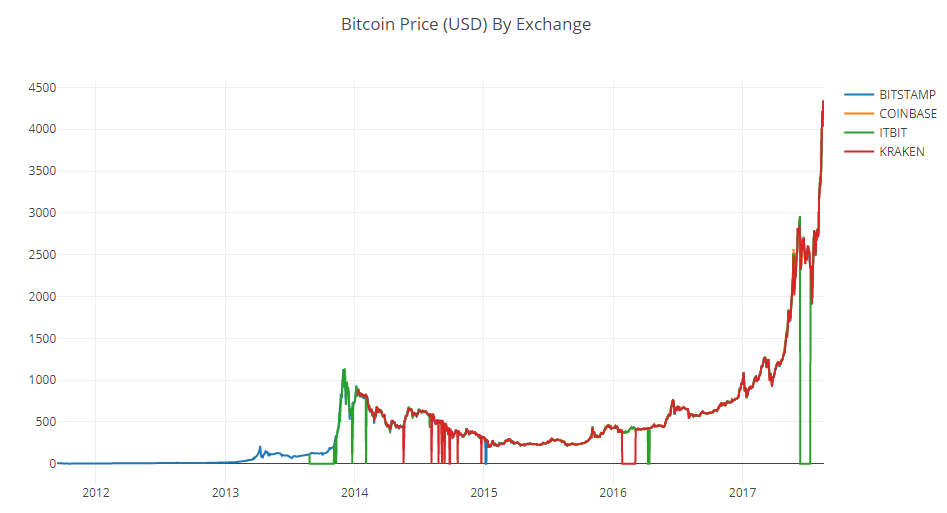
Podemos generar fácilmente un gráfico para datos de precios de bitcoin.
# Plot all of the BTC exchange prices df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
2.6 Limpieza y combinación de datos de precios
Podemos ver que a pesar del hecho de que las 4 series de datos se comportan aproximadamente de la misma manera, hay varias desviaciones de la norma que deben eliminarse.
Eliminemos todos los valores cero del marco, ya que sabemos que el precio de bitcoin nunca ha sido cero dentro del período de tiempo que estamos considerando.
# Remove "0" values btc_usd_datasets.replace(0, np.nan, inplace=True)
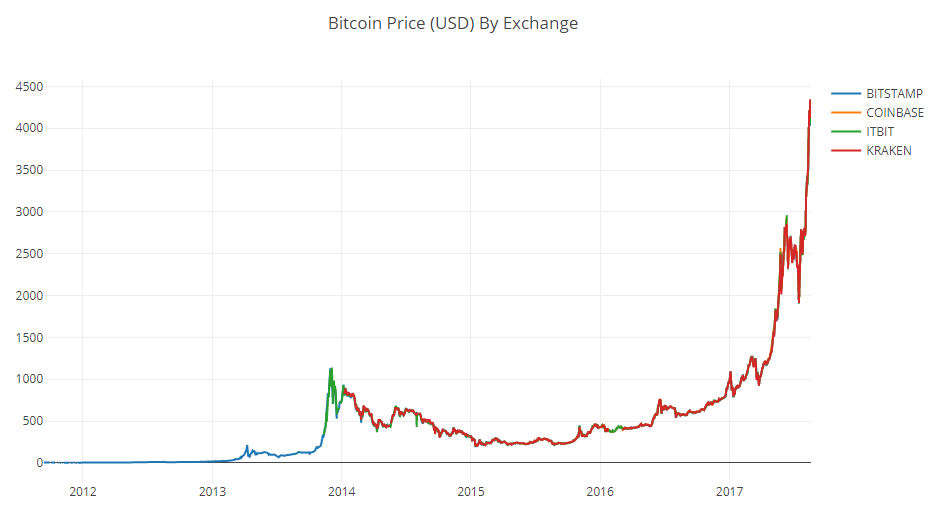
Una vez que construimos el gráfico nuevamente, obtenemos una curva más ordenada, sin ninguna caída pronunciada.
