Empecé a escribir este texto hace mucho tiempo, por lo que no fue planeado como políticamente relevante. Pero resultó que fue en estos días cuando los medios aparecieron una guía de información relacionada con los idiomas pequeños (minoritarios) de Rusia. Es posible que el estudio, sobre el que escribo a continuación, aclare algo a alguien en este sentido.
¿Cuántos idiomas hay en Rusia?
Esto no es tan fácil de realizar, pero en Rusia hablan una cantidad impresionante de idiomas. Además, en Rusia hablan idiomas que no se distribuyen en ningún otro lado. Digamos, millones de ucranianos y uzbekos viven en Rusia, pero al mismo tiempo hay estados soberanos Ucrania y Uzbekistán, donde los idiomas correspondientes son oficiales. Pero en Rusia hablan bashkir, tuvan, udmurt y muchos (de hecho, muchos) otros idiomas que no tienen su estado en ningún otro lugar.
El estado del estado es importante. En la era de la globalización, para sobrevivir, los idiomas necesitan apoyo que afecte positivamente a los medios impresos, los medios, el arte y, en última instancia, el deseo y la capacidad de las personas de hablar su idioma nativo.
¿Y cómo se adaptaron estos idiomas a las nuevas realidades digitales? ¿Es cierto que solo se hablan en pueblos remotos de montaña? ¿O siguen siendo una forma completa de comunicarse en línea? Hace unos años, mis colegas y yo decidimos averiguarlo.
Al principio, este fue un estudio en el marco del ahora desaparecido Centro para el Estudio de Internet y la Sociedad NES (ahora se ha transformado con éxito en el Club de Internet y amantes de la sociedad ), luego organizamos un proyecto de investigación en la escuela de posgrado de la Escuela de Lingüística de la Escuela Superior de Economía y, en general, tuvimos éxito. Todos los resultados se presentan en un sitio web especial, Idiomas de Rusia , pero le contaré lo más interesante, lo que hicimos y cómo (así como lo que sucedió).
En primer lugar, era necesario establecer cuántos idiomas hay en general en Rusia y qué idiomas son. Los lingüistas no tenían una lista generalmente aceptada: no se sabe acerca de algunos idiomas si al menos otro hablante está vivo, no hay acuerdo sobre algunos, ¿es realmente un idioma o es realmente un dialecto de otro idioma? Y no hay criterios claros para distinguir uno del otro. Hay una broma: "el idioma es un dialecto con el ejército y la marina", pero con todo el ingenio de esta declaración de Weinreich, hay suficientes contraejemplos: Brasil tiene un ejército y una marina, pero no tiene su propio idioma (los brasileños usan el portugués, el idioma de su antigua metrópoli), además, Los estadounidenses, dueños del ejército más poderoso del mundo, usan solo un dialecto y no su propio idioma. Islandia no tiene un ejército o una flota (solo barcos de la guardia costera), pero nadie invade la peculiaridad de su idioma (aunque nadie argumenta que es pariente del noruego moderno).
En una palabra, la tarea no fue fácil. De particular dificultad fueron los idiomas de Daguestán. Hay tantos idiomas (¡idiomas reales, no dialectos! Sus operadores no se entienden entre sí) que puede resolverlo solo después de consultar con especialistas.
También decidimos mover los idiomas de título de otros estados fuera de nuestra lista. De hecho, si todo un país fuera de Rusia habla algún idioma, lo más probable es que el recurso estatal también se use para apoyar el idioma. Es posible considerar un idioma como el idioma de Rusia, pero sería incorrecto evaluar su presencia en Internet en comparación con otros idiomas que no son alimentados desde el extranjero: Ingush y el kazajo estarán en categorías de peso completamente diferentes. Entonces, Osetia resultó estar por la borda de nuestro estudio: a pesar de que en Rusia hay toda una región titular donde se habla Osetia, también hay un país separado reconocido por Rusia, Osetia del Sur, para el cual este idioma es oficial. Estrictamente hablando, en Osetia del Sur y del Norte hablan diferentes dialectos, hierro y digor. Pero automáticamente, la computadora, para distinguir entre ellos es muy difícil. Por lo tanto, es mejor considerarlos como un idioma que no pertenece a la clase de idiomas de Rusia.
Otro incidente está relacionado con el yiddish. En Rusia, nominalmente, también hay una región en la que deberían vivir los hablantes de yiddish: la Región Autónoma Judía. Al mismo tiempo, nuestros expertos nos explicaron que casi no había hablantes de yiddish en la EAO, y todos los textos en Internet en este idioma fueron escritos casi exclusivamente en Israel y los Estados Unidos. Por lo tanto, analizar la representación del yiddish en Internet como idioma de Rusia es una estupidez. Esto se suma al hecho de que enfrentaríamos un dolor de cabeza asociado con una variedad de opciones de ortografía. Aquí hay algunos enlaces relevantes sobre esto: [ 1 ], [ 2 ], [ 3 ].
Entonces, decidimos los idiomas. Había 96 de ellos.
