
Instagram tiene una de las bases de datos Apache Cassandra más grandes del mundo. El proyecto comenzó a usar Cassandra en 2012 para reemplazar a Redis y apoyar la implementación de características de la aplicación, como un sistema de reconocimiento de fraude, Tape y Direct. Al principio, los clústeres de Cassandra trabajaban en AWS, pero luego los ingenieros los migraron a la infraestructura de Facebook junto con todos los demás sistemas de Instagram. Cassandra se desempeñó muy bien en términos de confiabilidad y tolerancia a fallas. Al mismo tiempo, las métricas de latencia al leer datos claramente podrían mejorarse.
El año pasado, el equipo de soporte de Cassandra en Instagram comenzó a trabajar en un proyecto destinado a reducir significativamente la latencia en la lectura de datos en Cassandra, que los ingenieros llamaron Rocksandra. En este artículo, el autor explica qué motivó al equipo a implementar este proyecto, las dificultades que tuvieron que superarse y las métricas de rendimiento que los ingenieros usan tanto en los entornos de nube internos como externos.
Motivos para la transición
Instagram utiliza activa y ampliamente Apache Cassandra como un servicio de almacenamiento de valor clave. La mayoría de las solicitudes de Instagram se realizan en línea, por lo tanto, para proporcionar una experiencia de usuario confiable y agradable para cientos de millones de usuarios de Instagram, los SLA son muy exigentes con el rendimiento del sistema.
Instagram se adhiere a una calificación de confiabilidad de cinco y nueve. Esto significa que el número de fallas en un momento dado no puede exceder 0.001%. Para mejorar el rendimiento, los ingenieros supervisan activamente el rendimiento y las latencias de varios clústeres de Cassandra y se aseguran de que el 99% de todas las solicitudes se ajusten a un determinado indicador (retraso P99).
A continuación se muestra un gráfico que muestra el retraso del lado del cliente de uno para uno de los grupos de combate de Cassandra. El azul indica la velocidad de lectura promedio (5 ms) y el naranja indica la velocidad de lectura del 99%, que varía de 25 a 60 ms. Sus cambios dependen mucho del tráfico del cliente.
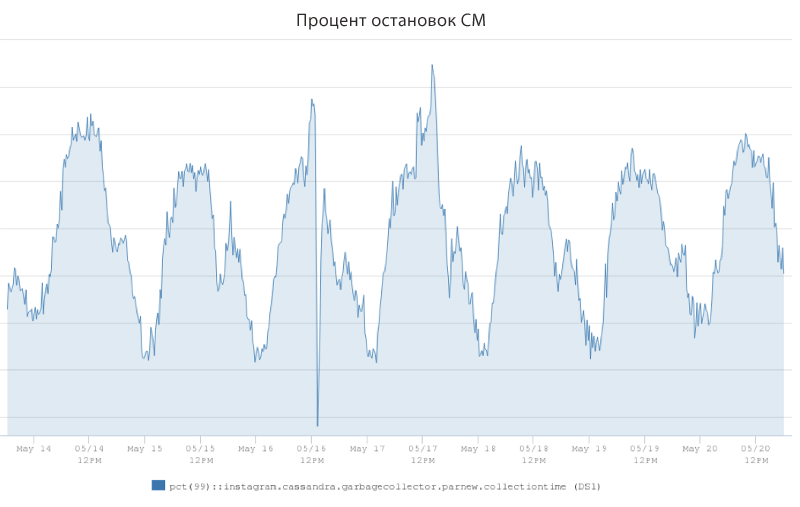

