Ejemplo de operación de AttnGAN. En la fila superior hay varias imágenes de diferentes resoluciones generadas por una red neuronal. La segunda y tercera fila muestran el procesamiento de las cinco palabras más adecuadas por dos modelos de atención de la red neuronal para dibujar las secciones más relevantes.La creación automática de imágenes a partir de descripciones de texto en un lenguaje natural es un problema fundamental para muchas aplicaciones, como la generación de arte y el diseño de computadoras. Este problema también estimula el progreso en el campo del entrenamiento multimodal de IA con una relación entre visión y lenguaje.
Investigaciones recientes de investigadores en esta área se basan en redes de confrontación generativa (GAN). El enfoque general es traducir la descripción del texto completo al vector de oración global. Este enfoque demuestra una serie de resultados impresionantes, pero tiene las principales desventajas: la falta de detalles claros a nivel de palabra y la incapacidad para generar imágenes de alta resolución. Un equipo de desarrolladores de la Universidad de Lichai, la Universidad de Rutgers, la Universidad de Duke (todos - EE. UU.) Y Microsoft propusieron su
propia solución al problema: la nueva red neuronal
Attenional Generative Adversarial Network (AttnGAN) representa una mejora en el enfoque tradicional y permite el cambio en varias etapas de la imagen generada, cambiando palabras individuales en el texto descripción.
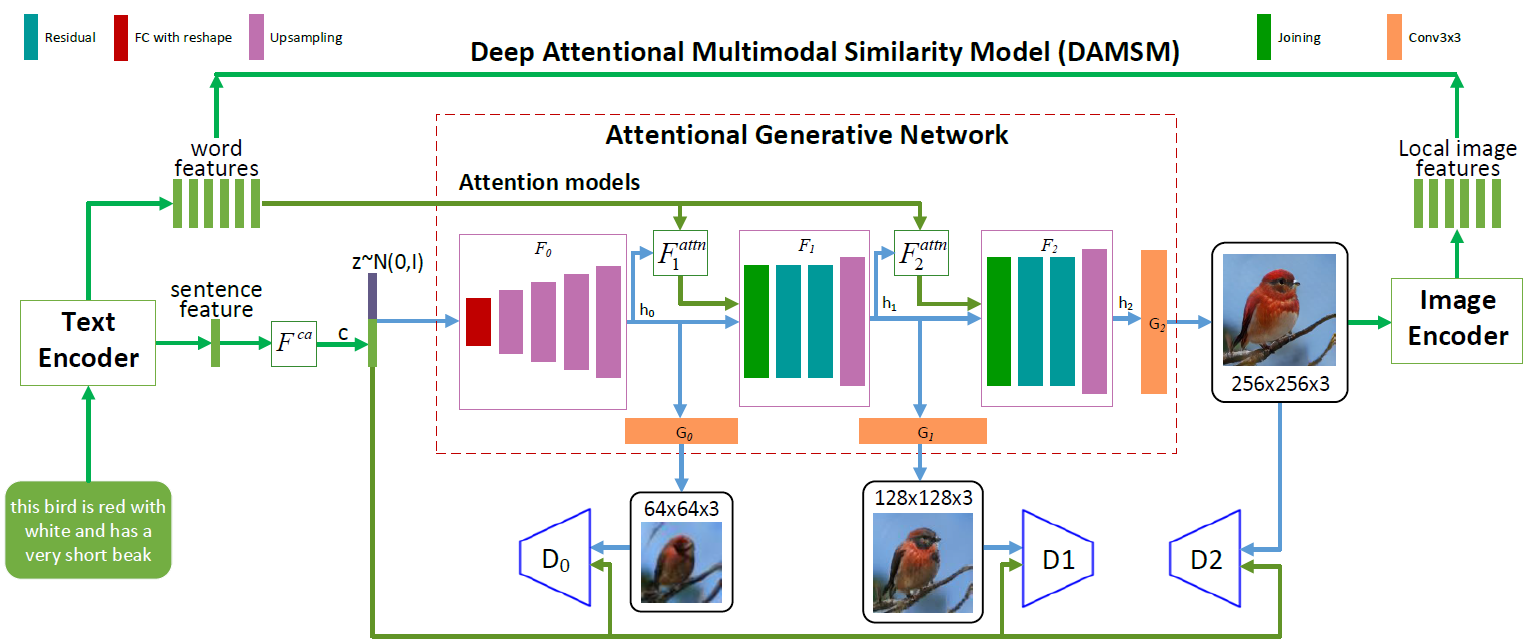 AttnGAN arquitectura de redes neuronales. Cada modelo de atención recibe automáticamente condiciones (es decir, vectores de vocabulario correspondientes) para generar diferentes áreas de la imagen. El módulo DAMSM proporciona granularidad adicional para la función de pérdida de conformidad en la traducción de imagen a texto en la red generativa
AttnGAN arquitectura de redes neuronales. Cada modelo de atención recibe automáticamente condiciones (es decir, vectores de vocabulario correspondientes) para generar diferentes áreas de la imagen. El módulo DAMSM proporciona granularidad adicional para la función de pérdida de conformidad en la traducción de imagen a texto en la red generativaComo puede ver en la ilustración que representa la arquitectura de la red neuronal, el modelo AttnGAN tiene dos innovaciones en comparación con los enfoques tradicionales.
