A principios de noviembre de 2017, Qualcomm Datacenter Technologies (QDT) completó el trabajo en su nueva creación, un procesador basado en tecnología de 10 nm, Centriq 2400. ¿Qué futuro le espera a la industria según los creadores de esta innovación? ¿Cuáles son los beneficios de obtener servidores y por qué el Centriq 2400 es tan único? Lea más sobre esto y más.
El 8 de noviembre, se celebró una conferencia de prensa de QDT en San José (California), en la que se anunció oficialmente el inicio de las entregas del nuevo procesador. Anand Chandrasekher, Vicepresidente Senior y Director Ejecutivo, dijo:
La presentación de hoy es un logro importante y la culminación de más de 4 años de diligente diseño, desarrollo y soporte del sistema ... Hemos creado el procesador de servidor más avanzado del mundo, que proporciona un alto rendimiento combinado con un alto nivel de eficiencia energética, lo que permite a nuestros clientes reducir significativamente sus costos.
Además del orgullo no disfrazado de su producto, los representantes de la compañía no tienen reparos en declarar que su procesador Centriq 2400 es significativamente superior a los productos de la competencia, por ejemplo, Intel Xeon Platinum 8180. Según sus cálculos, por cada dólar gastado (y el costo del procesador es de $ 1995), el usuario obtendrá rendimiento en 4 veces Y cuando se recalcula en rendimiento en 1 vatio, en un 45% más. Sin embargo, en negrita, muchos de los representantes de varias compañías interesadas en el nuevo producto están más que felices de escucharlos.
Especificaciones técnicas de Qualcomm Centriq 2400
Arquitectura de CPU:- hasta 48 núcleos de 64 bits con una frecuencia pico de 2.6 GHz;
- Compatibilidad Armv8
- AArch64 solamente;
- Armv8 FP / SIMD;
- Extensión de CRC y Armv8 Crypto;
Caché de la CPU:- Caché de 64 Kb de instrucciones (instrucciones) L1 y 24 Kb de caché de ciclo único L0;
- Caché de datos de 32 Kb L1;
- 512 KB de caché L2 total por cada 2 núcleos;
- 60 MB de caché L3 compartida;
- filtrado de solicitudes de interprocesador L2;
- QoS;
donde, L (L1, L2, L3, L0) es el nivel, es decir L0 es el nivel cero.Tecnología:- La tecnología FinFET de 10 nm de Samsung;
Ancho de banda de memoria:- 6 canales para conectar módulos de memoria DDR4;
- hasta 2667 MT / s por conexión;
- 128 GB / s: ancho de banda total máximo;
- Compresión de ancho de banda incorporada
Capacidad de memoria:- 768 GB = 128 GB x 6 conexiones;
Tipo de memoria:- Conexiones DDR4 de 64 bits con ECC de 8 bits;
- RDIMM y LRDIMM;
Interfaz compatible- GPIO
- I²C;
- SPI
- 8 bandas SATA Gen 3;
- 32 PCIe Gen3 con la capacidad de conectar hasta 6 controladores PCIe;
Además de las características anteriores, vale la pena señalar que este procesador tiene 18 mil millones de transistores en cada chip. Y todos sus núcleos están conectados por un bus de anillo bidireccional. Con la carga máxima, el Centriq 2400 consume solo 120 vatios.
El enfoque principal del nuevo procesador sigue siendo soluciones en la nube. Según los representantes de la compañía, Centriq 2400 le permitirá crear sistemas de servidor que se caracterizarán por su alto rendimiento, eficiencia y escalabilidad.
Esto no podía dejar de atraer a muchas empresas, tecnologías en la nube para las cuales son casi la base de sus actividades. A la presentación asistieron: Alibaba, LinkedIn, Cloudflare, American Megatrends Inc., Arm, Cadence Design Systems, Canonical, Chelsio Communications, Excelero, Hewlett Packard Enterprise, Illumina, MariaDB, Mellanox, Microsoft Azure, MongoDB, Netronome, Packet, Red Hat, ScyllaDB, 6WIND, Samsung, Solarflare, Smartcore, SUSE, Synopsys, Uber, Xilinx. La lista es bastante impresionante, lo que indica una mayor atención a este producto.
Por el momento, el procesador Qualcomm Centriq 2400 solo está ganando impulso, tanto en prevalencia como en popularidad. Lo que, naturalmente, conducirá a la aparición de algo nuevo, similar o incluso más productivo, de los competidores de QDT.
Pero no todos creen ciegamente en la frescura de los nuevos artículos. Si aquellos que creen que realizar pruebas y análisis comparativos de varios procesadores les permitirán ver resultados mucho más indicativos que las palabras de los promotores Centriq 2400.
Cloudflare realizó un análisis comparativo de tres plataformas: Grantley (Intel), Purley (Intel) y Centriq (Qualcomm).
A continuación se presentarán gráficos de este análisis y las conclusiones de su autor,
Vlad Krasnov . (
Original de este análisis en el blog de Cloudflare )
Criptografía de clave pública
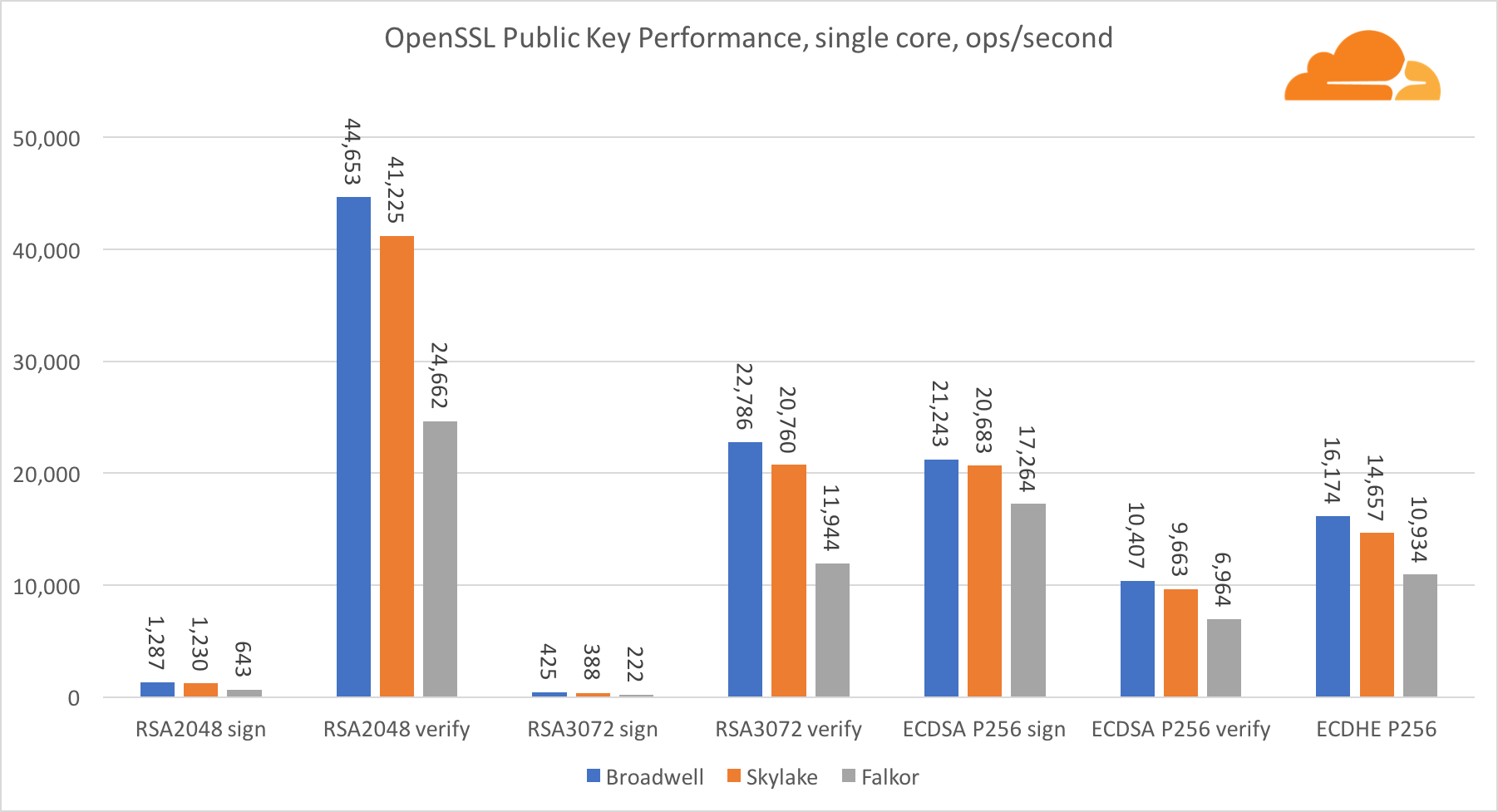
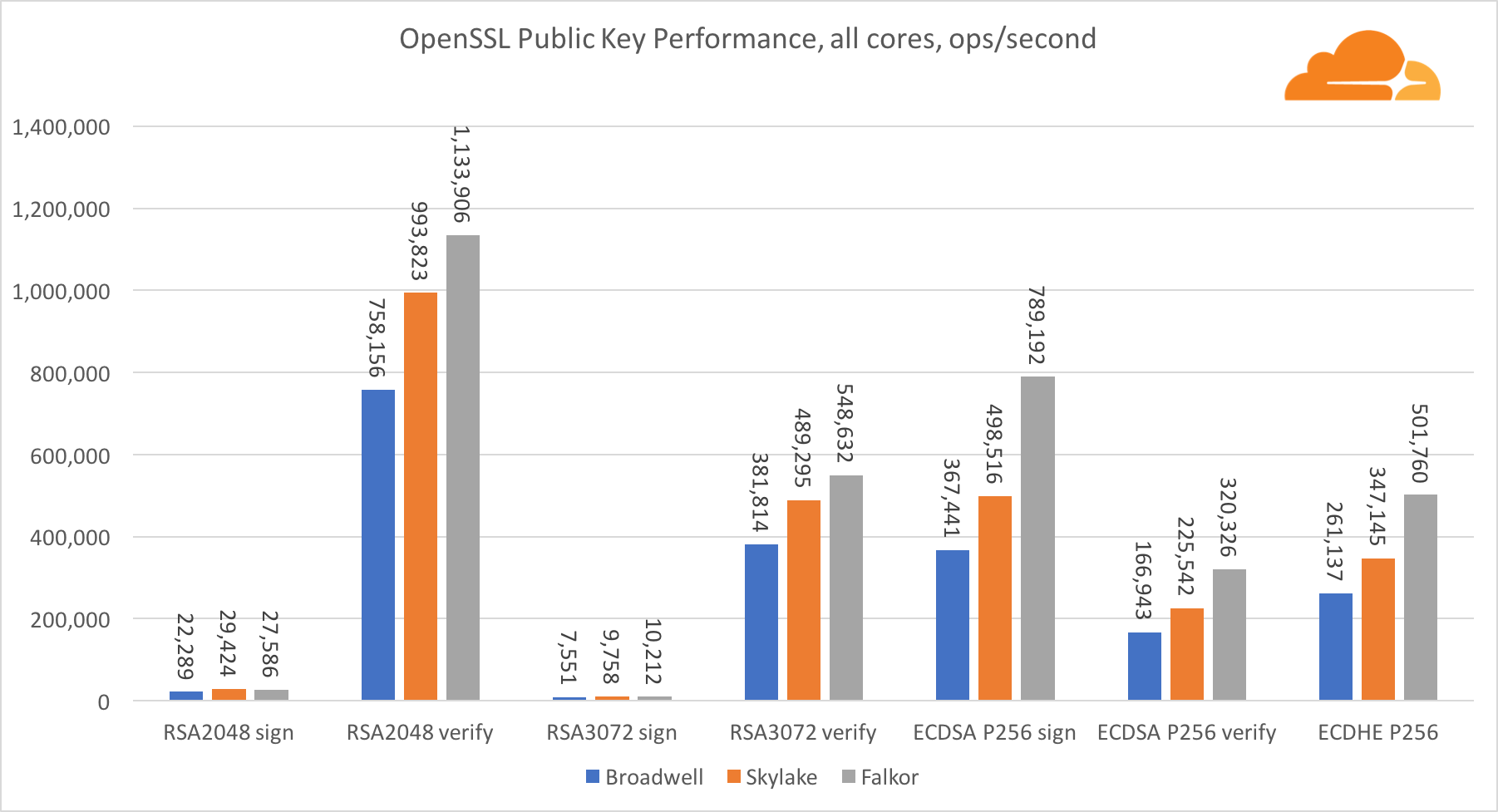
La criptografía de clave pública es el rendimiento más puro de ALU (dispositivo de lógica aritmética). Es interesante, pero no sorprendente, que en un punto de referencia básico, el núcleo de Broadwell es más rápido que Skylake, y ambos son más rápidos que Falkor. Esto se debe a que Broadwell opera a una frecuencia más alta, aunque en términos de arquitectura no es muy inferior a Skylake.
