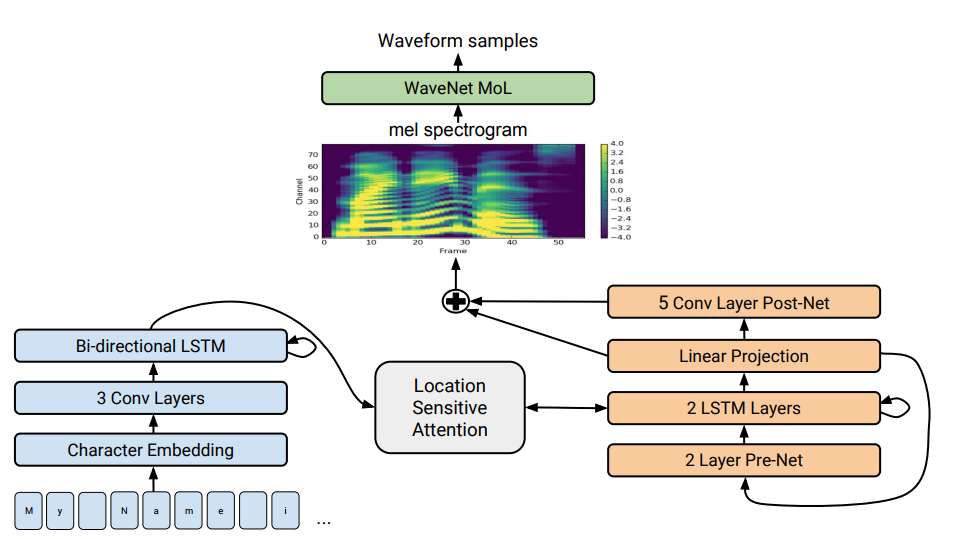
 Arquitectura Tacotron 2. En la parte inferior de la ilustración, se muestran modelos de oferta a oferta que traducen una secuencia de letras en una secuencia de atributos en un espacio de 80 dimensiones. Para una descripción técnica ver un artículo científico.
Arquitectura Tacotron 2. En la parte inferior de la ilustración, se muestran modelos de oferta a oferta que traducen una secuencia de letras en una secuencia de atributos en un espacio de 80 dimensiones. Para una descripción técnica ver un artículo científico.La síntesis del habla, la reproducción artificial del habla humana a partir de un texto, se considera tradicionalmente uno de los componentes de la inteligencia artificial. Anteriormente, tales sistemas solo podían verse en películas de ciencia ficción, pero ahora funcionan literalmente en todos los teléfonos inteligentes: estos son Siri, Alice y similares. Pero no hacen frases muy realistas: voz inanimada, las palabras están separadas entre sí.
Google ha
desarrollado un sintetizador de voz avanzado de próxima generación. Se llama Tacotron 2 y se basa en una red neuronal. Para demostrar sus capacidades, la compañía publicó
ejemplos de síntesis . En la parte inferior de la página con ejemplos, puede realizar una prueba e intentar determinar dónde entrega el texto el sintetizador de voz y dónde está la persona. Determinar la diferencia es casi imposible.
A pesar de décadas de investigación, la síntesis del habla sigue siendo una tarea urgente para la comunidad científica. En los últimos años, han prevalecido diferentes técnicas en esta área: la síntesis concatenativa con la elección de fragmentos recientemente se ha considerado la más avanzada: el proceso de combinar pequeños fragmentos de sonido pregrabados, así como la síntesis estadística paramétrica del habla, en la que el vocoder sintetizó rutas de pronunciación suaves. El segundo método resolvió muchos problemas de síntesis concatenativa con artefactos en los límites entre fragmentos. Sin embargo, en ambos casos, el sonido sintetizado sonaba arrastrado y poco natural en comparación con el habla humana.
Luego vino el motor de sonido WaveNet (un modelo generativo de formas de onda en el dominio del tiempo), que por primera vez pudo mostrar una calidad de sonido comparable a la humana. Ahora se usa en el sistema de síntesis de
voz Deep Voice 3 .
A principios de 2017, Google presentó la
arquitectura de oferta a oferta de
Tacotron . Genera espectrogramas de amplitudes a partir de una secuencia de caracteres. Tacotron simplifica el transportador de motor de audio tradicional. Aquí, las características lingüísticas y acústicas son generadas por una única red neuronal entrenada solo en datos. La frase "oración a oración" significa que la red neuronal establece una correspondencia entre una secuencia de letras y una secuencia de atributos para codificar el sonido. Los signos se generan en un espectrograma de audio de 80 dimensiones con cuadros de 12,5 milisegundos.
La red neuronal aprende no solo la pronunciación de las palabras, sino también características específicas de la voz, como el volumen, la velocidad y la entonación.
Luego, las ondas de sonido se generan directamente utilizando el algoritmo Griffin-Lim (para la estimación de fase) y la transformada inversa de Fourier a corto plazo. Como señalaron los autores, esta fue una solución temporal para demostrar las capacidades de la red neuronal. De hecho, el motor WaveNet y similares crean un sonido mejor que el algoritmo Griffin-Lim, y sin artefactos.
En el sistema Tacotron 2 modificado, los especialistas de Google todavía conectaban el vocoder WaveNet a la red neuronal. Por lo tanto, la red neuronal crea espectrogramas, y luego una versión modificada de WaveNet genera sonido a 24 kHz.
La red neuronal aprende independientemente (de extremo a extremo) sobre el sonido de una voz humana, que se acompaña de texto. Una red neuronal bien entrenada lee los textos de tal manera que es casi imposible distinguirlos del sonido del habla humana, como se puede ver en
ejemplos reales .
Los investigadores señalan que el sistema Deep Voice 3 utiliza un enfoque similar, pero la calidad de su síntesis aún no se puede comparar con el habla humana. Pero Tacotron 2 sí puede ver los resultados de la prueba de Puntuación de Opinión Media (MOS) en la tabla.
Hay otro sintetizador de voz que también funciona en una red neuronal: este es
Char2Wav , pero tiene una arquitectura completamente diferente.
Los científicos dicen que, en general, la red neuronal funciona bien, pero aún tiene dificultades para pronunciar algunas palabras complejas (como
decoro o
merlot ). Y a veces produce ruidos extraños al azar; las razones de esto ahora se están aclarando. Además, el sistema no puede funcionar en tiempo real, y los autores aún no han podido tomar el control del motor, es decir, establecer la entonación deseada, por ejemplo, una voz feliz o triste. Cada uno de estos problemas es interesante en sí mismo, escriben.
El artículo científico fue
publicado el 16 de diciembre de 2017 en el sitio de preimpresión arXiv.org (arXiv: 1712.05884v1).