En primer lugar, es una red de confrontación, que se refiere a la atención como un factor de aprendizaje (Red atencional generativa de confrontación). Es decir, implementa el mecanismo de atención, que determina las palabras más adecuadas para generar las partes correspondientes de la imagen. En otras palabras, además de codificar la descripción del texto completo en el espacio vectorial global de las oraciones, cada palabra individual también se codifica como un vector de texto. En la primera etapa, la red neuronal generativa utiliza el espacio vectorial global de las oraciones para representar una imagen de baja resolución. En los siguientes pasos, ella usa el vector de imagen en cada región para consultar los vectores del diccionario, usando la capa de atención para formar el vector de contexto de la palabra. Luego, el vector de imagen regional se combina con el vector de contexto de palabra correspondiente para formar un vector de contexto multimodal, en base al cual el modelo genera nuevas características de imagen en las regiones respectivas. Esto le permite aumentar efectivamente la resolución de toda la imagen como un todo, ya que en cada etapa hay más y más detalles.
La segunda innovación de red neuronal de Microsoft es el módulo Modelo de similitud multimodal de atención profunda (DAMSM). Usando el mecanismo de atención, este módulo calcula el grado de similitud entre la imagen generada y la oración de texto, utilizando tanto la información del nivel del espacio vectorial de las oraciones como un nivel bien detallado de los vectores del diccionario. Por lo tanto, DAMSM proporciona una granularidad adicional para la función de pérdida de ajuste en la traducción de imagen a texto cuando se entrena al generador.
Gracias a estas dos innovaciones, la red neuronal AttnGAN muestra resultados significativamente mejores que los mejores sistemas GAN tradicionales, escriben los desarrolladores. En particular, la puntuación máxima de inicio conocida para las redes neuronales existentes mejoró en un 14.14% (de 3.82 a 4.36) en el conjunto de datos CUB y mejoró hasta en un 170.25% (de 9.58 a 25.89) en el conjunto de datos COCO más sofisticado.
La importancia de este desarrollo es difícil de sobreestimar. La red neuronal AttnGAN por primera vez mostró que una red generativa-adversaria multicapa, que se refiere a la atención como un factor de aprendizaje, puede determinar automáticamente las condiciones de nivel de palabra para generar partes individuales de una imagen.
El artículo científico fue
publicado el 28 de noviembre de 2017 en el sitio de preimpresión arXiv.org (arXiv: 1711.10485v1).