
Durante la última década, las redes neuronales profundas (DNN) se han convertido en una excelente herramienta para una serie de tareas de inteligencia artificial como la clasificación de imágenes, el reconocimiento de voz e incluso la participación en juegos. Cuando los desarrolladores intentaron mostrar qué causó el éxito de DNN en el campo de la clasificación de imágenes, y crearon herramientas de visualización (por ejemplo, Deep Dream, Filters) que ayudan a comprender "qué" exactamente "estudia" el modelo DNN, surgió una nueva aplicación interesante : extraer "estilo" de una imagen y aplicar a otro contenido diferente. Esto se ha denominado la "transferencia de estilo de imagen".
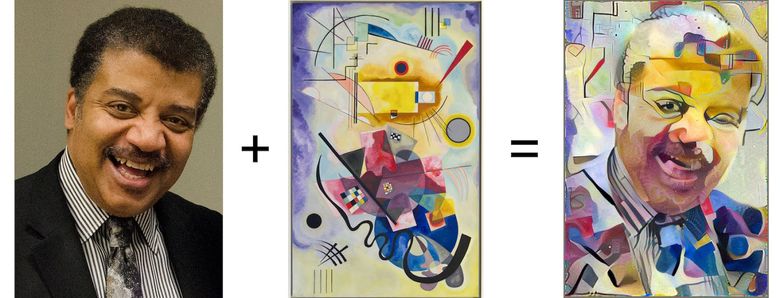
Izquierda: imagen con contenido útil, en el centro: imagen con estilo, derecha: contenido + estilo (fuente: Google Research Blog )
Esto no solo despertó el interés de muchos otros investigadores (por ejemplo, 1 y 2 ), sino que también llevó a la aparición de varias aplicaciones móviles exitosas. En los últimos años, estos métodos de transferencia de estilo visual han mejorado mucho.

Adobe estilo de envoltura (fuente: Engadget )

Ejemplo del sitio web de Prisma
Una breve introducción a tales algoritmos:
Sin embargo, a pesar de los avances en el trabajo con imágenes, la aplicación de estas técnicas en otras áreas, por ejemplo, para procesar música, fue muy limitada (ver 3 y 4 ), y los resultados no son tan impresionantes como en el caso de las imágenes. Esto sugiere que es mucho más difícil transferir estilo en la música. En este artículo, examinaremos el problema con más detalle y discutiremos algunos enfoques posibles.
¿Por qué es tan difícil transferir estilo en la música?
Primero respondamos la pregunta: ¿qué es la "transferencia de estilo" en la música ? La respuesta no es tan obvia. En imágenes, los conceptos de "contenido" y "estilo" son intuitivos. "Contenido de imagen" describe los objetos representados, por ejemplo, perros, casas, caras, etc., y "estilo de imagen" se refiere a colores, iluminación, pinceladas y textura.
Sin embargo, la música es semánticamente abstracta y de naturaleza multidimensional . "Contenido musical" puede significar diferentes cosas en diferentes contextos. A menudo, los contenidos de la música están asociados con una melodía y el estilo con un arreglo o armonización. Sin embargo, el contenido puede ser la letra, y las diferentes melodías utilizadas para cantar se pueden interpretar como estilos diferentes. En la música clásica, el contenido puede considerarse la partitura (que incluye la armonización), mientras que el estilo es la interpretación de las notas por parte del intérprete, quien aporta su propia expresión (variando y agregando algunos sonidos de sí mismo). Para comprender mejor la esencia de la transferencia de estilo en la música, mira algunos de estos videos:
En el segundo video, se utilizan varias técnicas de aprendizaje automático.