Falkor es inferior a los demás en esta prueba. En primer lugar, el modo turbo se activó en uno de los puntos de referencia básicos, lo que significa que los procesadores Intel funcionan a una frecuencia más alta. Además, Intel presentó dos instrucciones especiales en Broadwell para acelerar el procesamiento de grandes números: ADCX y ADOX. Realizan dos operaciones independientes de agregar con llevar por ciclo, mientras que ARM solo puede hacer una. Del mismo modo, el conjunto de instrucciones ARMv8 no tiene un solo comando para realizar la multiplicación de 64 bits; en cambio, se usa un par de instrucciones MUL y UMULH.
Sin embargo, a nivel de SoC, Falkor gana. Es un poco más lento que Skylake en términos de RSA2048, y solo porque RSA2048 no tiene una implementación optimizada para ARM. El rendimiento de ECDSA es ridículamente alto. Un solo chip Centriq puede satisfacer las necesidades de casi cualquier empresa en el mundo con ECDSA.
También es muy interesante ver que Skylake supera a Broadwell en un 30%, a pesar de que perdió un núcleo en la prueba y tiene solo un 20% más de núcleos que Broadwell. Esto puede explicarse por un modo turbo más eficiente y un hiperhilo mejorado.
Criptografía Simétrica
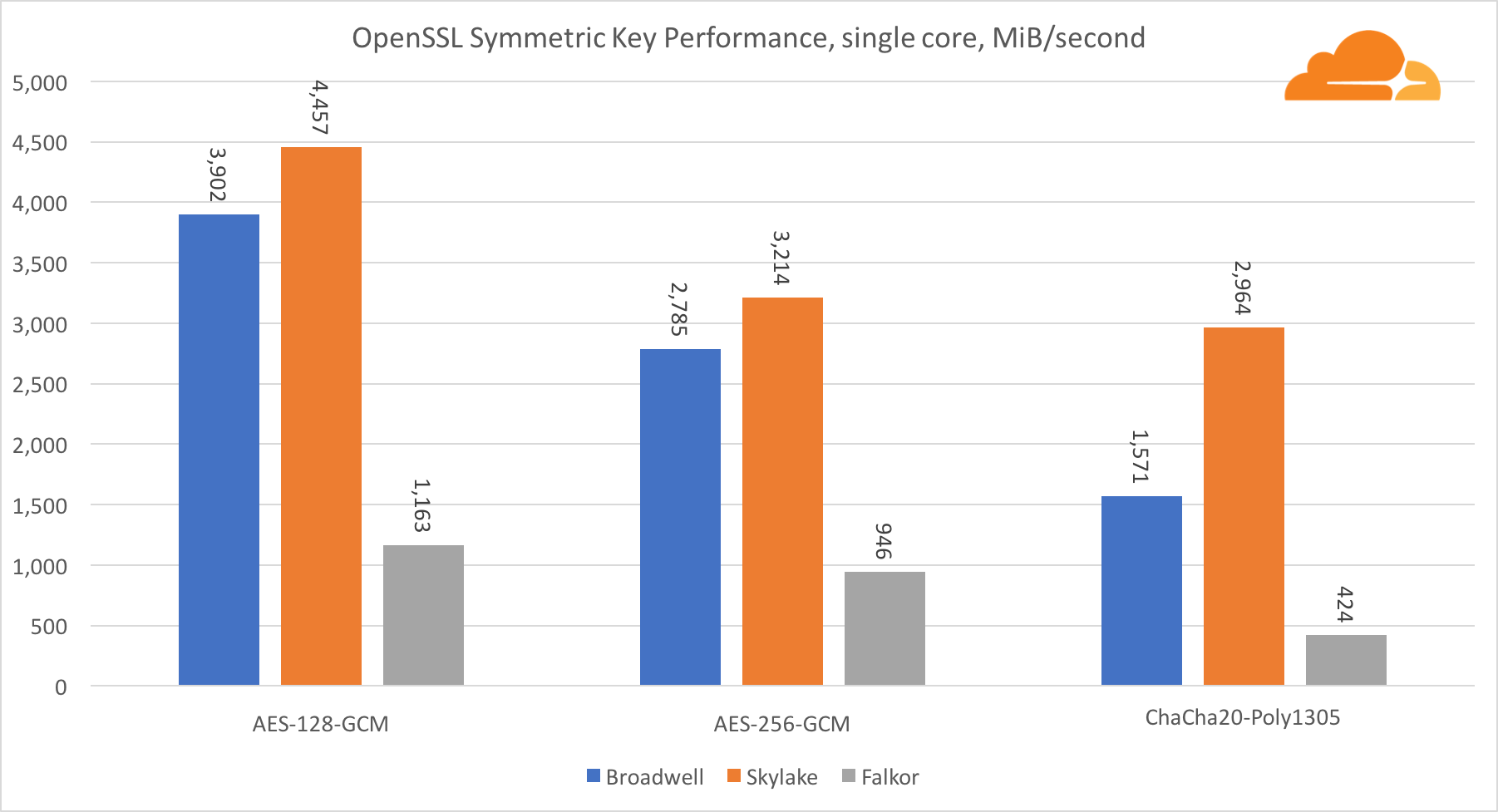
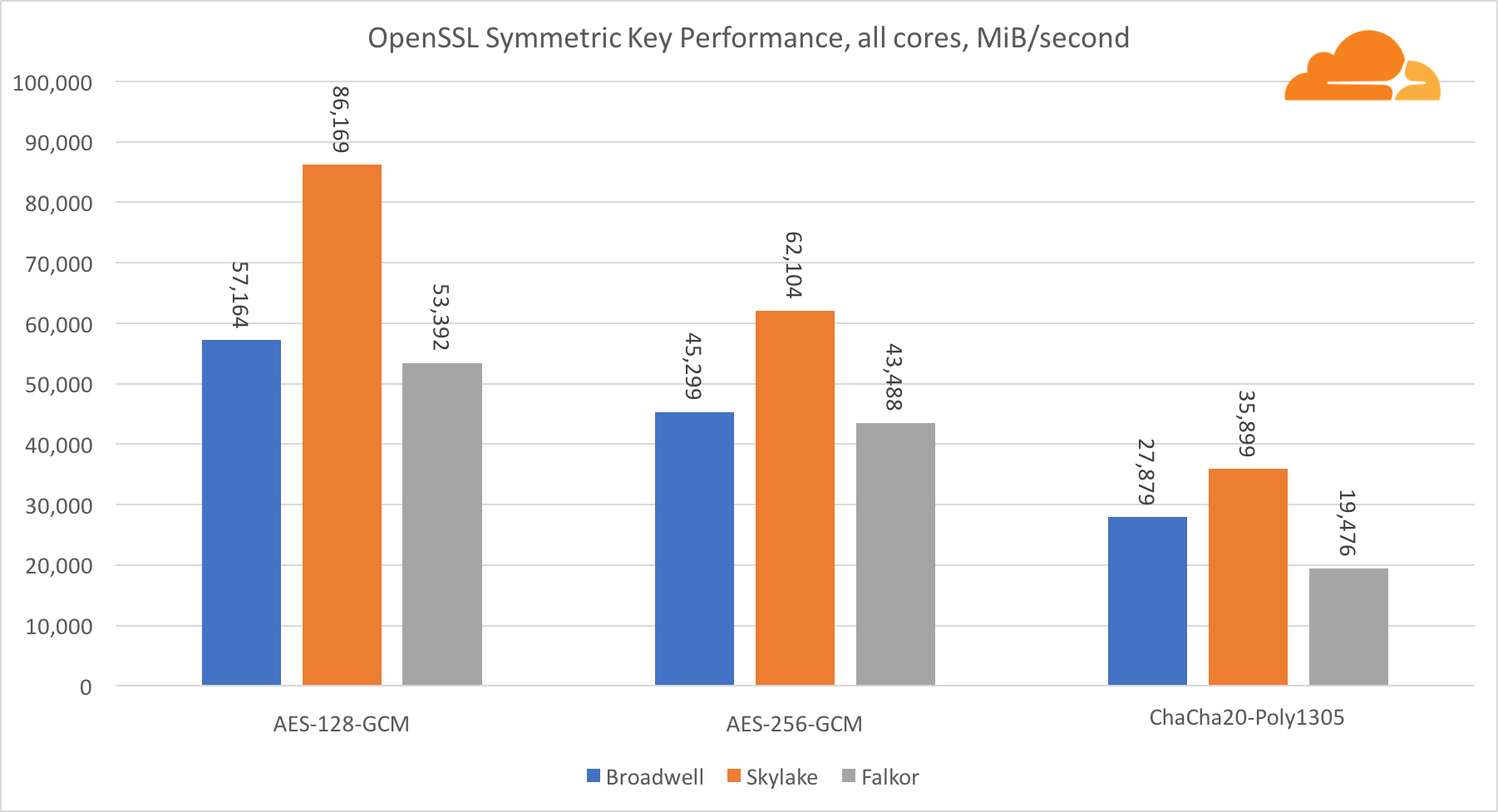
El rendimiento de los núcleos de Intel en criptografía simétrica es simplemente excelente.
AES-GCM utiliza una combinación de instrucciones de hardware especiales para acelerar AES y CLMUL. Intel introdujo estas instrucciones por primera vez en 2010, con su procesador Westmere y con cada generación mejoraron su rendimiento. ARM introdujo recientemente un conjunto de instrucciones similares con su conjunto de instrucciones de 64 bits como una adición opcional. Afortunadamente, todos los proveedores de equipos que conozco los han implementado. Es muy probable que Qualcomm mejore el rendimiento de las instrucciones criptográficas en las generaciones futuras.
ChaCha20-Poly1305 es un algoritmo más general diseñado de tal manera que se aprovechen mejor los módulos SIMD anchos. Qualcomm solo tiene NEON SIMD de 128 bits, Broadwell tiene AVX2 de 256 bits y Skylake tiene AVX-512 de 512 bits. Esto explica por qué Skylake con tal margen dejó a la cabeza en la evaluación del trabajo con un solo núcleo. En la prueba de todos los núcleos, la brecha de Skylake del resto se redujo al mismo tiempo, ya que debería reducir la frecuencia del reloj al realizar cargas de trabajo AVX-512. Cuando se ejecuta el AVX-512 en todos los núcleos, la frecuencia base disminuye a 1.4 GHz. Tenga esto en cuenta si combina AVX-512 y otro código.
La conclusión con respecto a la criptografía simétrica es que, aunque Skylake lidera, Broadwell y Falkor mostraron muy buenos resultados, con un rendimiento bastante alto en casos reales, dado que, por nuestro lado, el RSA consume más tiempo de procesador que todos los demás algoritmos criptográficos combinados .
Compresión (compresión)
La siguiente prueba que quería hacer era la compresión. Por dos razones En primer lugar, esta es una carga de trabajo importante, porque cuanto mejor sea la compresión, menos brechas en la capacidad, y esto permite una entrega más rápida de contenido al cliente. En segundo lugar, esta es una carga de trabajo de predicción errónea de alta frecuencia muy exigente.
Obviamente, la primera prueba será la popular biblioteca zlib. En Cloudflare, utilizamos una versión mejorada de la biblioteca optimizada para procesadores Intel de 64 bits, y aunque está escrita principalmente en C, utiliza algunas características integradas específicas de Intel. Sería injusto comparar esta versión optimizada con el zlib original. Pero no se preocupe, un poco de esfuerzo y adapté la biblioteca para que funcione en la arquitectura ARMv8, utilizando las propiedades NEON y CRC32. Además, su velocidad es 2 veces mayor que la original, para algunos archivos.
La segunda prueba es la nueva biblioteca brotli, escrita en C y que permite el uso de condiciones iguales para todas las plataformas.
