
Nuestro día comienza con la frase "¡Buenos días!". Durante el día hablamos con colegas, parientes, amigos e incluso extraños que solicitan indicaciones para llegar al metro más cercano. Hablamos incluso cuando no hay nadie a nuestro alrededor para percibir mejor nuestro propio razonamiento. Todo esto es nuestro discurso, un regalo que es verdaderamente incomparable con muchas otras posibilidades del cuerpo humano. El habla nos permite establecer conexiones sociales, expresar pensamientos y emociones, expresarnos, por ejemplo, en canciones.
Y así, los autos inteligentes aparecieron en la vida de las personas. Una persona, ya sea por curiosidad o por sed de nuevos logros, está tratando de enseñarle a la máquina a hablar. Pero para hablar, necesitas escuchar y escuchar. Hoy en día es difícil sorprender con un programa (por ejemplo, Siri) que puede reconocer el habla, encontrar un restaurante en el mapa, llamar a mamá e incluso contar un chiste. Ella entiende mucho, no todo, por supuesto, pero mucho. Pero no siempre fue así, naturalmente. Hace décadas, era por felicidad, cuando una máquina podía entender al menos una docena de palabras.
Hoy nos sumergiremos en la historia de cómo la humanidad pudo hablar con la máquina, los avances a lo largo de los siglos en esta área han servido como impulso para el desarrollo de la tecnología de reconocimiento de voz. También observamos cómo los dispositivos modernos perciben y procesan nuestras voces. Vamos
Los orígenes del reconocimiento de voz.
¿Qué es el habla? En términos generales, esto es sonido. Entonces, para reconocer el habla, primero debe reconocer el sonido y grabarlo.
Ahora tenemos iPods, reproductores de MP3, antes había grabadoras de cinta, incluso gramófonos y gramófonos anteriores. Todos estos son dispositivos para reproducir sonidos. ¿Pero quién fue el progenitor de todos ellos?
 Thomas Edison con su invento. Año 1878
Thomas Edison con su invento. Año 1878Era un fonógrafo. El 29 de noviembre de 1877, el gran inventor Thomas Edison demostró su nueva creación, capaz de grabar y reproducir sonidos. Fue un avance que despertó el mayor interés de la sociedad.
El principio del fonógrafo.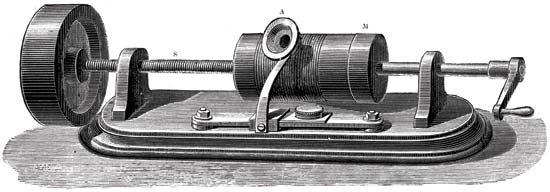
Las partes principales del mecanismo de grabación de sonido eran un cilindro recubierto de aluminio y una aguja de corte. La aguja se movió a lo largo de un cilindro que giraba. Y las vibraciones mecánicas fueron capturadas usando una membrana de micrófono. Como resultado, la aguja dejó marcas en la lámina. Como resultado, recibimos un cilindro con un registro. Para reproducirlo, se utilizó inicialmente el mismo cilindro que al grabar. Pero el papel de aluminio era demasiado frágil y se desgastaba rápidamente, porque los registros fueron de corta duración. Luego comenzaron a aplicar cera, que cubría el cilindro. Para prolongar la existencia de los registros, comenzaron a copiar utilizando galvanoplastia. Mediante el uso de materiales más duros, las copias duraron mucho más.