Lista completa de idiomas.Abaza
Avar
agul
Adyghe
Aleutiano
alutor
amuzgi-shirinsky
andino
archinsky
ahwahian
Bagvalinsky
Bashkir
bezhtinsky
botlikh
Buriatia
Vepsiano
Verkhneurkunsky
Vodsky
Gapshiminsky
ginuhsky
godoberinsky
montaña mari
Gunzib
Izhora
Ingush
Itelmen
Kabardino-circasiano
Kadar (posiblemente el dialecto de Darginsky)
kaitag
Kalmyk
karatinsky
Karachay-Balkar
Carelio
Ket
Kola Sami
Komi-Zyryansky
Komi-Permyak
Koryak
Kubachi-Ashtinsky
kumyk
laksky
Lezgi
Bosque nenets
prado este mari
Mansi
megeb
moksha-mordoviano
muirinsky
Nanai
Nganasan
negidalsky
nivkhsky
Nogai
Orok
rutulsky
sanji itarin
North Altai
North Yukagir (tundra, vadul)
Severodarginsky (incl. Darginsky literario)
Selkup
Soyot-Tsatansky
Tabasaran
tanty-sirkhinsky (posiblemente el mismo idioma que Verkhneurkunsky)
Tártaro
tat (en peligro de extinción)
tindin
tofalar
tubalar
Tuviniano
tundra nenets
Udine
Udmurt
Udege
Ulchi
usisha-tsudahar
Khakass
Khanty
Khvarshinsky
Tsakhur
cesiano
gitano
chamalinsky
Checheno
chiraghi
Chuvash
Chukchi
Chulymsky
Shor
Evenki
Incluso
enetsky
Erzya Mordovian
esquimal
Altai del sur
Yukagir del Sur (Kolyma, Odul)
Yakut
¿Cómo ahora buscarlos en la web? Puede desinflar todo Internet e intentar encontrar los textos necesarios en la colección resultante ... Pero espere, realmente no puede desinflar todo Internet. Es decir, es posible si usted es una gran empresa de TI con una flota de servidores adecuada y un equipo de desarrollo. Y si tienes un pequeño equipo universitario a tu disposición, entonces no hay nada en qué pensar. Por otro lado, no necesita descargar nada en esta etapa, porque los motores de búsqueda ya han pasado por alto toda la red. Solo es necesario preguntar a los motores de búsqueda las consultas correctas. Es cierto que a los motores de búsqueda no les gustan los resultados automáticos. Pero si realmente pregunta, puede usar, por ejemplo, Yandex.XML, que tiene un límite en la cantidad de solicitudes, pero aún así no es lo mismo que trabajar con resultados de búsqueda con las manos.
Palabras de marcador
Pero que preguntar? Se necesitan palabras, esto está claro. Los índices de búsqueda se forman a partir de palabras, por lo que debe seleccionar palabras para cada idioma que está buscando que se encontrarán en ese idioma en particular y no coincidirán con la composición de las letras con ninguna palabra en ningún otro idioma. En cierto sentido, la búsqueda de idiomas rusos debería ser más simple, porque casi todos los idiomas en nuestra lista tienen scripts cirílicos, y este es un caso relativamente raro para los idiomas del mundo, por lo que la probabilidad de que dos palabras coincidan de diferentes idiomas se reduce drásticamente: será posible confundir solo las palabras de idiomas del espacio postsoviético, y las palabras de algunos idiomas de Oceanía no crearán ruido.
¿Pero de dónde sacar las palabras? Si volvemos a recurrir a los lingüistas, le dirán que hay una publicación antigua y bien merecida: Gilyarevsky R. S., Grivnin V. S. El determinante de los idiomas del mundo por el lenguaje escrito (M., 1961 para la segunda edición). Cada uno de los idiomas descritos (alrededor de 200) tiene una página, donde una plantilla contiene el nombre del idioma, dos textos breves sobre ellos, el alfabeto, sus principales características e información sobre el número de portadores y afiliación genética.
Parece que el libro para nuestros propósitos es completamente inútil, pero en la página 259 hay una sección adicional, "Combinaciones típicas y palabras de servicio de algunos idiomas". Parece que esto es lo que necesita, pero desafortunadamente, las palabras que se citan allí son muy cortas y en la composición de las letras coinciden con las palabras del idioma ruso. Por ejemplo, para Balkar es la palabra "bla", que al buscar producirá una cantidad monstruosa de basura que no se corresponde en absoluto con el idioma Balkar (no solo bla, sino también " vehículo aéreo no tripulado "), y para la montaña Mari - "don" ( la búsqueda será aún peor). Bueno, de todos modos, las palabras en esta sección son bastante raras. Y por combinación de letras en Yandex no mirarás.
Entonces los lingüistas propondrían hacer. Los informáticos tendrían una solución diferente. ¿Por qué no tomar Wikipedia (después de todo, hay Wikipedia en los idiomas de los pueblos de Rusia), hacer un libro de frecuencia con ella, cruzar diccionarios, encontrar tokens únicos de esta manera y usarlos para consultas de búsqueda? Lamentablemente, esto tampoco funcionará. En primer lugar, Wikipedia no es para todos los idiomas de Rusia. Solo hay 22 secciones de Wikipedia "reales", no de una incubadora. La incubadora agrega 41 más. Pero generalmente es un máximo de varias docenas de textos muy cortos, es decir, no producirán resultados estadísticamente significativos. Aquí hay una incubadora con Tabasaran Wikipedia (5 artículos). Aquí hay una incubadora Nogai (23 artículos). Además, en algunos no hay ningún texto, sino el artículo sobre los Bashkirs . Y así sucesivamente.