Todas las pruebas se realizaron en HTML blog.cloudflare.com, en memoria, similar a cómo NGINX realiza la compresión de transmisión. A menos que la versión específica del archivo HTML sea 29329 bytes, que es un buen indicador, ya que corresponde al tamaño de la mayoría de los archivos que comprimimos. La prueba de compresión paralela es la compresión paralela de varios archivos al mismo tiempo, la compresión única es la compresión de un archivo en varias secuencias, similar a cómo funciona NGINX.
gzip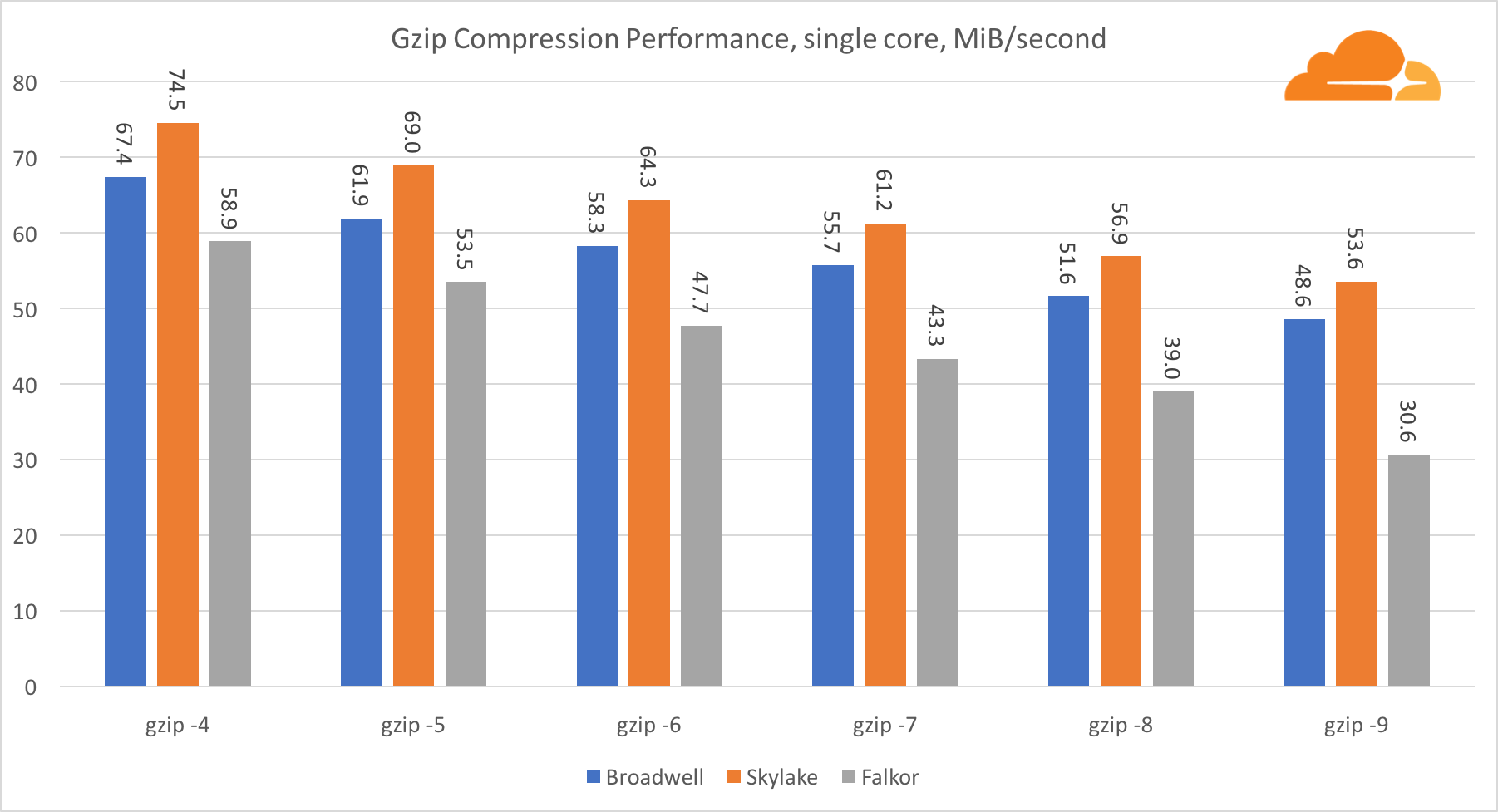
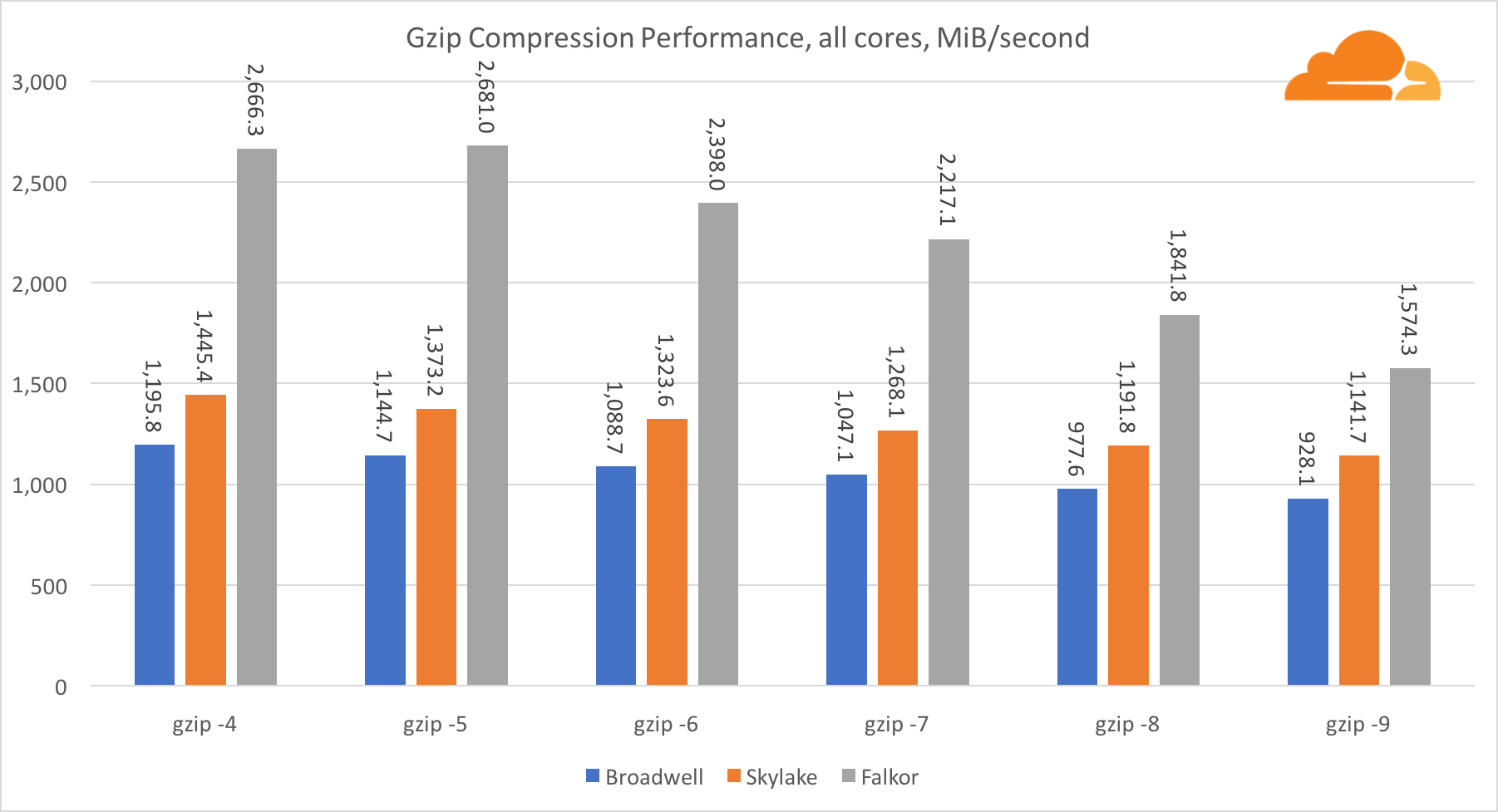
Usando gzip en el nivel de núcleo único, Skylake sin duda gana. Con una frecuencia menor que Broadwell, Skylake se beneficia de una menor exposición a la predicción errónea de las ramas. El núcleo de Falkor no está muy lejos. A nivel del sistema, Falkor funciona mucho mejor con más núcleos. Observe cómo gzip escala bien en múltiples núcleos.
BrotliCon brotli en un núcleo, la situación es similar a la anterior. Skylake es el más rápido, pero Falkor no está muy lejos. Y en el estándar 9, Falkor es aún más rápido. Standard 4 Brotli es muy similar al nivel 5 de gzip, mientras que la compresión real es aún mejor (8010B versus 8187B).
Al comprimir en múltiples núcleos, la situación se vuelve un poco confusa. Para los niveles 4, 5 y 6, el brotli escala muy bien. En los niveles 7 y 8, comienza a caer productivamente en el núcleo, hundiéndose hasta el fondo en el nivel 9, donde obtenemos 3 veces menos productividad de todos los núcleos en comparación con uno.
En mi opinión, esto se debe al hecho de que con cada nivel, brotli comienza a consumir más memoria y bloquea el caché. Los indicadores ya comienzan a recuperarse en los niveles 10 y 11.
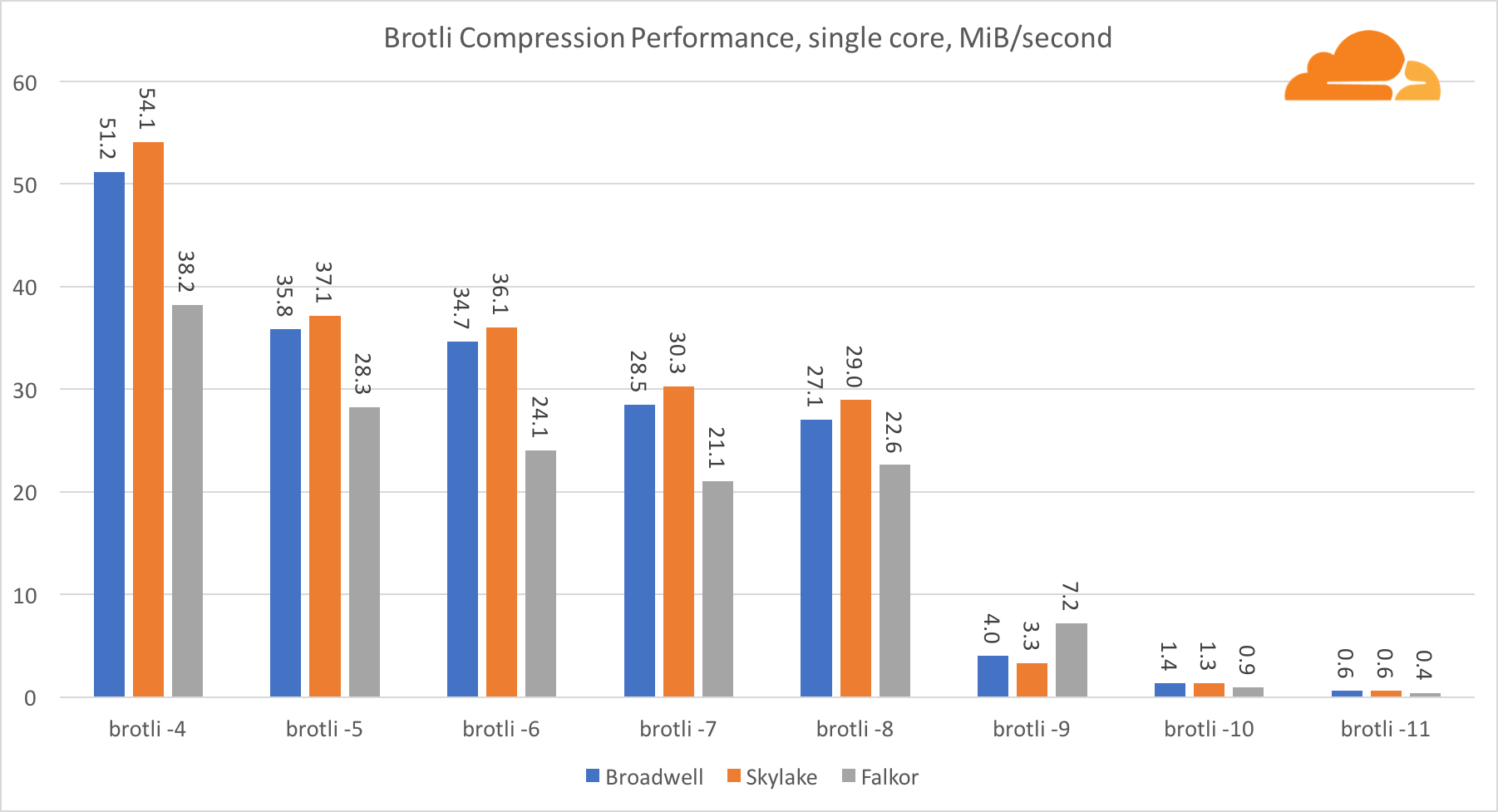
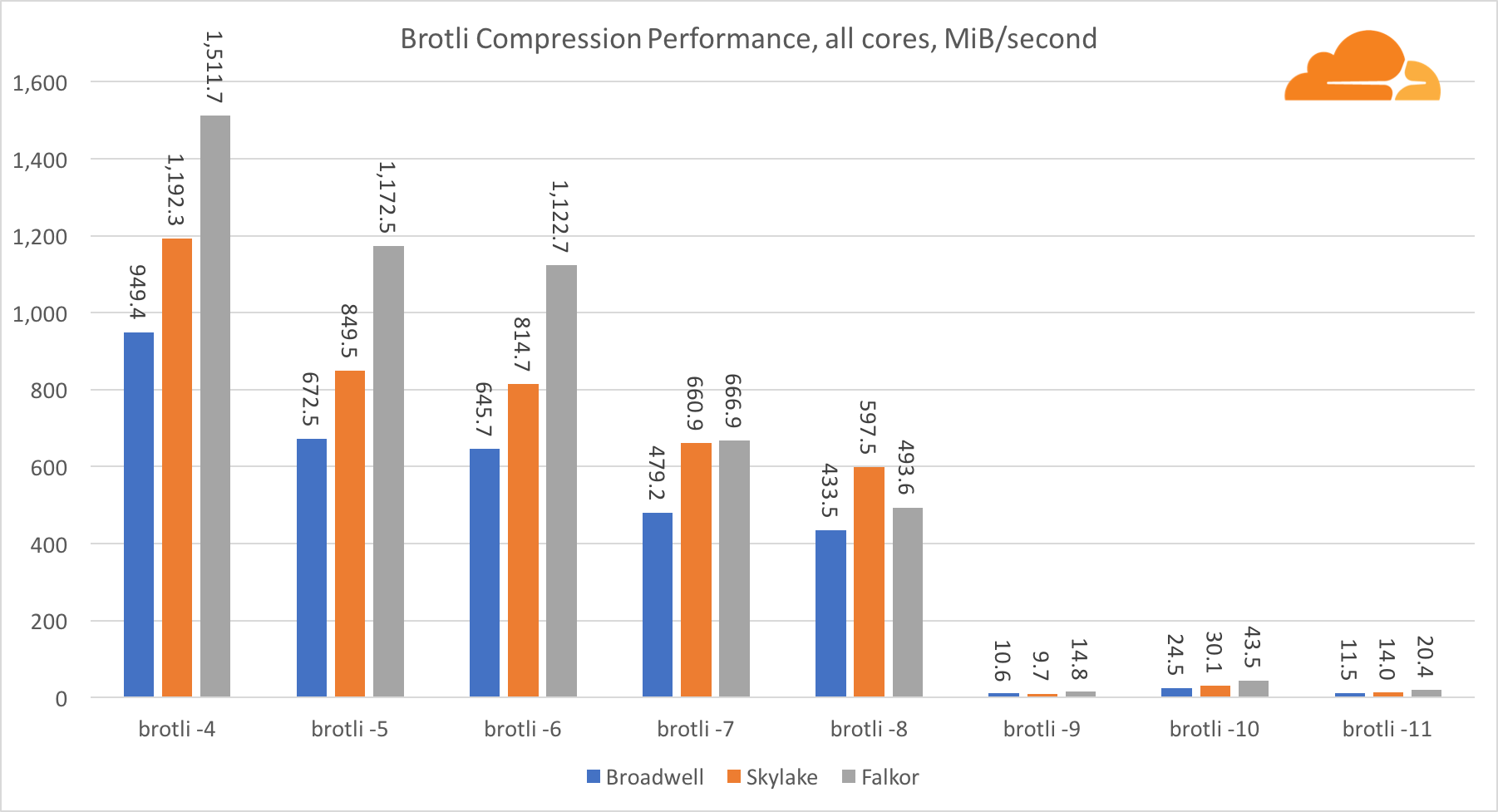
Como conclusión, Falkor ganó, dado que la compresión dinámica no superará el nivel 7.