# Plot the revised dataframe df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
Y ahora podemos calcular una nueva columna que contiene el precio promedio diario de bitcoin en función de los datos de todos los intercambios.
# Calculate the average BTC price as a new column btc_usd_datasets['avg_btc_price_usd'] = btc_usd_datasets.mean(axis=1)
¡Esta nueva columna es nuestro índice de precios de Bitcoin! Vamos a trazarlo para asegurarnos de que se vea normal.
# Plot the average BTC price btc_trace = go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd']) py.iplot([btc_trace])
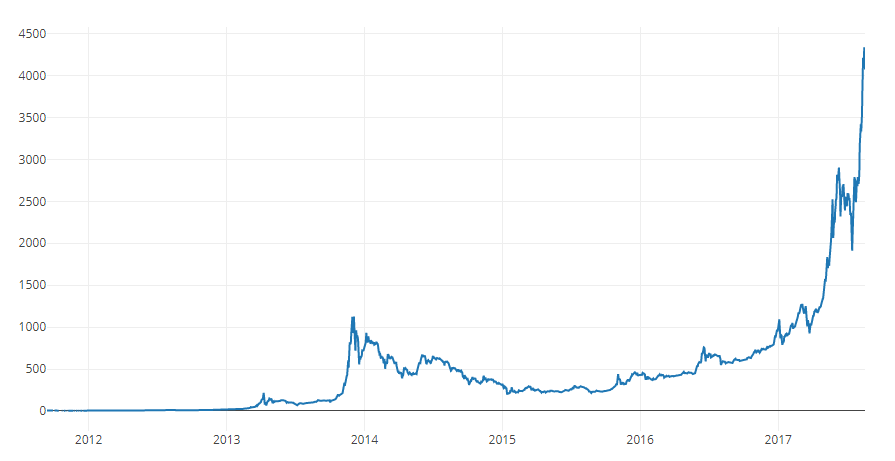
Si, se ve bien. Utilizaremos las series de precios combinados en el futuro para convertir los tipos de cambio de otras criptomonedas en dólares estadounidenses.
Etapa 3. Obtención de datos de precios de altcoin
Ahora que tenemos una serie temporal confiable de precios para bitcoin, solicitemos algunos datos para las criptomonedas que no son bitcoin, que a menudo se llaman altcoins.
3.1 Definición de funciones auxiliares para trabajar con la API de Poloniex
Para obtener datos de altcoin, utilizaremos
la API de Poloniex . Dos funciones auxiliares que descargan y almacenan en caché los datos JSON pasados a esta API nos ayudarán con esto.
Primero, definimos
get_json_data , que descargará y almacenará en caché los datos JSON en la URL proporcionada.
def get_json_data(json_url, cache_path): '''Download and cache JSON data, return as a dataframe.''' try: f = open(cache_path, 'rb') df = pickle.load(f) print('Loaded {} from cache'.format(json_url)) except (OSError, IOError) as e: print('Downloading {}'.format(json_url)) df = pd.read_json(json_url) df.to_pickle(cache_path) print('Cached {} at {}'.format(json_url, cache_path)) return df
A continuación, definimos una función que genera solicitudes HTTP a la API de Poloniex, y luego llama a
get_json_data , que, a su vez, almacena los datos solicitados.
base_polo_url = 'https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}' start_date = datetime.strptime('2015-01-01', '%Y-%m-%d') # get data from the start of 2015 end_date = datetime.now() # up until today pediod = 86400 # pull daily data (86,400 seconds per day) def get_crypto_data(poloniex_pair): '''Retrieve cryptocurrency data from poloniex''' json_url = base_polo_url.format(poloniex_pair, start_date.timestamp(), end_date.timestamp(), pediod) data_df = get_json_data(json_url, poloniex_pair) data_df = data_df.set_index('date') return data_df
Ella toma una cadena que indica el par de criptomonedas (por ejemplo, BTC_ETH) y devuelve un marco de datos que contiene datos históricos a su tasa de cambio.