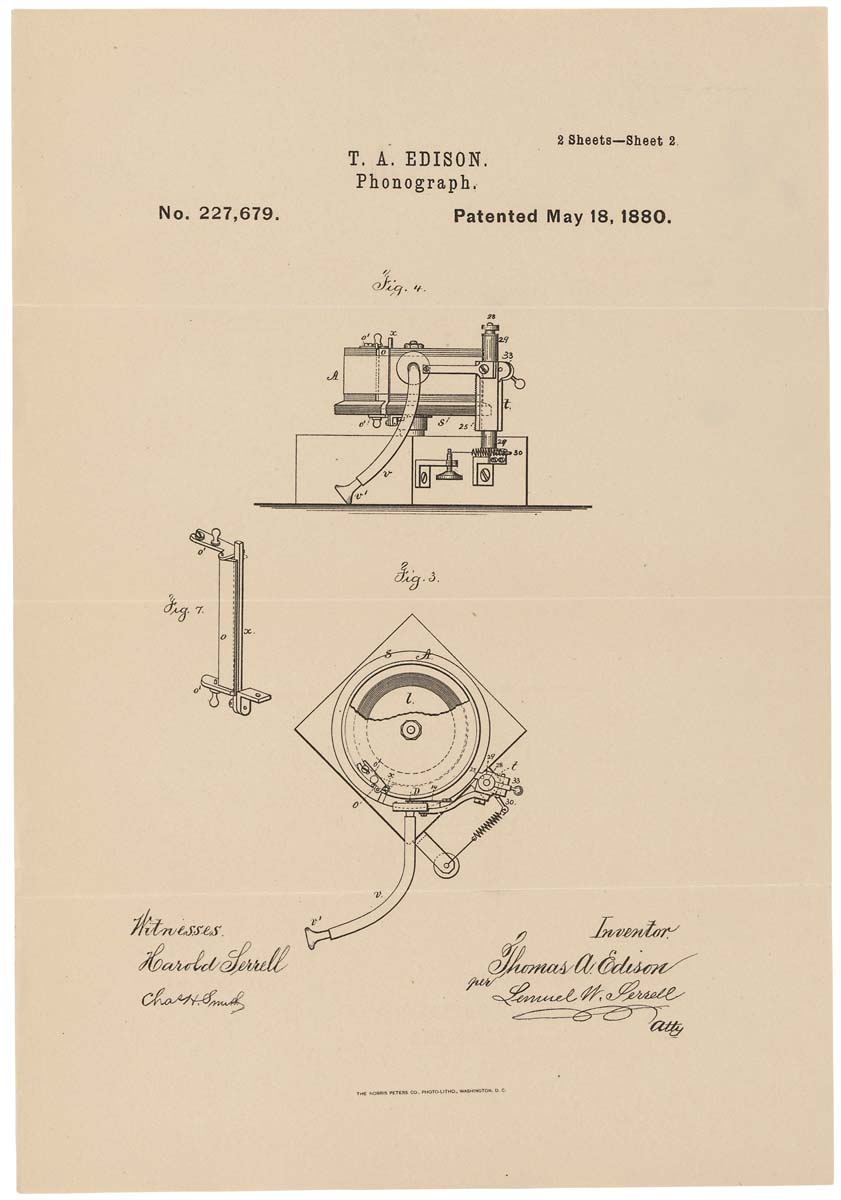 Ilustración esquemática de un fonógrafo en una patente. 1880, 18 de mayo
Ilustración esquemática de un fonógrafo en una patente. 1880, 18 de mayoTeniendo en cuenta los inconvenientes anteriores, el fonógrafo, aunque era una máquina interesante, pero no fue barrido de los estantes. Solo con el advenimiento del fonógrafo de disco, mejor conocido como el gramófono, llegó el reconocimiento público. La novedad permitió hacer grabaciones más largas (el primer fonógrafo solo pudo grabar un par de minutos), lo que sirvió durante mucho tiempo. Y el gramófono en sí estaba equipado con un altavoz que aumentaba el volumen de reproducción.
Thomas Edison originalmente concibió el fonógrafo como un dispositivo para grabar conversaciones telefónicas, como las grabadoras de voz modernas. Sin embargo, su creación ha ganado gran popularidad en la reproducción de obras musicales. Habiendo servido como el comienzo para la formación de la industria discográfica.
Discurso "órgano"
Bell Labs es famoso por sus inventos en el campo de las telecomunicaciones. Uno de esos inventos fue Voder.
En 1928, Homer Dudley comenzó a trabajar en un vocoder, un dispositivo capaz de sintetizar el habla. Hablaremos de él más tarde. Ahora consideraremos su parte: el vader.