Golang
Golang es otro lenguaje muy importante para Cloudflare. También es uno de los primeros idiomas que admite ARMv8, por lo que puede esperar un buen rendimiento. Utilicé algunas pruebas integradas, pero las modifiqué para múltiples goroutines.
Ir criptoMe gustaría comenzar con las pruebas de rendimiento de cifrado. Gracias a OpenSSL, tenemos excelentes datos de origen, y será muy interesante ver qué tan buena es la biblioteca Go.
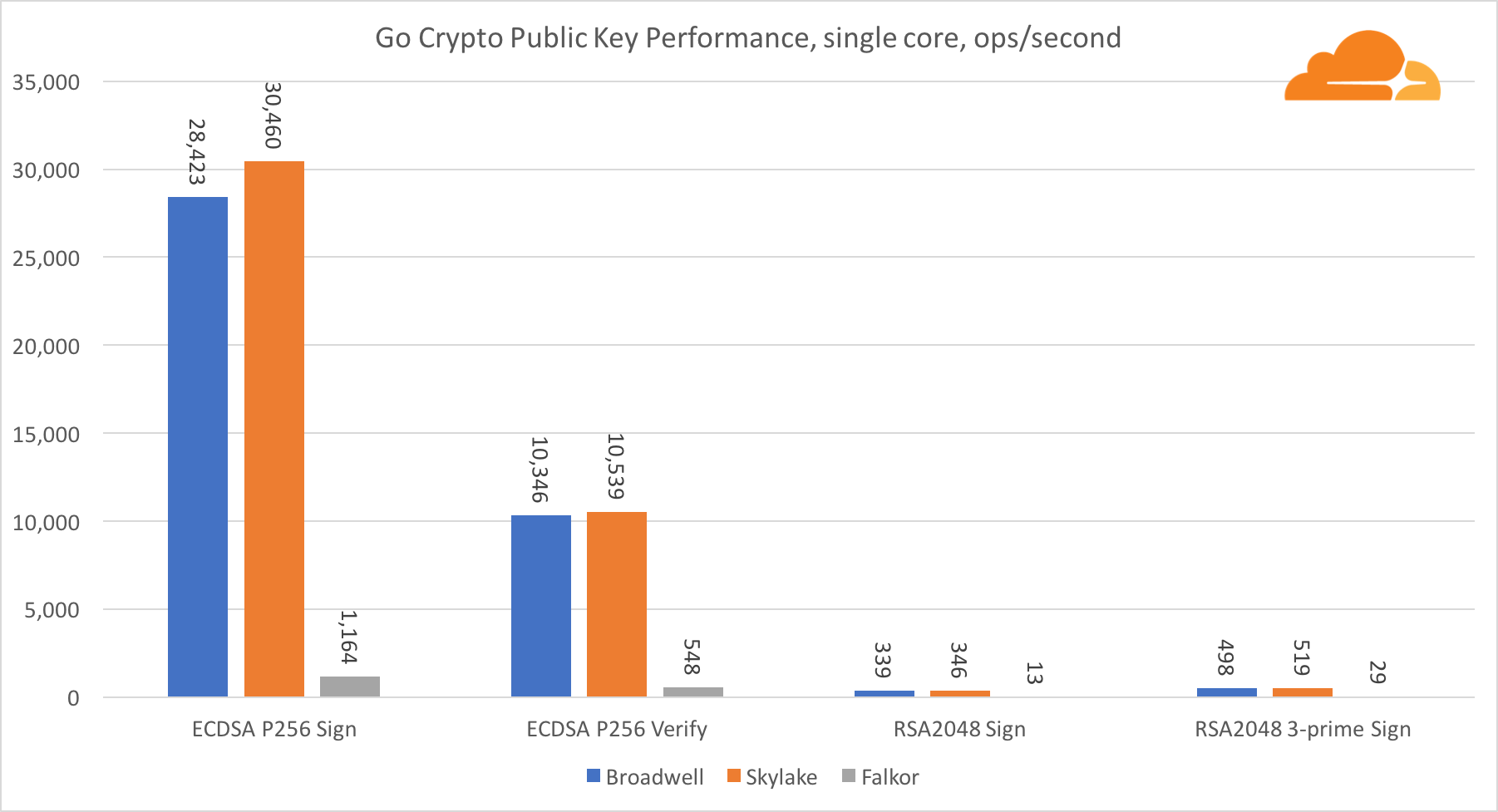
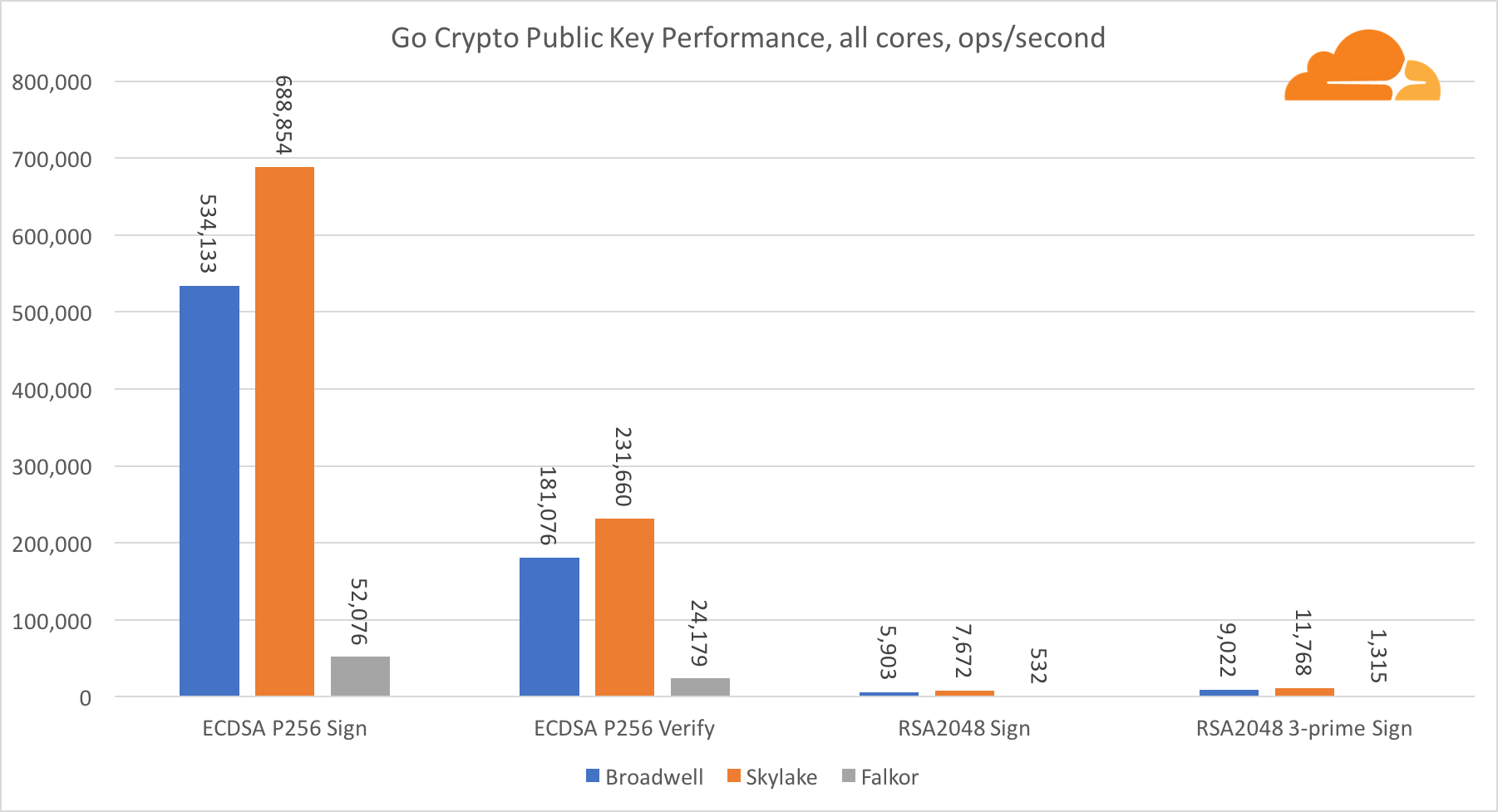
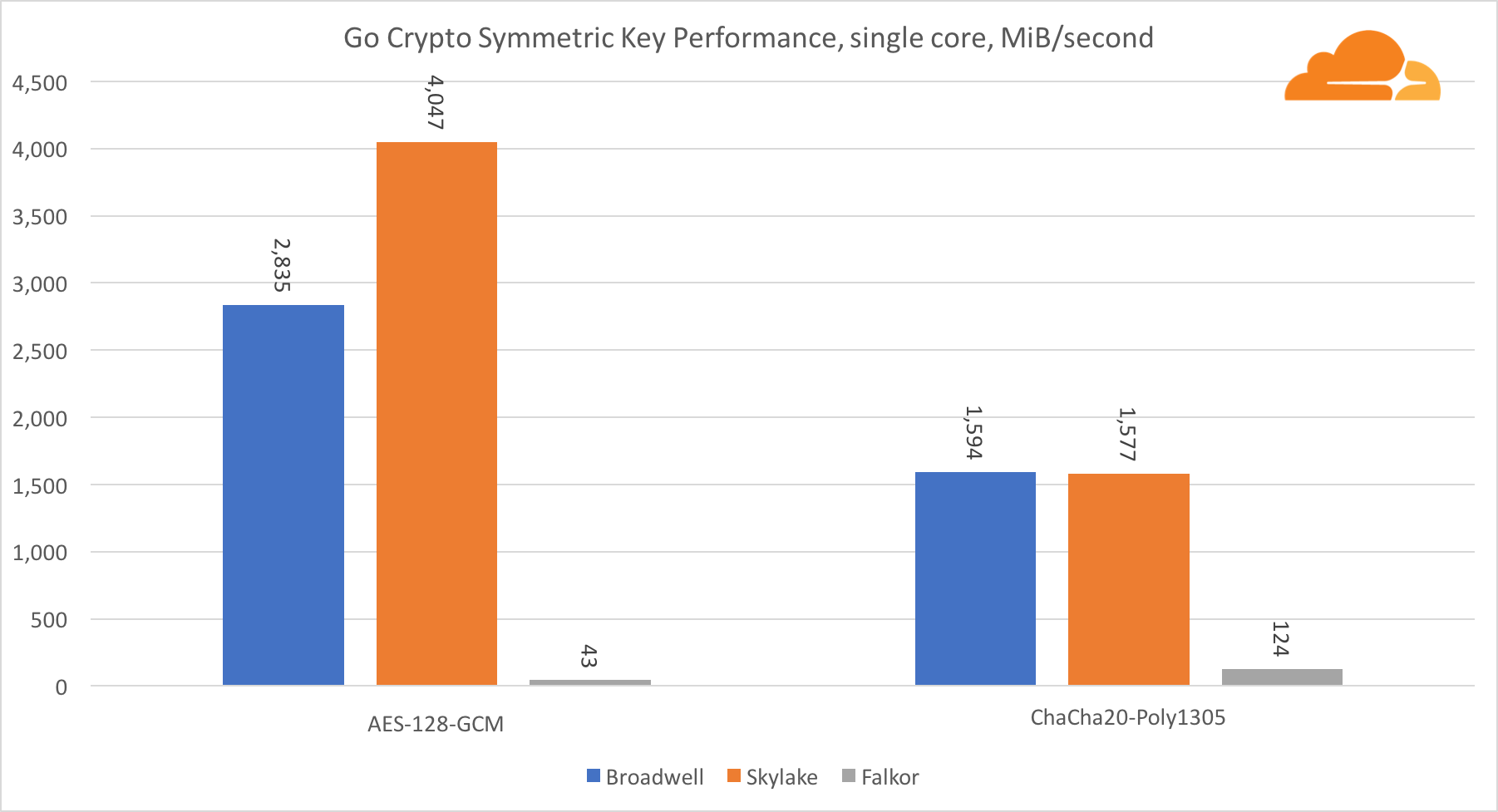
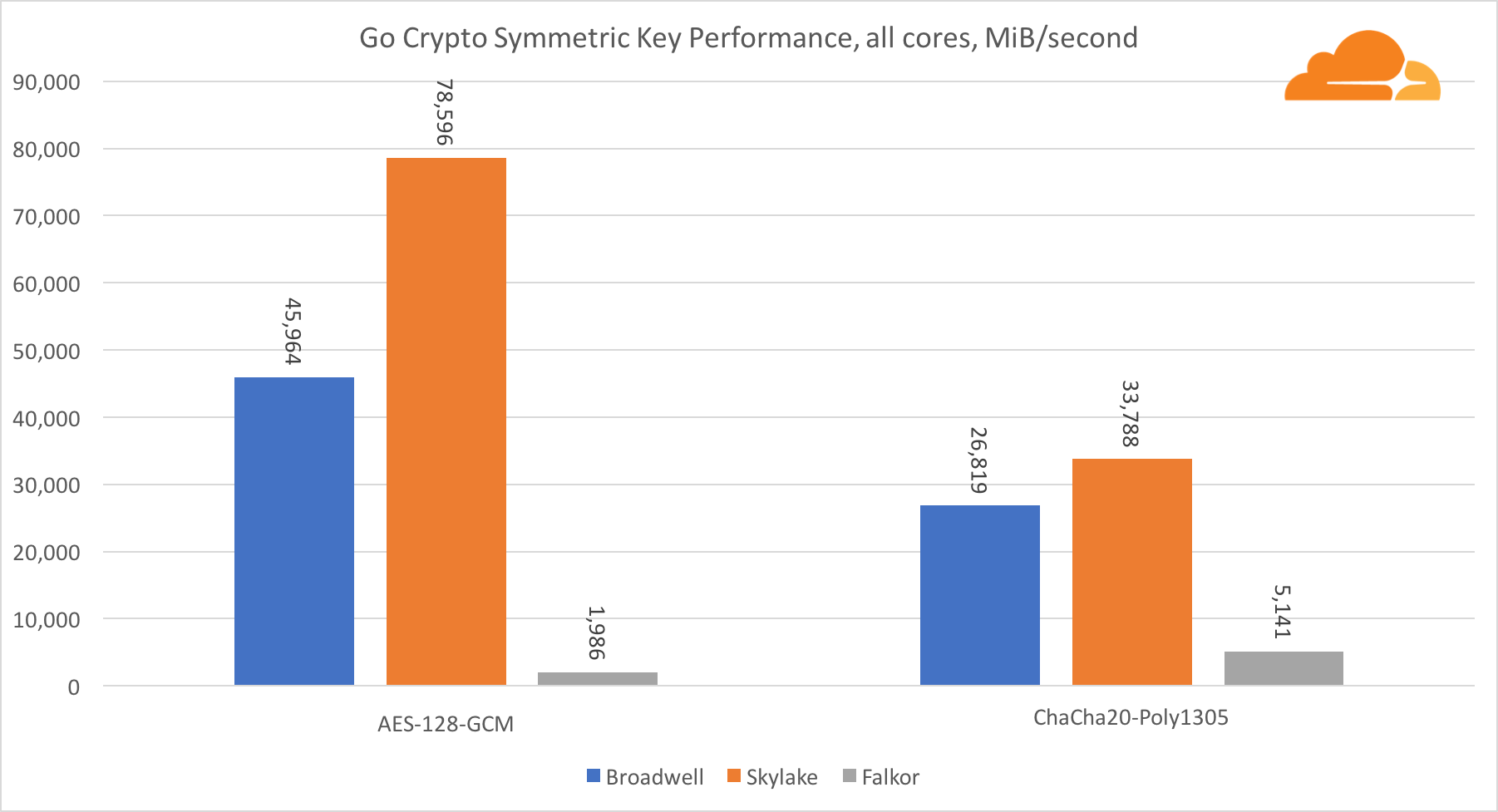
Con respecto a Go crypto, ARM e Intel ni siquiera están en la misma categoría de peso. Go tiene un código de ensamblador altamente optimizado para ECDSA, AES-GCM y Chacha20-Poly1305 en Intel. También hay funciones matemáticas optimizadas utilizadas en los cálculos RSA. ARMv8 no tiene todo esto, lo que lo coloca en una posición muy desventajosa.
Sin embargo, la brecha se puede reducir con relativamente poco esfuerzo, y sabemos que con la optimización adecuada, el rendimiento puede estar a la par con OpenSSL. Incluso cambios muy menores, como la implementación de la función addMulVVW en el ensamblaje, conducen a un aumento de más de diez veces en el rendimiento de RSA, colocando a Falkor (con un puntaje de 8009) por encima de Broadwell y Skylake.