Entonces, la transferencia de estilo en la música es, por definición, difícil de formalizar. Hay otros factores clave que complican la tarea:
- Las máquinas MAL entienden la música (por ahora): el éxito en la transferencia de estilo en las imágenes se deriva del éxito de DNN en tareas relacionadas con la comprensión de imágenes, como el reconocimiento de objetos. Debido a que los DNN pueden aprender propiedades que varían entre los objetos, las técnicas de propagación hacia atrás se pueden usar para modificar la imagen de destino para que coincida con las propiedades del contenido. Aunque hemos logrado un progreso significativo en la creación de modelos basados en DNN que son capaces de comprender tareas musicales (por ejemplo, transcribir melodías, definir un género, etc.), todavía estamos lejos de las alturas alcanzadas en el procesamiento de imágenes. Este es un serio obstáculo para la transferencia de estilo en la música. Los modelos existentes simplemente no pueden aprender las propiedades "excelentes" que permiten clasificar la música, lo que significa que la aplicación directa de los algoritmos de transferencia de estilo utilizados al trabajar con imágenes no da el mismo resultado.
- La música es fugaz : son datos que representan series dinámicas, es decir, un fragmento musical cambia con el tiempo. Esto complica el aprendizaje. Aunque las redes neuronales recurrentes y la LSTM (memoria a corto plazo) le permiten aprender más de los datos transitorios, todavía tenemos que crear modelos confiables que puedan aprender a reproducir la estructura musical a largo plazo (nota: esta es un área real de investigación, y los científicos del equipo de Google Magenta ha logrado cierto éxito en esto ).
- La música es discreta (al menos a nivel simbólico): la música simbólica o grabada en papel es de naturaleza discreta. En el temperamento uniforme , el sistema de afinación de instrumentos musicales más popular en la actualidad, los tonos de sonido ocupan posiciones discretas en una escala de frecuencia continua. Al mismo tiempo, la duración de los tonos también se encuentra en un espacio discreto (generalmente cuartos de tono, tonos completos, etc.). Por lo tanto, es muy difícil adaptar los métodos de propagación posterior de píxeles (utilizados para trabajar con imágenes) en el campo de la música simbólica.
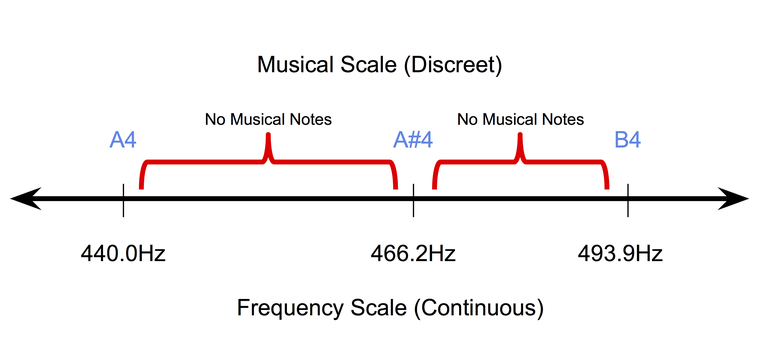
La naturaleza discreta de las notas musicales en un temperamento uniforme.
Por lo tanto, las técnicas utilizadas para transferir estilo en imágenes no son directamente aplicables a la música. Para hacer esto, necesitan ser procesados con énfasis en conceptos e ideas musicales.
¿Para qué sirve la transferencia de estilo en la música?
¿Por qué necesitas resolver este problema? Al igual que con las imágenes, los usos potenciales de la transferencia de estilo en la música son bastante interesantes. Por ejemplo, desarrollar una herramienta para ayudar a los compositores . Por ejemplo, un instrumento automático capaz de transformar una melodía usando arreglos de diferentes géneros será extremadamente útil para los compositores que necesitan probar rápidamente diferentes ideas. Los DJ también estarán interesados en tales instrumentos.
Un resultado indirecto de tal investigación será una mejora significativa en los sistemas informáticos musicales. Como se explicó anteriormente, para la transferencia del estilo al trabajo en la música, los modelos que creamos deben aprender a "comprender" mejor los diferentes aspectos.
