Independientemente del fabricante o tipo de RAM, casi toda la memoria de la computadora contiene algún tipo de microdefectos. Un fabricante de memoria puede gastar entre el 10 y el 15% del costo de un DIMM para realizar pruebas exhaustivas de errores, pero la memoria puede ser propensa a fallas y fallas durante la operación del sistema. Una amplia variedad de factores, desde el calentamiento excesivo hasta el "envejecimiento" y la presencia de microdefectos, puede provocar errores de memoria.

De hecho, las tasas de error de memoria dinámica de acceso aleatorio (DRAM) son órdenes de magnitud más altas que los informes informados. En un estudio reciente a gran escala de errores de DRAM de campo basados en datos recopilados durante dos años, aproximadamente un tercio de todas las máquinas y más del 8% de los DIMM registraron al menos un error corregible por año (
errores de DRAM en la naturaleza: un gran estudio de campo a escala ). En algunas plataformas, en casi el 50% de los sistemas, se produjeron errores corregibles (informe IBID), y en promedio solo alrededor del 1.3% de los sistemas estuvieron sujetos a errores irreparables, y para algunas plataformas esta cifra fue del 2-4%.
En las PC de oficina estándar, los errores de memoria rara vez afectan negativamente el rendimiento del software de aplicación estándar. Sin embargo, en sistemas de alta gama con cálculos intensivos en el mundo de las finanzas, la investigación en el campo del petróleo y el gas, en las tareas de imágenes médicas, producción de medios (renderización y edición), etc., la integridad de los datos es un componente esencial de la arquitectura general del sistema. En estos sistemas de alto rendimiento, el reemplazo de memoria es uno de los primeros lugares para reparar debido a componentes defectuosos, y los errores de memoria son uno de los problemas de hardware más comunes que pueden provocar fallas en el sistema (informe IBID).

Por lo tanto, la capacidad de detectar, informar y prevenir errores DIMM en estaciones de trabajo de alto rendimiento se está convirtiendo en una necesidad.
Dada la alta demanda de rendimiento de RAM extremo, Dell ha patentado una tecnología innovadora y exclusiva utilizada en las estaciones de trabajo Dell Precision que ayuda a marcar y retirar la memoria inutilizable. Esta característica exclusiva de Dell ayuda a reducir el tiempo de inactividad del sistema, simplifica el soporte de TI y reduce los costos generales de mantenimiento, aumentando la vida útil de la memoria y aumentando la productividad del usuario.
Veamos los conceptos básicos de Dell Reliable Memory Technology PRO (RMT PRO), algunas de las principales causas de errores de memoria y cómo RMT PRO ayuda a resolver estos errores.
RAM
Junto con los nuevos avances en la tecnología de procesador, el aumento de la velocidad del bus y las mejoras en la arquitectura general, los sistemas informáticos se están volviendo más complejos y la RAM también tiene que mantenerse al día con estos cambios.

Esencialmente (muy simplificado), los chips DRAM son una matriz de elementos con estados de encendido / apagado que retienen este estado (1 o 0) cuando hay energía. Cuando se apaga la alimentación, vuelven al estado cero. Varios chips se ensamblan en un subsistema de memoria y se colocan en una placa de circuito impreso, un DIMM (módulo de memoria dual en línea).
La mayoría de las estaciones de trabajo, como Dell Precision, utilizan el tipo DIMM conocido como DDR4 SDRAM, un dispositivo de almacenamiento dinámico sincrónico de acceso aleatorio. Esencialmente, en comparación con versiones anteriores de tipos de memoria (por ejemplo, DDR3), DDR4 es más rápido, tiene un mayor ancho de banda y una mayor densidad de memoria, y requiere menos fuente de alimentación.
Errores de memoria
Los errores de memoria pueden ser causados por una gran cantidad de factores, como resultado de lo cual un bit DRAM cambia automáticamente al estado opuesto (por ejemplo, de 1 a 0, cuando durante este ciclo la memoria debe permanecer en 1). Los errores pueden verse afectados por factores como el sobrecalentamiento, la antigüedad de la memoria, los defectos, etc. Como los estudios han demostrado, en los primeros 10 meses de funcionamiento del DIMM, el nivel de errores aumenta considerablemente.
Estos tipos de errores se denominan errores recuperables: dañan bits al azar, pero no dejan daños físicos y se pueden solucionar actualizando el estado de la memoria.
Sin embargo, en muchos casos, se producen errores no corregibles. Este es un error de bit repetido debido a un defecto físico u otra anomalía del DIMM, o cuando ocurren dos errores simultáneamente dentro del mismo bloque de memoria. Un error de memoria irrecuperable puede provocar un bloqueo del sistema (se requiere un reinicio) o una aplicación (código de error de detención en el nivel del sistema, volcado del kernel o "pantalla azul de la muerte" - BSoD). Los errores corregibles con frecuencia advierten sobre errores fatales inminentes. En los estudios, alrededor del 65-80% de los errores no corregibles en el mismo mes fueron precedidos por un error corregible.
Manejo de errores
Hoy en día, muchas PC de clase de estación de trabajo incluyen algoritmos de paridad de memoria que, simplemente, garantizan que cada vez que se lee un byte de datos, los datos enviados coinciden con los datos recibidos.