Vale la pena señalar otra cosa interesante: en Skylake, el código Go Chacha20-Poly1305 que usa AVX2 funciona de manera muy similar al código OpenSSL AVX512. Nuevamente, esto se debe al hecho de que el AVX2 funciona a frecuencias de reloj más altas.
Go gzipAhora echemos un vistazo al rendimiento Go de gzip. También hay una gran guía para el código bastante bien optimizado, y podemos compararlo con Go. En el caso de la biblioteca gzip, no hay optimizaciones específicas para Intel.
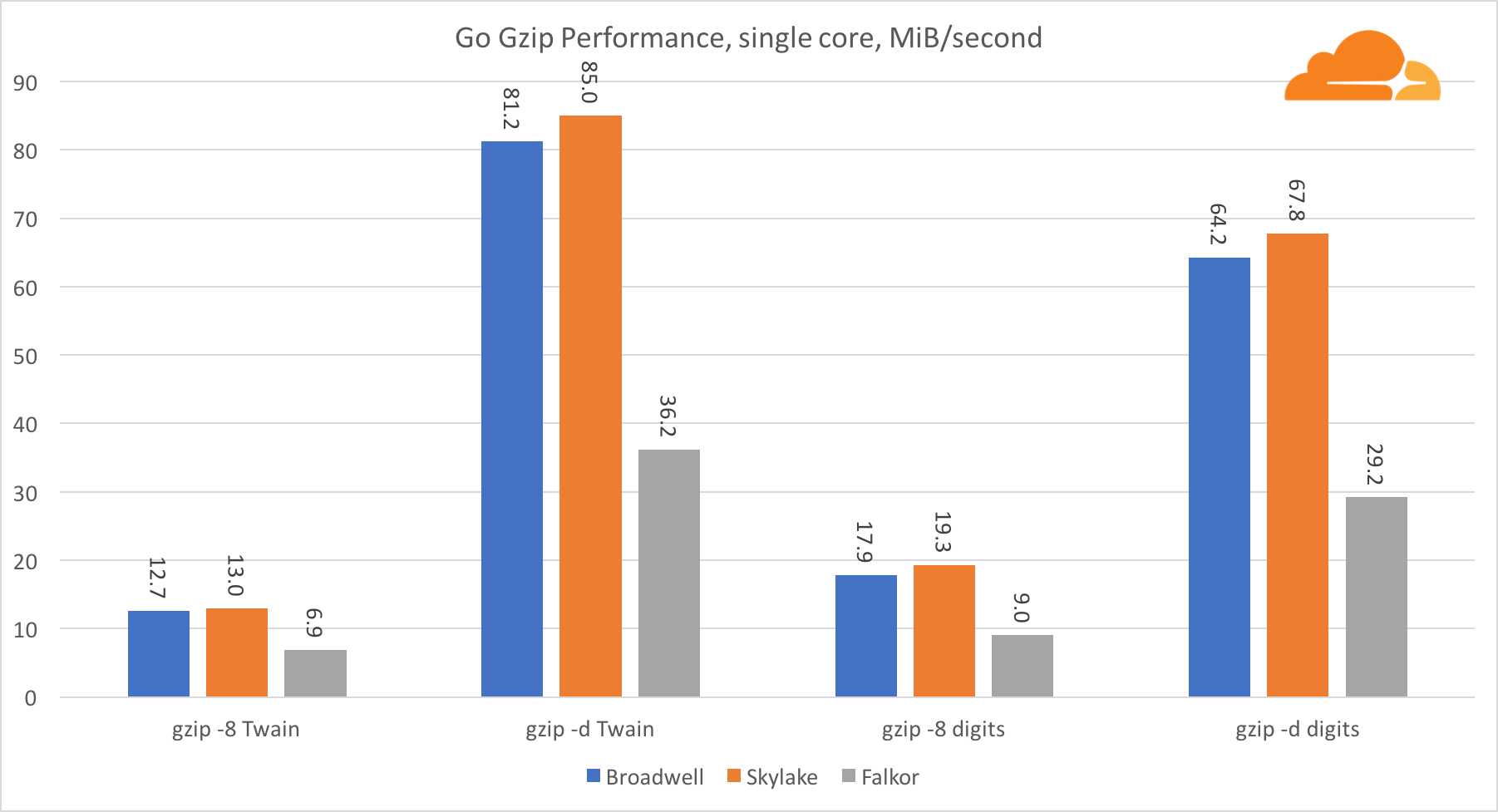

El rendimiento de Gzip es bastante bueno. El rendimiento en un solo núcleo Falkor está muy por detrás de ambos procesadores Intel, pero a nivel de sistema, logró vencer a Broadwell y se encuentra debajo de Skylake. Como ya sabemos que Falkor es superior a los otros dos procesadores cuando se ejecuta C. Esto solo puede significar una cosa: el backend Go para ARMv8 todavía no está finalizado en comparación con gcc.
Ir regexpRegexp se usa ampliamente en una variedad de tareas, porque su rendimiento también es extremadamente importante. Ejecuté pruebas integradas en transmisiones de 32 kb.