Pero la Wikipedia real (sin incubación) no puede servir como una buena fuente. Porque ellos ... ¡no están escritos por personas! La Wikipedia más grande en los idiomas de los pueblos de Rusia sufre de lo que los Wikipedia llaman " aracnofilia ". es decir, el llenado automático de la sección con artículos generados por la plantilla en la que se insertan algunos datos numéricos de una base de datos o registro abierto. Digamos, la Wikipedia Bashkir y Tártaro para un porcentaje muy pequeño de "humano", hay decenas de miles de artículos automáticos sobre ríos y lagos. Intente hacer clic en el enlace " artículo aleatorio " en la Wikipedia bashkir, ¿cuántas veces de cada 10 obtiene un "artículo no relacionado con el agua" (puede buscar "río" con la palabra clave "yylkha")? Ahora la situación ha mejorado un poco, todavía hay artículos sobre países y asentamientos, pero hace cinco años hubo temas de "agua" en 8 de cada 10. Hice clic ahora, resultó 7: 3 a favor de los ríos. Que hay de ti
Todo estaría bien, pero las palabras de frecuencia en dichos textos no son palabras de frecuencia en el idioma. ¿Cómo se ve un diccionario de frecuencia "normal" basado en textos de origen natural? Las primeras dos docenas de posiciones están ocupadas por diferentes palabras oficiales, que son muchas veces más comunes en el habla que las significativas. Aquí hay un diccionario de frecuencias para el idioma ruso . El primer sustantivo (año) aparece allí al final de los terceros diez. Y antes de eso, todo es completamente: conjunciones, preposiciones, pronombres y partículas. Y aquí está el diccionario de frecuencia de la Wikipedia tártara para 2013:
| No | Forma de la palabra | Traducción / Significado | Ocurrencia |
|---|
| 1 | elga | el rio | 132567 |
| 2 | piscinas | la piscina | 75706 |
| 3 | sous | agua | 54689 |
| 4 4 | buencha | por | 48838 |
| 5 5 | Rusia | Rusia | 48722 |
| 6 6 | urnashkan | localizado | 38043 |
| 7 7 | Km | kilómetro | 36962 |
| 8 | Һәm | y | 27231 |
| 9 9 | keche | pequeño | 27203 |
| 10 | dәүlәt | el estado | 26888 |
Solo hay dos palabras oficiales, de las cuales solo una, Һәm “y”, se encuentra especialmente en textos reales. El resto, por supuesto, se incluyeron en la lista solo debido a los detalles de la muestra original.
Solo había una salida para nosotros: recopilar palabras para definir consultas de búsqueda manualmente para cada idioma. Este es un trabajo experto, debe buscar en diccionarios y gramáticas, luego conducir las palabras candidatas a la búsqueda y mirar el resultado y evaluar la cantidad de basura que sale. Además, cada palabra debe cumplir dos criterios obligatorios. En primer lugar, debe ser la frecuencia de tu idioma. Por lo tanto, el tártaro Һәm "y" encajaría. De hecho, esta palabra se encuentra en la mayoría de los textos en idioma tártaro, y una solicitud que contenga esta palabra nos permitirá recibir y, por lo tanto, capturar la mayoría de los sitios que tienen textos en idioma tártaro. En segundo lugar, dicha palabra debe ser única, es decir, debe usarse solo en este idioma, pero no en ningún otro. Desde este punto de vista, Um , por desgracia, "vuela", porque exactamente la misma palabra está en bashkir.
Hay un matiz más. En los alfabetos de los idiomas nacionales hay muchos caracteres "especiales", es decir, letras que no están en el alfabeto del idioma ruso, utilizando estos caracteres (como dicen los lingüistas, "grafema"), se graban sonidos especiales (como dicen los lingüistas, "fonemas") de estos idiomas. Por ejemplo, la palabra Komi-Zyryan tashtöm contiene dicho símbolo, lejos de ser el más exótico de los que pueden ser (se pueden ver otros ejemplos en la lista tártara de palabras "agua" más arriba).
El hecho es que dado que todo este lujo gráfico no está en el teclado ruso estándar, en el que todos escriben básicamente, los usuarios reales no ingresan estas letras, reemplazándolas por otras que son similares en ortografía o sonido. La palabra tashtöm se traduce como tashtem o tashtom. En bashkir, la letra "ә" se transmite como "e" o "a", y la letra "ҙ" como "z". Aquí en KDPV solo la palabra "menan" en realidad debería escribirse "menen". Siguiendo al lingüista A. A. Zaliznyak, llamamos a ese régimen de ortografía "sistema de escritura cotidiana". Sobre los mismos procesos (solo sin teclados y otro software) que Zaliznyak describió para el dialecto del Antiguo Novgorod grabado en letras de corteza de abedul.
¿Qué significa esto en la práctica? Que, idealmente, no solo se necesitan palabras marcadoras que sean exclusivas de este idioma y la frecuencia en este idioma. Estas palabras también son necesarias para que no contengan estos "caracteres especiales". Debido a que en realidad tales caracteres no están escritos por todos, y si envía una solicitud al motor de búsqueda con la palabra en el calendario "correcto", entonces la integridad de la respuesta será así: no encontraremos una gran cantidad de textos escritos en el sistema doméstico.
Además, hay más símbolos astutos, por ejemplo, "I": "Varita de Yakovlev" (en diferentes idiomas del Cáucaso significa un arco laríngeo o el llamado sonido "abusivo"). A menudo, en un sistema doméstico se reemplaza con una unidad, pero sucede que también escriben el símbolo "|", una barra vertical, que se usa como operador de búsqueda "o" (busca páginas que contengan cualquiera de las palabras asociadas con este operador).
En resumen, no es fácil. Pero hicimos tales listas de palabras marcadoras para la mayoría de los idiomas que nos interesaban. Y esto es lo único que no publicamos públicamente, porque esas palabras aún pueden ser útiles para buscar textos, y esta lista es muy fácil de destrozar, por ejemplo, si alguien quiere usarlas para generar spam de búsqueda.
Buscar
Entonces, tenemos términos de búsqueda, los enviamos a Yandex.XML y obtenemos los resultados. Aquí tampoco es tan simple. En primer lugar, Yandex.XML limita nuestros apetitos a 10,000 solicitudes por día. ¿No tan poco? Sí, pero entrega enlaces página por página (10 por página) y la transición a la página siguiente se considera una solicitud por separado ...
