La traducción automática con la ayuda de redes neuronales ha
recorrido un largo camino desde el momento de la primera investigación científica sobre este tema hasta el momento en que Google anunció la
transferencia completa del servicio Google Translate al aprendizaje profundo .
Como saben, la base del traductor neuronal es el mecanismo de Redes Neuronales Recurrentes Bidireccionales, construido sobre cálculos matriciales, que le permite construir modelos probabilísticos significativamente más complejos que los traductores automáticos estadísticos. Sin embargo, siempre se creyó que la traducción neural, como la traducción estadística, requiere textos bilingües paralelos para el entrenamiento. Se está formando una red neuronal en estos edificios, tomando como referencia una traducción humana.
Al final resultó que ahora, las redes neuronales son capaces de dominar un nuevo idioma para la traducción, incluso sin corpus de textos paralelos!
Se publicaron
dos trabajos sobre este tema en el sitio de preimpresión arXiv.org.
“Imagine que le está dando a una persona muchos libros chinos y muchos libros árabes, no hay libros idénticos entre ellos, y esta persona está aprendiendo a traducir del chino al árabe. Parece imposible, ¿verdad? Pero demostramos que una computadora es capaz de esto ”,
dice Mikel Artetxe, un informático de la Universidad del País Vasco en San Sebastián (España).
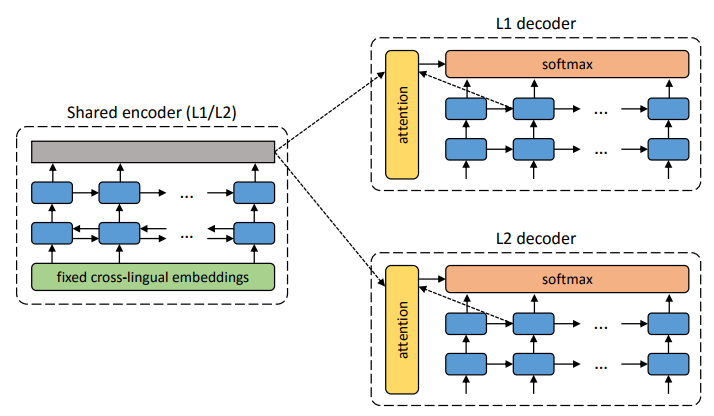
La mayoría de las redes neuronales de traducción automática se enseñan "con un maestro", cuyo papel es precisamente el corpus paralelo de textos traducidos por el hombre. En el proceso de aprendizaje, en términos generales, la red neuronal asume, comprueba el estándar y realiza las configuraciones necesarias en sus sistemas, luego aprende más. El problema es que para algunos idiomas en el mundo no hay una gran cantidad de textos paralelos, por lo tanto, no están disponibles para las redes neuronales tradicionales de traducción automática.
Dos nuevos modelos ofrecen un nuevo enfoque: enseñar una red neuronal de traducción automática
sin un maestro . El sistema en sí está tratando de formar una especie de corpus de textos paralelos, agrupando palabras entre sí. El hecho es que en la mayoría de los idiomas del mundo existen los mismos significados, que simplemente corresponden a diferentes palabras. Por lo tanto, todos estos significados se agrupan en grupos idénticos, es decir, los mismos significados de palabras se agrupan alrededor de los mismos significados de palabras, casi independientemente del idioma (consulte el artículo "
Google Neural Network compiló una base unificada de los significados de las palabras humanas ") .