Los sistemas más complejos usan otros métodos de corrección y detección de errores. La opción más común es la memoria del código de corrección de errores (ECC). Se utiliza en servidores y estaciones de trabajo, como las estaciones de trabajo Dell Precision. Esencialmente, la memoria ECC incluye bits adicionales y un controlador de memoria incorporado que verifica la paridad de la memoria, y en caso de un error de un bit, la lógica de la memoria ECC puede corregir el error y generar los datos corregidos para que el sistema continúe funcionando.
ECC hace frente a la corrección de errores de memoria aislados y garantiza un funcionamiento estable del sistema. Sin embargo, la memoria ECC no proporciona una solución para múltiples errores en un solo bloque de memoria. En estos casos, se producirá corrupción de datos. En esta situación, Dell Reliable Memory Technology PRO puede ayudar.
Beneficios de la tecnología RMT PRO
Si la placa del disco duro está físicamente dañada, el sistema de PC marcará el sector defectuoso como inutilizable. Sin embargo, en la mayoría de las computadoras, incluidas las estaciones de trabajo con memoria ECC, un error fatal o varios errores corregibles en el mismo bloque de memoria en el DIMM pueden causar un bloqueo del sistema. El usuario, como regla, se ve obligado a informar dicho error a su servicio de soporte, que, a su vez, debe ejecutar un determinado programa de diagnóstico para detectar el error. A menudo, una sola falla puede requerir el reemplazo de todo el DIMM.
El resultado es un mayor tiempo de inactividad, una menor productividad, pérdida de tiempo del personal de TI, la necesidad de reemplazar los DIMM y posibles daños a los archivos de aplicaciones clave.