Además, todavía recibimos basura en la salida. Incluso para "buenos" marcadores. Que tenemos Espejos y dobles. Especialmente muchas tomas de Wikipedia. ¿Y por qué deberíamos considerar Wikipedia si nuestro objetivo es recopilar todos los textos en un idioma determinado? ¡Después de todo, Wikipedia se puede descargar con un solo clic! Que mas Artículos científicos lingüísticos. Algunos lingüistas escriben un artículo en ruso y dan un ejemplo de una oración en alguna rutina, y esta oración contiene nuestra palabra marcadora. Esto tampoco es bueno, porque ante nosotros hay un texto en ruso. O de lo contrario podría ser un diccionario. También habrá la palabra que estábamos buscando, pero no habrá texto. Una sorpresa para nosotros fueron los sitios de música. Contienen mp3 de numerosas canciones populares o de derechos de autor en un idioma pequeño. Tampoco hay textos allí, pero hay frases cortas adecuadas para la solicitud: los nombres de las obras musicales. Para algunos idiomas, estos sitios son tan numerosos que obstruyen todo el resultado. Decidimos que dado que estamos buscando textos, estos tampoco son nuestros clientes.
Algo debe ser cortado. El primer filtro se puede ingresar en la etapa de contacto con el motor de búsqueda. Si tenemos varios marcadores para el idioma, luego de haber capturado algún dominio en la parte inferior, podemos preguntarle al motor de búsqueda si hay otras palabras de nuestra lista en el mismo sitio. Si es así, es probable que hayamos llegado al sitio que necesitamos. Si hay un marcador, pero el resto no está representado, es muy probable que tengamos un muñeco en nuestras manos. Existe, por ejemplo, la maravillosa palabra Khakass "seno" ("otra vez"). Cumple con todos los criterios para una palabra de marcador enumerada anteriormente. Pero aquí está la cosa. Cuando escriben en ruso, a veces cometen errores y escriben "seno" en lugar de "senos" (nariz). Nuestro filtro ayudará a comprender si un error tipográfico está en el texto ruso o, de hecho, en el texto Khakass. La cuestión es que se trata de solicitudes adicionales, de las cuales hay muy pocas.
No todo es inequívoco con la lista de sitios en los que se encontraron los textos que necesitamos. Si planeamos no solo encontrar estos sitios, sino también bombearlos para formar el corpus, entonces necesitamos saber a qué profundidad se debe realizar el bombeo. Dividimos todos los dominios encontrados en tres categorías (todo esto también se puede encontrar haciendo las consultas correctas de Yandex).
, ( — ) .
, ( ) .
, . Youtube ( - «» ) stihi.ru ( , , ).
, , VK.com. , , , , ( ), , , -, . , , . .
VK.com . : - , - , vk.com. 2016 , .
. . , . Scrapy , . VK API .
. , . , , . , , , , - . ( — , ngram) . - , , , . , . .
, - . , , , . — ( , ), — . . . - «» . , , , . , , .
, , , .
Resultados
, . . ?
, . , , , . «» . .
- . ? , , - ?
, ( ) .
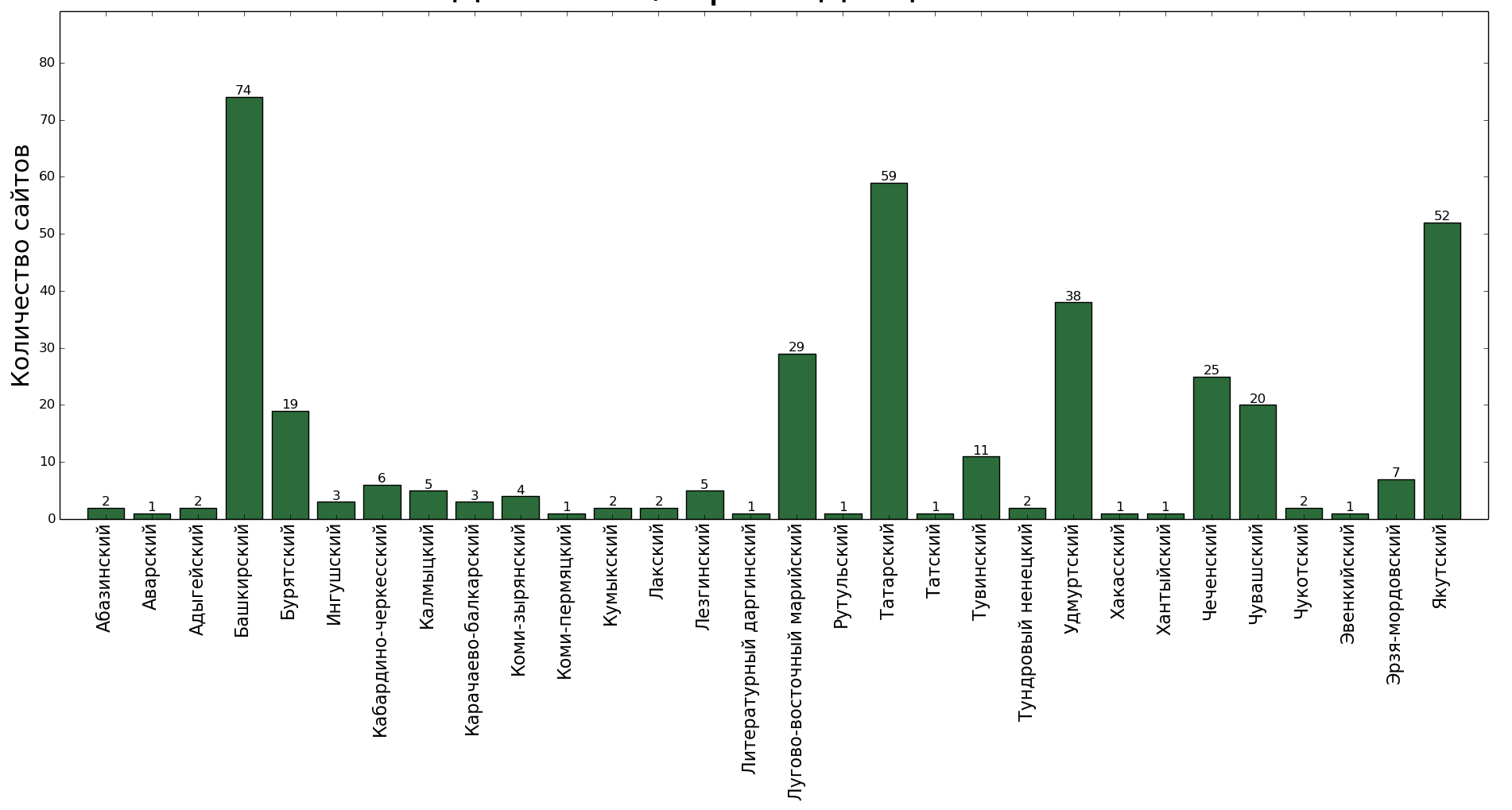
? — ?