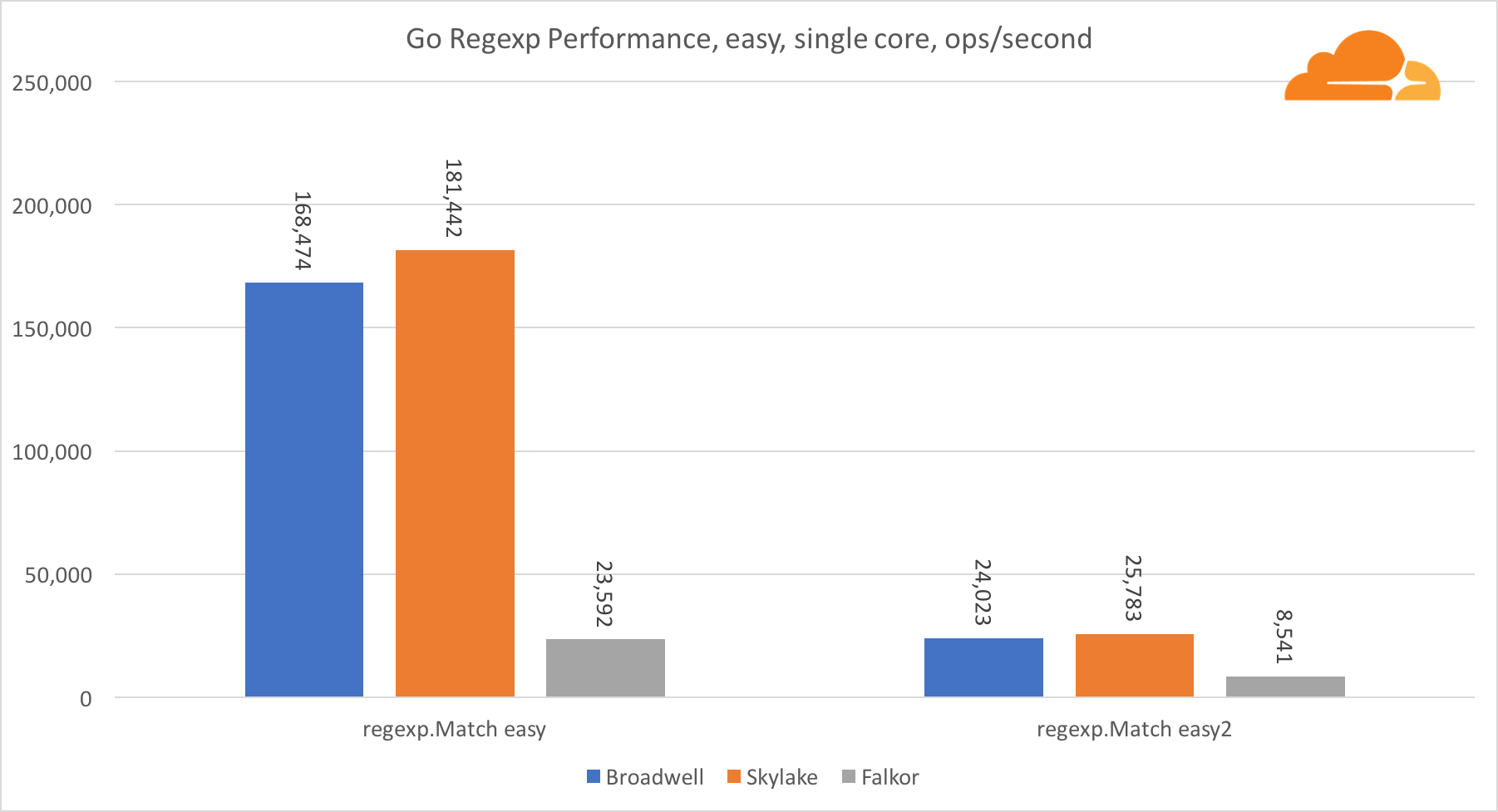
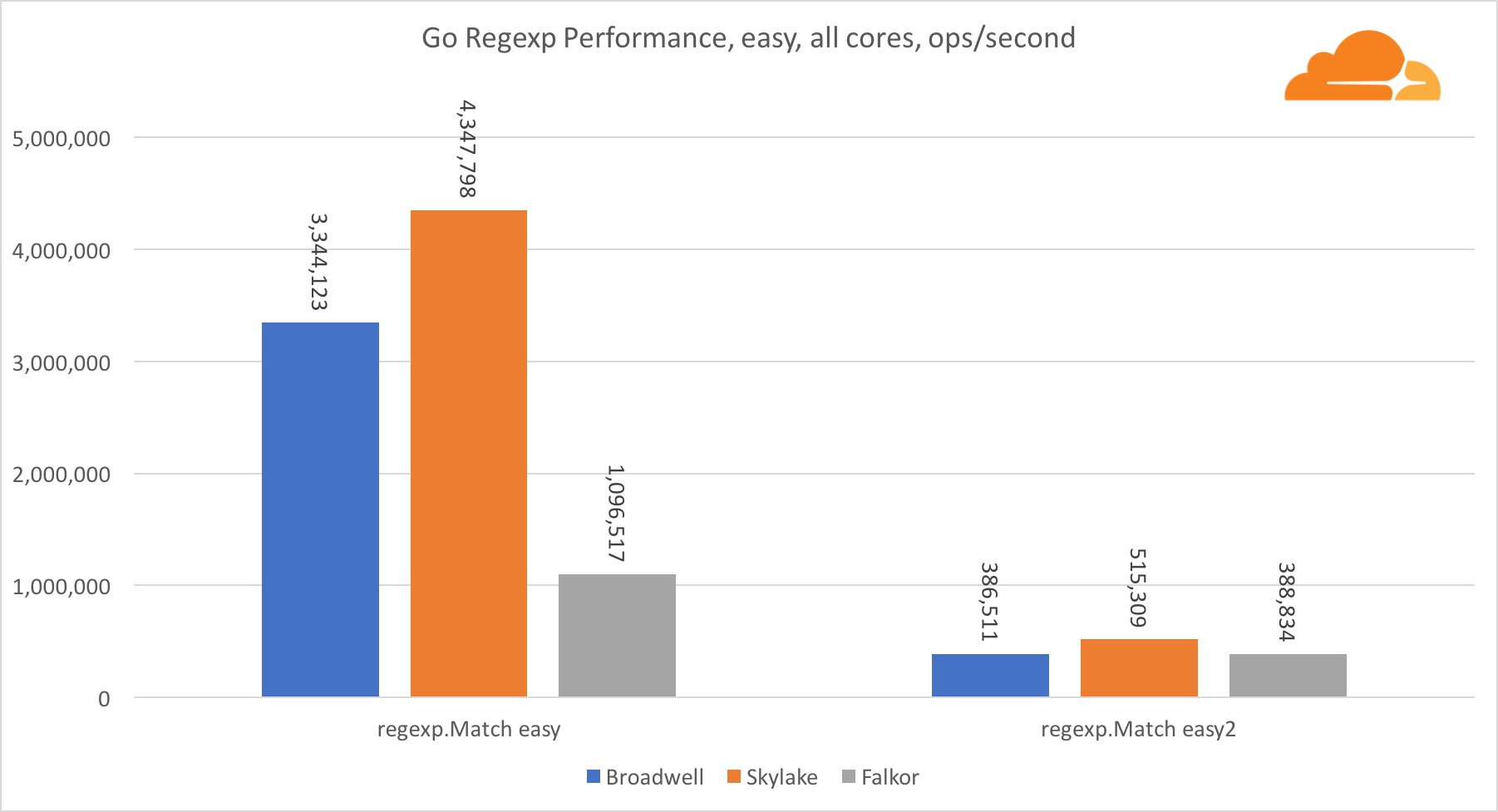
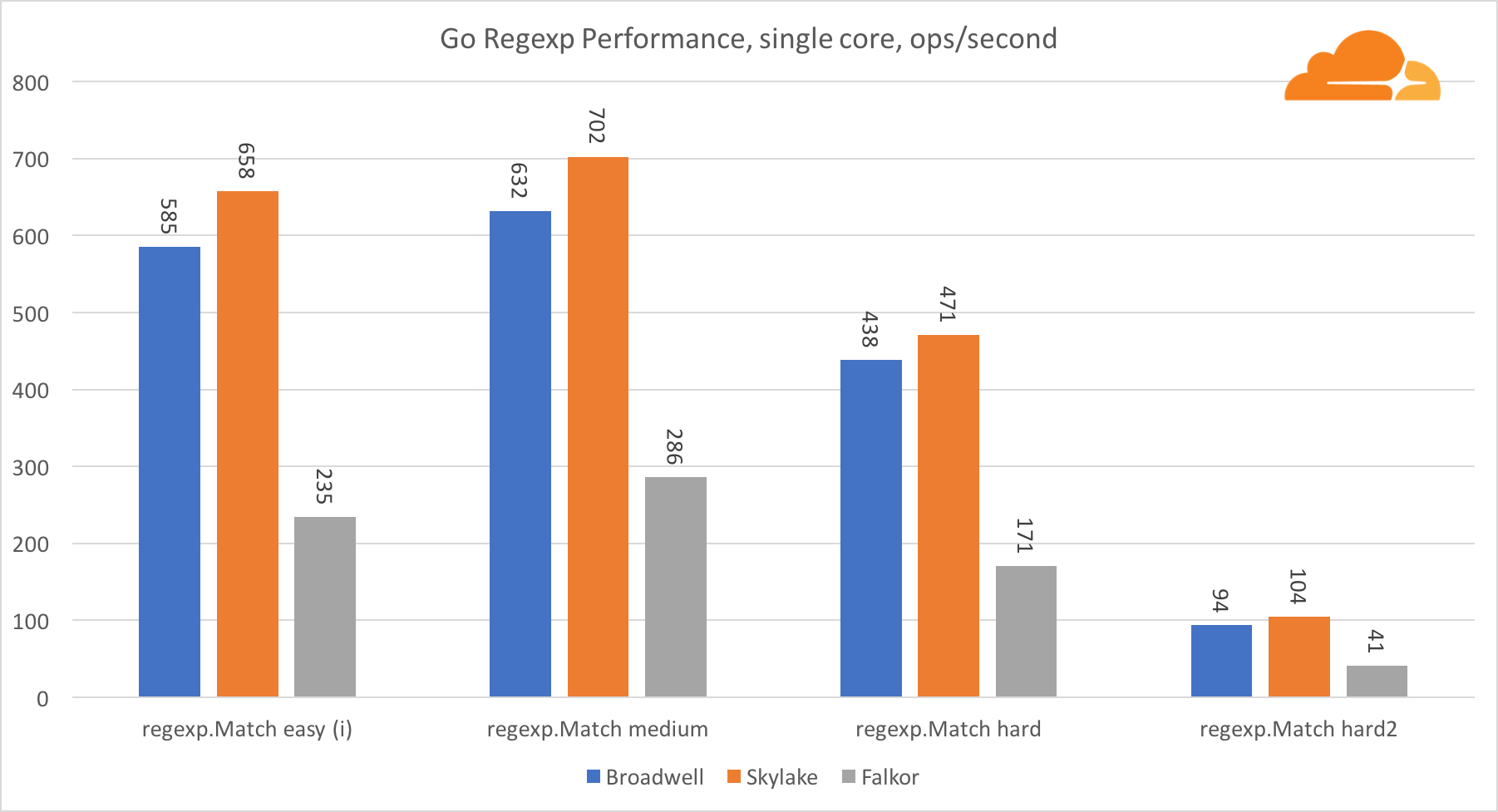
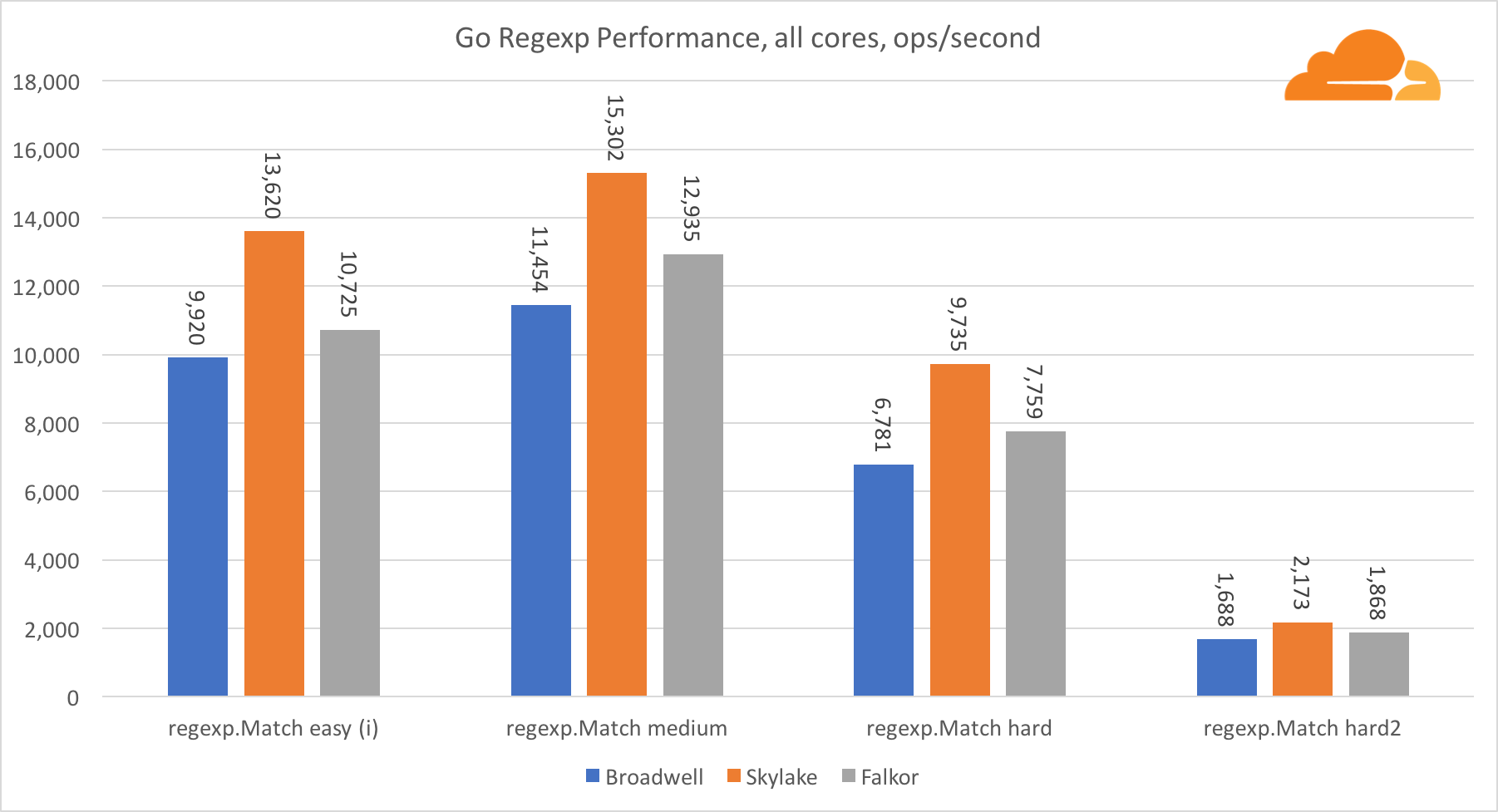
En Falkor, el rendimiento de Go regexp no es muy bueno. Toma el segundo lugar en pruebas medias y complejas, gracias a una mayor cantidad de núcleos, pero Skylake es mucho más rápido.