Simplifica la tarea de transferir estilo en la música
Comencemos con una tarea muy simple de analizar melodías monofónicas en diferentes géneros. Las melodías monofónicas son secuencias de notas, cada una de las cuales está determinada por el tono y la duración. La progresión del tono en su mayor parte depende de la escala de la melodía, y la progresión de la duración depende del ritmo. Primero, separamos claramente " contenido de tono" y "estilo rítmico" como dos entidades con las que puede reformular la tarea de transferir el estilo. Además, al trabajar con melodías monofónicas, ahora evitaremos las tareas asociadas con la disposición y el texto.
En ausencia de modelos pre-entrenados que puedan distinguir con éxito entre progresiones de tono y ritmos de melodías monofónicas, primero recurrimos a un enfoque muy simple para transferir el estilo. En lugar de tratar de cambiar el contenido del tono aprendido en la melodía objetivo con el estilo rítmico aprendido en el ritmo objetivo, intentaremos enseñar individualmente los patrones de tonos y duraciones de diferentes géneros, y luego intentaremos combinarlos. Esquema aproximado del enfoque:
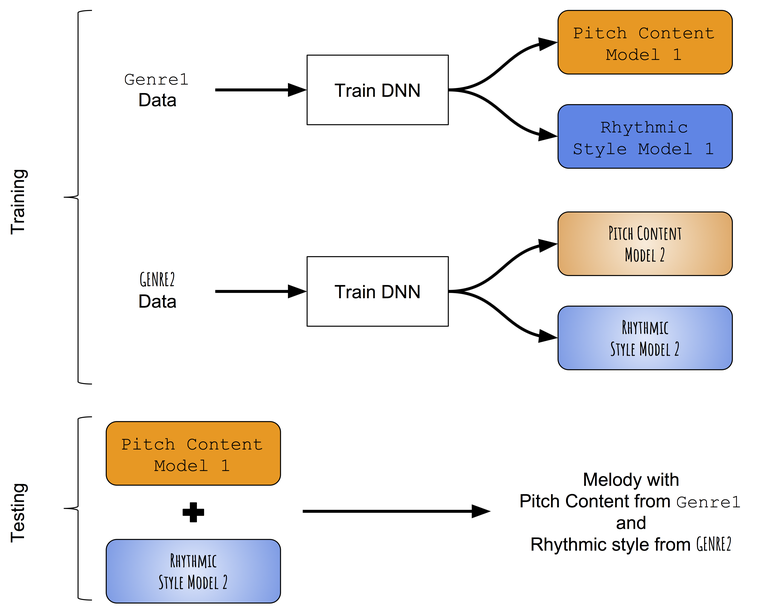
Esquema del método de transferencia de estilo intergénero.
Enseñamos progresiones de tono y ritmo por separado.
Presentación de datos.
Presentaremos melodías monofónicas como una secuencia de notas musicales, cada una de las cuales tiene un índice de tono y una secuencia. Para que nuestra clave de presentación sea independiente, utilizaremos la presentación en función de los intervalos: el tono de la siguiente nota se presentará como una desviación (± semitono) del tono de la nota anterior. Creemos dos diccionarios para tonos y duraciones en los que a cada estado discreto (para tono: +1, -1, +2, -2, y así sucesivamente; para duraciones: una nota negra, una nota completa, un cuarto con un punto, etc.) se le asigna un índice diccionario
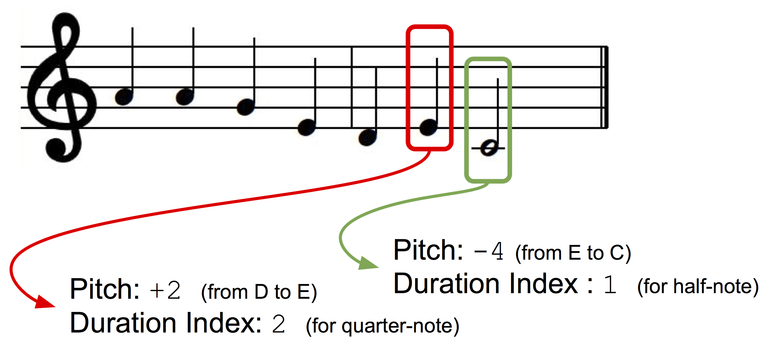
Presentación de datos.