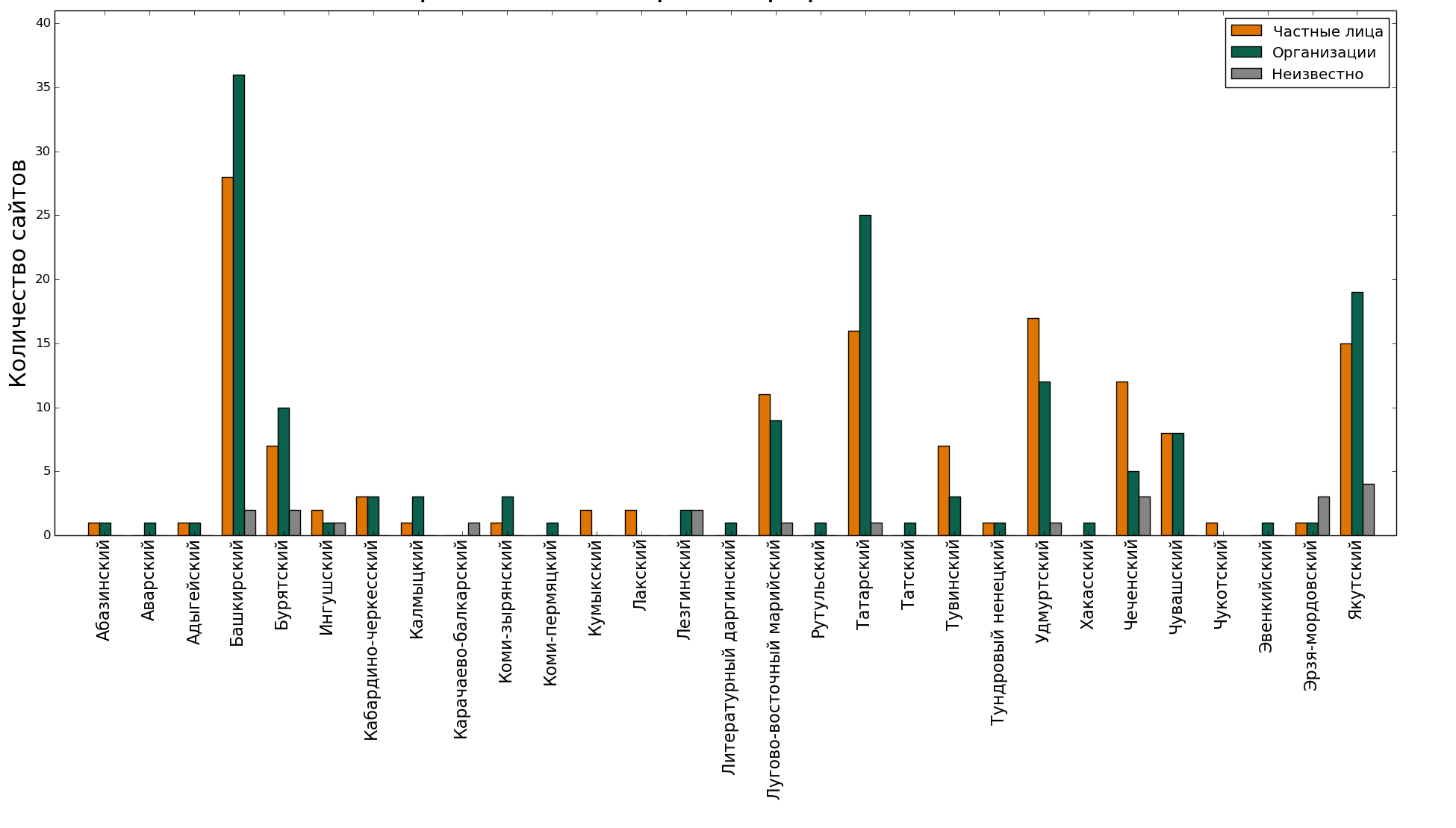
, - , .
?