3.2 Descargar datos comerciales con Poloniex
La mayoría de las monedas alternativas no se pueden comprar directamente por dólares estadounidenses. Para adquirirlos, las personas a menudo compran bitcoins y los intercambian por altcoins en los intercambios. Por lo tanto, descargamos los tipos de cambio BTC para cada moneda y utilizamos los datos al precio BTC para calcular el costo de las monedas alternativas en USD.
Descargamos datos de existencias de las nueve criptomonedas más populares:
Ethereum ,
Litecoin ,
Ripple ,
Ethereum Classic ,
Stellar ,
Dashcoin ,
Siacoin ,
Monero y
NEM .
altcoins = ['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM'] altcoin_data = {} for altcoin in altcoins: coinpair = 'BTC_{}'.format(altcoin) crypto_price_df = get_crypto_data(coinpair) altcoin_data[altcoin] = crypto_price_df
Ahora tenemos un diccionario de 9 marcos de datos, cada uno de los cuales contiene datos históricos sobre los pares de precios de cambio diarios promedio de altcoins y bitcoin.
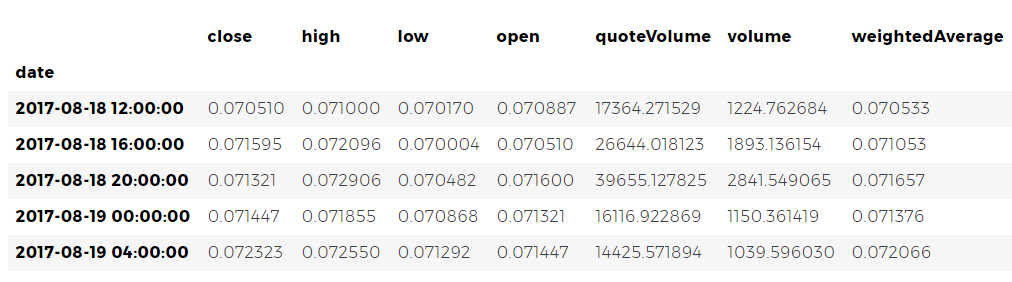
Nuevamente, revisaremos las últimas cinco líneas de la tabla de precios de Ethereum para asegurarnos de que todo esté en orden.
altcoin_data['ETH'].tail()
3.3 conversión de precios a dólares estadounidenses
Ahora podemos comparar los datos sobre pares de precios con nuestro índice de precios de bitcoin para obtener directamente datos históricos sobre el valor de las monedas alternativas en dólares estadounidenses.
# Calculate USD Price as a new column in each altcoin dataframe for altcoin in altcoin_data.keys(): altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']
Usando este código, creamos una nueva columna en el marco de datos de cada moneda alternativa con precios de monedas en dólares.
Además, podemos reutilizar la función previamente definida
merge_dfs_on_column para crear un marco de datos que contenga precios en dólares para cada criptomoneda.
# Merge USD price of each altcoin into single dataframe combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')
Solo asi. Ahora, también agreguemos precios de bitcoin a la última columna del marco de datos combinado.
# Add BTC price to the dataframe combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']
Y ahora tenemos un marco único que contiene los precios diarios en dólares de las diez criptomonedas que estamos estudiando.
df_scatter función
df_scatter establecida
df_scatter para dibujar un gráfico comparativo de los cambios en el precio de la criptomoneda.
# Chart all of the altocoin prices df_scatter(combined_df, 'Cryptocurrency Prices (USD)', seperate_y_axis=False, y_axis_label='Coin Value (USD)', scale='log')

Genial El gráfico le permite evaluar con bastante claridad la dinámica de los tipos de cambio de cada criptomoneda en los últimos años.