Arquitectura modelo
Utilizaremos la misma arquitectura que utilizaban Colombo y sus colegas : enseñaron simultáneamente dos redes neuronales LSTM al mismo género musical: a) la red de tonos aprendió a predecir el siguiente tono en función de la nota anterior y la duración anterior, b) la red de duración aprendió a predecir la próxima duración en función de la siguiente nota y duración previa. Además, antes de las redes LSTM, agregaremos capas de incrustación para comparar índices de tonos de entrada y duraciones en espacios de inserción memorizados. La arquitectura de la red neuronal se muestra en la imagen:
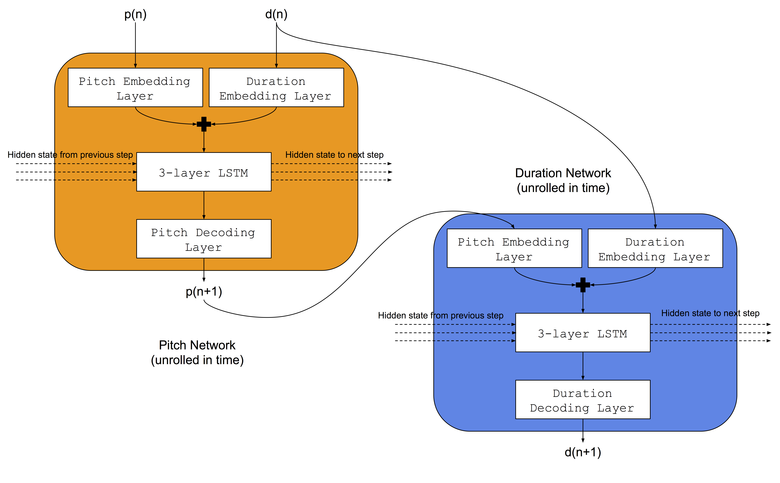
Procedimiento de entrenamiento
Para cada género, las redes responsables de tonos y duraciones se entrenan al mismo tiempo. Utilizaremos dos conjuntos de datos: a) Conjunto de datos folklóricos de Norbeck , que abarca alrededor de 2.000 melodías populares irlandesas y suecas, b) un conjunto de datos de jazz (no disponible públicamente), que abarca alrededor de 500 melodías de jazz.
Fusionar modelos entrenados
Durante las pruebas, la melodía se genera primero utilizando la red de tonos y la red de duración entrenada en el primer género (por ejemplo, folk). Luego, la secuencia de tonos de la melodía generada se usa en la entrada para una red de secuencias entrenadas en otro género (digamos, jazz), y el resultado es una nueva secuencia de duraciones. Por lo tanto, una melodía creada usando una combinación de dos redes neuronales tiene una secuencia de tonos correspondiente al primer género (folk) y una secuencia de duraciones correspondiente al segundo género (jazz).
Resultados preliminares
Extractos breves de algunas de las melodías resultantes:
Tonos populares y duraciones populares

Extracto de notación musical.
Tonos populares y duraciones de jazz

Extracto de notación musical.
Tonos de jazz y secuencias de jazz

Extracto de notación musical .
Tonos de jazz y secuencias folklóricas

Extracto de notación musical.
Conclusión
Aunque el algoritmo actual no es malo para comenzar, tiene una serie de inconvenientes críticos:
- Es imposible "transferir estilo" basado en una melodía de destino específica . Los modelos aprenden patrones de tonos y duraciones en un género, lo que significa que todas las transformaciones están determinadas por el género. Sería ideal modificar una pieza musical al estilo de una canción o pieza objetivo específica.
- No es posible controlar el grado de cambio de estilo. Sería muy interesante obtener un "control" que rija este aspecto.
- Al fusionar géneros, es imposible preservar la estructura musical en una melodía transformada. Una estructura a largo plazo es importante para la evaluación musical en general, y para que las melodías generadas sean musicalmente estéticas, la estructura debe preservarse.
En futuros artículos, veremos formas de sortear estas deficiencias.