 Ilustración esquemática de un vader
Ilustración esquemática de un vaderEl principio básico del vader era dividir el habla humana en componentes acústicos. La máquina era extremadamente compleja y solo un operador capacitado podía operarla.
Vader imitó los efectos del tracto vocal humano. Hubo 2 sonidos principales que el operador podía elegir con su muñeca. Los pedales se utilizaron para controlar el generador de oscilaciones discontinuas (zumbidos), que crearon vocales sonoras y sonidos nasales. Un tubo de descarga de gas (silbido) creó sibilantes (consonantes fricativas). Todos estos sonidos pasaron por uno de los 10 filtros, que fue seleccionado con las teclas. También había teclas especiales para sonidos como "p" o "d", y para los africanos "j" en la palabra "mandíbula" y "ch" en la palabra "queso".
Este pequeño extracto de la presentación del vader demuestra claramente el principio de su funcionamiento y las acciones del operador.Un operador podría producir un discurso válido reconocible solo después de varios meses de dura práctica y entrenamiento.
Por primera vez, el transportista se demostró en una exposición en Nueva York en 1939.
Guardar mediante síntesis de voz
Ahora considere un vocoder, parte del cual fue el controlador mencionado anteriormente.
 Uno de los modelos de vocoder: HY-2 (1961)
Uno de los modelos de vocoder: HY-2 (1961)Originalmente, el vocoder tenía la intención de guardar los recursos de frecuencia de los enlaces de radio al transmitir mensajes de voz. En lugar de la voz en sí, se transmitieron los valores de sus parámetros específicos, que fueron procesados por el sintetizador de voz en la salida.
La base del vocoder eran tres propiedades principales:
- generador de ruido (sonidos consonantes);
- generador de tonos (vocales);
- filtros formales (recreando las características individuales del hablante).
A pesar de su propósito serio, el vocoder atrajo la atención de los músicos electrónicos. La conversión de la señal fuente y su reproducción en otro dispositivo permitió lograr una variedad de efectos, como el efecto de un instrumento musical que canta con una "voz humana".
Máquina de conteo
En 1952, las tecnologías no eran tan avanzadas como ahora. Pero esto no impidió que los científicos entusiastas se establecieran tareas imposibles, según muchos. Entonces, caballeros Stephen Balashek (S. Balashek), Ralon Biddulf (R. Biddulph) y K.Kh. Davis (KH Davis) decidió enseñarle a la máquina a entender su discurso. Siguiendo la idea, el auto de Audrey nació. Sus capacidades eran muy limitadas: solo podía reconocer números del 0 al 9. Pero esto ya era suficiente para declarar con seguridad un avance en la tecnología informática.
 Audrey con uno de sus creadores (según Internet, corrígeme si no es así)
Audrey con uno de sus creadores (según Internet, corrígeme si no es así)A pesar de sus pequeñas capacidades, Audrey no podía presumir de las mismas dimensiones. Era una "niña" bastante grande: el gabinete de retransmisión tenía casi 2 metros de altura y todos los elementos ocupaban una pequeña habitación. Lo cual no es sorprendente para las computadoras de esa época.
El procedimiento de interacción entre el operador y Audrey también tenía algunas condiciones. El operador pronunció las palabras (números, en este caso) en el auricular de un teléfono normal, asegúrese de soportar una pausa de 350 milisegundos entre cada palabra. Audrey aceptó la información, la tradujo a formato electrónico y encendió una bombilla específica correspondiente a un dígito en particular. Sin mencionar el hecho de que no todos los operadores pueden obtener una respuesta exacta. Para lograr una precisión del 97%, el operador tenía que ser una persona que había practicado "charlar" con Audrey durante mucho tiempo. En otras palabras, Audrey entendía solo a sus creadores.
Incluso teniendo en cuenta todas las deficiencias de Audrey, que no están asociadas con errores de diseño, sino con las limitaciones de la tecnología de aquellos tiempos, se convirtió en la primera estrella en el horizonte de máquinas que entienden la voz humana.