Tenga en cuenta que utilizamos la escala de ordenadas logarítmicas, ya que nos permite ajustar todas las monedas en un gráfico. Pero si lo desea, puede probar diferentes valores de parámetros (como scale='linear' ) para ver los datos desde una perspectiva diferente.3.4 Análisis de correlación
Es posible que haya notado que los tipos de cambio de criptomonedas, a pesar de sus valores y volatilidad completamente diferentes, parecen tener cierta correlación entre ellos. Especialmente si observa el intervalo después del aumento de agosto, incluso pequeñas fluctuaciones ocurren con diferentes tokens como si fueran sincrónicamente.
Pero una premonición basada en un parecido externo no es mejor que una simple suposición hasta que podamos respaldarla con datos estadísticos.
Podemos probar nuestra hipótesis de correlación usando el método
corr() de la colección Pandas, usándolo para calcular el coeficiente de correlación de Pearson de todas las columnas del marco entre sí.
Corrección de fecha 22/08/2017 - Esta parte del trabajo ha sido revisada. Ahora, para calcular los coeficientes de correlación, en lugar de los valores de precios absolutos, se utilizan los valores porcentuales de sus cambios diarios.El cálculo de correlaciones directamente entre series de tiempo no estacionarias (como datos de precios brutos) puede conducir a resultados sesgados. Corregiremos este defecto aplicando el método
pct_change() , que convierte el valor de cada celda de trama de un valor absoluto a un porcentaje de su cambio diario.
Para empezar, calculamos la correlación en 2016.
# Calculate the pearson correlation coefficients for cryptocurrencies in 2016 combined_df_2016 = combined_df[combined_df.index.year == 2016] combined_df_2016.pct_change().corr(method='pearson')
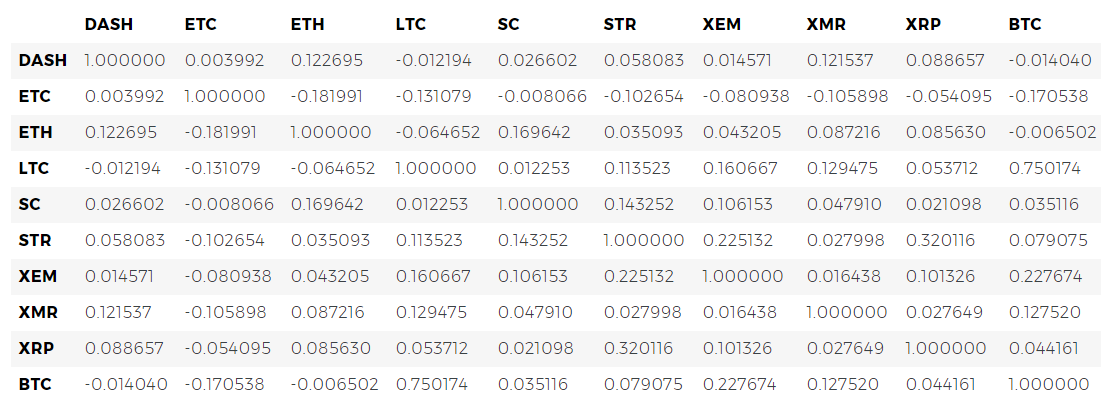
Ahora tenemos probabilidades en todas partes. Los valores cercanos a 1 o -1 indican que entre las series de tiempo existe una fuerte correlación directa o inversa, respectivamente. Los coeficientes cercanos a cero significan que los valores no se correlacionan y varían independientemente uno del otro.
Para visualizar los resultados, necesitamos crear otra función de visualización auxiliar.