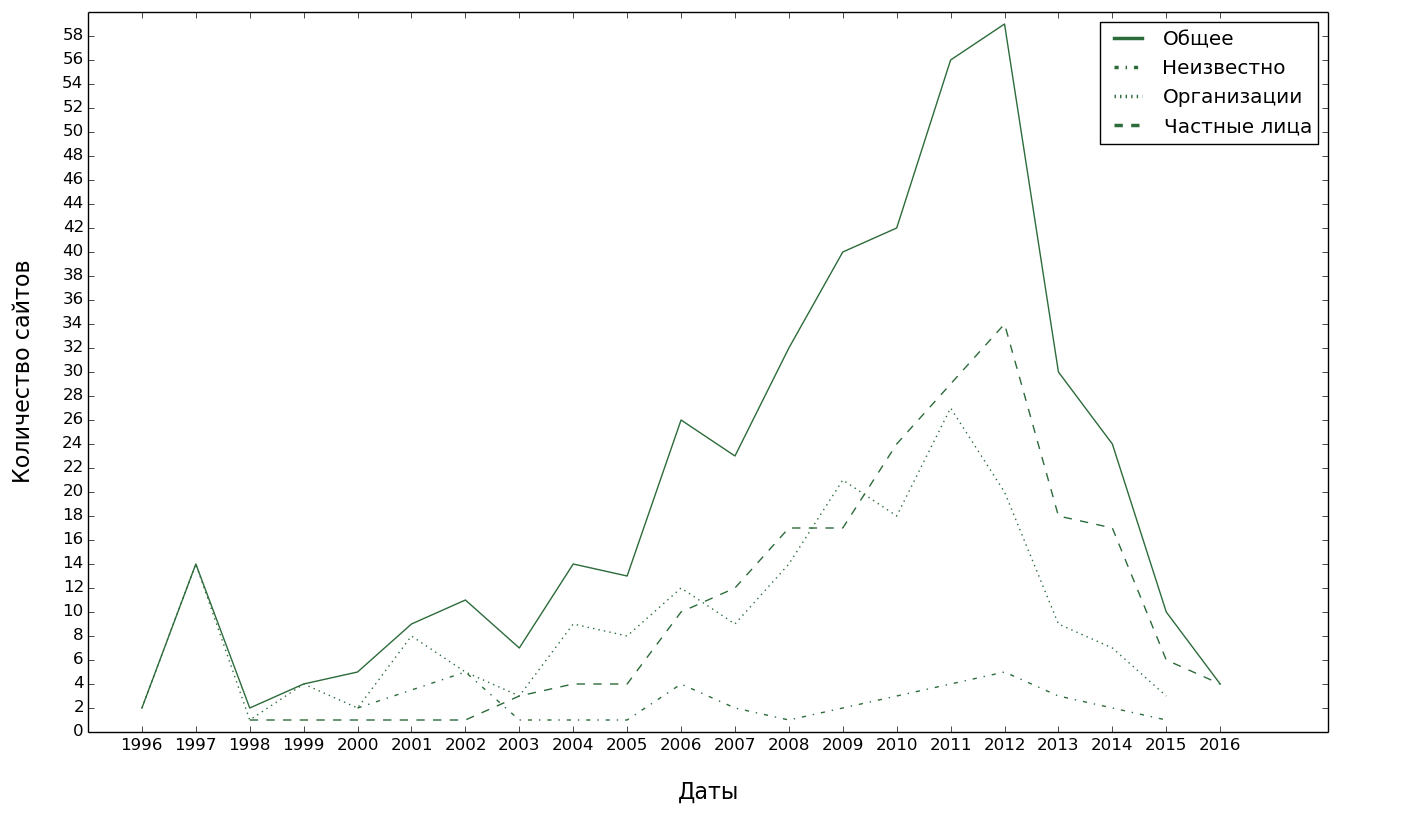
, , 2012 . Por qué , . , vk.com.
. : , ( , ). ( , , , - , ). ? ?
, - ( 0.7), - . , , , . , , , . , , . , , .
, . ? , , , , .
