Hola Habr! Finalmente, esperamos otra parte de la serie de materiales del graduado de nuestros programas de
Big Data Specialist y
Deep Learning , Cyril Danilyuk, sobre el uso de Mask R-CNN, las redes neuronales actualmente populares, como parte de un sistema para clasificar imágenes, a saber evaluar la calidad de un plato preparado utilizando un conjunto de datos de sensores.
Después de examinar el conjunto de datos del juguete que consta de imágenes de señales de tráfico en el
artículo anterior , ahora podemos proceder a resolver el problema que enfrenté en la vida real:
"¿Es posible implementar el algoritmo de aprendizaje profundo, que podría distinguir los platos de alta calidad de los platos malos uno por uno? fotos? . En resumen, el negocio quería esto:
Lo que representa una empresa cuando piensa en el aprendizaje automático:Este es un ejemplo de un problema planteado incorrectamente: en este caso es imposible determinar si existe una solución, si es única y estable. Además, la declaración del problema en sí es muy vaga, sin mencionar la implementación de su solución. Por supuesto, este artículo no está dedicado a la efectividad de las comunicaciones o la gestión de proyectos, pero es importante tener en cuenta:
nunca tome proyectos en los que el resultado final no esté definido y registrado en los Términos de Referencia. Una de las formas más confiables para lidiar con tal incertidumbre es construir primero un prototipo y luego, utilizando nuevos conocimientos, estructurar el resto de la tarea. Eso es lo que hicimos.
Declaración del problema.
En mi prototipo, me concentré en un plato del menú, una tortilla, y construí una tubería escalable, que determina la "calidad" de la tortilla en la salida. Esto se puede describir con más detalle de la siguiente manera:
- Tipo de problema: clasificación multiclase con 6 clases de calidad discretas: buena (buena), yema rota (con yema para untar), sobrecocida (sobrecocida), dos huevos (dos huevos), cuatro huevos (cuatro huevos), piezas mal colocadas (con piezas esparcidas en un plato) .
- Conjunto de datos: 351 fotografías recolectadas manualmente de varias tortillas. Muestras de entrenamiento / validación / prueba: 139/32/180 fotos mixtas.
- Etiquetas de clase: cada foto corresponde a una etiqueta de clase correspondiente a una evaluación subjetiva de la calidad de la tortilla.
- Métrica: entropía cruzada categórica.
- Conocimiento mínimo del dominio: una tortilla de "calidad" debería tener este aspecto: consta de tres huevos, una pequeña cantidad de tocino, una hoja de perejil en el centro, no tiene yemas y trozos demasiado cocidos. Además, la composición general debe "verse bien", es decir, las piezas no deben esparcirse por todo el plato.
- Criterio de finalización: el mejor valor de la entropía cruzada en la muestra de prueba entre todos los posibles después de dos semanas de desarrollo del prototipo.
- El método de visualización final: t-SNE en el espacio de datos de una dimensión más pequeña.
 Imágenes de entrada
Imágenes de entradaEl objetivo principal de la tubería es aprender a combinar varios tipos de señales (por ejemplo, imágenes desde diferentes ángulos, un mapa de calor, etc.), después de haber recibido una representación precomprimida de cada una de ellas y pasar estas características a través del clasificador de red neuronal para la predicción final. Por lo tanto, podemos realizar nuestro prototipo y hacerlo prácticamente aplicable en futuros trabajos. A continuación se presentan algunas de las señales utilizadas en el prototipo:
- Máscaras de ingredientes clave (Máscara R-CNN): Señal No. 1 .
- El número de ingredientes clave en el marco., Señal número 2 .
- Cultivo RGB de platos con tortilla sin fondo. Para simplificar, decidí no agregarlos al modelo todavía, aunque son la señal más obvia: en el futuro, puede entrenar la red neuronal convolucional para la clasificación utilizando alguna función de pérdida de triplete adecuada, calcular incrustaciones de imágenes y cortar la distancia L2 de la corriente Imágenes para perfeccionar. Desafortunadamente, no tuve la oportunidad de probar esta hipótesis, ya que la muestra de prueba constaba de solo 139 objetos.
Vista general de la tubería.
Observo que tendré que omitir algunos pasos importantes, como el análisis de datos exploratorios, la construcción de un clasificador básico y el etiquetado activo (mi término propuesto, que significa anotación semiautomática de objetos, inspirada en el
video de demostración Polygon-RNN ) para la máscara R-CNN (más sobre esto en las próximas publicaciones).