El estudio encontró que los fuertes estallidos de demora se deben en gran medida al trabajo del recolector de basura JVM. Los ingenieros introdujeron una métrica llamada "porcentaje de paradas para SM" para medir el porcentaje de tiempo que el servidor Cassandra dedicó a "detener el mundo", y fue acompañado por una denegación de servicio para las solicitudes de los clientes. Aquí está la tabla anterior que muestra la cantidad de tiempo (en porcentaje) que pasó hasta que el SM deja de usar el ejemplo de uno de los servidores de combate de Cassandra. El indicador osciló entre el 1,25% en los momentos del tráfico más pequeño y el 2,5% en los momentos de carga máxima.
El gráfico muestra que esta instancia del servidor Cassandra podría pasar el 2.5% de su tiempo recolectando basura en lugar de atender las solicitudes de los clientes. Las operaciones preventivas del colector obviamente tuvieron un impacto significativo en el retraso P99, y por lo tanto quedó claro que si pudiéramos reducir la tasa de detención de CM, entonces los ingenieros podrían reducir significativamente la tasa de retraso P99.
Solución
Apache Cassandra es una base de datos distribuida basada en Java con su propio motor de almacenamiento de datos basado en árboles LSM. Los ingenieros descubrieron que los componentes del motor, como una tabla de memoria, una herramienta de compresión, rutas de lectura / escritura, y algunos otros crearon muchos objetos en la memoria dinámica de Java, lo que llevó a la JVM a tener que realizar muchas operaciones generales adicionales. Para reducir el impacto de los mecanismos de almacenamiento en el trabajo del recolector de basura, el equipo de soporte consideró varios enfoques y finalmente decidió desarrollar un motor C ++ y reemplazar el existente con él.
Los ingenieros no querían hacer todo desde cero y, por lo tanto, decidieron tomar RocksDB como base.
RocksDB es una base de datos incorporada de código abierto de alto rendimiento para almacenamiento de valor clave. Está escrito en C ++, y su API tiene enlaces de lenguaje oficiales para C ++, C y Java. RocksDB está optimizado para un alto rendimiento, especialmente en unidades rápidas como SSD. Es ampliamente utilizado en la industria como motor de almacenamiento para MySQL, mongoDB y otras bases de datos populares.
Dificultades
En el proceso de implementación del nuevo motor de almacenamiento en RocksDB, los ingenieros enfrentaron tres tareas difíciles y las resolvieron.
La primera dificultad fue que Cassandra aún carece de una arquitectura que permita la conexión de procesadores de datos de terceros. Esto significa que el trabajo del motor existente está estrechamente interconectado con otros componentes de la base de datos. Para encontrar un equilibrio entre la refactorización a gran escala y las iteraciones rápidas, los ingenieros definieron la API del nuevo motor, incluidas las interfaces de lectura, escritura y transmisión más comunes. Por lo tanto, el equipo de soporte pudo implementar nuevos mecanismos de procesamiento de datos para la API e insertarlos en las rutas de ejecución de código apropiadas dentro de Cassandra.
La segunda dificultad fue que Cassandra soportaba tipos de datos estructurados y esquemas de tablas, mientras que RocksDB solo proporcionaba interfaces clave-valor. Los ingenieros definieron cuidadosamente los algoritmos de codificación y decodificación para admitir el modelo de datos de Cassandra dentro de las estructuras de datos de RocksDB y garantizaron la continuidad de la semántica de consultas similares entre las dos bases de datos.
La tercera dificultad estaba asociada con un componente tan importante para cualquier componente de base de datos distribuida como trabajar con flujos de datos. Cada vez que se agrega o elimina un nodo de un clúster Cassandra, necesita distribuir correctamente los datos entre diferentes nodos para equilibrar la carga dentro del clúster. Las implementaciones existentes de estos mecanismos se basaron en la obtención de datos detallados del motor de base de datos existente. Por lo tanto, los ingenieros tuvieron que separarlos unos de otros, crear una capa de abstracción e implementar una nueva opción para procesar secuencias utilizando la API RocksDB. Para obtener flujos de gran ancho de banda, el equipo de soporte ahora primero distribuye los datos a archivos sst temporales, y luego usa la API especial de RocksDB para "tragar" los archivos, permitiendo que se descarguen simultáneamente a la instancia de RocksDB.
Indicadores de desempeño
Después de casi un año de desarrollo y pruebas, los ingenieros completaron la primera versión de la implementación y la "implementaron" con éxito en varios grupos de Instagram Instagram Cassandra. En uno de los grupos de combate, el retraso P99 se redujo de 60 ms a 20 ms. Las observaciones también mostraron que las paradas de SM en este grupo cayeron del 2.5% al 0.3%, es decir, ¡casi 10 veces!
Los ingenieros también querían verificar si Rocksandra podía funcionar bien en un entorno de nube pública. El equipo de soporte creó un clúster Cassandra en AWS utilizando tres instancias i3.8 xlarge EC2, cada una con un procesador de 32 núcleos, 244 GB de RAM y una incursión cero de cuatro unidades flash NVMe.
Para las pruebas comparativas, utilizamos
NDBench y el esquema de tabla predeterminado para el marco.
TABLE emp ( emp_uname text PRIMARY KEY, emp_dept text, emp_first text, emp_last text )
Los ingenieros precargaron 250 millones de 6 filas de 6 KB cada una (se almacenan aproximadamente 500 GB de datos en cada servidor). Luego, configure 128 lectores y escritores en NDBench.
El equipo de soporte probó varias cargas y midió las latencias promedio de lectura / escritura de P99 / P999. Los gráficos a continuación muestran que Rocksandra mostró latencias de lectura y escritura significativamente más bajas y más estables.


Los ingenieros también verificaron la carga en modo de lectura sin escribir y descubrieron que con el mismo retraso de lectura P99 (2 ms), Rocksandra puede proporcionar un aumento de más de 10 veces en la velocidad de lectura de información (300 K / s para Rocksandra frente a 30 K / s para C * 3.0).


Planes futuros
El equipo de soporte de Instagram ha abierto el código y el
marco de Rocksandra para evaluar el rendimiento . Puede descargarlos de Github y probarlos en su propio entorno. ¡Asegúrate de contarnos qué sucedió!
Como siguiente paso, el equipo está trabajando activamente para agregar un soporte más amplio para la funcionalidad C *, como índices secundarios, correcciones y más. Y además, los ingenieros están desarrollando la
arquitectura del motor de base de datos de complementos en C * para transferir aún más estos desarrollos a la comunidad de Apache Cassandra.