def correlation_heatmap(df, title, absolute_bounds=True): '''Plot a correlation heatmap for the entire dataframe''' heatmap = go.Heatmap( z=df.corr(method='pearson').as_matrix(), x=df.columns, y=df.columns, colorbar=dict(title='Pearson Coefficient'), ) layout = go.Layout(title=title) if absolute_bounds: heatmap['zmax'] = 1.0 heatmap['zmin'] = -1.0 fig = go.Figure(data=[heatmap], layout=layout) py.iplot(fig)
correlation_heatmap(combined_df_2016.pct_change(), "Cryptocurrency Correlations in 2016")
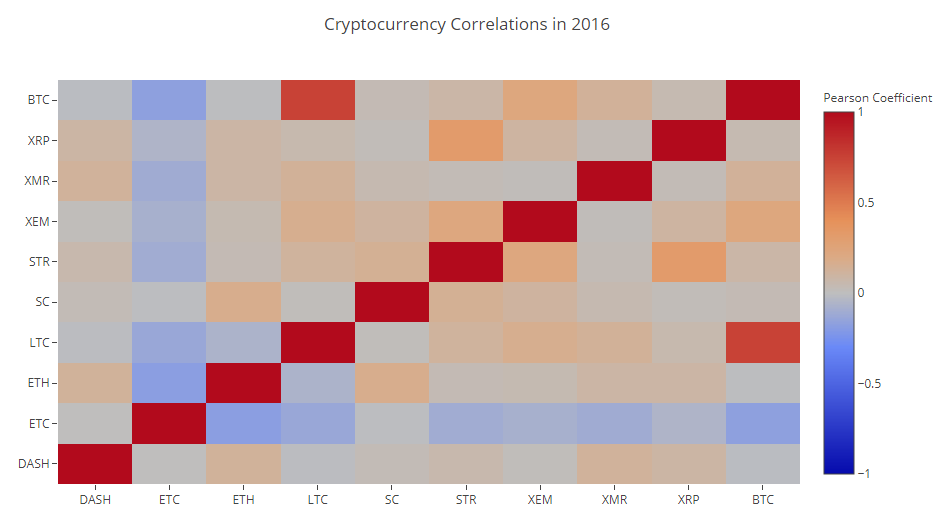
Las celdas de color rojo oscuro en el gráfico indican una fuerte correlación (y cada una de las monedas obviamente se correlacionarán lo más posible), azul oscuro, una fuerte correlación inversa. Todos los colores azul, naranja, gris, arena entre ellos indican diferentes grados de correlación débil o su ausencia.
¿Qué nos dice este cuadro? De hecho, muestra que la relación estadísticamente significativa entre las fluctuaciones de precios de varias criptomonedas en 2016 es pequeña.
Y ahora, para probar nuestra hipótesis de que las criptomonedas se han correlacionado más en los últimos meses, repitamos la misma prueba utilizando datos ya para 2017.
combined_df_2017 = combined_df[combined_df.index.year == 2017] combined_df_2017.pct_change().corr(method='pearson')
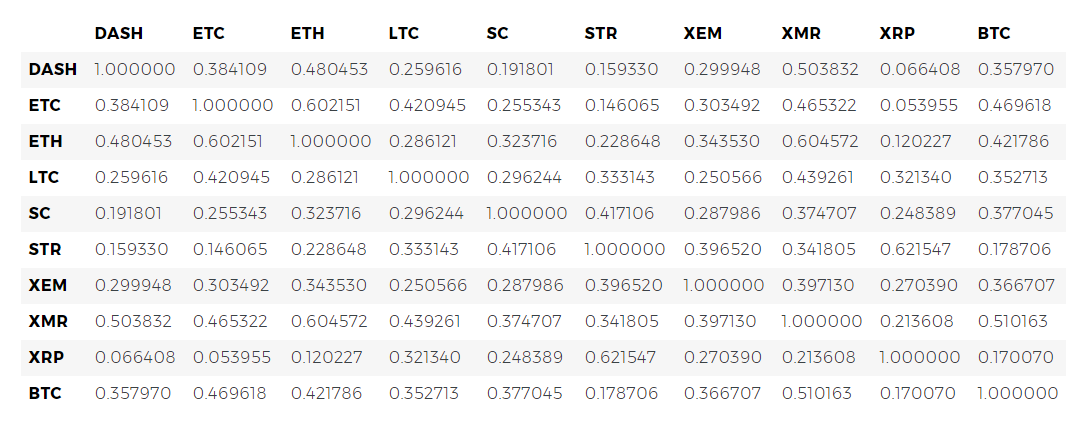
Los coeficientes obtenidos indican la presencia de una correlación más significativa. ¿Es lo suficientemente fuerte como para aprovechar este hecho para la inversión? Definitivamente no.