El futuro en la caja de zapatos.
En 1961, en el Laboratorio de Desarrollo de Sistemas Avanzados de IBM, se desarrolló un nuevo dispositivo milagroso: el Shoebox, que puede reconocer 16 palabras (en inglés exclusivamente) y números del 0 al 9. El autor de esta computadora fue William C. Dersch.
 Caja de zapatos de IBM
Caja de zapatos de IBMEl nombre inusual correspondía a la apariencia de la máquina, tenía el tamaño y la forma de una caja de zapatos. Lo único que me llamó la atención fue el micrófono, que estaba conectado a los tres filtros de audio necesarios para reconocer los sonidos altos, medios y bajos. Los filtros se conectaron a un decodificador lógico (circuito lógico diodo-transistor) y a un mecanismo de interruptor de luz.
El operador se llevó el micrófono a la boca y pronunció una palabra (por ejemplo, el número 7). La máquina convirtió datos acústicos en señales electrónicas. El resultado de la comprensión fue la inclusión de una bombilla con la firma "7". Además de comprender palabras individuales, Shoebox podría entender problemas aritméticos simples (como 5 + 6 o 7-3) y dar la respuesta correcta.
Shoebox fue presentado por su creador en 1962 en la Seattle World Expo.
Conversación telefónica con el coche
En 1971, IBM, conocida por su amor por las invenciones y tecnologías innovadoras, decidió poner en práctica el reconocimiento de voz. El sistema de identificación automática de llamadas permitió a un ingeniero ubicado en cualquier lugar de los Estados Unidos llamar a una computadora en Raleigh, Carolina del Norte. La persona que llama puede hacer una pregunta y recibir una respuesta de voz. La singularidad de este sistema radica en la comprensión de las muchas voces, dada su tonalidad, énfasis, volumen de voz, etc.
Arpía volando alto
La Oficina de Proyectos de Investigación Avanzada del Departamento de Defensa (DARPA para abreviar) anunció el lanzamiento de un programa de investigación y desarrollo de reconocimiento de voz en 1971 que tiene como objetivo crear una máquina que pueda reconocer 1,000 palabras. Un proyecto audaz, dados los éxitos de su predecesor, en decenas de palabras. Pero no hay límite para el ingenio humano. Y en 1976, la Universidad Carnegie Mellon demuestra a Harpy, capaz de reconocer 1011 palabras.
Video demostración de HarpyLa universidad ya ha desarrollado sistemas de reconocimiento de voz: Hearsay-1 y Dragon. Se utilizaron como base para implementar Harpy.
En Hearsay-1, el conocimiento (es decir, un diccionario de máquina) se representa en forma de procedimientos, y en Dragon, en forma de una red de Markov con una transición probabilística a priori. En Harpy, se decidió usar el último modelo, pero sin esta transición.
En este video, el principio de funcionamiento se describe con más detalle.
En pocas palabras, puede representar una red: una secuencia de palabras y sus combinaciones, así como sonidos con una sola palabra, para que la máquina entienda la pronunciación diferente de la misma palabra.
Harpy entendió a 5 operadores, incluidos tres hombres y dos mujeres. Eso habló sobre las mayores capacidades informáticas de esta máquina. La precisión del reconocimiento de voz fue aproximadamente del 95%.
Tangora de IBM
A principios de la década de 1980, IBM decidió desarrollar un sistema capaz de reconocer más de 20,000 palabras a mediados de la década. Así nació Tangora, en cuyo trabajo se usaron modelos ocultos de Markov. A pesar del vocabulario bastante impresionante, el sistema no requirió más de 20 minutos de colaboración con el nuevo operador (la persona que habla) para aprender a reconocer su discurso.
Muñeca viviente
En 1987, la compañía de juguetes Worlds of Wonder lanzó una novedad revolucionaria: una muñeca parlante llamada Julie. La característica más impresionante del juguete danés fue la capacidad de entrenarlo para reconocer el discurso del propietario. Julie podía hablar bastante bien. Además, la muñeca estaba equipada con muchos sensores, gracias a los cuales reaccionó cuando la recogieron, le hicieron cosquillas o la transfirieron de una habitación oscura a una brillante.