Una mirada más cercana al proceso muestra que se dedica mucho tiempo a la función bytes.IndexByte. Esta función tiene una implementación de ensamblador para amd64 (runtime.indexbytebody), pero la implementación principal es para Go. Durante las pruebas livianas, regexp pasó aún más tiempo en esta función, lo que explica la brecha más amplia.
Ir cuerdasOtra biblioteca importante para el servidor web son las cadenas Go. Probé solo la clase principal de Replacer.
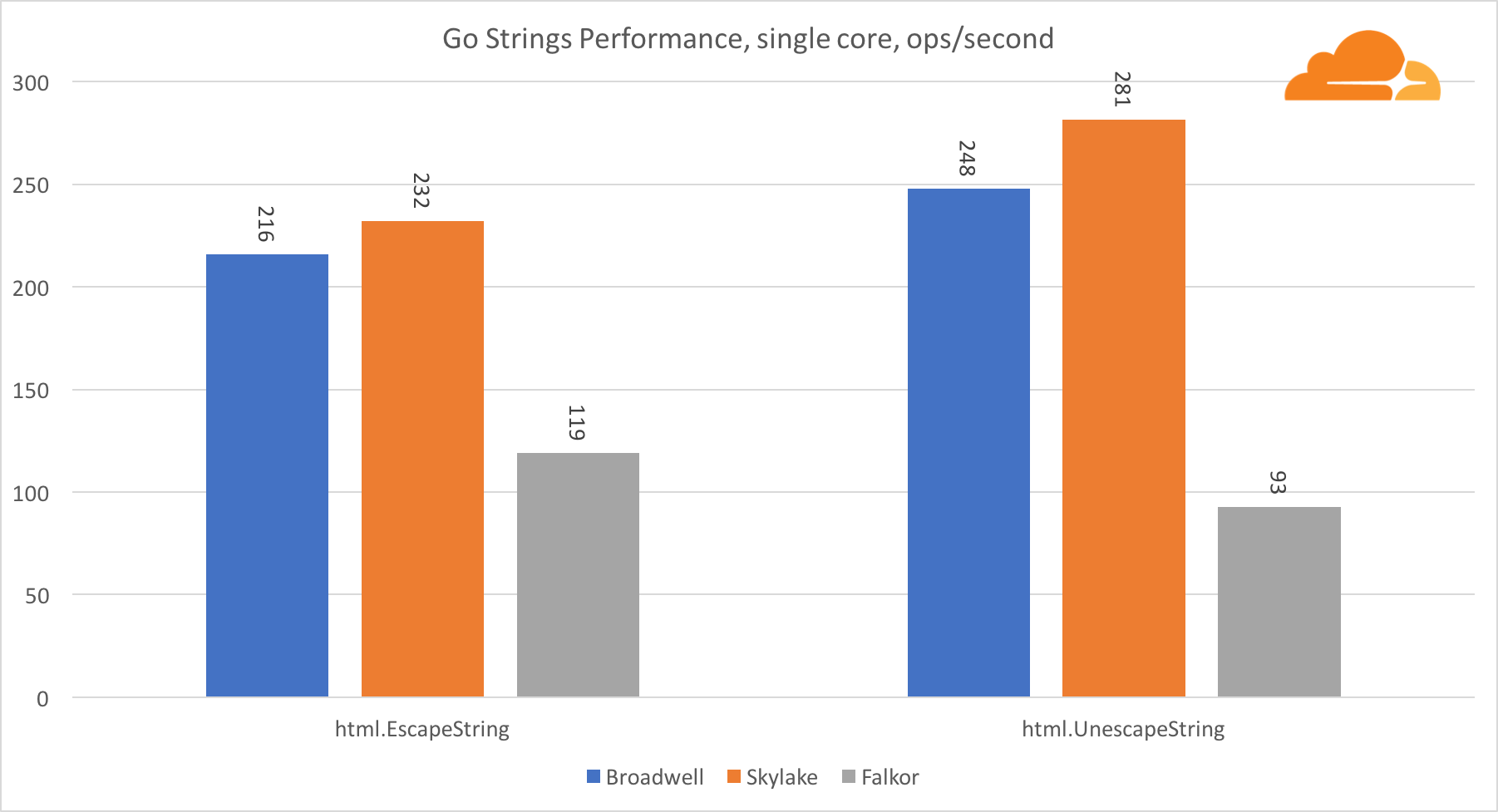
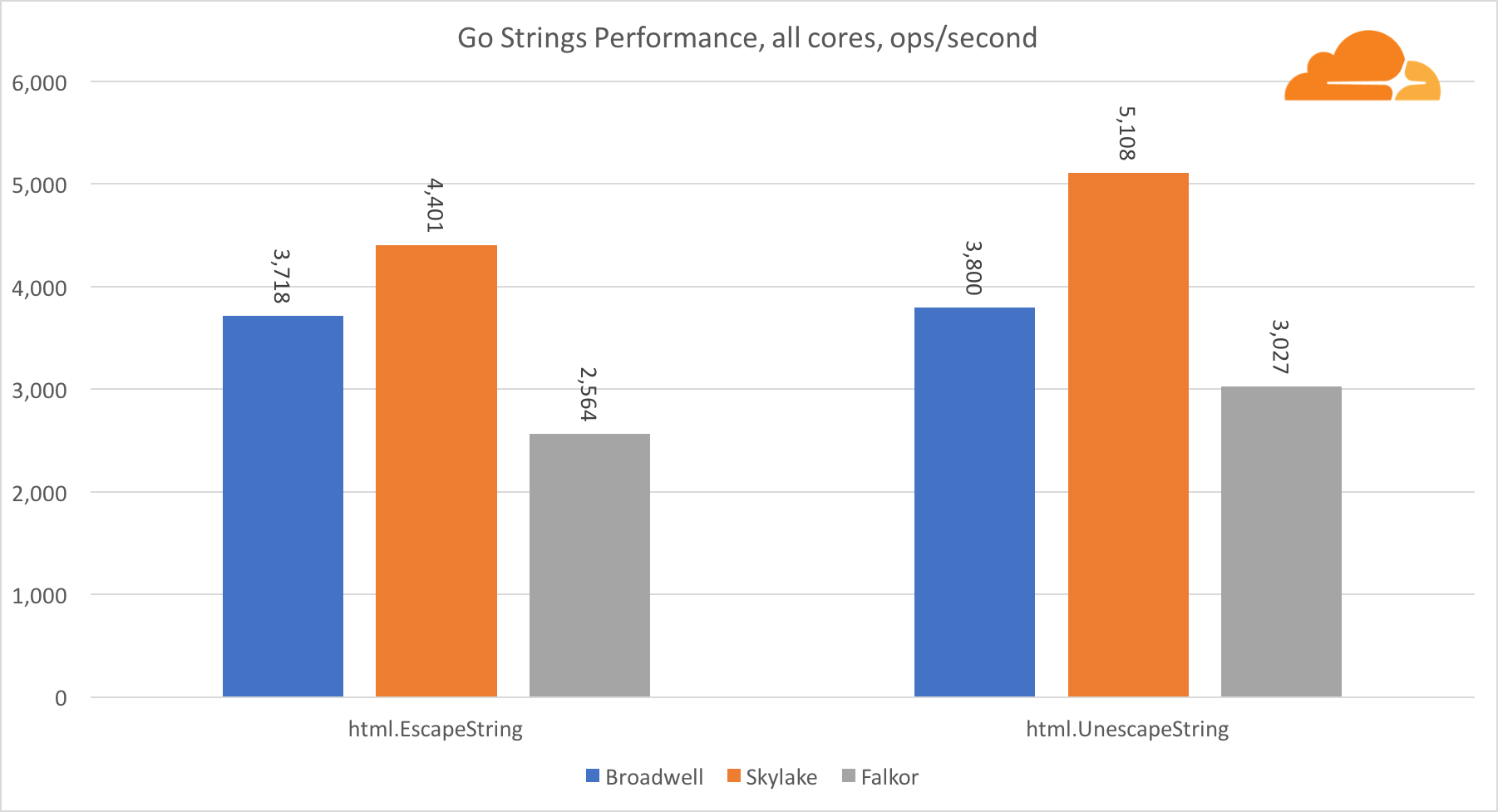
En esta prueba, Falkor vuelve a quedarse atrás, incluso detrás de Broadwell. Una mirada más cercana revela una larga permanencia en la función runtime.memmove. ¿Sabes que? Ella tiene un código de ensamblador perfectamente optimizado para amd64 que usa AVX2, pero solo el ensamblador más simple que copia 8 bytes a la vez. Al cambiar 3 líneas en este código y usar las instrucciones LDP / STP (carga de pares / almacenamiento de pares), puede copiar 16 bytes a la vez, lo que aumentó el rendimiento de memmove en un 30%, lo que, a su vez, acelera EscapeString y UnescapeString en un 20%. Y esto es solo la punta del iceberg.
Ir a la conclusiónIr a soporte en aarch64 es bastante decepcionante. Me complace anunciar que todo se compiló y funcionó a la perfección, pero por el lado del rendimiento podría ser mejor. Uno tiene la impresión de que la mayor parte del esfuerzo se gastó en el backend del compilador, y la biblioteca estaba casi intacta. Hay muchas optimizaciones de bajo nivel, por ejemplo, mi arreglo addMulVVW, que tardó 20 minutos. Qualcomm y otros proveedores de ARMv8 tienen la intención de gastar importantes recursos técnicos para rectificar la situación, pero cualquiera puede contribuir a Go. Por lo tanto, si desea dejar su huella en el historial, ahora es el momento.
Luajit
Lua es el pegamento que mantiene unido Cloudflare.