Eche un vistazo a toda la tubería en general:
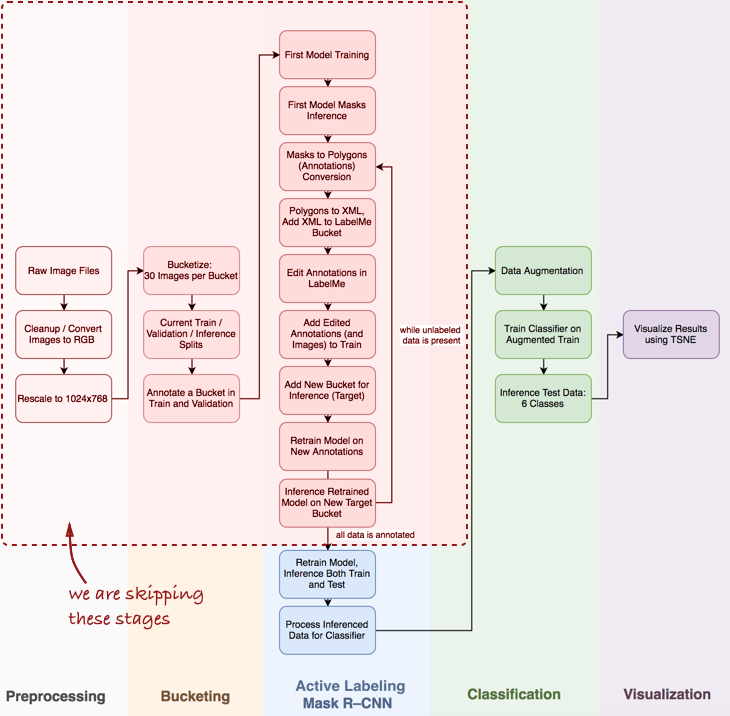 En este artículo, estamos interesados en las etapas de la máscara R-CNN y la clasificación dentro de la tubería.
En este artículo, estamos interesados en las etapas de la máscara R-CNN y la clasificación dentro de la tubería.A continuación, consideraremos tres etapas: 1) usar la máscara R-CNN para construir máscaras de ingredientes de tortilla; 2) clasificador ConvNet basado en Keras; 3) visualización de resultados usando t-SNE.
Etapa 1: Máscara R-CNN y máscaras de construcción
Máscara R-CNN (MRCNN) ha estado recientemente en la cima de la popularidad. A partir del
artículo original de
Facebook y terminando con el
Data Science Bowl 2018 en Kaggle, Mask R-CNN se ha establecido como una arquitectura poderosa, por ejemplo, la segmentación (es decir, no solo la segmentación de imágenes píxel por píxel, sino también la separación de varios objetos que pertenecen a la misma clase ) Además, es un placer trabajar con la
implementación de MRCNN de Matterport en Keras. El código está bien estructurado, tiene buena documentación y funciona de inmediato, aunque más lentamente de lo esperado.
En la práctica, especialmente cuando se desarrolla un prototipo, es fundamental contar con una red neuronal convolucional preformada. En la mayoría de los casos, el conjunto de datos etiquetados del científico de datos es muy limitado o nada en absoluto, mientras que ConvNet requiere una gran cantidad de datos etiquetados para lograr la convergencia (por ejemplo, el conjunto de datos ImageNet contiene 1,2 millones de imágenes etiquetadas). Aquí el
aprendizaje de transferencia viene al rescate: podemos arreglar el peso de las capas convolucionales y volver a entrenar solo el clasificador. La fijación de capas convolucionales es importante para pequeños conjuntos de datos, ya que esta técnica evita el reentrenamiento.
Esto es lo que obtuve después de la primera era de reciclaje:
 Resultado de segmentación de objetos: todos los ingredientes clave reconocidos
Resultado de segmentación de objetos: todos los ingredientes clave reconocidosEn la siguiente etapa de la tubería (
Procesar datos inferidos para el clasificador ), es necesario recortar la parte de la imagen que contiene la placa y extraer la máscara binaria bidimensional para cada ingrediente en esta placa:
 Imagen recortada con ingredientes clave en forma de máscaras binarias.
Imagen recortada con ingredientes clave en forma de máscaras binarias.Estas máscaras binarias se combinan en una imagen de 8 canales (ya que definí 8 clases de máscara para MRCNN), y obtenemos la
Señal No. 1 :
 Señal No. 1 : imagen de 8 canales que consiste en máscaras binarias. En color para una mejor visualización.
Señal No. 1 : imagen de 8 canales que consiste en máscaras binarias. En color para una mejor visualización.Para obtener la
Señal No. 2 , conté la cantidad de veces que se encuentra cada ingrediente en el cultivo de la placa y obtuve un conjunto de vectores de características, cada uno de los cuales corresponde a su cultivo.