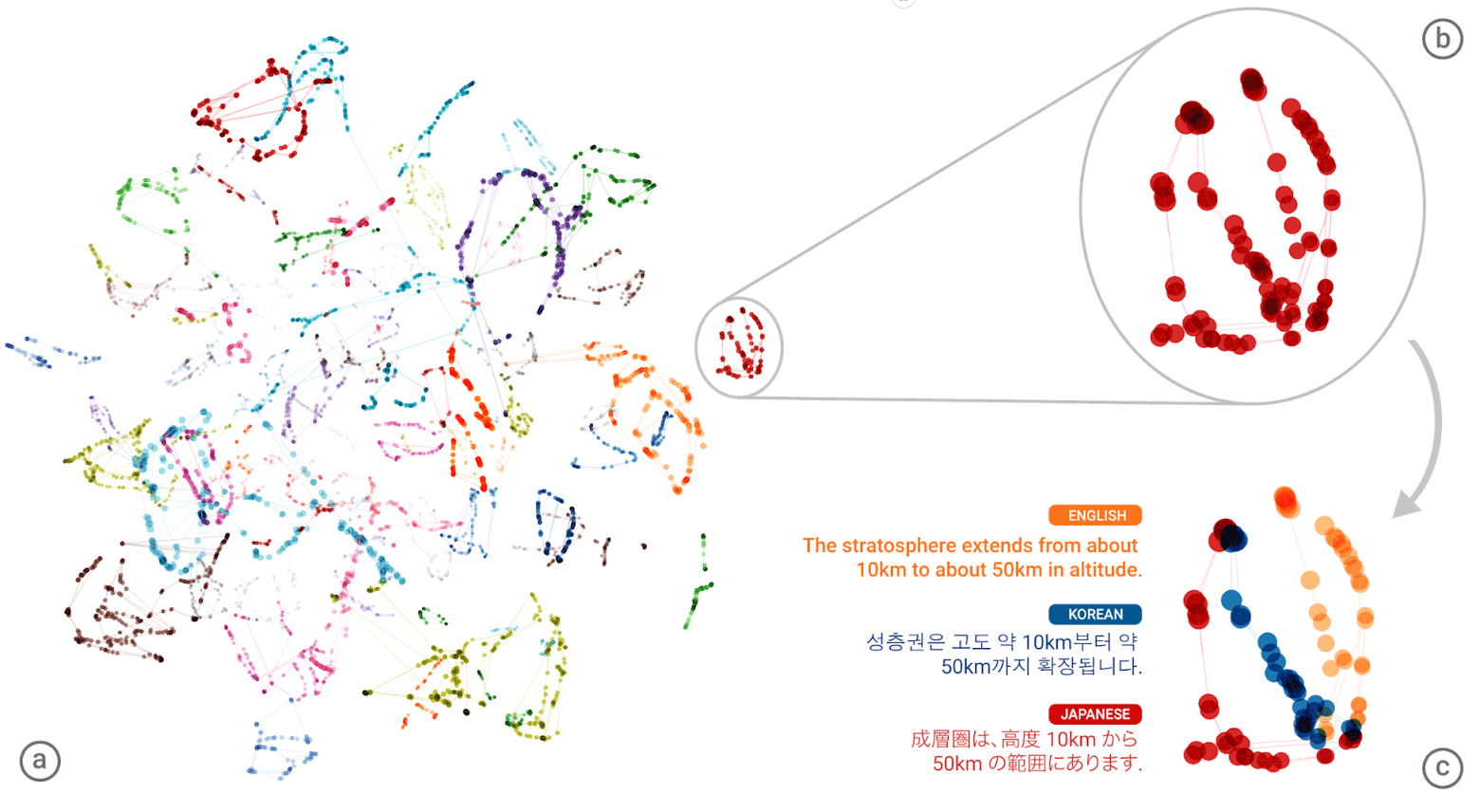 El "lenguaje universal" de la red neuronal de Google Neural Machine Translation (GNMT). Los grupos de significados de cada palabra se muestran en diferentes colores en la ilustración de la izquierda, los significados más bajos son los significados de las palabras obtenidas de diferentes idiomas humanos: inglés, coreano y japonés
El "lenguaje universal" de la red neuronal de Google Neural Machine Translation (GNMT). Los grupos de significados de cada palabra se muestran en diferentes colores en la ilustración de la izquierda, los significados más bajos son los significados de las palabras obtenidas de diferentes idiomas humanos: inglés, coreano y japonésDespués de haber compilado un gigantesco "atlas" para cada idioma, el sistema intenta superponer uno de esos atlas en otro, y aquí está, ¡está listo para tener algún tipo de corpus de texto paralelo!
Puede comparar los patrones de las dos arquitecturas de aprendizaje sin maestros propuestas.