Sin embargo, debemos prestar atención al hecho de que casi todas las criptomonedas en su conjunto se han correlacionado más entre sí.
correlation_heatmap(combined_df_2017.pct_change(), "Cryptocurrency Correlations in 2017")

Y esta es una observación bastante interesante.
¿Por qué está pasando esto?
Buena pregunta No puedo decir con certeza.
El primer pensamiento que viene a la mente: la razón es que los fondos de cobertura recientemente comenzaron a comerciar abiertamente en los mercados de criptomonedas. [
1 ] [
2 ] Dichos fondos tienen una cantidad de capital mucho mayor que los comerciantes promedio, y si se protegen de los riesgos al rociar sus fondos en una variedad de criptomonedas y utilizan estrategias comerciales similares para cada uno de ellos, basadas en variables independientes (como lo hacen , por ejemplo, en el mercado de valores), entonces una consecuencia lógica de este enfoque puede ser la aparición de una tendencia a aumentar las correlaciones.
Análisis en profundidad: XRP y STR
Por ejemplo, una de las tendencias confirma indirectamente el razonamiento anterior. XRP (token Ripple) está menos correlacionado con otras altcoins. Pero hay una excepción notable: STR (el token Stellar, el oficial se llama "Lumens"), cuyo coeficiente de correlación con XRP es 0.62.
Curiosamente, tanto Stellar como Ripple son plataformas fintech bastante similares cuyas actividades están destinadas a simplificar el proceso de pagos interbancarios internacionales.
Veo una situación muy real en la que algunos jugadores ricos y fondos de cobertura usan estrategias similares para intercambiar fondos invertidos en Stellar y Ripple, ya que ambos servicios detrás de estos tokens son de naturaleza muy similar. Esta suposición puede explicar por qué XRP está mucho más correlacionado con STR que con otras criptomonedas.
Tu turno
Sin embargo, esta explicación es en gran medida una conclusión especulativa. ¿Pero tal vez puedas hacerlo mejor? La base que establecimos en este trabajo nos permite continuar el estudio de datos en una variedad de direcciones.
Aquí hay algunas ideas para verificar:
- Agregue datos para más criptomonedas al análisis.
- Corrija el marco temporal y el grado de detalle del análisis de correlación, considerando las tendencias con más detalle, o viceversa, en términos más generales.
- Busque tendencias en volúmenes de negociación y / o conjuntos de datos para la minería de blockchain. Las relaciones de ventas / compras son más adecuadas para predecir las fluctuaciones de precios que los datos de precios brutos.
- Agregue datos de precios de acciones, productos básicos y materias primas, monedas fiduciarias para averiguar cuál de estos activos se correlaciona con las criptomonedas. (Pero siempre recuerde el viejo dicho, "La correlación aún no implica causalidad").
- Cuantifique la cantidad de publicidad en torno a las criptomonedas individuales utilizando Event Registry , GDELT y Google Trends .
- Utilizando el aprendizaje automático, capacite un programa para analizar datos para predecir tendencias de precios. Si la ambición lo permite, incluso podría intentar hacerlo con una red neuronal recurrente.
- Use su análisis para crear un comercio automatizado de comerciantes de bots en sitios como Poloniex y Coinbase utilizando las API apropiadas. Pero tenga cuidado: un robot comercial mal optimizado puede privarlo rápidamente de todos los fondos disponibles.
- Comparte tus hallazgos! La mejor característica de Bitcoin y otras criptomonedas en general es que su naturaleza descentralizada los hace más libres y democráticos, en comparación con casi cualquier otro activo. , , , -.
HTML- python-
.
, , - , , , .
, , , - , . - ,
Github- .
, , , . , , , .