El comercial de Worlds of Wonder, Julie, presenta sus característicasSus ojos y labios eran móviles, lo que creaba una imagen aún más viva. Además de la muñeca en sí, fue posible comprar un libro en el que se hicieron dibujos y palabras en forma de pegatinas especiales. Si sostienes las muñecas con los dedos sobre ellas, emitirá lo que "siente" al tacto. Doll Julie fue el primer dispositivo con una función de reconocimiento de voz, que estaba disponible para cualquiera.
El primer software de dictado.

En 1990, Dragon Systems lanzó el primer software de computadora personal basado en el reconocimiento de voz: DragonDictate. El programa funcionó exclusivamente en Windows. El usuario tuvo que hacer pequeñas pausas entre cada palabra para que el programa pudiera analizarlas. En el futuro, apareció una versión más avanzada que le permite hablar continuamente: Dragon NaturallySpeaking (es lo que está disponible ahora, mientras que DragonDictate original ha dejado de actualizarse desde Windows 98). A pesar de su "lentitud", DragonDictate ha ganado gran popularidad entre los usuarios de PC, especialmente entre las personas con discapacidad.
Esfinge no egipcia
La Universidad Carnegie Mellon, que ya se ha "iluminado" anteriormente, se ha convertido en el lugar de nacimiento de otro sistema de reconocimiento de voz históricamente importante: Sphinx 2.
 Creador de la esfinge Xuedong Huang
Creador de la esfinge Xuedong HuangEl autor directo del sistema fue Xuedong Huang. Sphinx 2 se distinguió de su predecesor por su velocidad. El sistema se centró en el reconocimiento de voz en tiempo real para programas que usan lenguaje hablado (todos los días). Entre las características de Sphinx 2 estaban: formación de hipótesis, cambio dinámico entre modelos de lenguaje, detección de equivalentes, etc.
El código Sphinx 2 se ha utilizado en muchos productos comerciales. Y en 2000, en el sitio web de SourceForge, Kevin Lenzo publicó el código fuente del sistema para su visualización general. Aquellos que deseen estudiar el código fuente de Sphinx 2 y sus otras variaciones pueden seguir el
enlace .
Dictado médico
En 1996, IBM lanzó MedSpeak, el primer producto comercial con reconocimiento de voz. Se suponía que debía usar este programa en médicos para compilar registros médicos. Por ejemplo, un radiólogo, al examinar las imágenes de la paciente, expresó sus comentarios, que el sistema MedSpeak tradujo al texto.
Antes de pasar a los representantes más famosos de programas con reconocimiento de voz, echemos un vistazo rápido y breve a algunos eventos históricos más relacionados con esta tecnología.
Bombardeo histórico
- 2002: Microsoft integra el reconocimiento de voz en todos sus productos de Office;
- 2006 - La Agencia de Seguridad Nacional de EE. UU. Comienza a utilizar programas de reconocimiento de voz para identificar palabras clave limitadas en los registros de conversación;
- 2007 (30 de enero): Microsoft lanza Windows Vista, el primer sistema operativo con reconocimiento de voz;
- 2007 - Google presenta GOOG-411, un sistema de reenvío telefónico (una persona llama a un número, dice qué organización o persona necesita y el sistema los conecta). El sistema funcionó dentro de los Estados Unidos y Canadá;
- 2008 (14 de noviembre): Google lanza la búsqueda por voz en dispositivos móviles iPhone. Este fue el primer uso de la tecnología de reconocimiento de voz en teléfonos móviles;
Y ahora llegamos al período de tiempo en que mucha gente se encontró con la tecnología de reconocimiento de voz.
Las damas no pelean
El 4 de octubre de 2011, Apple anunció Siri, cuya decodificación del nombre habla por sí sola: la interfaz de interpretación y reconocimiento de voz (es decir, la interfaz de interpretación y reconocimiento de voz).