Etapa 2: Clasificador ConvNet en Keras
El clasificador CNN se implementó desde cero utilizando Keras. Quería combinar varias señales (
Señal No. 1 y
Señal No. 2 , así como la posible adición de datos en el futuro) y dejar que las redes neuronales las usen para hacer pronósticos sobre la calidad del plato. La arquitectura presentada a continuación es de prueba y está lejos de ser ideal:

Algunas palabras sobre la arquitectura del clasificador:
- Módulo convolucional multiescala : inicialmente elegí un filtro de 5x5 para capas convolucionales, pero esto solo condujo a un resultado satisfactorio. Se lograron mejoras aplicando AveragePooling2D a varias capas con diferentes filtros: 3x3, 5x5, 7x7, 11x11. Se agregó una capa convolucional adicional de 1x1 frente a cada una de las capas para reducir la dimensión. Este componente es un poco como un módulo de inicio , aunque no planeé construir una red demasiado profunda.
- Filtros más grandes : utilicé filtros más grandes, porque ayudan a extraer fácilmente signos más grandes de la imagen de entrada (que en sí misma es esencialmente una capa de activación con 8 filtros; la máscara de cada ingrediente puede considerarse como un filtro separado).
- Combinación de señales : en mi ingenua implementación, solo se usó una capa que conectaba dos conjuntos de atributos: máscaras binarias procesadas ( Señal No. 1 ) e ingredientes contados ( Señal No. 2 ). Sin embargo, a pesar de su simplicidad, la adición de la Señal No. 2 hizo posible reducir la métrica de entropía cruzada de 0.8 a [0.7, 0.72] .
- Logits : en términos de TensorFlow, logit es una capa en la que se aplica tf.nn.softmax_cross_entropy_with_logits para calcular la pérdida de lote .
Etapa 3: visualización de resultados usando t-SNE
Para visualizar los resultados del clasificador en los datos de prueba, utilicé t-SNE, un algoritmo que le permite transferir los datos de origen a un espacio de menor dimensión (para comprender el principio del algoritmo, le recomiendo leer
el artículo original , es extremadamente informativo y está bien escrito).
Antes de la visualización, tomé imágenes de prueba, extraje la capa de logite del clasificador y apliqué el algoritmo t-SNE a este conjunto de datos. Aunque no he probado diferentes valores del parámetro de perplejidad, el resultado sigue siendo bastante bueno:
 El resultado de t-SNE en datos de prueba con predicciones de clasificador
El resultado de t-SNE en datos de prueba con predicciones de clasificadorPor supuesto, este enfoque es imperfecto, pero funciona. Puede haber bastantes mejoras posibles:
- Más datos Las redes de convolución requieren muchos datos, y solo tenía 139 imágenes para entrenamiento. Técnicas como el aumento de datos funcionan bien (utilicé D4 o aumento diédrico simétrico , resultando en más de 2 mil imágenes), pero tener más datos reales sigue siendo extremadamente importante.
- Función de pérdida más adecuada. Para simplificar, utilicé la entropía cruzada categórica, lo cual es bueno porque funciona de inmediato. La mejor opción sería utilizar la función de pérdida, que tiene en cuenta la variación dentro de las clases, por ejemplo, la función de pérdida de triplete (consulte el artículo de FaceNet ).
- Mejora de la arquitectura del clasificador. El clasificador actual es esencialmente un prototipo, cuyo único propósito es construir máscaras binarias y combinar varios conjuntos de características para formar una sola tubería.
- Diseño de imagen mejorado. Fui muy descuidado al marcar imágenes manualmente: el clasificador hizo este trabajo mejor que yo en una docena de imágenes de prueba.
Conclusión Finalmente, debe reconocerse que el negocio no tiene datos, ni explicaciones, ni siquiera una tarea más clara que deba resolverse. Y esto es bueno (de lo contrario, ¿por qué lo necesitan?), Porque su trabajo consiste en utilizar varias herramientas, procesadores multinúcleo, modelos previamente capacitados y una combinación de experiencia técnica y comercial para crear valor adicional en la empresa.
Comience con algo pequeño: se puede crear un prototipo funcional a partir de varios bloques de código de juguetes, y aumentará significativamente la productividad de futuras conversaciones con la administración de la empresa. Este es el trabajo de un científico de datos: ofrecer a los negocios nuevos enfoques e ideas.
El 20 de septiembre de 2018, comienza el
"Especialista en Big Data 9.0" , donde, entre otras cosas, aprenderá cómo visualizar datos y comprender la lógica empresarial detrás de esta o aquella tarea, lo que ayudará a presentar de manera más efectiva los resultados de su trabajo a colegas y gerencia.