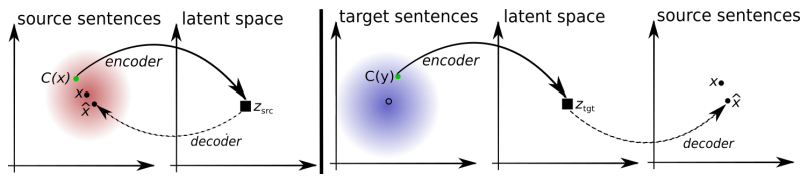
 La arquitectura del sistema propuesto. Para cada oración en el lenguaje L1, el sistema aprende la alternancia de dos pasos: 1) eliminación de ruido , que optimiza la probabilidad de codificar una versión ruidosa de la oración con un codificador común y su reconstrucción por el decodificador L1; 2) traducción inversa, cuando una oración se traduce en modo de salida (es decir, codificada por un codificador común y decodificada por el decodificador L2), y luego se optimiza la probabilidad de codificar esta oración traducida con un codificador común y la restauración de la oración original por el decodificador L1. Ilustración: artículo científico de Mikel Artetks et al.
La arquitectura del sistema propuesto. Para cada oración en el lenguaje L1, el sistema aprende la alternancia de dos pasos: 1) eliminación de ruido , que optimiza la probabilidad de codificar una versión ruidosa de la oración con un codificador común y su reconstrucción por el decodificador L1; 2) traducción inversa, cuando una oración se traduce en modo de salida (es decir, codificada por un codificador común y decodificada por el decodificador L2), y luego se optimiza la probabilidad de codificar esta oración traducida con un codificador común y la restauración de la oración original por el decodificador L1. Ilustración: artículo científico de Mikel Artetks et al.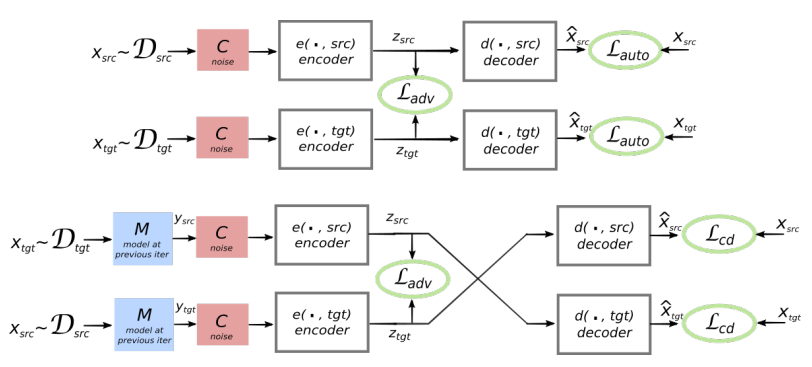 La arquitectura propuesta y los objetivos de aprendizaje del sistema (del segundo trabajo científico). La arquitectura es un modelo de traducción de oraciones, donde el codificador y el decodificador funcionan en dos idiomas, dependiendo del identificador del idioma de entrada, que intercambia las tablas de búsqueda. Arriba (codificación automática): el modelo está aprendiendo cómo realizar la reducción de ruido en cada dominio. A continuación (traducción): como antes, además de codificar desde otro idioma, utilizando como entrada la traducción producida por el modelo en la iteración anterior (rectángulo azul). Las elipses verdes indican términos en la función de pérdida. Ilustración: artículo científico de Guillaume Lampl et al.
La arquitectura propuesta y los objetivos de aprendizaje del sistema (del segundo trabajo científico). La arquitectura es un modelo de traducción de oraciones, donde el codificador y el decodificador funcionan en dos idiomas, dependiendo del identificador del idioma de entrada, que intercambia las tablas de búsqueda. Arriba (codificación automática): el modelo está aprendiendo cómo realizar la reducción de ruido en cada dominio. A continuación (traducción): como antes, además de codificar desde otro idioma, utilizando como entrada la traducción producida por el modelo en la iteración anterior (rectángulo azul). Las elipses verdes indican términos en la función de pérdida. Ilustración: artículo científico de Guillaume Lampl et al.Ambos artículos científicos utilizan una técnica notablemente similar con ligeras diferencias. Pero en ambos casos, la traducción se lleva a cabo a través de un "lenguaje" intermedio o, mejor, una dimensión o espacio intermedio. Hasta ahora, las redes neuronales sin un maestro muestran una calidad de traducción no muy alta, pero los autores dicen que es fácil mejorar si se usa un poco de ayuda de un maestro, solo por el bien de la pureza del experimento que no hicieron.
Tenga en cuenta que el segundo trabajo científico fue publicado por investigadores de la división de inteligencia artificial de Facebook.
Los trabajos se presentan para la Conferencia Internacional sobre Representaciones de Aprendizaje 2018. Ninguno de los artículos ha sido publicado aún en la prensa científica.