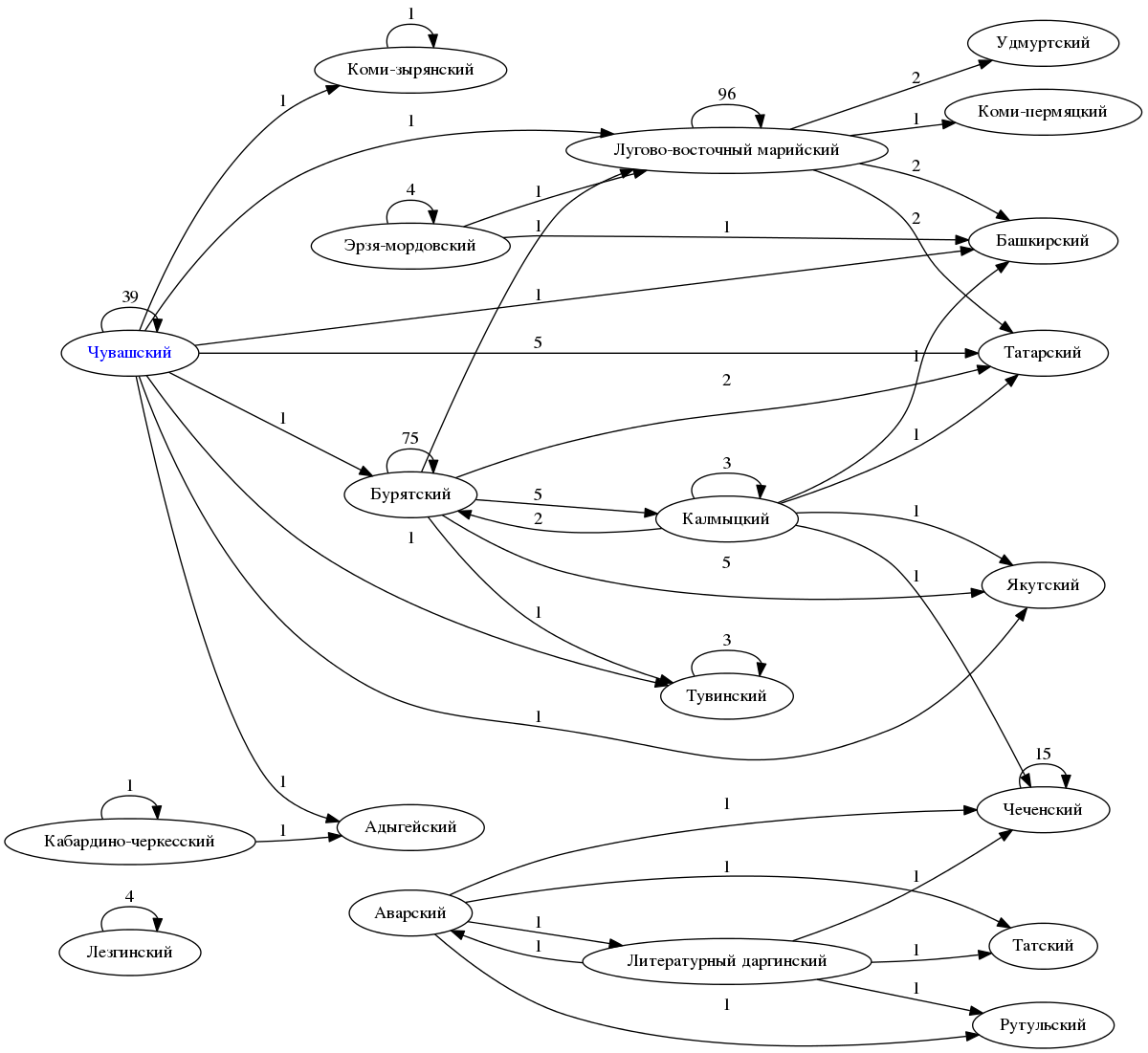
- "", , , . , : , , , . , , , .
, . , , , , , .
, -, ?
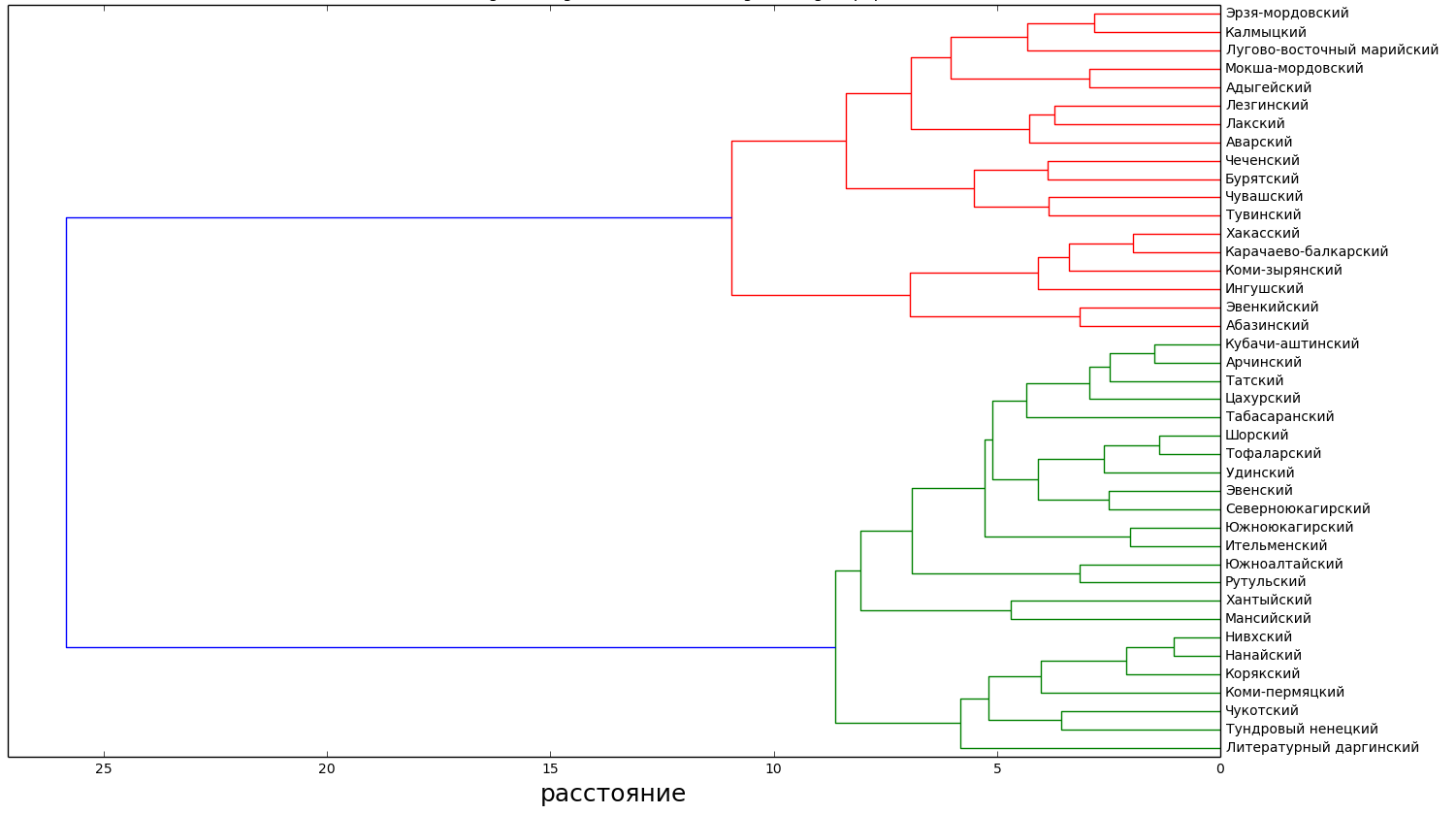
, , : - , , - , , .