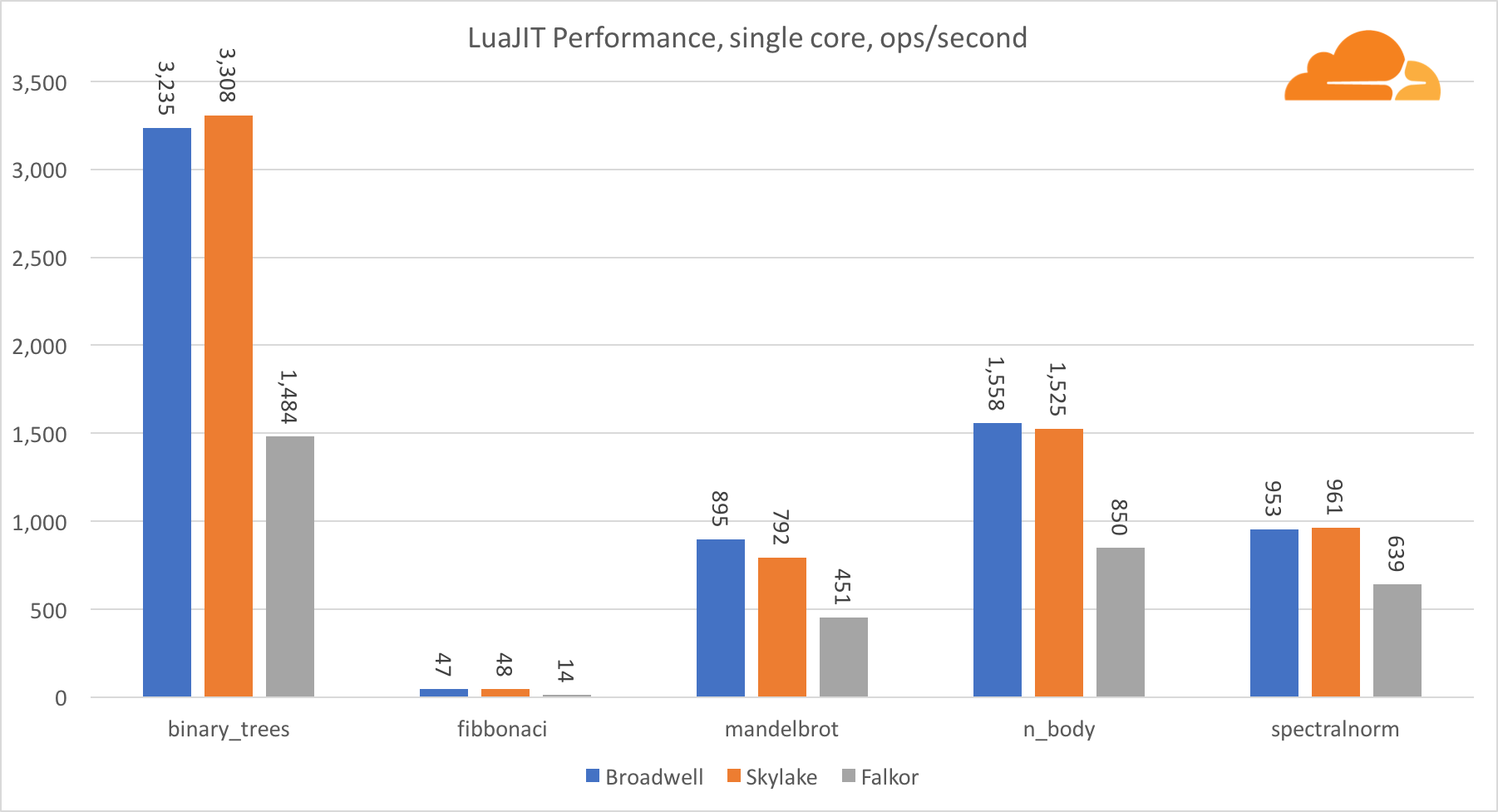
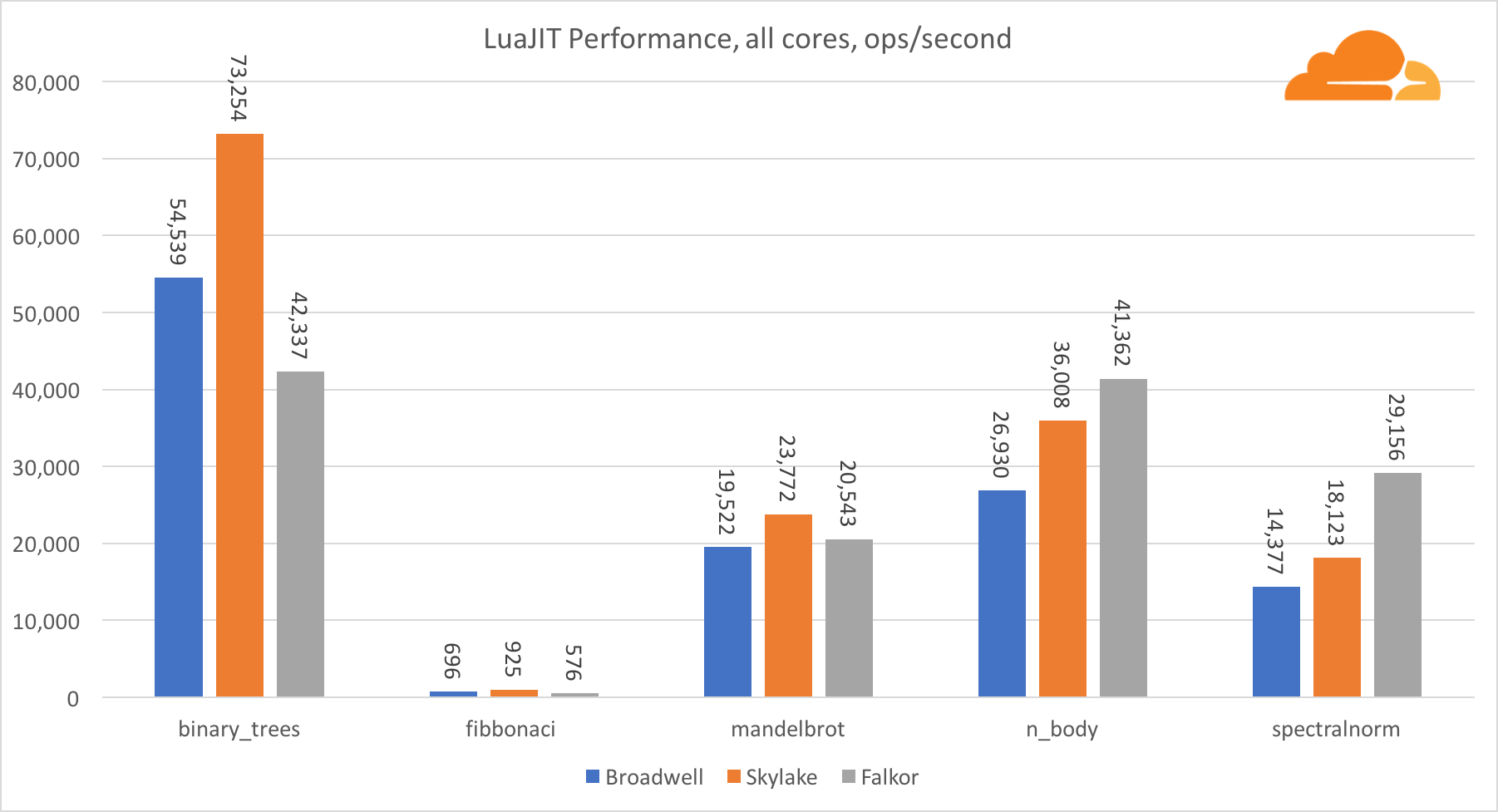
Con la excepción de la prueba binary_trees, el rendimiento de LuaJIT en ARM es muy competitivo. Gana dos pruebas, y la tercera va cara a cara con los competidores.
Vale la pena señalar que la prueba binary_trees es extremadamente importante, ya que involucra muchos ciclos de asignación de memoria y recolección de basura. Requiere una consideración más meticulosa en el futuro.
Nginx
Como una carga de trabajo NGINX, decidí crear una que se pareciera al servidor real.
Configuré un servidor que sirve el archivo HTML utilizado en la prueba gzip sobre https usando el conjunto de cifrado ECDHE-ECDSA-AES128-GCM-SHA256.
También utiliza LuaJIT para redirigir la solicitud entrante, eliminar todos los saltos de línea y espacios adicionales del archivo HTML al agregar una marca de tiempo. El HTML se comprime usando brotli 5.
Cada servidor se configuró para trabajar con tantos usuarios como procesadores virtuales. 40 para Broadwell, 48 para Skylake y 46 para Falkor.
Como cliente para esta prueba, utilicé el programa Hey que se ejecuta en 3 servidores Broadwell.
Al mismo tiempo que la prueba, tomamos lecturas de potencia de los bloques BMC correspondientes de cada servidor.
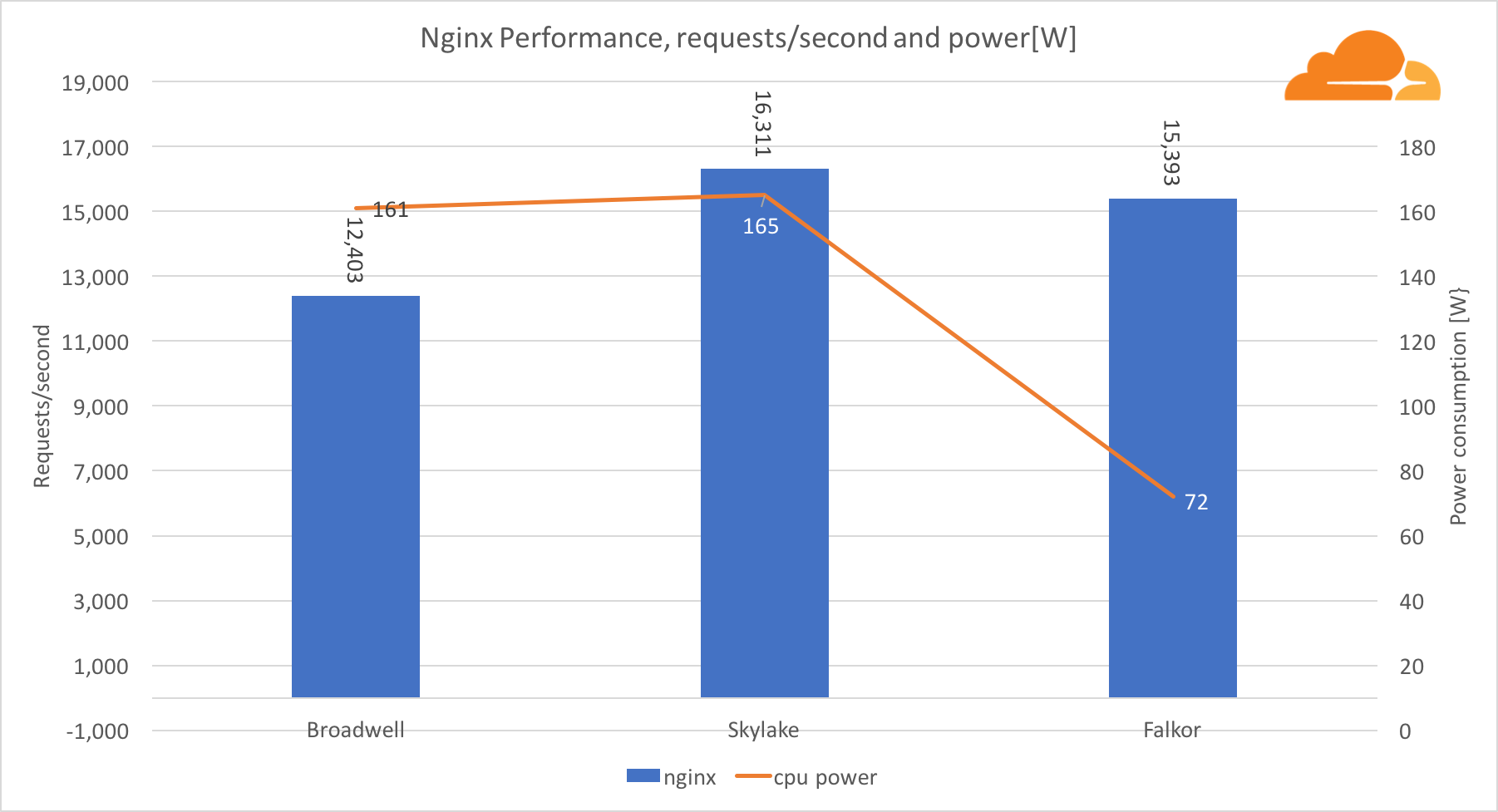
Con la carga de trabajo, NGINX Falkor manejó casi el mismo número de solicitudes que el servidor Skylake, y ambos estuvieron significativamente por delante de Broadwell. Las lecturas de energía tomadas del BMC muestran que esto sucedió cuando la energía se consumió la mitad que otros procesadores. Esto significa que Falkor logró obtener 214 solicitudes / W, Skylake - 99 solicitudes / W y Broadwell - 77 solicitudes / W.
Me sorprendió que Skylake y Broadwell consuman aproximadamente la misma cantidad de energía, dado que se producen de la misma manera, y Skylake tiene más núcleos.
El bajo consumo de energía de Falkor no es sorprendente, ya que los procesadores Qualcomm son conocidos por su alta eficiencia energética, lo que les permitió ocupar una posición dominante en el mercado de procesadores para dispositivos móviles.
Conclusión
La muestra de Falkor que obtuvimos realmente me impresionó. Esta es una gran mejora con respecto a los intentos anteriores en servidores basados en ARM. Por supuesto, al comparar el núcleo con el núcleo, Intel Skylake es mucho mejor, pero si observamos el nivel del sistema, el rendimiento se vuelve muy atractivo.
La versión de producción de Centriq SoC contendrá 48 núcleos Falkor que operan a frecuencias de hasta 2.6 GHz, lo que da un aumento potencial de rendimiento del 8%.
Obviamente, el Skylake que probamos no es un buque insignia como Platinum con sus 28 núcleos, pero estos 28 núcleos cuestan mucho y consumen 200W, mientras tratamos de optimizar nuestros costos y aumentar el rendimiento en 1 vatio.
Por el momento, estoy más preocupado por el bajo rendimiento del lenguaje Go, pero esto cambiará tan pronto como los servidores basados en ARM ocupen su nicho en el mercado.
El rendimiento C y LuaJIT son muy competitivos y, en muchos casos, superiores a Skylake. En casi todas las pruebas, Falkor demostró ser un digno reemplazo para Broadwell.
La mayor ventaja para Falkor en este momento es el bajo consumo de energía. Aunque el TDP es de 120 W, durante mis pruebas, esta cifra nunca superó los 89 W (para las pruebas Go). A modo de comparación, Skylake y Broadwell superaron los 160 W, mientras que su TDP es de 170 W.
Como un anuncio publicitario. ¡Estos no son solo servidores virtuales! Estos son VPS (KVM) con unidades dedicadas, que no pueden ser peores que los servidores dedicados, y en la mayoría de los casos, ¡mejor!
Fabricamos VPS (KVM) con unidades dedicadas en los Países Bajos y los EE . UU. (Configuraciones de VPS (KVM) - E5-2650v4 (6 núcleos) / 10GB DDR4 / 240GB SSD o 4TB HDD / 1Gbps 10TB disponibles a un precio excepcionalmente bajo - desde $ 29 / mes , las opciones con RAID1 y RAID10 están disponibles) , ¡no pierda la oportunidad de hacer un pedido de un nuevo tipo de servidor virtual, donde todos los recursos le pertenecen, como en uno dedicado, y el precio es mucho más bajo, con un hardware mucho más productivo!
Cómo construir la infraestructura del edificio. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo? Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos!