Los desarrolladores de Google Brain han demostrado que las imágenes "en conflicto" pueden contener tanto a una persona como a una computadora; y las posibles consecuencias son aterradoras.
En la imagen de arriba, a la izquierda no hay duda de un gato. Pero, ¿puedes decir con seguridad si el gato está a la derecha o solo un perro que se parece a él? La diferencia entre los dos es que el correcto se hace utilizando un algoritmo especial que no proporciona modelos informáticos llamados "redes neuronales convolucionales" (CNN), que concluye inequívocamente en la imagen. En este caso, el SNS cree que se trata más de un perro que de un gato, pero lo más interesante es que la mayoría de las personas piensan de la misma manera.
Este es un ejemplo de lo que se llama una "imagen contradictoria" (en lo sucesivo, el KARP): se modifica especialmente para engañar al SCN y evitar que el contenido se identifique correctamente. Los investigadores de Google Brain querían entender si es posible hacer que las redes neuronales biológicas funcionen mal en nuestras cabezas de la misma manera y, como resultado, crearon opciones que afectan igualmente a los automóviles y a las personas, haciéndoles pensar que están viendo algo que no realmente
¿Qué son las imágenes en conflicto?
Casi en todas partes, para el reconocimiento en el SCN, se utilizan algoritmos de clasificación visual. Al "mostrar" al programa una gran cantidad de ilustraciones diferentes con pandas, puede entrenarlo para que reconozca a los pandas, ya que aprende en comparación para destacar una característica común para todo el conjunto. Tan pronto como el SNA (también llamado
"clasificadores" ) recolecte una variedad suficiente de "signos de panda" en los datos de entrenamiento, podrá reconocer al panda en cualquier imagen nueva que proporcione.
Reconocemos a los pandas por sus características abstractas: pequeñas orejas negras, grandes cabezas blancas, ojos negros, pelaje y todo ese jazz. El SNA hace lo contrario, lo cual no es sorprendente, ya que la cantidad de información sobre el entorno que las personas interpretan cada minuto es mucho mayor. Por lo tanto, teniendo en cuenta las características específicas de los modelos, es posible influir en las imágenes de manera que sean "inconsistentes" al mezclarlas con datos cuidadosamente calculados, después de lo cual el resultado para una persona se verá casi como el original, pero completamente diferente para el
clasificador , que comenzará a cometer errores al intentar determinar contenidos.
Aquí hay un ejemplo de panda:
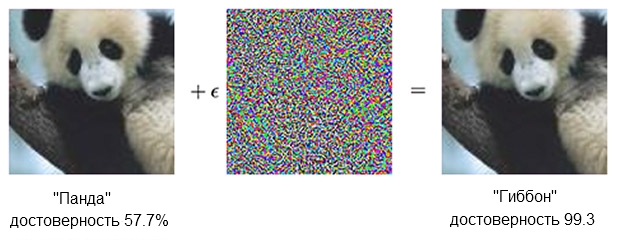 La imagen de un panda, combinada con indignación, puede convencer al clasificador de que en realidad es un gibón.Fuente: OpenAIEl clasificador
La imagen de un panda, combinada con indignación, puede convencer al clasificador de que en realidad es un gibón.Fuente: OpenAIEl clasificador basado en el SNA está seguro de que el panda de la izquierda es aproximadamente del 60%. Pero si complementa ligeramente ("crea indignación") la fuente agregando lo que parece un ruido caótico, el mismo clasificador estará 99.3 por ciento seguro de que ahora está mirando el gibón. Pequeños cambios que ni siquiera se pueden ver claramente dan lugar a un ataque muy exitoso, pero funcionará solo en un modelo de computadora específico y no llevará a cabo aquellos que podrían ser "aprendidos" en otra cosa.
Para crear contenido que provoque la reacción equivocada entre un gran y diverso número de analistas artificiales, uno debe actuar con más rudeza: las pequeñas correcciones no afectarán. Lo que funciona de manera confiable no se podría hacer con "medios pequeños". En otras palabras, si desea que el contenido funcione desde todos los ángulos y distancias, debe intervenir de manera más significativa, o como diría una persona, más obvio.
En la vista - un hombre
Aquí hay dos ejemplos de Carpa grosera, donde una persona puede detectar fácilmente interferencias.
 Fuente: AI abierto a la izquierda, Google Brain a la derecha
Fuente: AI abierto a la izquierda, Google Brain a la derechaLa imagen del gato a la izquierda, que el SNS se define como una computadora, se realizó con "geometría rota". Si observa más de cerca (o incluso no demasiado cerca), verá que hay varias estructuras angulares y en forma de caja que pueden parecerse a la forma de una unidad del sistema. Y la imagen del plátano a la derecha, que se reconoce como una tostadora, constantemente da un falso positivo desde cualquier punto de vista. La gente en este momento encontrará un plátano aquí, sin embargo, un extraño artilugio al lado tiene algunos signos de tostadora, y esto hace que la tecnología sea una tontería.
Cuando crea una imagen "contradictoria" adecuada garantizada que necesita para vencer a toda una compañía de modelos de reconocimiento, a menudo esto lleva a la aparición de un "factor humano". En otras palabras, lo que confunde a una sola red neuronal puede no ser percibido como un problema en absoluto, y cuando intenta obtener un rebus que sea definitivamente adecuado para engañar a cinco o diez a la vez, resulta que funciona sobre la base de mecanismos que, si La gente es completamente inútil.
Como resultado, no hay absolutamente ninguna necesidad de tratar de obligar a una persona a creer que un gato angular es una caja de computadora, y la suma de un plátano y un adorno extraño parece una tostadora. Es mucho mejor cuando se crean CARPs diseñadas para que usted y yo nos centremos inmediatamente en usar modelos que perciban el mundo como lo hacen las personas.
Engañando el ojo (y el cerebro)
El SNA con entrenamiento profundo y visión humana son algo similares, pero básicamente la red neuronal "mira" las cosas "de una manera similar a una computadora". Por ejemplo, cuando recibe una imagen, "ve" una cuadrícula estática de píxeles rectangulares al mismo tiempo. El ojo funciona de manera diferente, una persona percibe detalles altos en un sector de aproximadamente cinco grados a cada lado de la línea de visión, pero fuera de esta zona, la atención al detalle disminuye linealmente.
Por lo tanto, a diferencia de una máquina, por ejemplo, difuminar los bordes de una imagen no funcionará con una persona y simplemente pasará desapercibido. Los investigadores pudieron simular esta característica al agregar una "capa de retina" que cambió los datos suministrados por el SNA a lo que se vería para el ojo, con el objetivo de limitar la red neuronal al mismo marco que la visión normal.
Cabe señalar que una persona hace frente a sus deficiencias de percepción por el hecho de que la mirada no se dirige a un punto, sino que se mueve constantemente, examinando toda la imagen, pero también fue posible compensar las condiciones del experimento, nivelando las diferencias entre el SCN y las personas.
Nota del trabajo en sí:
Cada experimento comenzó con un punto de mira de instalación, que apareció en el centro de la pantalla durante 500-1000 milisegundos, y cada sujeto recibió instrucciones de fijar la mirada en el punto de mira.El uso de la "capa retiniana" fue el último paso que tuvo que tomarse como parte de un "ajuste fino" del aprendizaje automático para las "características humanas". Durante la generación de las muestras, fueron conducidas a través de diez modelos diferentes, cada uno de los cuales debería haber llamado claramente, por ejemplo, un gato, por ejemplo, un perro. Si el resultado fue "10 de 10 se equivocaron", entonces el material se sometió a prueba en humanos.
¿Esto funciona?
En el experimento participaron tres grupos de imágenes: “mascotas” (gatos y perros), “vegetales” (calabacín y brócoli) y “amenazas” (arañas y serpientes, aunque como propietario de la serpiente sugeriría un término diferente para la evaluación). Para cada grupo, se contaba el éxito si la persona de la prueba elegía lo incorrecto: llamaba al perro gato y viceversa. Los participantes se sentaron frente a un monitor que mostraba una imagen durante aproximadamente 60 o 70 milisegundos, y tuvieron que presionar uno de los dos botones para indicar el objeto. Dado que la imagen se mostró por un tiempo muy corto, esto suavizó la diferencia entre cómo las personas y las redes neuronales perciben el mundo; La ilustración en el título, por cierto, es sorprendente en su persistencia de error.
Lo que mostraron los sujetos podría ser una imagen no modificada (imagen), una CarP "ordinaria" (adv), una CarP "invertida" (flip), en la que el ruido se volcó antes de la aplicación, o una CarP "falsa", en la que una capa con Se aplicó ruido a una imagen que no pertenece a ninguno de los tipos del grupo (falso). Las últimas dos opciones se utilizaron para controlar la naturaleza de la perturbación (¿afectará la estructura del ruido de otra manera al revés, o simplemente "comerá"?), Además, permitieron comprender si la interferencia engaña completamente a las personas o simplemente reduce ligeramente la precisión.
Nota del trabajo en sí:
Falso: se agregó una condición para obligar al sujeto a cometer un error. Lo agregamos, porque si los cambios iniciales reducen la precisión del observador, esto puede deberse a una disminución en la calidad de la imagen directa. Para mostrar que las CARP realmente funcionan en cada clase, introdujimos opciones en las que ninguna opción podía ser correcta y su precisión era 0, y observamos exactamente cuál era la respuesta "correcta" en ese caso. Demostramos imágenes arbitrarias de ImageNet, que fueron afectadas por una u otra clase en el grupo, pero no se ajustaban a ninguna de ellas. El participante del experimento tuvo que determinar qué estaba frente a él. Por ejemplo, podríamos mostrar una imagen de un avión distorsionado aplicando ruido de "perro", aunque durante el experimento el sujeto debería haber reconocido solo un gato o un perro.Aquí hay un ejemplo que muestra un porcentaje del número de personas que pudieron identificar claramente una imagen como un perro, dependiendo de cómo se utilizó el ruido. Permítame recordarle que solo tomó entre 60 y 70 milisegundos echar un vistazo y tomar una decisión.
 Fuente: Google Brain
Fuente: Google Brain
Cuadro original con un perro; Carpa con un perro, aceptada tanto por un hombre como por una computadora como gato; controle la imagen con una capa de ruido al revés.Y aquí están los resultados finales:
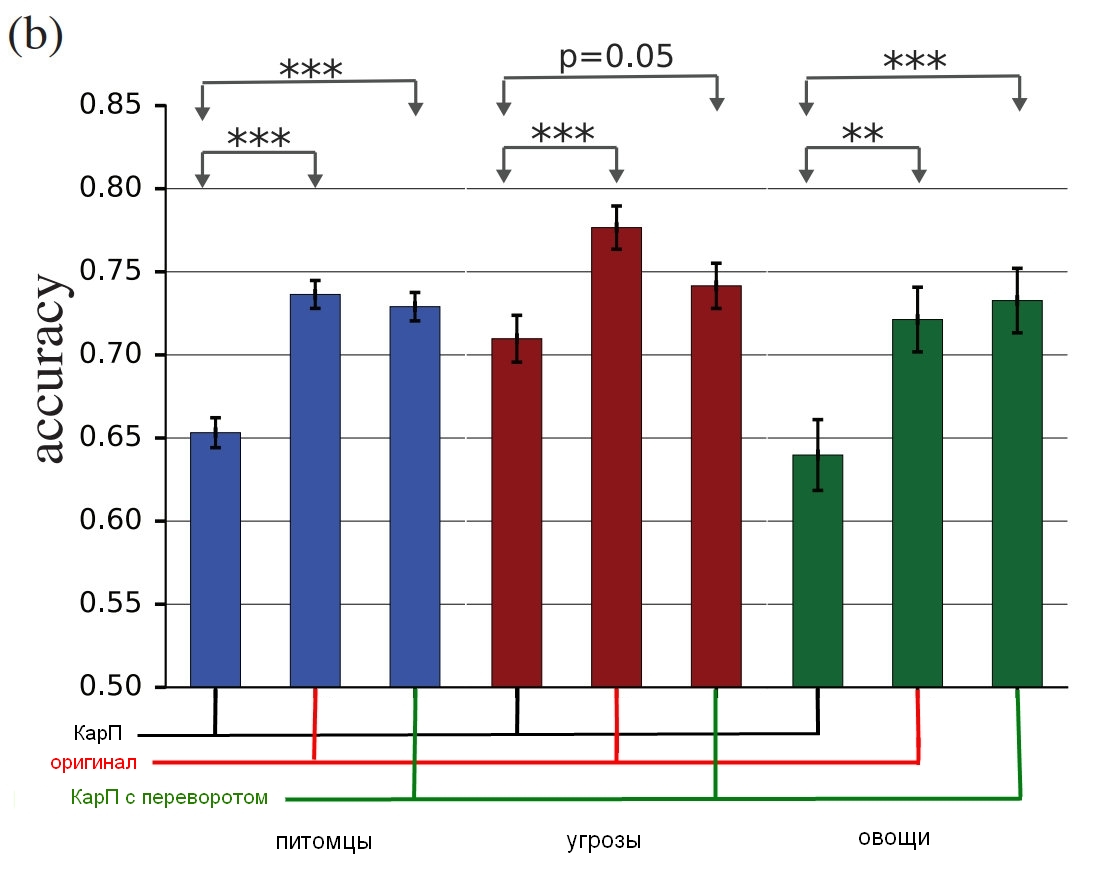 Fuente: Google Brain
Fuente: Google Brain
Los resultados del estudio, cómo las personas verdaderas identifican estas imágenes en comparación con las distorsionadas.El cuadro muestra la precisión del partido. Si elige un gato y realmente es un gato, la precisión aumenta. Si elige un gato, pero en realidad es un perro, convertido por el ruido en una especie de gato, la precisión se reduce.
Como puede ver, las personas son mucho más correctas en la selección de imágenes no corregidas o con capas de ruido invertidas que en la selección de las "inconsistentes". Esto demuestra que el principio de ataque a la percepción puede transferirse de las computadoras a nosotros.
Los impactos no solo son innegablemente efectivos, sino que también son más delgados de lo esperado: no hay boxcats o pseudo-tostadoras, ni nada de eso. Como vimos ambas capas con ruido e imágenes antes y después del procesamiento, tenemos que descubrir qué es lo que nos confunde exactamente en esto. Aunque los investigadores son cautelosos, afirman que "nuestros ejemplos están hechos especialmente para hacer el ridículo, por lo que debes tener cuidado al usar personas como experimentales para estudiar el efecto".
En el futuro, el equipo tratará de derivar algunas reglas generales para ciertas categorías de modificación, incluida la "
destrucción de los bordes de un objeto , especialmente por impactos moderados, perpendiculares a la línea del borde;
corrección de áreas limítrofes aumentando el contraste mientras texturiza el borde;
cambiando la textura ;
usando partes oscuras "Imágenes en las que el nivel de impacto en la percepción es alto incluso a pesar de pequeñas perturbaciones". Los siguientes son ejemplos donde las áreas encerradas en un círculo rojo en las que los métodos descritos se ven mejor.
 Fuente: Google Brain
Fuente: Google Brain
Ejemplos de imágenes con diferentes principios de distorsión.Cual es el resultado?
La conclusión es que esto es más, mucho más que un simple truco inteligente. Los chicos de Google Brain confirmaron que pueden crear una técnica efectiva de engaño, pero no entienden completamente por qué funciona, teniendo en cuenta el nivel de abstracción, y es posible que este sea literalmente un nivel básico de realidad:
Nuestro proyecto plantea preguntas fundamentales sobre cómo funcionan las CARP, cómo funcionan las redes neuronales y el cerebro. ¿Logró transferir los ataques del SCN al cerebro porque las representaciones semánticas de la información en ellos son similares? ¿O porque ambas representaciones corresponden a un cierto modelo semántico general, que existe naturalmente en el mundo circundante?
En conclusión, si realmente quieres ponerte un poco paranoico, entonces los investigadores están felices de hacerte un favor, señalando que "el reconocimiento visual de los objetos ... es difícil hacer una evaluación objetiva". ¿Es "Fig. 1" verdadera objetivamente un perro, o es un gato objetivo que puede hacer que la gente piense que es un perro? " En otras palabras, ¿la imagen realmente se convierte en un objeto, o simplemente te hace pensar de manera diferente?
Aquí es espeluznante (y lo digo en serio "espeluznante") que al final puedes obtener formas de influir en cualquier hecho, porque la distancia entre manipular el SCN y manipular a una persona obviamente no es demasiado grande. En consecuencia, las tecnologías de aprendizaje automático pueden usarse potencialmente para distorsionar imágenes o videos de la manera correcta, lo que reemplazará nuestra percepción (y la reacción correspondiente), y ni siquiera entenderemos lo que sucedió. Del informe:
Por ejemplo, un grupo de modelos con capacitación en profundidad se puede capacitar en las evaluaciones de las personas sobre el nivel de confianza en ciertos tipos de personas, características, expresiones. Será posible generar indignaciones "conflictivas" que aumentarán o disminuirán la sensación de "credibilidad", y dichos materiales "modificados" se pueden usar en clips de noticias o publicidad política.
En el futuro, los riesgos teóricos incluyen la posibilidad de crear estimulaciones sensoriales que ingresen al cerebro de una gran variedad de formas y con una eficiencia muy alta. Como sabes, muchos animales son vistos como vulnerables a las estimulaciones por encima del umbral. Digamos que los cucos pueden simular simultáneamente estar indefensos y hacer un llamado lastimero, lo que en combinación hace que las aves de otras razas alimenten a los polluelos de cuco antes que a su propia descendencia. Las muestras "en conflicto" se pueden considerar como una forma tan peculiar de estimulación superthreshold para redes neuronales. Y el hecho de que los estímulos excesivos, que en teoría son mucho más propensos a afectar a una persona que simplemente hacer que cuelguen una etiqueta de "un gato" en la imagen de un perro, es motivo de gran preocupación, pueden crearse utilizando una máquina y luego transferirse a las personas.
Por supuesto, tales métodos se pueden usar "para bien", y ya se han propuesto una serie de opciones, como "agudizar los rasgos característicos de las imágenes para aumentar el nivel de concentración, por ejemplo, al controlar la situación del aire o analizar imágenes de rayos X, ya que este trabajo es monótono y las consecuencias el descuido puede ser terrible ". Además, "los diseñadores de interfaces de usuario pueden usar perturbaciones para desarrollar interfaces más intuitivas". Hmmm Ciertamente es genial, pero de alguna manera estoy más preocupado por la cuestión de hackear mi cerebro y establecer el nivel de confianza en las personas, ¿sabes?
Algunas de las preguntas planteadas serán objeto de futuras investigaciones: se puede descubrir qué hace que las imágenes específicas sean más adecuadas para transmitir un error a una persona, y esto puede proporcionar nuevas pistas para comprender los principios del cerebro. Y esto, a su vez, ayudará a crear redes neuronales más avanzadas que aprenderán más rápido y mejor. Pero debemos tener cuidado y recordar que, como las computadoras, a veces no es tan difícil engañarnos.
El proyecto
" Ejemplos adversarios que engañan tanto a la visión humana como a la informática , de Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow y Jascha Sohl-Dickstein, de Google Brain" , se puede descargar de
arXiv . Y si necesita imágenes más controvertidas que funcionen en las personas, entonces el material de apoyo está
aquí .