Dell Reliable Memory Technology PRO (RMT PRO) viene al rescate.
Similar en concepto a la tecnología de corrección de errores del disco duro, RMT PRO detecta errores fatales y errores corregibles de múltiples bits en el DIMM y soluciona el problema. En lugar de un costoso tiempo de inactividad, ejecutar diagnósticos, abrir el sistema y reemplazar un módulo DIMM fallido con tecnología RMT PRO al reiniciar:
- Marca la parte defectuosa de un solo DIMM.
- Informa el defecto y la ubicación del DIMM fallido en el BIOS.
- Elimina estas celdas defectuosas y una pequeña cantidad de celdas vecinas del grupo de memoria del sistema utilizada.
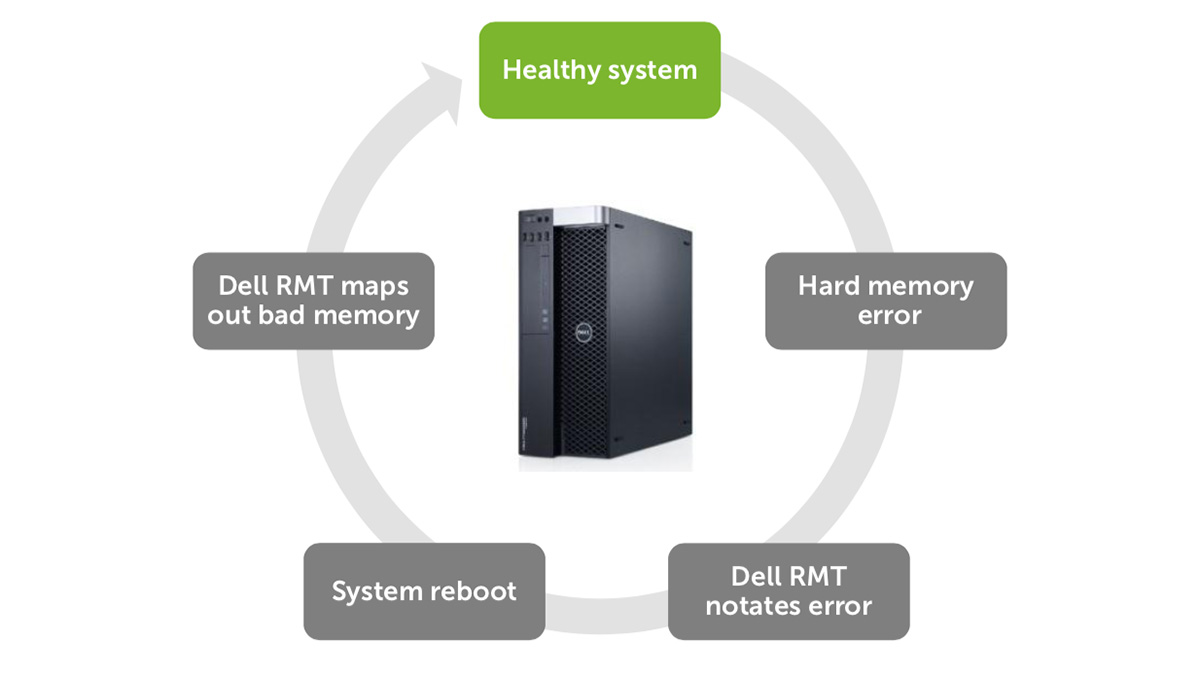
Después de un simple reinicio, el RMT PRO hace que el área defectuosa sea invisible para el sistema operativo. Las aplicaciones y las funciones críticas del sistema "desviarán" el área marcada y continuarán funcionando sin la necesidad de reemplazar el equipo. Todo será como si la mala memoria nunca existiera. Esto garantiza un funcionamiento ininterrumpido, reduce el número de bloqueos del sistema y errores de aplicación.
RMT PRO puede reducir los costos de hardware: módulos de memoria. Dado que la memoria puede deteriorarse con el uso intensivo o el calor excesivo (generalmente debido a una gran carga), la cantidad de errores físicos puede aumentar. A pesar de la "mala memoria", la información permanece en el DIMM. Además, si se requiere el reemplazo de DIMM, RMT PRO mostrará en el BIOS exactamente qué DIMM están causando errores, acelerando la resolución de problemas y el reemplazo de DIMM, lo que ayuda a reducir el tiempo de inactividad y el costo general del servicio. Por lo tanto, la tecnología RMT PRO extiende el ciclo de vida de la memoria y ayuda a ahorrar dinero.

Conclusiones
Aunque algunos esquemas de detección de errores, como la memoria ECC, pueden detectar errores de memoria, muchos de estos algoritmos solo manejan errores corregibles. Cuando se producen defectos físicos o errores fatales en el DIMM, Dell RMT PRO proporciona un nivel adicional de detección y corrección de memoria defectuosa.
Al combinar y eliminar sectores defectuosos, la tecnología RMT PRO hace que las aplicaciones informáticas intensivas accedan solo a la memoria utilizable. Esto puede conducir a ahorros significativos en tiempo y dinero debido a una reducción en el tiempo requerido para reemplazar equipos y módulos DIMM, y para reducir el tiempo de inactividad. Cuando la integridad de los datos es crítica, RMT PRO ofrece el nivel correcto de confianza al proporcionar memoria disponible para maximizar la productividad y confiabilidad de la estación de trabajo.