Redes sociales
, vk.com. - , - , : , . . .
:
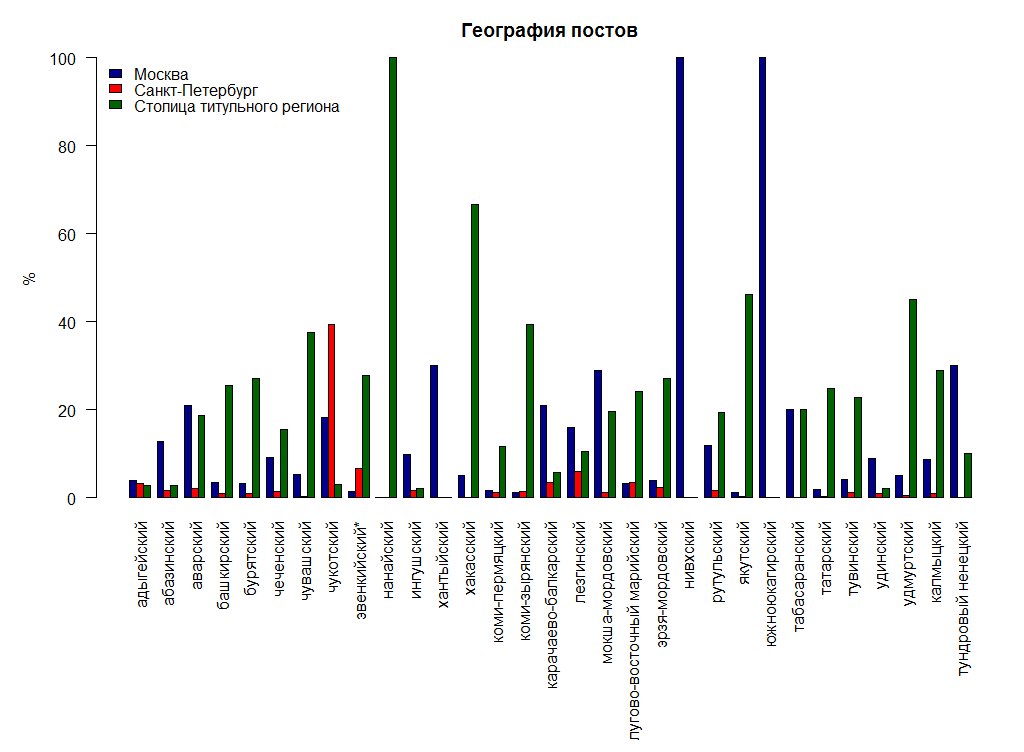
, , , , — . , — . , , . . , .
- ?
, «» :
?
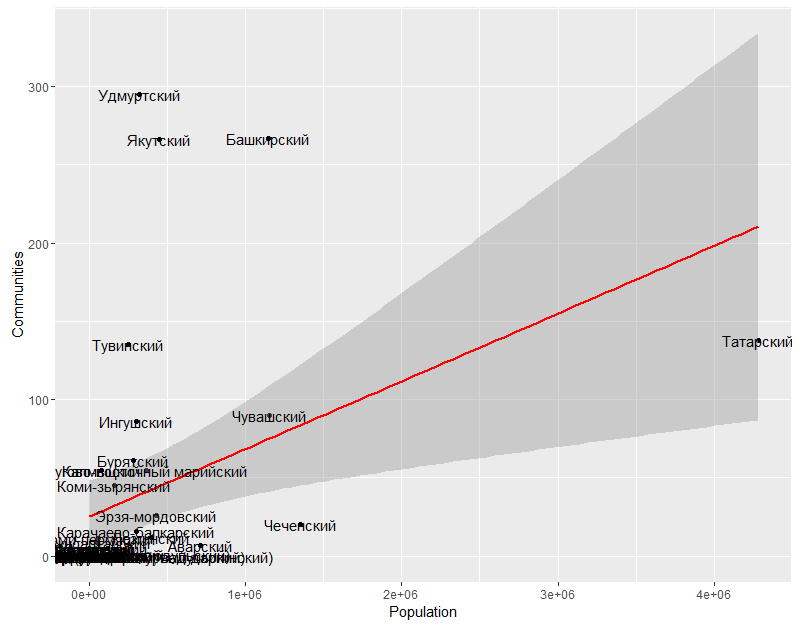
- . , , . , , . , 90- 2000-.
Entonces, aprendimos que hay pequeños idiomas de Rusia en Internet. Viven en sitios y redes sociales, y desde 2012, principalmente en redes sociales. Tanto allí como allí se ven obligados a resistir una feroz competencia con el "prestigioso" idioma ruso. La vitalidad de un idioma en Internet no depende mucho de cuánto habla ese idioma "en la vida". Lo más importante es si se ha desarrollado una comunidad de red activa en torno a este idioma, que opera en sitios de Internet de prestigio (Wikipedia, Vkontakte). Si sucedió, sucedió "en el terreno" en la región donde viven hablantes nativos de este idioma.
Pero si los idiomas pequeños sobreviven en una situación de globalización, todavía tenemos que aprender durante nuestras vidas.
Todo el código del proyecto está en el repositorio . Todas las colecciones de texto y listas de dominios y comunidades están disponibles para descargar .
Y no puedo dejar de recomendar la comunidad en vk.com con lindos memes en pequeños idiomas con gatos .