La historia del desarrollo de Siri es muy larga (de hecho, tiene 40 años de trabajo) e interesante. El hecho mismo de su existencia y su amplia funcionalidad es el trabajo conjunto de muchas empresas y universidades. Sin embargo, no nos centraremos en este producto, porque el artículo no trata sobre Siri, sino sobre el reconocimiento de voz en general.
Microsoft no quería robar la espalda, porque en 2014 (2 de abril) anunciaron su asistente digital virtual Cortana.

La funcionalidad de Cortana es similar a la de su competidor Siri, con la excepción de un sistema más flexible para configurar el acceso a la información.
Debate sobre Cortana o Siri. ¿Quién es mejor? realizado desde su aparición en el mercado. Como, en general, y la lucha entre usuarios de iOS y Android. Pero eso es bueno. Los productos de la competencia, en un intento de parecer mejores que sus rivales, proporcionarán más y más nuevas oportunidades, desarrollarán y utilizarán tecnologías y técnicas más avanzadas en la misma esfera de reconocimiento de voz. Con solo un representante en cualquier campo de la tecnología de consumo, no hay necesidad de hablar sobre su rápido desarrollo.
Un pequeño video divertido de la conversación entre Siri y Cortana (obviamente construido, pero no menos divertido). ¡Atención! En este video hay blasfemias.
Conversación con autos. ¿Cómo nos entienden?
Como mencioné anteriormente, en términos generales, el habla es sonido. ¿Y cuál es el sonido para el auto? Estos son cambios (fluctuaciones) en la presión del aire, es decir ondas de sonido Para que la máquina (computadora o teléfono) pueda reconocer el habla, primero debe considerar estas fluctuaciones. La frecuencia de medición debe ser de al menos 8,000 veces por segundo (incluso mejor - 44,100 veces por segundo). Si las mediciones se llevan a cabo con grandes interrupciones de tiempo, obtendremos un sonido inexacto, lo que significa un discurso ilegible. El proceso descrito anteriormente se denomina digitalización de 8 kHz o 44,1 kHz.
Cuando se recopilan datos sobre las vibraciones de las ondas de sonido, deben clasificarse. Dado que en el montón general tenemos tanto el habla como los sonidos secundarios (ruido de la máquina, crujir de papel, el sonido de una computadora en funcionamiento, etc.). La realización de operaciones matemáticas nos permite eliminar con precisión nuestro discurso, que necesita reconocimiento.
El siguiente es el análisis de la onda de sonido seleccionada: el habla. Dado que consta de muchos componentes separados que forman ciertos sonidos (por ejemplo, "ah" o "ee"). Destacar estas características y convertirlas en equivalentes numéricos le permite definir palabras específicas.
, , 40 (44, , 100), .. . , , . . , , «» , ( , , , ..), . , «t» «sTar» «t» «ciTy» -.
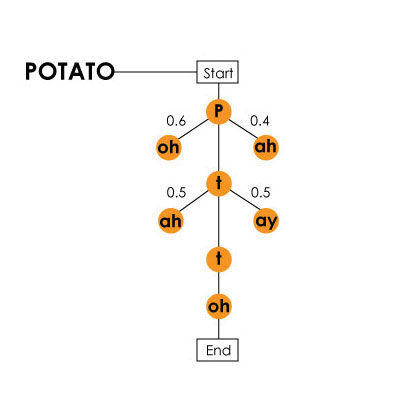 «potato» () / Harpy
«potato» () / Harpy, , . , «hang ten», — «hey, ngten», «ngten».
, , . , (), , №2 №1. «What do cats like for breakfast?» «water gaslight four brick vast?». , . . , , , . .
, . , , .
, . . - , ( , ), . . , , , . , -, , .
. 25% 3 6 !
! VPS (KVM) , , — !
VPS (KVM) c ( VPS (KVM) — E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD 4TB HDD / 1Gbps 10TB — $29 / , RAID1 RAID10) , , , , , «»!
. c Dell R730xd 5-2650 v4 9000 ? Dell R730xd 2 ? 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los EE. UU.